Panoramica
- Approccio passo dopo passo all'esecuzione dell'EDA
- Risorse come i blog, MOOCS per familiarizzare con EDA
- Acquisire familiarità con varie tecniche di visualizzazione dei dati, grafici e diagrammi.
- Dimostrazione di alcuni passaggi con lo snippet di codice Python
Cos'è che differenzia un professionista della scienza dei dati dall'altro??
Non è apprendimento automatico, Non è apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute..., non è sql, è l'analisi esplorativa dei dati (EDA). Quanto è buono uno con l'identificazione del modello? / tendenze nascoste nei dati e quanto siano preziose le informazioni, è ciò che distingue i professionisti dei dati.

1. Cos'è l'analisi esplorativa dei dati?
L'analisi dei dati esplorativi è un approccio per analizzare i set di dati per riassumerne le caratteristiche principali, spesso utilizzando grafici statistici e altri metodi di visualizzazione dei dati.
EDA aiuta i professionisti della scienza dei dati in diversi modi: –
1 Ottieni una migliore comprensione dei dati
2 Identifica vari modelli di dati
3 Comprendere meglio l'affermazione del problema
[ Nota: il set di datiun "set di dati" o dataset è una raccolta strutturata di informazioni, che può essere utilizzato per l'analisi statistica, Apprendimento automatico o ricerca. I set di dati possono includere variabili numeriche, categorico o testuale, e la loro qualità è fondamentale per ottenere risultati affidabili. Il suo utilizzo si estende a varie discipline, come la medicina, Economia e scienze sociali, facilitare il processo decisionale informato e lo sviluppo di modelli predittivi.... in this blog is being opted as iris dataset]
2. Verifica dei dettagli introduttivi sui dati
Il primo e più importante passaggio di qualsiasi analisi dei dati, dopo aver caricato il file di dati, dovrebbe consistere nel controllare alcuni dettagli introduttivi. Che cosa, no. di colonne, no. di righe, tipi di funzionalità (categoriale o numerica), tipi di dati di immissione di colonna.
Frammento di codice Python
data.info ()
Indice di intervallo: 150 Biglietti, 0 un 149
colonne di dati (5 colonne in totale):
# Colonna Tipo di conteggio non nullo
– —— ————– —–
0 sepal_lunghezza 150 non null float64
1 larghezza_sepalo 150 float64 non nullo
2 petalo_lunghezza 150 non null float64
3 larghezza_petalo 150 non null float64
4 specie 150 oggetto non nullo
tipi d: float64 (4), oggetto (1)
utilizzo della memoria: 6.0+ KB
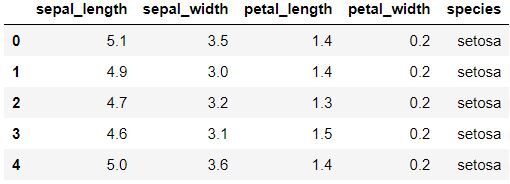
data.head () Per visualizzare le prime cinque righe
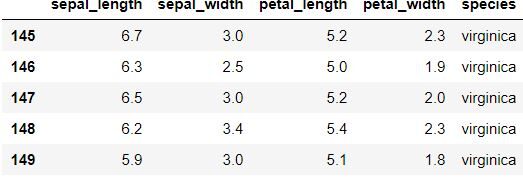
coda.dati () per visualizzare le ultime cinque righe
3. prospettiva statistica
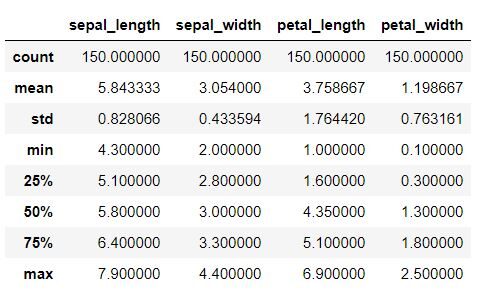
Questo passaggio dovrebbe essere fatto per ottenere dettagli su vari dati statistici come la media, deviazione standard, medianoLa mediana è una misura statistica che rappresenta il valore centrale di un insieme di dati ordinati. Per calcolarlo, I dati sono organizzati dal più basso al più alto e viene identificato il numero al centro. Se c'è un numero pari di osservazioni, I due valori fondamentali sono mediati. Questo indicatore è particolarmente utile nelle distribuzioni asimmetriche, poiché non è influenzato da valori estremi...., valore massimo, valore minimo.
