Questo blog è stato pubblicato come parte di Blogathon sulla scienza dei dati 7
importa panda come pd
Ogni progetto di analisi dei dati richiede un set di dati. Questi set di dati sono disponibili in vari formati di file, come .xlsx, .json, .csv, .html. Convenzionalmente, i set di dati si trovano principalmente in .csv formato. CSV (oh valori separati da virgola), Come suggerisce il nome, avere elementi di dati separati da virgole. I file CSV sono file di testo normale che hanno una dimensione del file più leggera. Cosa c'è di più, I file CSV possono essere visualizzati e salvati sotto forma di tabella in strumenti popolari come Microsoft Excel e Fogli Google.
Le virgole utilizzate nei file CSV sono note come Delimitatori. Pensa ai delimitatori come a un confine di separazione che distingue tra due elementi di dati successivi.

Lettura di file CSV utilizzando Pandas
Per leggere questi file CSV, usiamo una funzione della libreria Pandas chiamata read_csv ().
df = pd.read_csv()
La funzione read_csv () ha decine di parametri di cui uno obbligatorio e altri facoltativi per un utilizzo ad hoc. Questo parametro obbligatorio specifica il file CSV che vogliamo leggere. Ad esempio,
df = pd.read_csv("C:UtentiRahulDesktopabc.csv")
Nota: Ricorda di usare le doppie barre rovesciate quando specifichi il percorso del file.

(Fonte: personal computer)
Il parametro settembre
l'autenticazione debole è la minaccia più comune alla sicurezza e all'integrità del database parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... facoltativo in read_csv () è settembre, un nome breve per separatore. Questo operatore è il delimitatore di cui abbiamo parlato prima. Questo parametro sep dice all'interprete, quale delimitatore viene utilizzato nel nostro set di dati o in termini laici, come vengono separati gli elementi dei dati nel nostro file CSV.
Il valore predefinito del parametro sep è il coma (,) il che significa che se non specifichiamo il parametro sep nella nostra funzione read_csv (), si ritiene che il nostro file utilizzi una virgola come delimitatore. Perciò, nel nostro frammento di codice sopra, non specifichiamo il parametro sep, il nostro file era inteso per avere le virgole come delimitatori.
Usa altri delimitatori
Può capitare spesso, il set di dati in formato file .csv ha elementi di dati separati da un delimitatore che non è una virgola. Questo include il punto e virgola, due punti, spazio di tabulazione, barre verticali, eccetera. In tali casi, dobbiamo usare il parametro sep all'interno della funzione read.csv (). Ad esempio, un file chiamato Esempio.csv è un file CSV separato da punto e virgola.
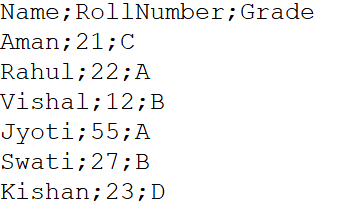
(Fonte: personal computer)
df = pd.read_csv("C:UsersRahulDesktopExample.csv", settembre = ';')
Quando si esegue questo codice, otteniamo un frame di dati chiamato df:
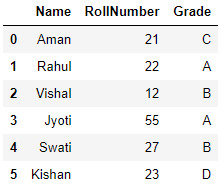
(Fonte: personal computer)
Separatore di barre verticali
Perciò, un file delimitato da barre verticali può essere letto da:
df = pd.read_csv("C:UsersRahulDesktopExample.csv", settembre = '|')
Separatore di due punti
E un file delimitato da due punti può essere letto da:
df = pd.read_csv("C:UsersRahulDesktopExample.csv", settembre = ':')
Separatore di tabulazioni
Spesso possiamo trovare set di dati in formato file .tsv. Questi file .tsv hanno valori separati da tabulazione o possiamo dire che ha uno spazio di tabulazione come delimitatore. Tali file possono essere letti utilizzando la stessa funzione .read_csv () da panda e dobbiamo specificare il delimitatore. Ad esempio:
df = pd.read_csv("C:UtentiRahulDesktopExample.tsv", settembre = 't')
Allo stesso modo, altri separatori possono essere utilizzati in base al delimitatore identificato dei nostri dati.
conclusione
È sempre utile controllare come i nostri dati sono archiviati nel nostro set di dati. È necessario comprendere i dati prima di iniziare a lavorarci. Un delimitatore può essere identificato facilmente controllando i dati. Secondo la nostra ispezione, possiamo usare il relativo delimitatore nel parametro sep.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





