Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
brutta copia. EDA è il processo di indagine del set di dati per scoprire modelli e anomalie (Valori atipici) e formulare ipotesi basate sulla nostra comprensione del set di dati.
L'EDA comporta la generazione di statistiche di riepilogo per i dati numerici nel set di dati e la creazione di varie rappresentazioni grafiche per comprendere meglio i dati.. In questo articolo, capiremo l'EDA con l'aiuto di un set di dati di esempio. noi useremo Chiodo idioma (panda biblioteca) per questo scopo.

Importazione di librerie
Inizieremo importando le librerie di cui avremo bisogno per eseguire EDA. Questi includono NumPy, panda, Matplotlib e Seaborn.
importa numpy come np importa panda come pd importa matplotlib.pyplot come plt %matplotlib in linea import seaborn come sns
Leggi i dati
Ora leggeremo i dati da un file CSV in un Pandas DataFrame. Puoi scarica il set di dati per tua referenza.
df = pd.read_csv(r'C:UtentiVipinData AnalyticsStudentiPerformance.csv')
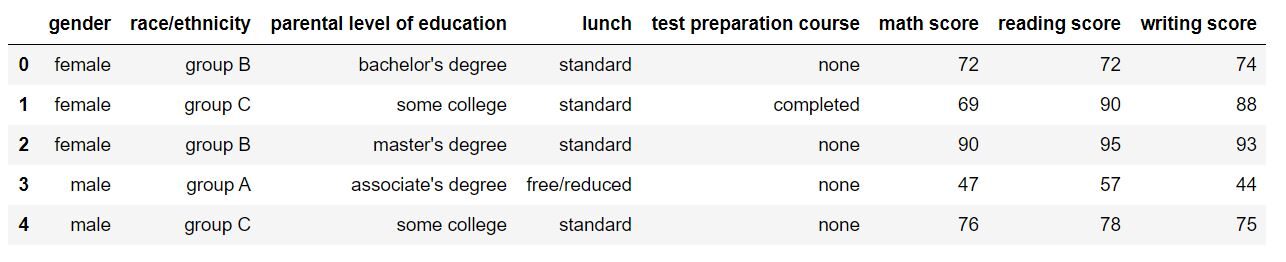
Diamo un'occhiata a come appare il nostro set di dati usando df.head (). L'output dovrebbe essere simile a questo:
Statistiche descrittive
Perfetto! I dati sembrano esattamente come volevamo. Puoi facilmente dirlo semplicemente guardando il set di dati che contiene dati su diversi studenti in una scuola / università e i loro punteggi in 3 soggetti. Iniziamo guardando il parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... Statistiche descrittive per il set di dati. Useremo descrivere () per questo.
df.descrivi(includi="Tutti")
Assegnando all'attributo di inclusione un valore di 'all', ci assicuriamo che anche le caratteristiche categoriali siano incluse nel risultato. L'output DataFrame dovrebbe essere simile a questo:
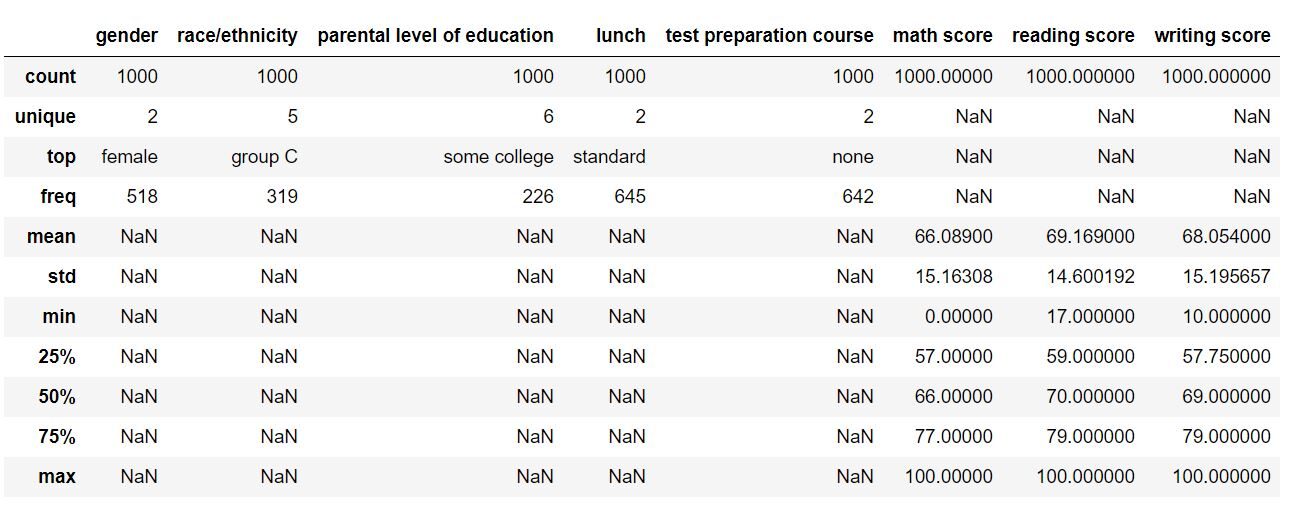