Frammento di codice Python
dati.descrivi ()
4. Pulizia dei dati
Questo è il passaggio più importante in EDA che comporta la rimozione di righe / colonne duplicate, riempi le voci vuote con valori come media / mediana dei dati, rimuovere più valori, rimuovere le voci nulle
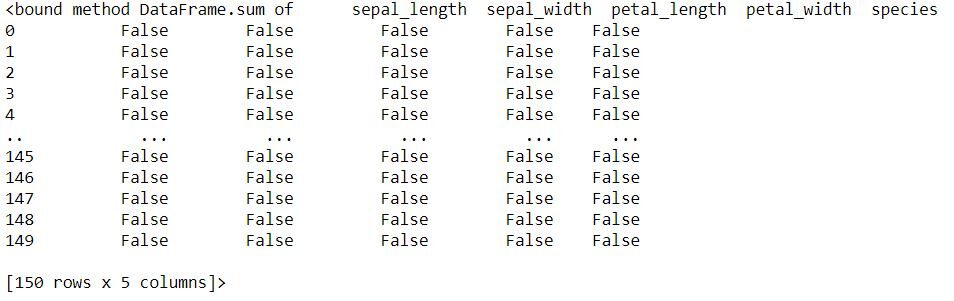
Controllo input nullo
Frammento di codice Python
data.IsNull (). sum da el número de valores perdidos para cada variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi....
Rimuovere le voci nulle
Frammento di codice Python
data.dropna (asse = 0, al posto = vero) Se sono presenti voci nulle
Riempi i valori invece di input nulli (se è una funzione numerica)
I valori possono essere meschini, la mediana o qualsiasi numero intero
Frammento di codice Python
dati[“sepal_lunghezza”].riempire (valore = dati[“sepal_lunghezza”].Significare (), al posto = vero) se è presente un input nullo
Controllo duplicato
Frammento di codice Python
data.duplicato (). somma () restituisce il numero totale di voci duplicate
puoi personalizzarlo in base alle tue particolari esigenze per comunicare il messaggio desiderato
Frammento di codice Python
data.drop_duplicates (al posto = vero)
5. Visualizzazione dati
La visualizzazione dei dati è il metodo per convertire i dati grezzi in una forma visiva., come mappa o grafico, per rendere i dati più facili da capire ed estrarre informazioni utili..
L'obiettivo principale della visualizzazione dei dati è inserire grandi set di dati in una rappresentazione visiva.. È uno dei passaggi importanti e facili quando si tratta di scienza dei dati.
Puoi fare riferimento al blog qui sotto per maggiori dettagli sulla visualizzazione dei dati.
