introduzione
Il machine learning e le immagini hanno un ottimo rapporto, la classificazione delle immagini è stato uno dei ruoli principali del machine learning nel corso degli anni. È stato molto utile durante la pandemia di COVID-19 riconoscere le persone che non seguono le regole come indossare maschere e mantenere le distanze.
Prerequisiti
Ogni programma ha alcuni prerequisiti per risolvere problemi legati all'ambiente.. Stiamo costruendo un set di dati per un progetto di machine learning, il requisito minimo per questo è una macchina con python3 installato e un modulo OpenCV su di esso.
Sto usando Jupyter Notebook sul mio sistema. Se anche tu vuoi usare le stesse impostazioni, devi installare Anaconda sulla tua macchina e quindi installare OpenCV.
Instalar OpenCV
Per installare OpenCV, apri il prompt dei comandi se non stai usando anaconda. Altrimenti, apri il prompt dei comandi di anaconda dalla ricerca di Windows e digita il comando indicato di seguito.
pip install opencv-python=3.4.2.17
Ora sei pronto per codificare e preparare il tuo set di dati.
Passi coinvolti
Qui tratteremo tutti i passaggi coinvolti nella creazione di questo programma.
passo 1: Importa moduli
Primo, dobbiamo importare tutti i moduli richiesti nella console del programma. Abbiamo solo bisogno di due moduli, uno è il “OpenCV” e l'altro è il modulo “tu”. Opencv viene utilizzato per acquisire e renderizzare l'immagine utilizzando la fotocamera del laptop e il modulo del sistema operativo viene utilizzato per creare una directory.

import cv2 as cv
import os
passo 2: Creare un oggetto fotocamera
Come dobbiamo creare il nostro set di dati di immagini, abbiamo bisogno della fotocamera, e OpenCV ci aiuta a creare oggetti della fotocamera che possono essere utilizzati in seguito per varie azioni.

#trama 0 is given to use the default camera of the laptop camera = cv.VideoCapture(0) #Now check if the camera object is created successfully if not camera.isOpened(): Stampa("La fotocamera non è aperta.... Uscita") uscita()
passo 3: creare cartelle di tag
Ora, abbiamo bisogno di creare cartelle per ogni etichetta per motivi di differenziazione. Utilizzare il codice riportato di seguito per creare queste cartelle, È possibile aggiungere tutti i tag desiderati. Abbiamo dato nomi ai nostri tag in base al gioco: pietra, carta, forbici. Stiamo preparando un dataset che potrebbe classificare l'immagine se si tratta di una pietra, un ruolo, una forbice o solo un fondo.

#Creazione di un elenco di lables "Puoi aggiungerne quanti ne vuoi"
Etichette = ["Sfondo","Pietra","Carta","Forbici"]
#Now create folders for each label to store images
for label in Labels:
in caso contrario, Os.Path.exists(etichetta):
os.mkdir(etichetta)
passo 4: passaggio finale per acquisire immagini
Questo è il passo finale e più cruciale del programma. I commenti sono stati scritti online per rendere più facile la comprensione. Aquí tenemos que capturar imágenes y almacenar esas imágenes de acuerdo con la carpeta de etiquetas. Lea el código a fondo, hemos mencionado cada pequeña cosa aquí.
per la cartella in Etichette:
#Utilizzo della variabile Count per assegnare un nome alle immagini nel dataset.
conteggio = 0
#Taking input to start the capturing
print("Premere 's' per avviare la raccolta dei dati per"+cartella)
userinput = input()
se userinput != 's':
Stampa("Input errato ..........")
uscita()
#ticchettio 200 immagini per etichetta, È possibile modificare come si desidera.
mentre conta<200:
#read returns two values one is the exit code and other is the frame
status, frame = camera.read()
#check if we get the frame or not
if not status:
Stampa("Il frame non è stato acquisito.. Uscita...")
break
#convert the image into gray format for fast caculation
gray = cv.cvtColor(portafoto, cv.COLOR_BGR2GRAY)
#display window with gray image
cv.imshow("Finestra video",grigio)
#resizing the image to store it
gray = cv.resize(grigio, (28,28))
#Store the image to specific label folder
cv.imwrite(«C:/Utenti/HP/Documenti/AnacondaML/'+cartella+'/img'+str(contare)+'.png',grigio)
count=count+1
#to quite the display window press 'q'
if cv.waitKey(1) == ord('Q'):
rottura
# Quando tutto è fatto, release the capture
camera.release()
cv.destroyAllWindows()
Implementación práctica
Ora, ejecute el programa para crear el conjunto de datos. Primero proporcionaremos el fondo, luego la piedra, el papel y las tijeras. Antes de la implementación, dovresti sempre essere chiaro su ciò che hai codificato e su come l'output ti aiuterà a risolvere il requisito del caso d'uso. Facciamolo ...