Per parametri numerici, i campi sono stati riempiti come media, la deviazione standard, percentili e massimo. Per caratteristiche categoriali, il conteggio è stato completato, il solo, il superiore (valore più frequente) e la frequenza corrispondente. Questo ci dà un'idea ampia del nostro set di dati.
Attribuzione del valore mancante
Ora controlleremo se mancano i valori. nel nostro set di dati. In caso di biglietti mancanti, li imputeremo con i valori appropriati (modo in caso di caratteristica categoriale e medianoLa mediana è una misura statistica che rappresenta il valore centrale di un insieme di dati ordinati. Per calcolarlo, I dati sono organizzati dal più basso al più alto e viene identificato il numero al centro. Se c'è un numero pari di osservazioni, I due valori fondamentali sono mediati. Questo indicatore è particolarmente utile nelle distribuzioni asimmetriche, poiché non è influenzato da valori estremi.... o media in caso di caratteristica numerica). Useremo la funzione isnull () per questo scopo.
df.isnull().somma()
Questo ci dirà quanti valori mancanti abbiamo in ogni colonna del nostro set di dati. L'uscita (Serie Panda) Dovrebbe sembrare come questo:

Fortunatamente per noi, nessun valore mancante in questo set di dati. Ora procederemo ad analizzare questo set di dati, osservare i modelli e identificare i valori anomali con l'aiuto di grafici e figure.
Rappresentazione grafica
Inizieremo con Analisi invariate. Useremo a grafico a barreIl grafico a barre è una rappresentazione visiva dei dati che utilizza barre rettangolari per mostrare confronti tra diverse categorie. Ogni barra rappresenta un valore e la sua lunghezza è proporzionale ad esso. Questo tipo di grafico è utile per visualizzare e analizzare le tendenze, facilitare l'interpretazione delle informazioni quantitative. È ampiamente utilizzato in varie discipline, come le statistiche, Marketing e ricerca, Grazie alla sua semplicità ed efficacia.... per questo scopo. Osserveremo la distribuzione degli studenti per genere, corsa / etnia, il loro stato di pranzo e se hanno o meno un corso di preparazione all'esame.