Sono disponibili vari tipi di analisi di visualizzazione:
un. Analisi invariate:
Questo mostra ogni osservazione / distribuzione dei dati su una singola variabile di dati.. Se puede mostrar con la ayuda de varios diagramas como Diagramma di dispersioneIl grafico a dispersione è uno strumento grafico utilizzato in statistica per visualizzare la relazione tra due variabili. Consiste in un insieme di punti in un piano cartesiano, dove ogni punto rappresenta una coppia di valori corrispondenti alle variabili analizzate. Questo tipo di grafico consente di identificare i modelli, Tendenze e possibili correlazioni, facilitare l'interpretazione dei dati e il processo decisionale sulla base delle informazioni visive presentate...., diagramma a linee, diagramma dell'istogramma (astratto), box plotDiagrammi a scatola, Conosciuto anche come diagrammi a scatola e baffi, sono strumenti statistici che rappresentano la distribuzione di un dataset. Questi diagrammi mostrano la mediana, quartili e valori anomali, Consentire la visualizzazione della variabilità e della simmetria dei dati. Sono utili nel confronto tra diversi gruppi e nell'analisi esplorativa, Rendendo più facile identificare tendenze e modelli nei dati...., diagramma di violinoIl diagramma del violino è una rappresentazione grafica che combina le caratteristiche di un boxplot e di un grafico di densità. Utilizzato per visualizzare la distribuzione di un set di dati, mostrando sia la mediana che la variabilità attraverso la loro forma, che assomiglia a un violino. Questo tipo di grafico è molto utile nell'analisi statistica, poiché consente di confrontare più distribuzioni in modo chiaro ed efficace...., eccetera.
B. Analisi bivariata:
Le schermate di analisi bivariate vengono eseguite per rivelare la relazione tra due variabili di dati. Può anche essere mostrato con l'aiuto di grafici a dispersione, istogrammiGli istogrammi sono rappresentazioni grafiche che mostrano la distribuzione di un set di dati. Sono costruiti dividendo l'intervallo di valori in intervalli, oh "Bidoni", e il conteggio della quantità di dati che cadono in ogni intervallo. Questa visualizzazione consente di identificare i modelli, tendenze e variabilità dei dati in modo efficace, facilitare l'analisi statistica e il processo decisionale informato in varie discipline...., mappe di calore, box plot, diagrammi di violino, eccetera.
C. Analisi multivariabile:
Analisi multivariata, Come suggerisce il nome, vengono visualizzati per rivelare la relazione tra più di due variabili di dati.
Diagrammi a dispersione, istogrammi, box plot, i grafici fiddle possono essere utilizzati per l'analisi multivariata
diversi appezzamenti
Di seguito sono riportati alcuni dei grafici che possono essere implementati per l'analisi univariata, bivariato e multivariato
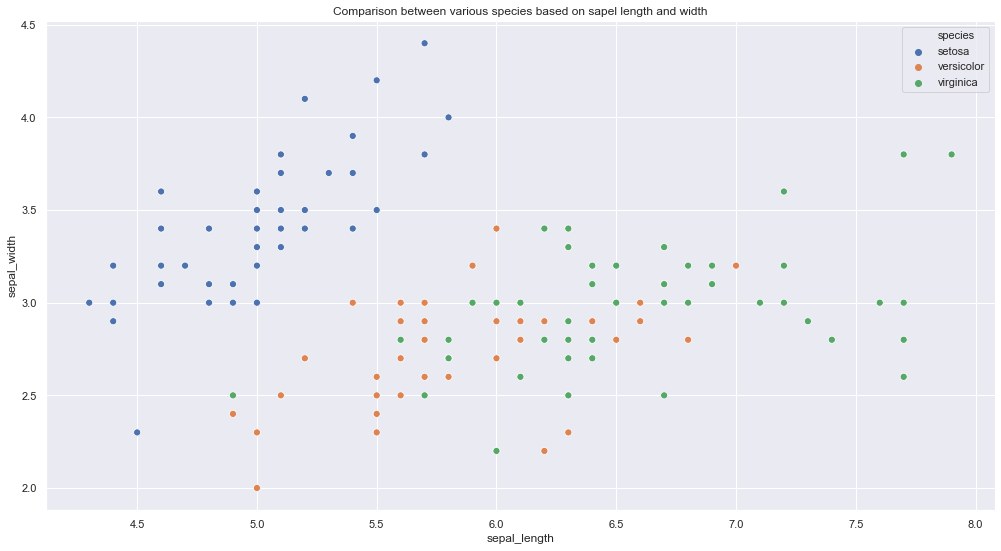
un. Grafico a dispersioneUn grafico a dispersione è una rappresentazione visiva che mostra la relazione tra due variabili numeriche utilizzando punti su un piano cartesiano. Ogni asse rappresenta una variabile, e la posizione di ciascun punto indica il suo valore in relazione ad entrambi. Questo tipo di grafico è utile per identificare i modelli, Correlazioni e tendenze nei dati, facilitare l'analisi e l'interpretazione delle relazioni quantitative....