Esegui il programma tutto in una volta
Stiamo usando il notebook jupyter per eseguire questo programma, puoi usare qualsiasi interprete Python. Primo, vai al menu della cella e fai clic su “Corri tutto”, questo eseguirà tutte le celle disponibili in un colpo solo.
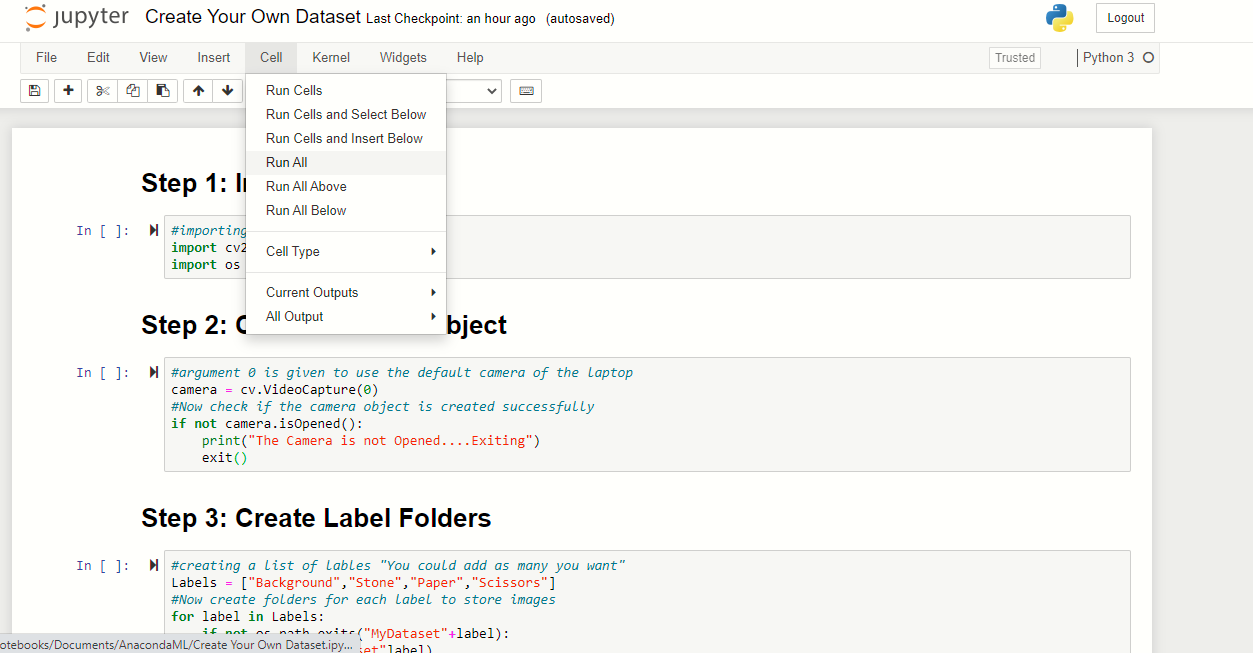
Ora, verrà generato un messaggio di input, premi 's’ e premi invio per iniziare a salvare le immagini per lo sfondo.