plt.sottotrama(221) df['Genere'].value_counts().complotto(tipo='bar', titolo="Genere degli studenti", figsize=(16,9)) plt.xticks(rotazione=0) plt.sottotrama(222) df['razza/etnia'].value_counts().complotto(tipo='bar', titolo="Razza/etnia degli studenti") plt.xticks(rotazione=0) plt.sottotrama(223) df['il pranzo'].value_counts().complotto(tipo='bar', titolo="Stato pranzo degli studenti") plt.xticks(rotazione=0) plt.sottotrama(224) df['corso di preparazione alla prova'].value_counts().complotto(tipo='bar', titolo="Corso di preparazione al test") plt.xticks(rotazione=0) plt.mostra()
L'output dovrebbe essere simile a questo:
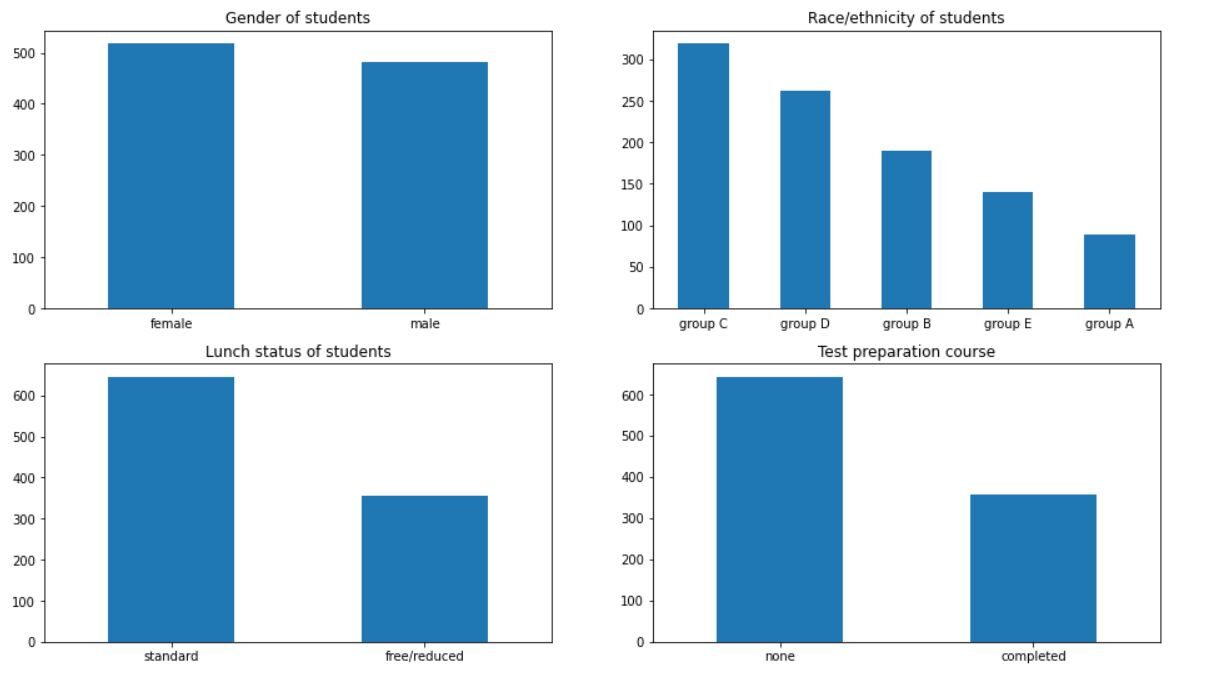
Possiamo dedurre molte cose dal grafico. Ci sono più ragazze a scuola che ragazzi. La maggior parte degli studenti appartiene ai gruppi C e D. Più di 60% degli studenti ha un pranzo standard a scuola. Cosa c'è di più, più di 60% degli studenti non ha frequentato corsi di preparazione agli esami.
Continuando con l'analisi univariata, prossimo, faremo un trama a scatola delle colonne numeriche (punteggio di matematica, punteggio di lettura e punteggio di scrittura) nel set di dati. Un box plot ci aiuta a visualizzare i dati in termini di quartili. Identifica anche valori anomali nel set di dati, se ci fossero. Useremo la funzione boxplot () per questo.
df.boxplot()
L'output dovrebbe essere simile a questo:
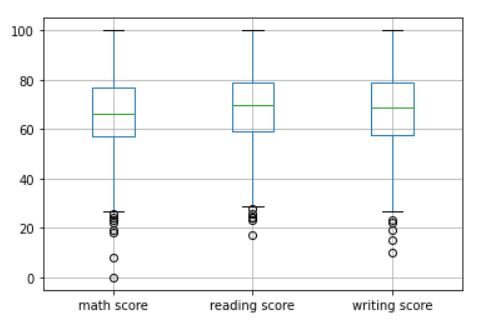
La porzione centrale rappresenta l'intervallo interquartile (IQR). La linea verde orizzontale al centro rappresenta la mediana dei dati. I cerchi vuoti vicino alle code rappresentano valori anomali nel set di dati. tuttavia, poiché è possibile che uno studente ottenga un punteggio estremamente basso in un test, non elimineremo questi valori atipici.