Frammento di codice Python
plt.figure (dimensione del fico = (17,9))
plt.titolo (‘Confronto tra specie diverse secondo la lunghezza e la larghezza del sapel’)
sns.scatterplot (dati['lunghezza_sepalo'],dati['larghezza_sepalo'], tono = dati['specie'], s = 50)
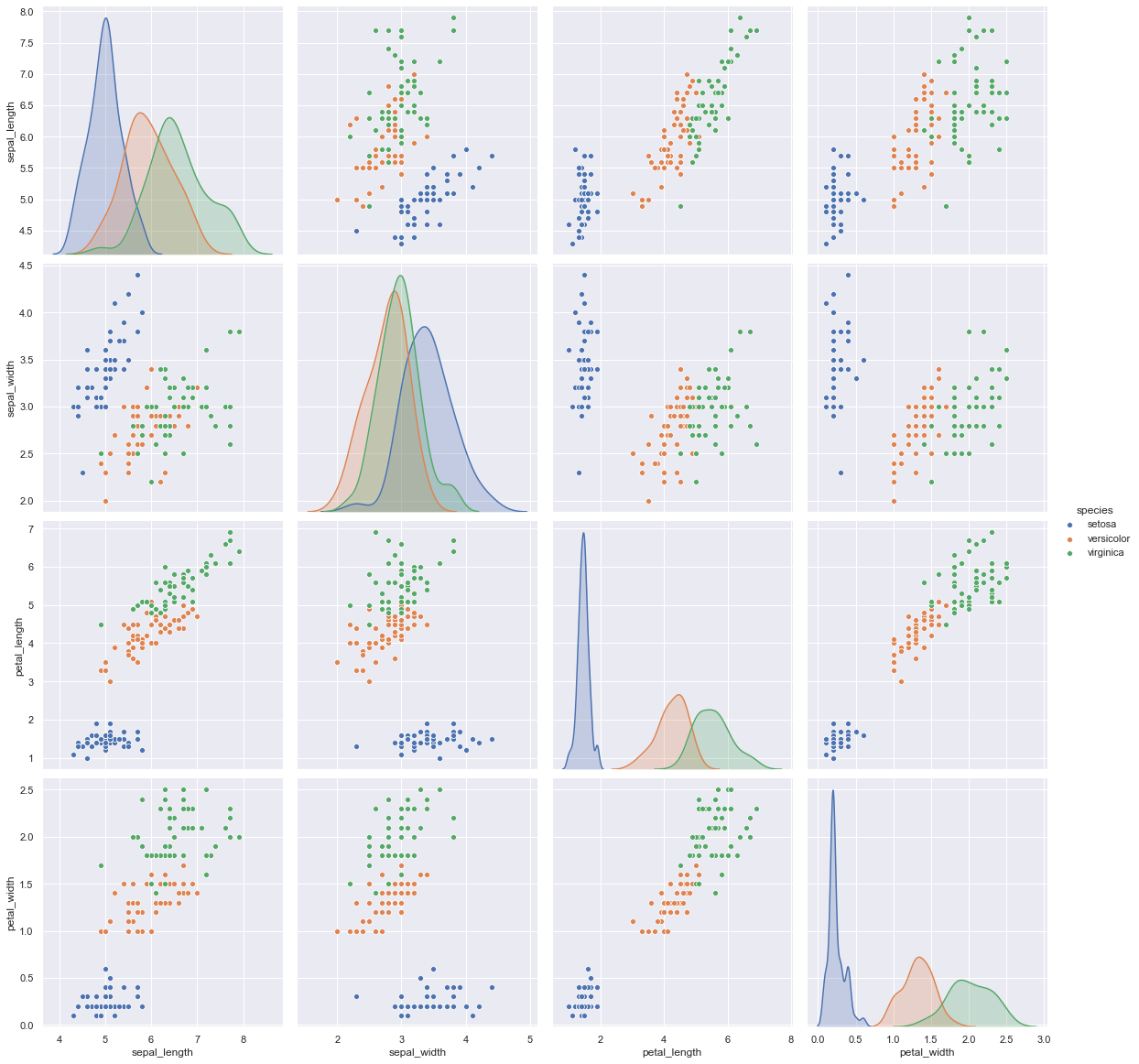
Per analisi multivariate
Frammento di codice Python
sns.pairplot (dati, tonalità = "specie", altezza = 4)
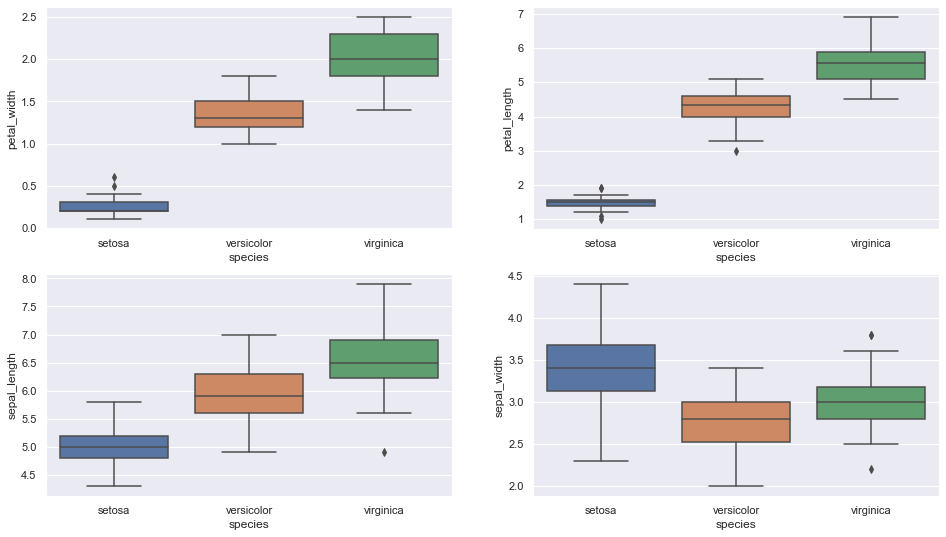
B. Trama scatola
Box plot per vedere come è distribuita la caratteristica categoriale “Specie” con le altre quattro variabili di input
Frammento di codice Python
Fig, assi = plt.sottotrame (2, 2, dimensione del fico = (16,9))
sns.boxplot (y = “larghezza_petalo”, x = “specie”, dati = dati_iris, oriente = 'v', ascia = assi[0, 0])
sns.boxplot (y = “petalo_lunghezza”, x = “specie”, dati = dati_iris, oriente = 'v', ascia = assi[0, 1])
