
Palcoscenico 1: Qualsiasi banca globale oggi ha più di 100 milioni di clienti che effettuano miliardi di transazioni ogni mese.
Palcoscenico 2: I siti Web di social media o i siti Web di e-commerce tengono traccia del comportamento dei clienti sul sito Web e quindi forniscono informazioni / prodotto pertinente.
I sistemi tradizionali faticano a far fronte a questa scala alla velocità richiesta in modo conveniente.
È qui che vengono in aiuto le piattaforme Big Data.. In questo articolo, vi presentiamo l'affascinante mondo di Hadoop. Hadoop è utile quando si tratta di dati enormi. Potrebbe non rendere il processo più veloce, ma ci dà la possibilità di utilizzare la potenza di elaborazione parallela per gestire i big data. In sintesi, Hadoop ci dà la capacità di affrontare le complessità di volume alto, velocità e varietà di dati (popolarmente noto come 3V).
Notare che, oltre a Hadoop, ci sono altre piattaforme di big data, ad esempio, NoSQL (MongoDB è il più popolare), li vedremo più tardi.
Introduzione a Hadoop
Hadoop è un ecosistema completo di progetti open source che ci fornisce il framework per gestire i big data. Iniziamo con il brainstorming delle potenziali sfide nell'affrontare i big data (nei sistemi tradizionali) e poi vediamo la capacità della soluzione Hadoop.
Le seguenti sono le sfide che mi vengono in mente quando ho a che fare con i big data:
1. Elevato investimento di capitale nell'acquisizione di un server con elevata capacità di elaborazione.
2. Tempo enorme investito
3. In caso di query lunghe, immagina che si verifichi un errore nell'ultimo passaggio. Perderai molto tempo a fare queste iterazioni.
4. Difficoltà a generare query sul programma
Ecco come Hadoop risolve tutti questi problemi:
1. Grande investimento di capitale per l'acquisizione di un server ad alto rendimento: I cluster Hadoop vengono eseguiti su un normale hardware di base e mantengono più copie per garantire l'affidabilità dei dati. Un massimo di 4500 macchine insieme utilizzando Hadoop.
2. Tempo enorme investito : Il processo è diviso in parti e viene eseguito in parallelo, risparmio di tempo. Un massimo di 25 Petabyte (1 PB = 1000 TB) dati utilizzando Hadoop.
3. In caso di query lunghe, immagina che si verifichi un errore nell'ultimo passaggio. Perderai molto tempo a fare queste iterazioni : Hadoop esegue il backup dei set di dati a tutti i livelli. Esegue anche query su set di dati duplicati per evitare la perdita di processo in caso di errore individuale. Questi passaggi rendono l'elaborazione Hadoop più precisa e accurata.
4. Difficoltà a generare query sul programma : Le query in Hadoop sono semplici come la codifica in qualsiasi lingua. Devi solo cambiare il modo in cui pensi alla creazione di una query per consentire l'elaborazione parallela.
Sfondo Hadoop
Con un aumento della penetrazione e dell'utilizzo di Internet, i dati acquisiti da Google sono aumentati esponenzialmente di anno in anno. Solo per darti una stima di questo numero, Su 2007 Google ha raccolto una media di 270 PB di dati ogni mese. Lo stesso numero è aumentato a 20000 PB ogni giorno in 2009. Ovviamente, Google aveva bisogno di una piattaforma migliore per elaborare dati così enormi. Google ha implementato un modello di programmazione chiamato MapReduce, chi potrebbe processarli? 20000 PB al giorno. Google ha eseguito queste operazioni MapReduce su un file system speciale chiamato Google File System (GFS). purtroppo, GFS non è open source.
Doug Cutting e Yahoo! ha decodificato il modello GFS e creato un file system distribuito Hadoop (HDFS) parallelo. Il software o framework che supporta HDFS e MapReduce è noto come Hadoop. Hadoop è open source e distribuito da Apache.
Forse ti interessa: Introduzione a MapReduce
Framework di elaborazione Hadoop
Facciamo un'analogia con la nostra vita quotidiana per capire come funziona Hadoop. La base della piramide di ogni azienda sono le persone che sono i singoli contribuenti. Possono essere analisti, programmatori, lavoro manuale, chef, eccetera. Gestire il tuo lavoro è il project manager. Il project manager è responsabile del completamento con successo dell'attività. Necessità di distribuire il lavoro, lisciare il coordinamento tra di loro, eccetera. Cosa c'è di più, la maggior parte di queste aziende ha un responsabile del personale, chi è più interessato a mantenere la squadra?.