Ora faremo un trama di distribuzione dei punteggi di matematica degli studenti. Un grafico di distribuzione ci dice come sono distribuiti i dati. Useremo la funzione distplot.
sns.distplot(df["punteggio di matematica"])
La trama nell'output dovrebbe essere simile a questa:
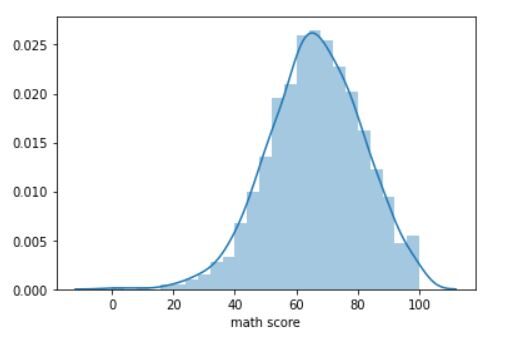
Il grafico rappresenta da vicino una curva a campana perfetta. Il picco è intorno 65 punti, la media dei punteggi di matematica degli studenti nel set di dati. Un grafico di distribuzione simile può essere realizzato anche per la lettura e la scrittura delle partiture..
Ora vedremo la correlazione tra 3 punteggi con l'aiuto di a mappa di caloreun "mappa di calore" è una rappresentazione grafica che utilizza i colori per mostrare la densità dei dati in un'area specifica. Comunemente usato nell'analisi dei dati, Marketing e studi comportamentali, Questo tipo di visualizzazione consente di identificare rapidamente modelli e tendenze. Attraverso variazioni cromatiche, Le mappe di calore facilitano l'interpretazione di grandi volumi di informazioni, aiutando a prendere decisioni informate..... Per questo, useremo la funzione corr () y mappa di calore () per questo esercizio.
corr = df.corr() sns.heatmap(corretto, annot=Vero, quadrato=Vero) plt.yticks(rotazione=0) plt.mostra()
La trama nell'output dovrebbe essere simile a questa:
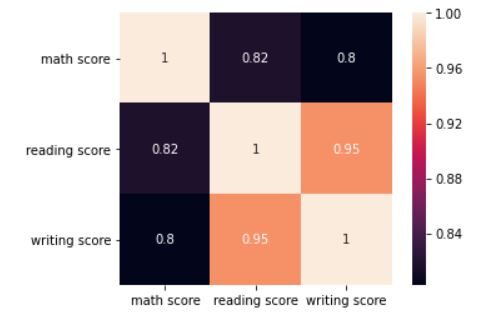
La mappa termica lo mostra 3 i punteggi sono altamente correlati. Il punteggio di lettura ha un coefficiente di correlazione di 0,95 con punteggio di scrittura. Il punteggio di matematica ha un coefficiente di correlazione di 0,82 con il punteggio di lettura e 0,80 con punteggio di scrittura.
Ora passiamo a Analisi bivariata. Ne esamineremo uno trama relazionale it Seaborn. Ci aiuta a capire la relazione tra 2 variabili in diversi sottoinsiemi del set di dati. Cercheremo di capire la relazione tra il punteggio di matematica e il punteggio di scrittura di studenti di sesso diverso.