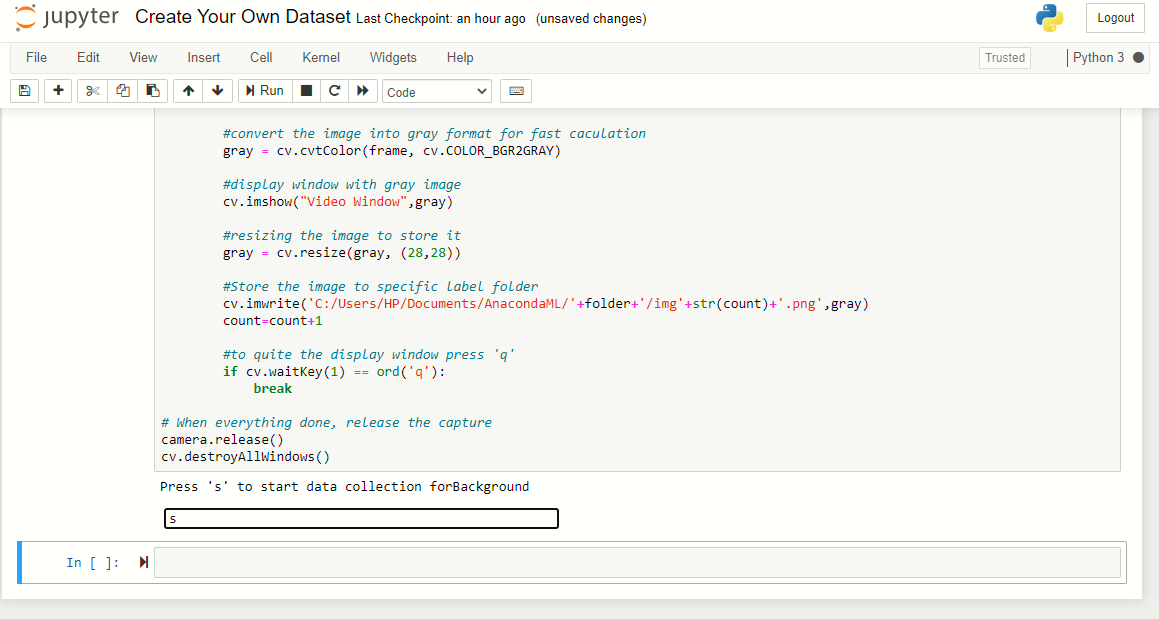
Dopo aver premuto 's', catturerà 200 immagini di sfondo. Apparirà la finestra di visualizzazione e le immagini inizieranno a essere catturate., quindi esci dall'inquadratura e consenti alla fotocamera di catturare lo sfondo.
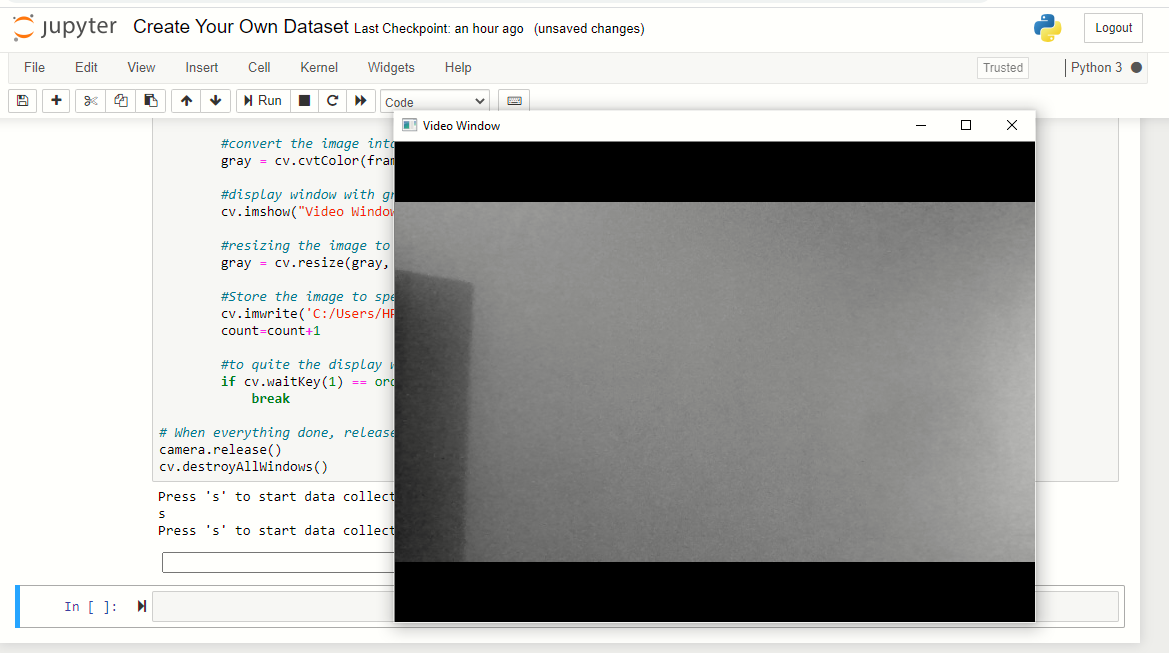
Ora, chiederà 's’ e catturerà immagini di “pietra”. Quindi, stringi il pugno e mostralo alla telecamera in varie posizioni.
