Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati.
introduzione
Rilevamento anomalie serie temporali
L'intero processo di rilevamento delle anomalie per un Serie storicheUna serie temporale è un insieme di dati raccolti o misurati in tempi successivi, di solito a intervalli di tempo regolari. Questo tipo di analisi consente di identificare i modelli, Tendenze e cicli dei dati nel tempo. La sua applicazione è ampia, che coprono settori come l'economia, Meteorologia e sanità pubblica, facilitare la previsione e il processo decisionale basato su informazioni storiche.... si svolge in 3 Passi:
- Scomporre le serie temporali nelle variabili sottostanti; Tendenza, stagionalità, residuo.
- Crea soglie superiore e inferiore con un valore di soglia
- Identificare come anomalie i punti dati che sono al di fuori delle soglie.
Argomento di studio
Scarichiamo il set di dati dal sito web del governo di Singapore che è facilmente accessibile. Consumo totale di elettricità nelle famiglie per tipo di abitazione. Il sito web dei dati del governo di Singapore si blocca abbastanza facilmente. Questo set di dati mostra il consumo totale di elettricità delle famiglie per tipo di abitazione (e GWh).
Gestito dall'Autorità per il mercato dell'energia
Frequenza annuale
Fonte (S) Autorità per il mercato dell'energia
Licenza Singapore Open Data License
Installa e carica i pacchetti R
In questo esercizio, lavoreremo con 2 Pacchetti chiave per il rilevamento di anomalie delle serie temporali in R: anomalo e temporizzazione. Questi richiedono che l'oggetto sia creato come una manciata di tempo, quindi caricheremo anche i pacchetti tibble. Per prima cosa installiamo e carichiamo queste librerie.
pacchetto <- C('tidyverso','tibbletime','anomalizzare','orario')
install.packages(pacchetto)
biblioteca(ordinatoverso)
biblioteca(tibbletime)
biblioteca(anomalizzare)
biblioteca(temporizzazione)
Caricare dati
Nel passaggio precedente, abbiamo scaricato il file dei consumi elettrici totali per tipologia di abitazione (e GWh) dal sito web del governo di Singapore. Carichiamo il file CSV in un frame di dati R.
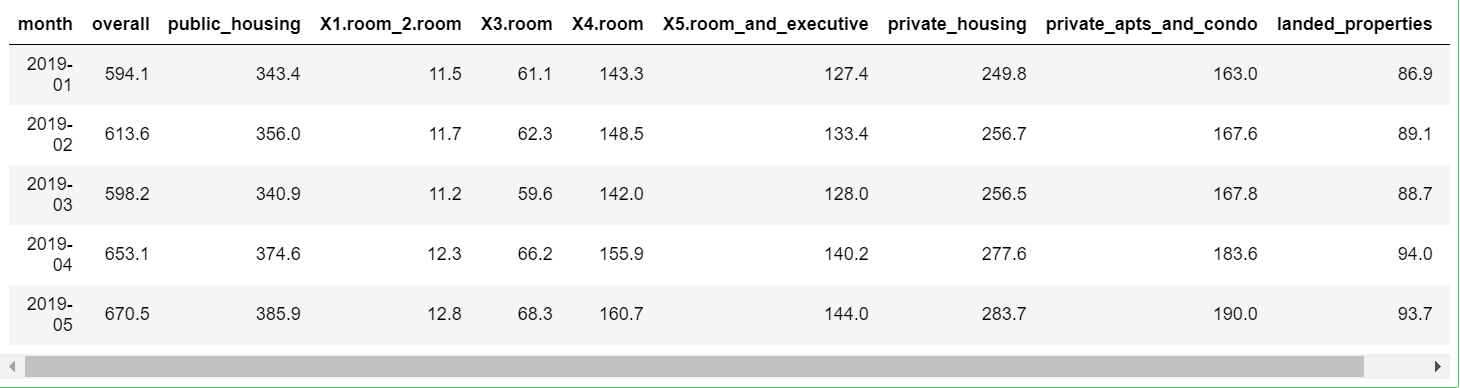
df <- leggi.csv("C:Rilevamento anomalie in Rtotale-consumo-elettricità-domestico.csv")
testa(df,5)
Elaborazione dati
Prima di poter applicare qualsiasi algoritmo di anomalia ai dati, dobbiamo cambiarlo in un formato di data.
La colonna 'mese’ è originariamente in formato fattoriale con molti livelli. Convertiamolo in un tipo di data e selezioniamo solo le colonne pertinenti nel frame di dati.