sns.relplot(x='punteggio matematico', y='punteggio di scrittura', tonalità="Genere", dati=df)
La trama relazionale dovrebbe assomigliare a questa:
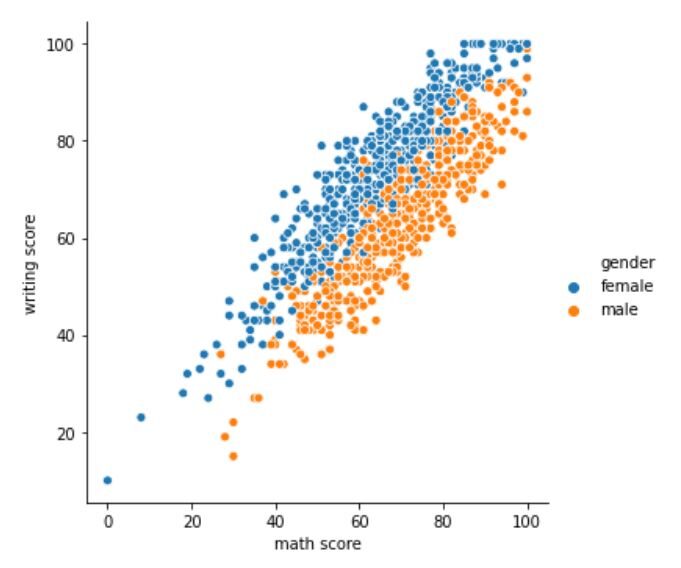
Il grafico mostra una chiara differenza nei punteggi tra studenti maschi e femmine. Per lo stesso punteggio in matematica, le studentesse hanno maggiori probabilità di ottenere punteggi di scrittura più alti rispetto agli studenti maschi. tuttavia, per lo stesso punteggio di scrittura, ci si aspetta che gli studenti maschi ottengano punteggi più alti in matematica rispetto alle studentesse.
I grafici relazionali ci aiutano a eseguire analisi bivariate. Puoi fare riferimento alla documentazione della funzione relplot () it Seaborn qui.
Finalmente, analizzeremo le prestazioni degli studenti in matematica, lettura e scrittura in base al livello di istruzione dei tuoi genitori e al corso di preparazione all'esame. Primo, Diamo un'occhiata all'impatto del livello di istruzione dei genitori sul rendimento scolastico dei loro figli utilizzando a grafico a linee.
df.groupby("livello di istruzione dei genitori")[["punteggio di matematica", 'spartito di lettura', 'spartito di scrittura']].Significare().T.trama(figsize=(12,8))
L'output sarà simile a questo:
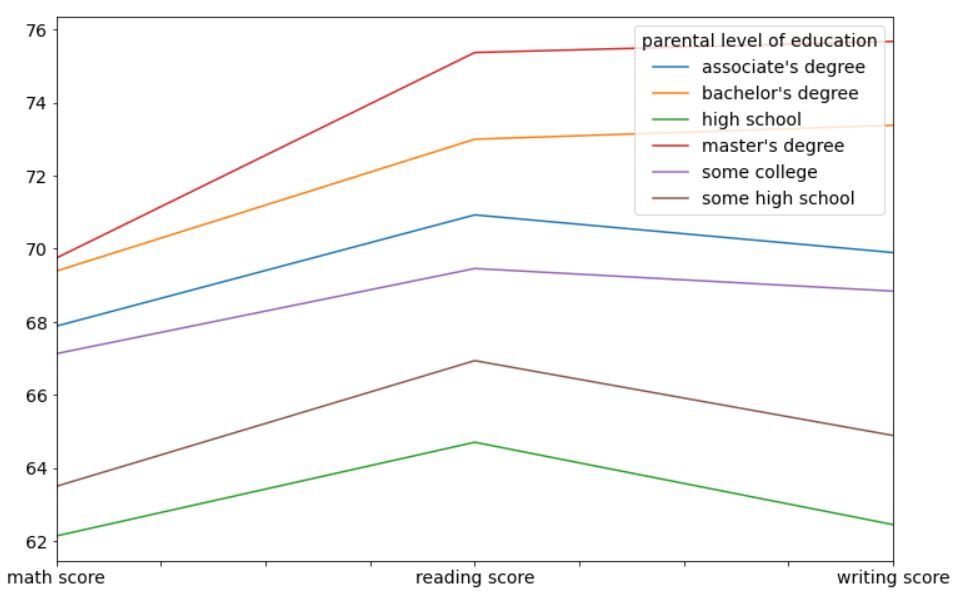
È molto chiaro da questo grafico che gli studenti i cui genitori sono più istruiti di altri (Master, laurea triennale e associata) ottenere risultati migliori in media rispetto agli studenti i cui genitori hanno meno istruzione (Scuola superiore). Questa potrebbe essere una differenza genetica o semplicemente una differenza nell'ambiente domestico degli studenti. I genitori più istruiti hanno maggiori probabilità di spingere i loro studenti verso gli studi.