sns.boxplot (y = ”lunghezza sepalo”, x = “specie”, dati = dati_iris, oriente = 'v', ascia = assi[1, 0])
sns.boxplot (y = “larghezza_sepalo”, x = “specie”, dati = dati_iris, oriente = 'v', ascia = ejes[1, 1])
plt.mostra ()
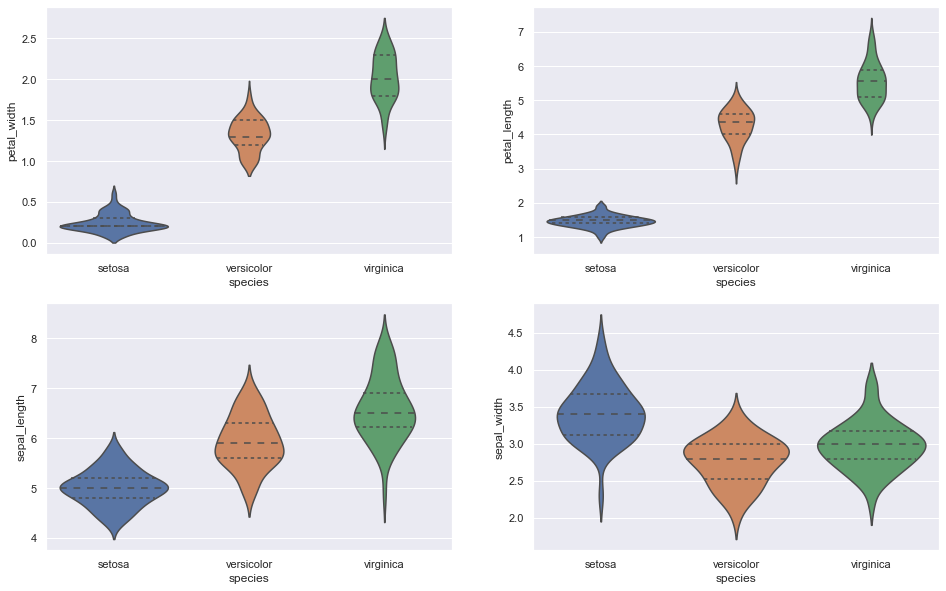
C. Cornice per violino
Più informativo rispetto al box plot e mostra la distribuzione completa dei dati.
Frammento di codice Python
Fig, assi = plt.sottotrame (2, 2, dimensione del fico = (16,10))
sns.violinplot (y = ”larghezza_petalo”, x = “specie”, dati = dati_iris, oriente = 'v', ascia = assi[0, 0], interno = 'quartile')
sns.violinplot (y = “petalo_lunghezza”, x = “specie”, dati = dati_iris, oriente = 'v', ascia = ejes[0, 1], interno = 'quartile')
sns.violinplot (y = ”lunghezza sepalo”, x = “specie”, dati = dati_iris, oriente = 'v', ascia = assi[1, 0], interno = 'quartile')
sns.violinplot (y = ”larghezza_sepalo”, x = “specie”, dati = dati_iris, oriente = 'v', ascia = assi[1, 1], interno = 'quartile')