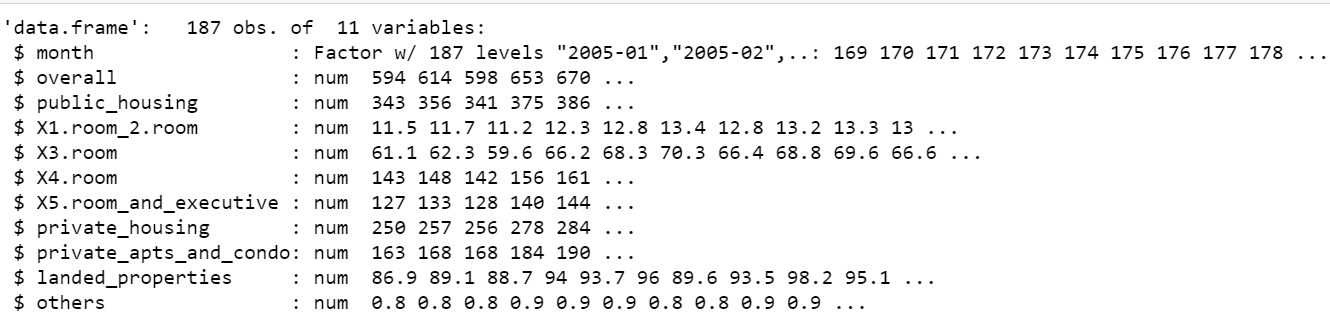
str(df)
# Change Factor to Date format df$month <- impasto(df$mese, "01", set="-") # Select only relevant columns in a new dataframe df$month <- asso. Dattero(df$mese,formato="%Y-%m-%d")
df <- df %>% Selezionare(mese,grembiule)
# Convert df to a tibble
df <- as_tibble(df)
classe(df)
Utilizzo del pacchetto 'anomalize'’
Il pacchetto R' anomalize’ consente a un flusso di lavoro di rilevare anomalie nei dati. Le funzioni principali sono time_decompose (), anomalia (), e time_recompose ().
df_anomalized <- df %>%
time_decompose(grembiule, merge = VERO) %>%
anomalizzare(resto) %>%
time_recompose()
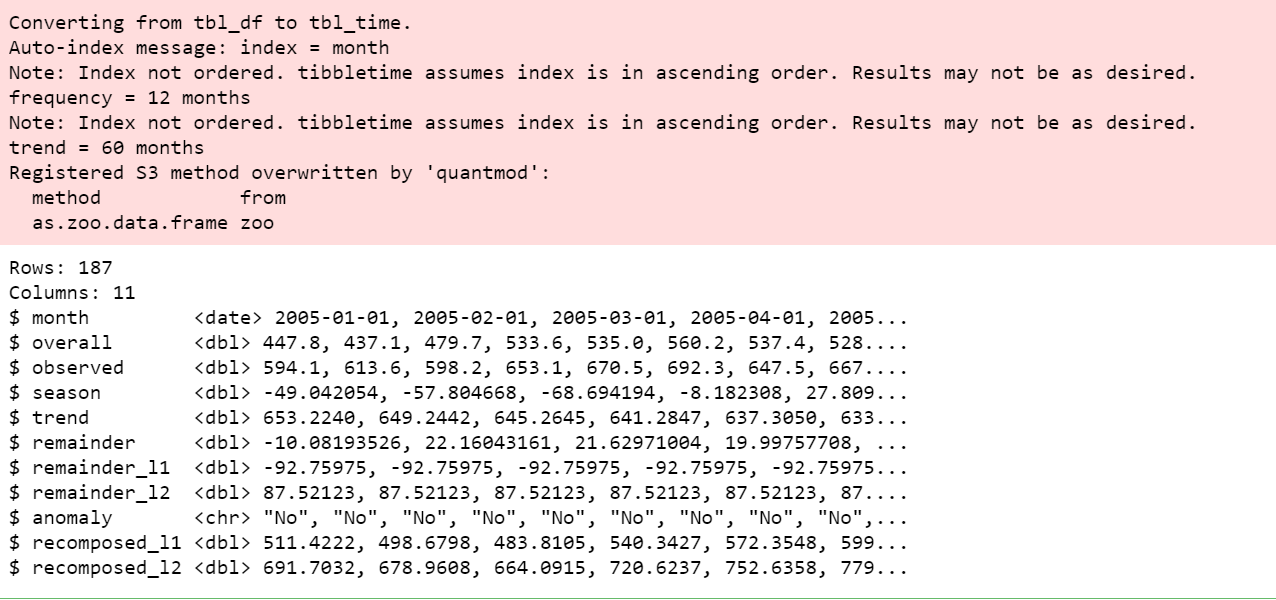
df_anomalized %>% Intravedere()
Visualizza le anomalie