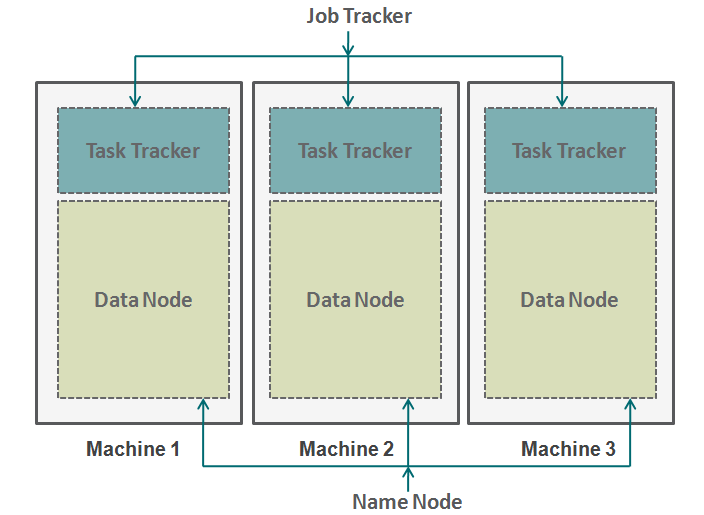
Hadoop funziona in un formato simile. In basso abbiamo le macchine disposte in parallelo. Queste macchine sono analoghe al singolo contribuente nella nostra analogia. Ogni macchina ha un nodo dati e un job tracker. Il nodo dati è anche noto come HDFS (File system distribuito Hadoop) e il tracker delle attività è anche noto come riduttori di mappe.
Il nodo dati contiene l'intero set di dati e il task tracker esegue tutte le operazioni. Puoi immaginare il tracker delle attività come le tue braccia e le tue gambe, che ti consente di eseguire un'attività e un nodo di dati come il tuo cervello, contenente tutte le informazioni che si desidera elaborare. Queste macchine lavorano in silos ed è molto importante coordinarle. Tracciatori di attività (project manager nella nostra analogia) su diverse macchine sono coordinate da un job tracker. Job Tracker si assicura che ogni operazione sia completata e se si verifica un errore nel processo su qualsiasi nodo, devi assegnare un'attività duplicata a un tracker di attività. Il job tracker distribuisce anche l'intera attività a tutte le macchine.
In secondo luogo, un nodo denominato coordina tutti i nodi di dati. Governa la distribuzione dei dati che vanno a ciascuna macchina. Verifica inoltre qualsiasi tipo di spurgo avvenuto in una macchina. Se si verifica tale debug, trova i dati duplicati che sono stati inviati a un altro nodo di dati e li duplica di nuovo. Puoi pensare a questo nodo del nome come al gestore delle persone nella nostra analogia, chi si preoccupa di più della conservazione dell'intero set di dati?.
Quando non usare Hadoop?
Fino ad ora, abbiamo visto come Hadoop ha reso possibile la gestione dei big data. Ma in alcuni scenari l'implementazione di Hadoop non è raccomandata. Di seguito sono riportati alcuni di questi scenari:
- Accesso ai dati a bassa latenza: accesso rapido a piccoli pezzi di dati
- Modifica di più dati: Hadoop è più adatto solo se ci occupiamo principalmente di leggere dati e non di scrivere dati.
- Molti piccoli file: Hadoop si adatta meglio agli scenari, dove abbiamo pochi ma grandi file.
Note finali
Questo articolo ti dà un'idea di come Hadoop viene in soccorso quando si tratta di dati enormi. Capire come funziona Hadoop è molto essenziale prima di iniziare a codificarlo. Questo perché devi cambiare il modo in cui pensi a un codice. Ora devi iniziare a pensare all'abilitazione dell'elaborazione parallela. Puoi eseguire molti diversi tipi di processi in Hadoop, ma devi convertire tutti questi codici in una funzione di riduzione della mappa. Nei prossimi articoli, spiegheremo come convertire la tua logica semplice in logica Map-Reduce basata su Hadoop. Prenderemo anche casi di studio specifici del linguaggio R per costruire una solida comprensione dell'applicazione Hadoop..
L'articolo ti è stato utile?? Condividi con noi tutte le applicazioni pratiche di Hadoop che hai incontrato al lavoro. Fateci sapere i vostri pensieri su questo articolo nella casella sottostante..