plt.mostra ()
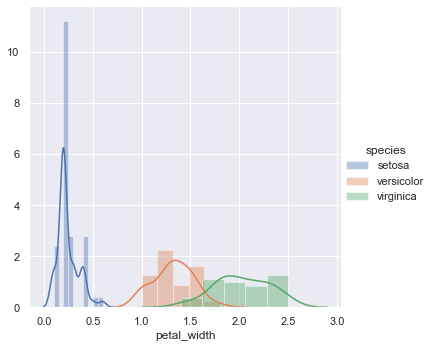
D. istogrammi
Può essere utilizzato per visualizzare la funzione di densità di probabilità (PDF)
Frammento di codice Python
sns.FacetGrid (iris_data, tonalità = "specie", altezza = 5)
.carta geografica (sns.distplot, “larghezza_petalo”)
.aggiungi_leggenda ();
Con questo chiudo questo blog..
Ciao a tutti, Namaste
Il mio nome è Pranshu Sharma e sono un appassionato di data science
Grazie mille per aver dedicato del tuo tempo prezioso a leggere questo blog.. Sentiti libero di segnalare eventuali errori (Dopotutto, sono un apprendista) e fornire i commenti corrispondenti o lasciare un commento.
Dhanyvaad !!
Feedback:
E-mail: [e-mail protetta]
Puoi fare riferimento al blog menzionato di seguito per familiarizzare con l'analisi esplorativa dei dati.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