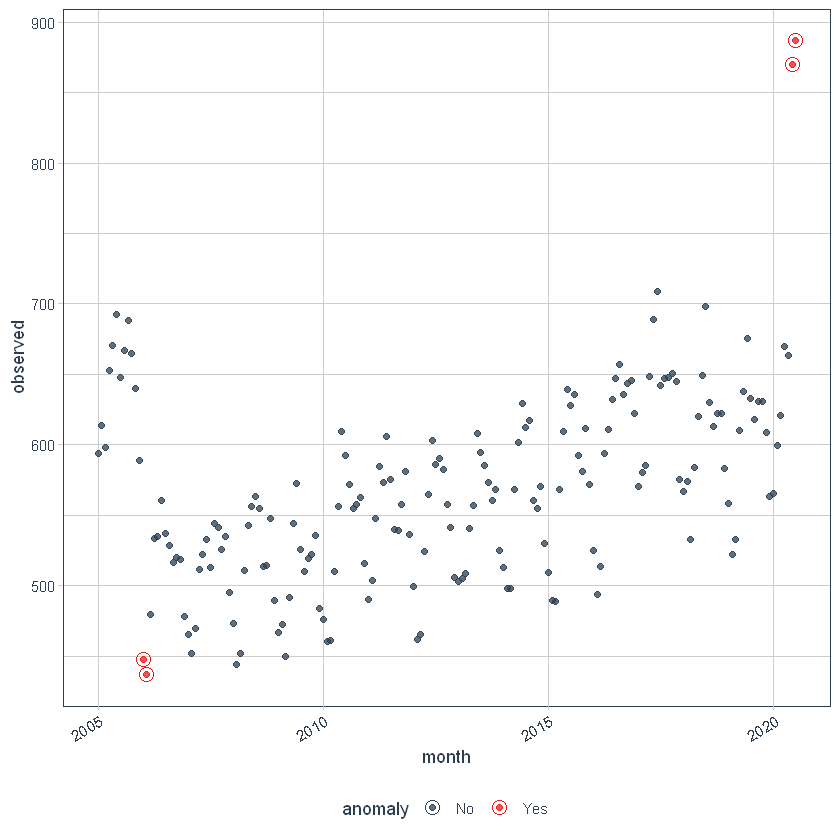
Possiamo quindi visualizzare le anomalie utilizzando il trama_anomalie () funzione.
df_anomalized %>% trama_anomalie(ncol = 3, punti_alpha = 0.75)
Regolazione dell'andamento e della stagionalità
Con anomalize, è facile apportare modifiche perché tutto è fatto con una data o un timestamp, in modo da poter selezionare in modo intuitivo gli incrementi per i periodi di tempo che hanno senso (ad esempio, "5 minuti" o "1 mese").
Primo, nota che una frequenza e una tendenza sono state selezionate automaticamente per noi. Questo è di progettazione. La frequenza degli argomenti = “auto” e tendenza = “auto” sono i valori predefiniti. Possiamo visualizzare questa scomposizione usando plot_anomaly_decomposition ().