Nota: agita semplicemente la mano con il pugno chiuso, non fissare la mano in una posizione per produrre un set di dati ben etichettato.
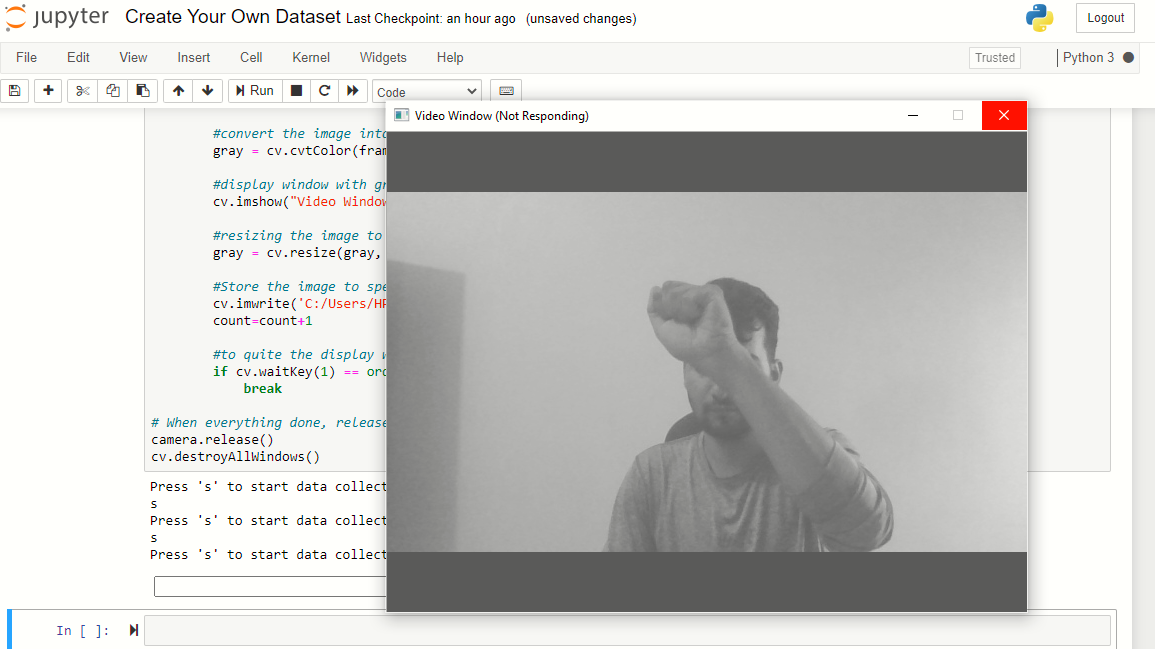
Ora, ripeti lo stesso processo per le immagini di carta e forbici. Non dimenticare di premere 's’ quando richiesto, altrimenti, la finestra del display sembrerà bloccata, ma non è.