Al secondo posto, Diamo un'occhiata all'impatto del corso di preparazione al test sulle prestazioni degli studenti utilizzando a grafico a barre orizzontali.
df.groupby('corso di preparazione alla prova')[["punteggio di matematica", 'spartito di lettura', 'spartito di scrittura']].Significare().T.trama(gentile='barh', figsize=(10,10))
L'output dovrebbe essere simile a questo:
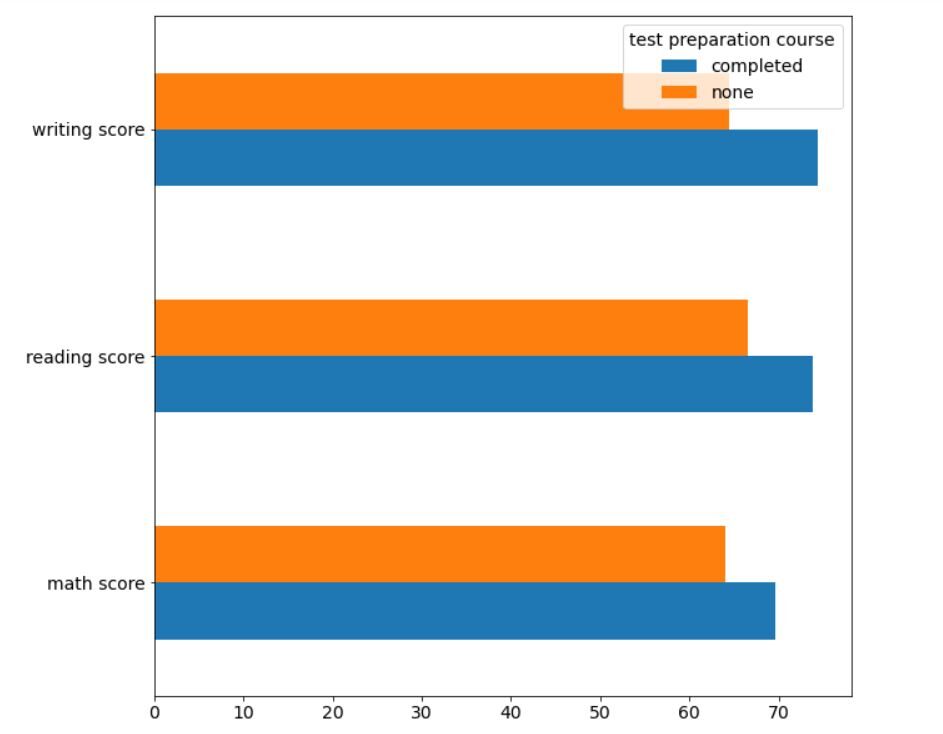
Un'altra volta, è molto chiaro che gli studenti che hanno completato il corso di preparazione all'esame hanno ottenuto risultati migliori, in media, rispetto agli studenti che non hanno optato per il corso.
Note finali
In questo articolo, abbiamo capito il significato di Exploratory Data Analysis (EDA) con l'aiuto di un set di dati di esempio. Vediamo come possiamo analizzare il set di dati, trarne conclusioni e formulare un'ipotesi basata su questo.
L'autore di questo articolo è Vishesh Arora. Puoi connetterti con me su LinkedIn.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