p1 <- df_anomalized %>%
plot_anomaly_decomposition() +
ggtitle("Freq/Trend = 'auto'")
p1
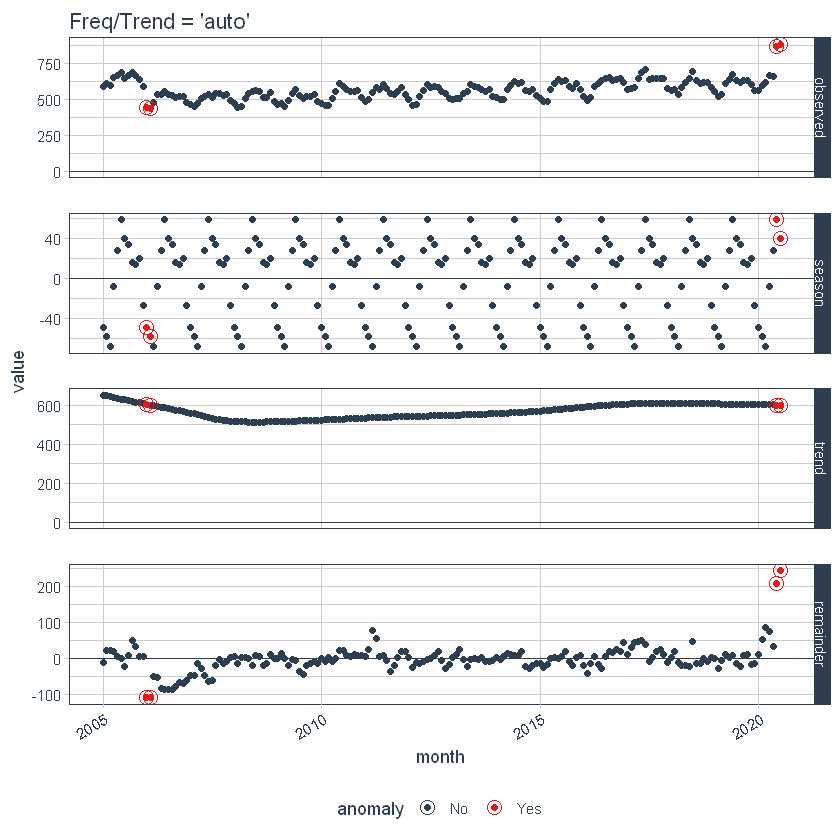
Quando è usato “auto”, get_time_scale_template () viene utilizzato per determinare la frequenza logica e gli intervalli di tendenza in base alla scala dei dati. Puoi scoprire la logica:
get_time_scale_template()

Ciò implica che se la scala è 1 giorno (il che significa che la differenza tra ciascun punto dati è 1 giorno), quindi la frequenza sarà 7 giorni (oh 1 settimana) e la tendenza sarà in giro 90 giorni (oh 3 mesi). Questa logica può essere facilmente regolata in due modi: Impostazione dei parametri locali e dei parametri globali.
Regolazione dei parametri locali
La regolazione del parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... viene effettuato regolando i parametri in base. Prossimo, adeguiamo la tendenza = “2 settimane”, il che lo rende una tendenza piuttosto sovradimensionata.
p2 <- df %>%
time_decompose(grembiule,
frequenza = "auto",
tendenza = "2 settimane") %>%
anomalizzare(resto) %>%
plot_anomaly_decomposition() +
ggtitle("Tendenza = 2 Settimane (Locale)")
# Show plots
p1
p2
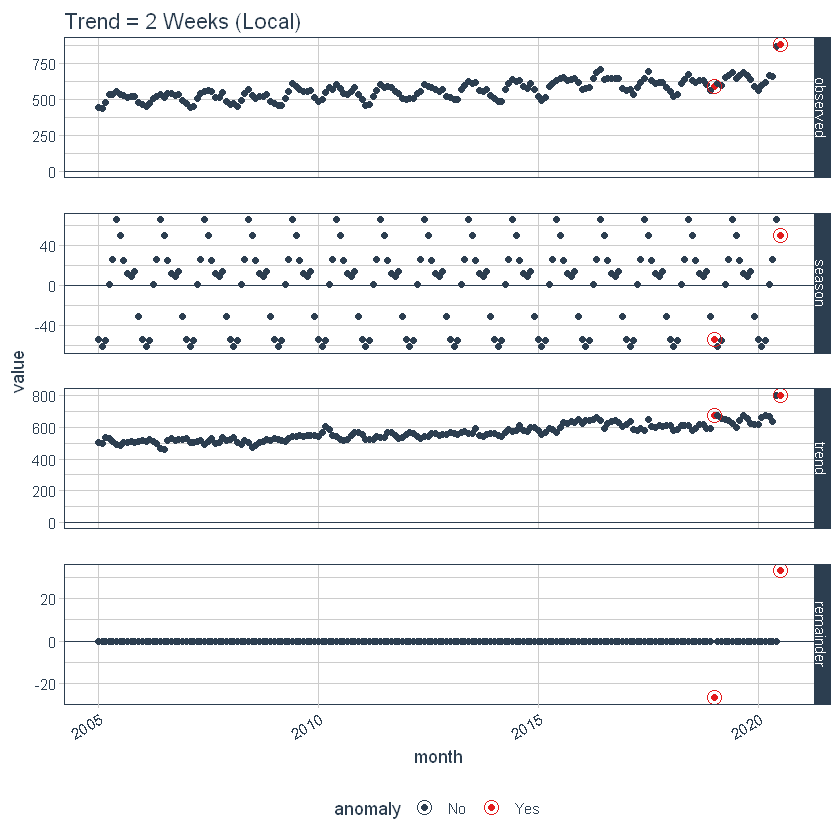
Impostazione del parametro globale
Possiamo anche regolare globalmente usando set_time_scale_template () per aggiornare il modello predefinito a quello che preferiamo. Cambieremo la tendenza da “3 mesi” un “2 settimane” per la scala temporale = “giorno”. Usare time_scale_template () per recuperare il modello di timeline con cui inizia l'anomalia, muto () il campo di tendenza nella posizione desiderata e utilizzare set_time_scale_template () per aggiornare il modello nelle opzioni globali. Possiamo recuperare il modello aggiornato usando get_time_scale_template () per verificare che la modifica sia stata eseguita correttamente.