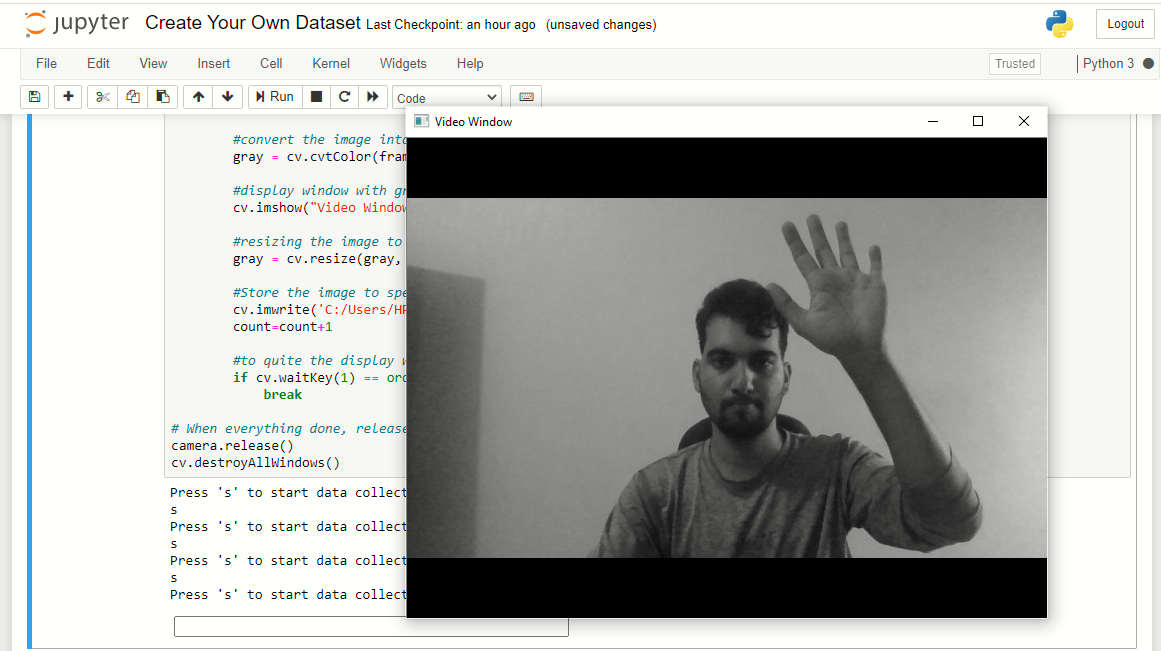
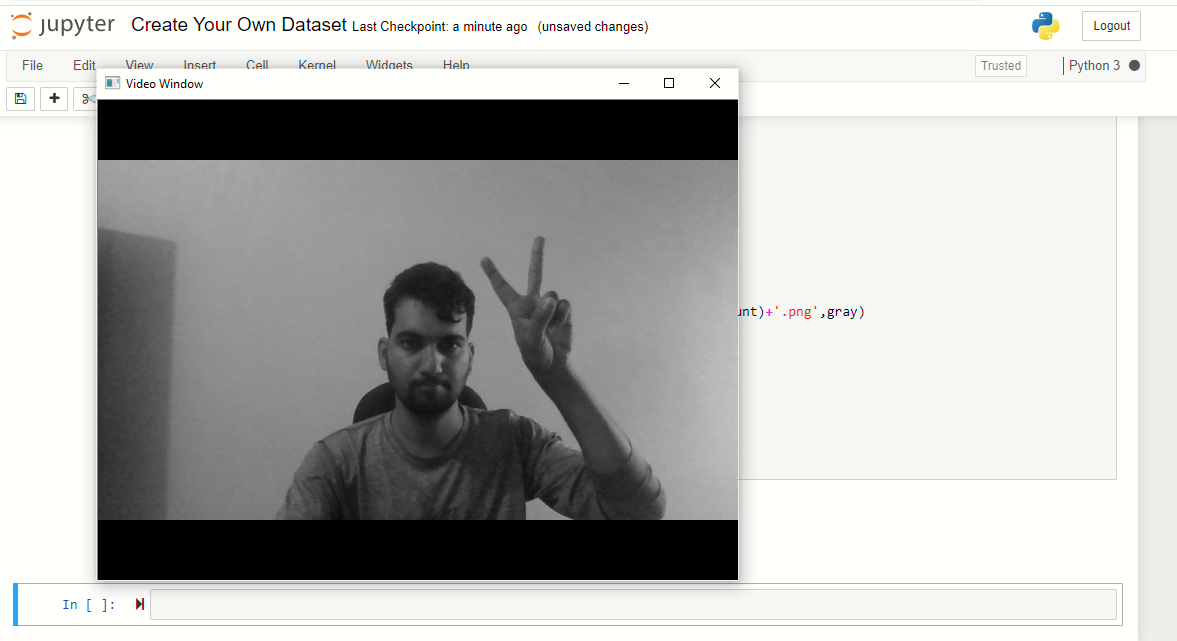
Il programma si chiuderà automaticamente. Ora puoi controllare navigando se il set di dati è stato creato o meno.
Nota: Il set di dati dell'immagine verrà creato nella stessa directory in cui è memorizzato il programma Python. Verranno create quattro directory in base all'etichetta assegnata loro.