time_scale_template() %>%
mutare(trend = ifelse(time_scale == "giorno", "2 settimane", tendenza)) %>%
set_time_scale_template()
get_time_scale_template()

Finalmente, possiamo rieseguire il time_decompose () con valori predefiniti, e possiamo vedere che la tendenza è "2 settimane".
p3 <- df %>%
time_decompose(grembiule) %>%
anomalizzare(resto) %>%
plot_anomaly_decomposition() +
ggtitle("Tendenza = 2 Settimane (Globale)")
p3
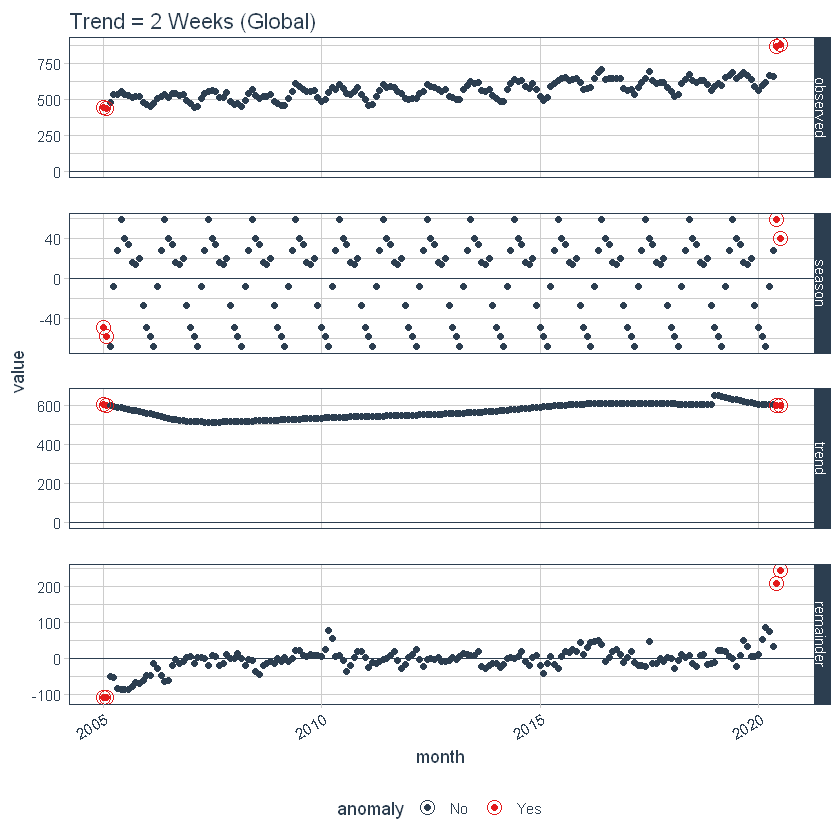
Ripristina i valori predefiniti del modello della timeline ai valori predefiniti originali.
time_scale_template() %>%
set_time_scale_template()
# Verify the change
get_time_scale_template()

Estrarre i punti dati anomali
Ora, possiamo estrarre i punti dati effettivi che sono anomalie. Per quello, È possibile eseguire il codice riportato di seguito.
df %>% time_decompose(grembiule) %>% anomalizzare(resto) %>% time_recompose() %>% filtro(anomalia == 'Sì')

Regolazione di alfa e valori massimi
il alfa e max_anoms sono i due parametri che controllano la proprietà anomalia () funzione. h
Alfa
Possiamo regolare l'alfa, impostato su 0.05 predefinito. Per impostazione predefinita, le bande coprono solo l'esterno dell'intervallo.
p4 <- df %>%
time_decompose(grembiule) %>%
anomalizzare(resto, alfa = 0.05, max_anoms = 0.2) %>%
time_recompose() %>%
trama_anomalie(time_recomposed = VERO) +
ggtitle("alfa = 0.05")
#> frequenza = 7 days
#> tendenza = 91 days
p4
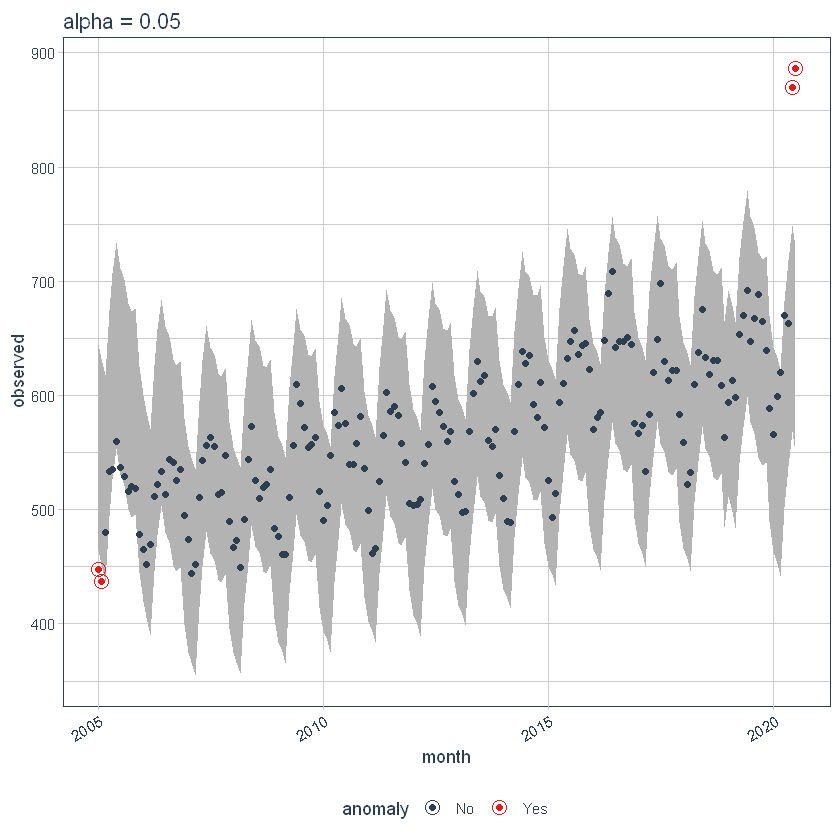
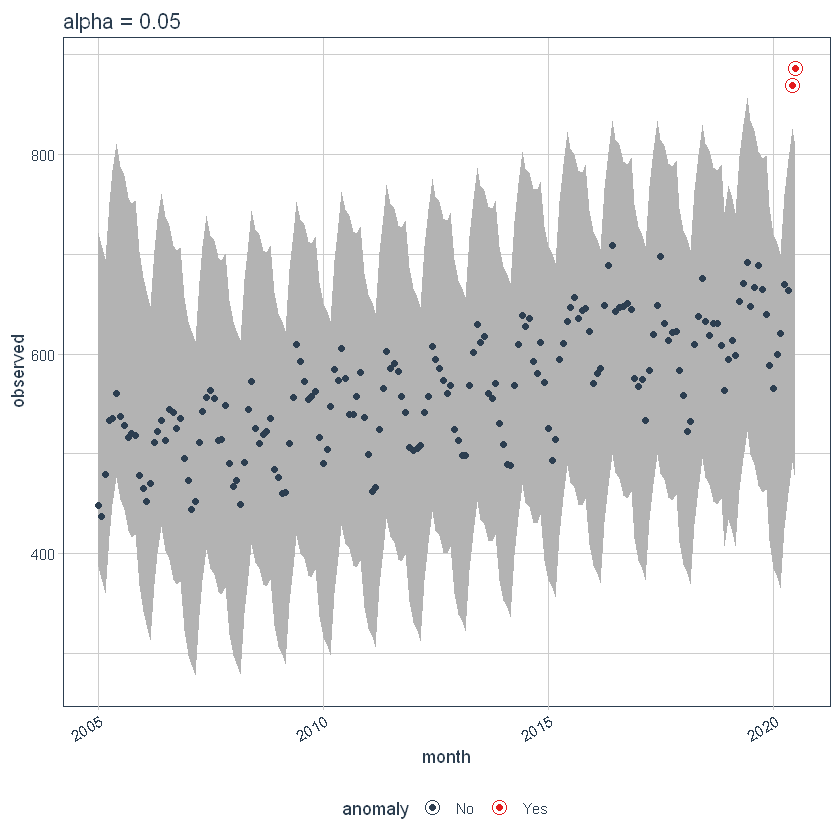
Se diminuiamo l'alfa, aumenta le bande, il che rende più difficile essere un outlier. Qui, puoi vedere che le band sono diventate due volte più grandi.