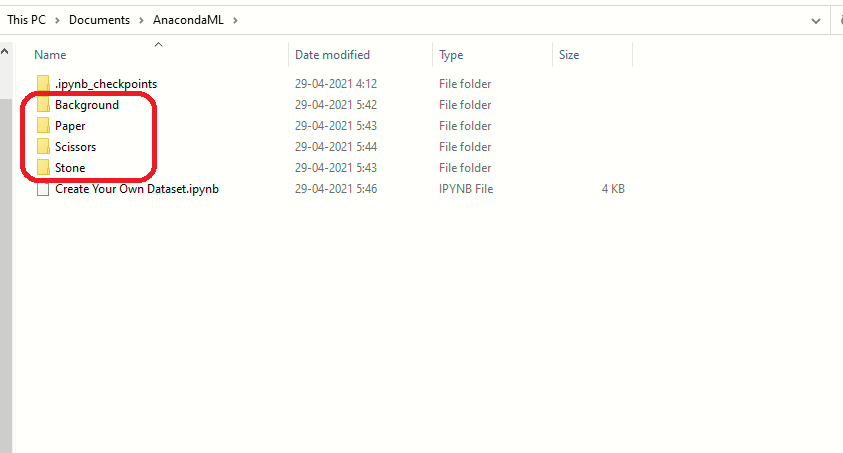
sì, le cartelle sono state create con successo, ora controlla se le immagini sono state catturate e salvate. La dimensione dell'immagine non sarà la stessa di quella che stavi visualizzando durante il processo di acquisizione. Abbiamo ridotto le dimensioni dell'immagine in modo che, quando utilizzato in un progetto di apprendimento automatico per addestrare il modello, richiedono meno risorse e tempo.
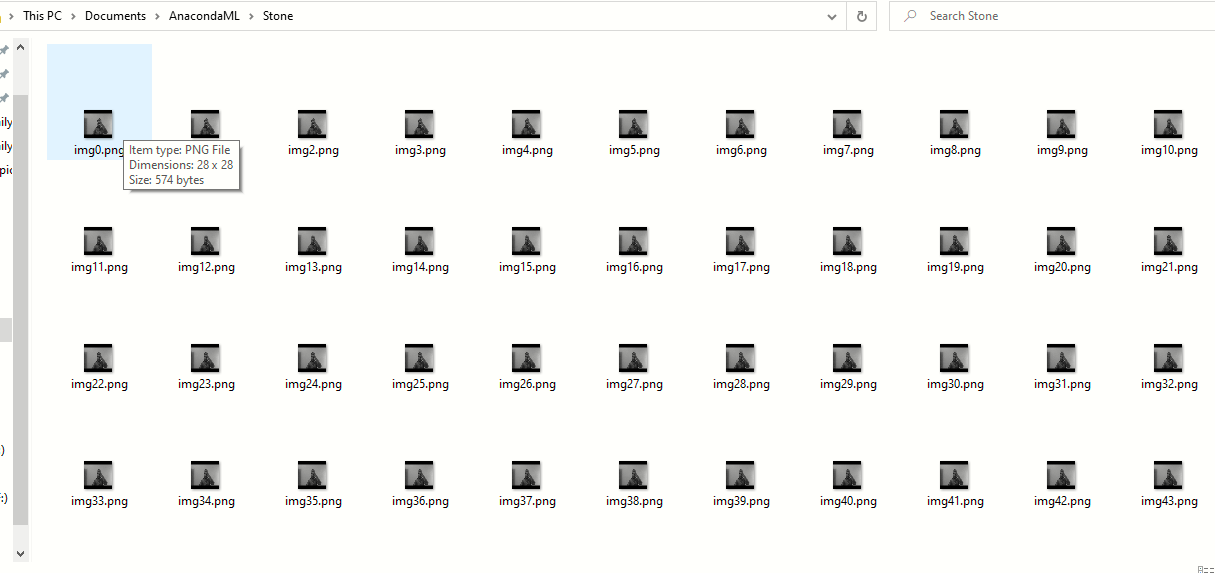
Viva! Abbiamo creato il nostro set di dati di immagini che, Cosa c'è di più, può essere utilizzato in progetti di apprendimento automatico per la classificazione.