P5 <- df %>%
time_decompose(grembiule) %>%
anomalizzare(resto, alfa = 0.025, max_anoms = 0.2) %>%
time_recompose() %>%
trama_anomalie(time_recomposed = VERO) +
ggtitle("alfa = 0.05")
#> frequenza = 7 days
#> tendenza = 91 days
p5
Max Anoms
il max_anoms Il parametro viene utilizzato per controllare la percentuale massima di dati che possono essere un'anomalia. Regoliamo alfa = 0.3 in modo che praticamente qualsiasi cosa sia un'anomalia. Ora proviamo un confronto tra max_anoms = 0.2 (20% di anomalie consentite) e max_anoms = 0.05 (5% di anomalie consentite).
P6 <- df %>%
time_decompose(grembiule) %>%
anomalizzare(resto, alfa = 0.3, max_anoms = 0.2) %>%
time_recompose() %>%
trama_anomalie(time_recomposed = VERO) +
ggtitle("20% Anomalie")
#> frequenza = 7 days
#> tendenza = 91 days
p7 <- df %>%
time_decompose(grembiule) %>%
anomalizzare(resto, alfa = 0.3, max_anoms = 0.05) %>%
time_recompose() %>%
trama_anomalie(time_recomposed = VERO) +
ggtitle("5% Anomalie")
#> frequenza = 7 days
#> tendenza = 91 days
p6
p7
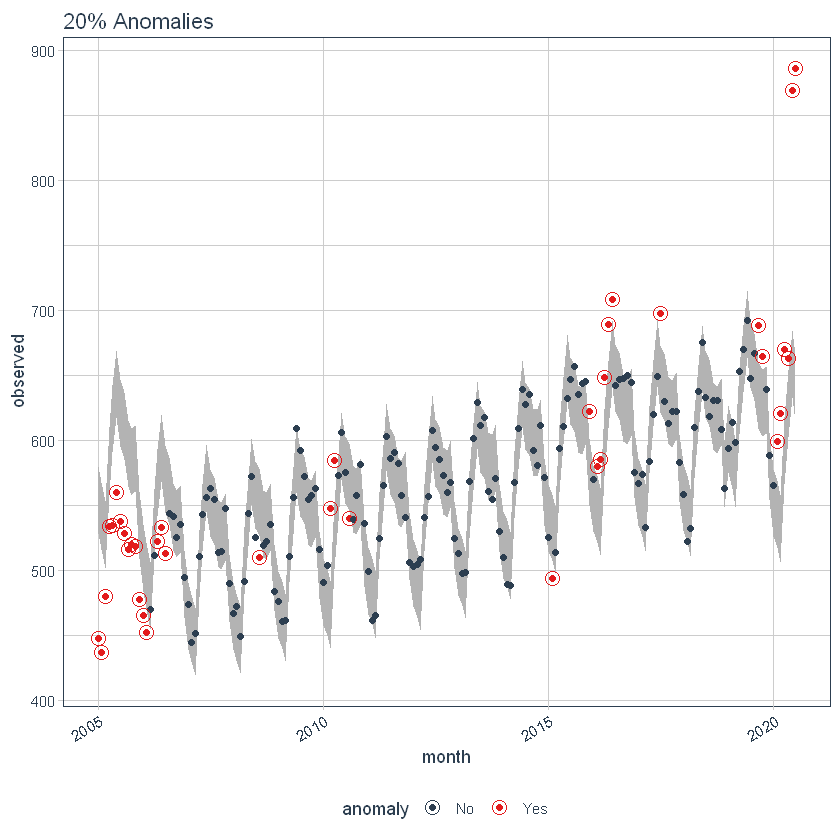
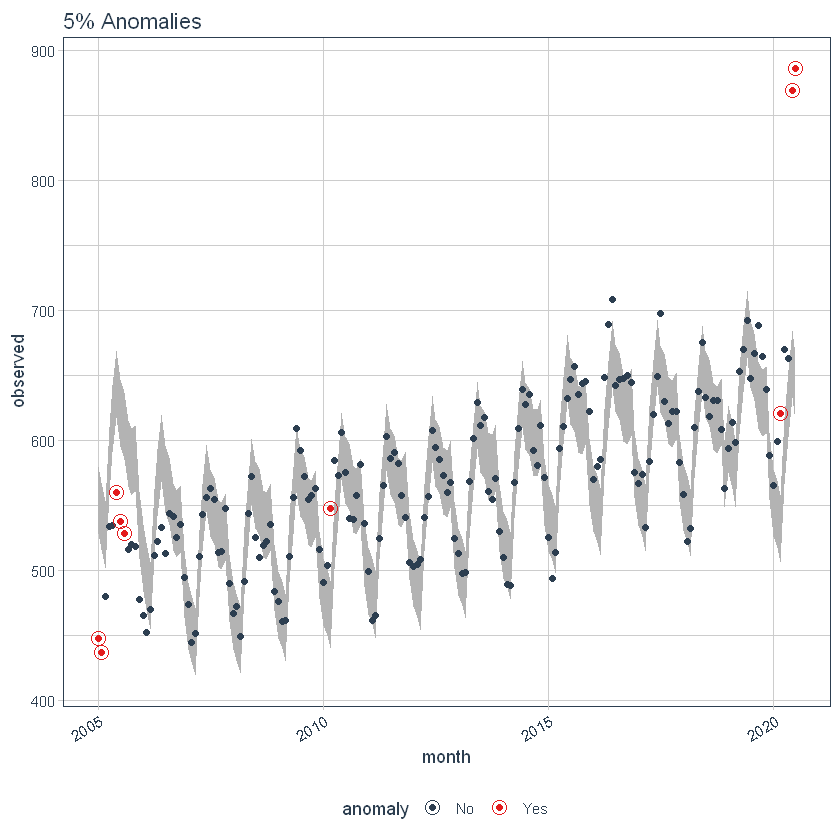
Utilizzo del pacchetto 'timetk’
È un toolkit per lavorare con serie temporali in R, per tracciare, discutere e presentare i dati delle serie temporali degli ingegneri per fare previsioni e previsioni di machine learning.
Visualizzazione interattiva delle anomalie
Qui, timetk La funzione plot_anomaly_diagnostics () consente di modificare alcuni dei parametri al volo.
df %>% temporizzazione::plot_anomaly_diagnostics(mese,grembiule, .facet_ncol = 2)
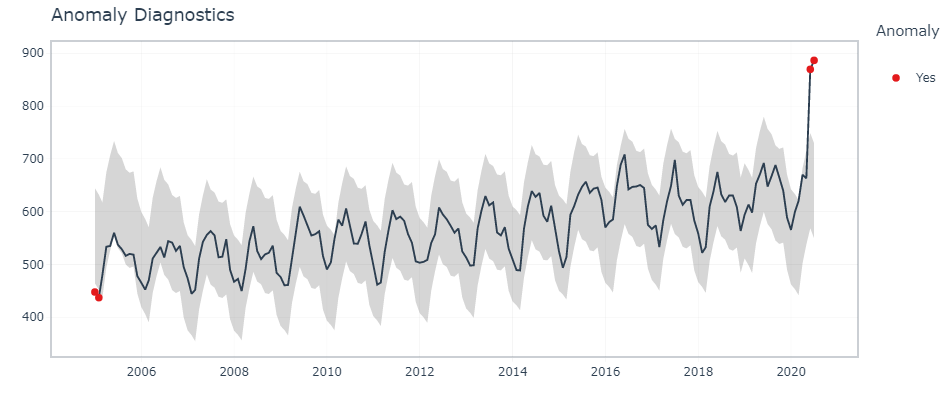
Rilevamento interattivo delle anomalie
Per trovare i punti dati esatti che sono anomalie, noi usiamo tk_anomaly_diagnostics () funzione.
df %>% temporizzazione::tk_anomaly_diagnostics(mese, grembiule) %>% filtro(anomalia=='Sì')

conclusione
In questo articolo, abbiamo visto alcuni dei pacchetti popolari in R che possono essere utilizzati per identificare e visualizzare le anomalie in una serie temporale. Per fornire un po' di chiarezza sulle tecniche di rilevamento delle anomalie in R, abbiamo fatto un caso di studio su un set di dati pubblicamente disponibile. Esistono altri metodi per rilevare valori anomali e possono anche essere esplorati.





