introduzione
Ciao lettori!
OpenCV – Visione artificiale open source. È uno degli strumenti più utilizzati per l'elaborazione delle immagini e le attività di visione artificiale. Utilizzato in varie applicazioni come il rilevamento dei volti, acquisizione video, tracciare oggetti in movimento, rivelazione di oggetti, al giorno d'oggi nelle applicazioni Covid come il rilevamento delle maschere, distanziamento sociale e molto altro. Se vuoi saperne di più su OpenCV, controllare questo Collegamento.
📌Se vuoi saperne di più sulle librerie Python per l'elaborazione delle immagini, controlla questo link.
📌Se vuoi imparare come elaborare le immagini usando NumPy, controlla questo link.
📌Per altri articoli😉, Clicca qui
In questo blog, Tratterò OpenCV in modo molto dettagliato coprendo alcuni dei compiti più importanti nell'elaborazione delle immagini attraverso l'implementazione pratica. Quindi iniziamo !! ?

Immagine Fonte
Sommario
- Rilevamento dei bordi e gradienti dell'immagine
- Dilatazione, apertura, chiusura ed erosione
- Trasformazione della prospettiva
- Piramidi di immagini
- Ordinare
- scalato, interpolazioni e ridimensionamento
- Soglia, soglia adattativa e binarizzazione
- Affilato
- Macchia
- contorni
- Detección de líneas mediante líneas duras
- Encontrar esquinas
- Contando círculos y elipses

Immagine Fonte
Rilevamento dei bordi e gradienti dell'immagine
Es una de las técnicas más fundamentales e importantes en el procesamiento de imágenes. Verifique el código a continuación para una implementación completa. Per maggiori informazioni, guarda questo Collegamento.
immagine = cv2.imread(«frutta.jpg») immagine = cv2.cvtColor(Immagine, cv2.COLOR_BGR2RGB) Hgt, Wdt,_ = image.shape # Sobel Edges x_sobel = cv2.Sobel(Immagine, cv2. CV_64F, 0, 1, ksize=5) y_sobel = cv2. Sobel(Immagine, cv2. CV_64F, 1, 0, ksize=5) plt.figure(figsize=(20, 20)) plt.sottotrama(3, 2, 1) plt.titolo("Originale") plt.imshow(Immagine) plt.sottotrama(3, 2, 2) plt.titolo("Sobel X") plt.imshow(x_sobel) plt.sottotrama(3, 2, 3) plt.titolo("Sobel Y") plt.imshow(y_sobel) sobel_or = cv2.bitwise_or(x_sobel, y_sobel) plt.sottotrama(3, 2, 4) plt.imshow(sobel_or) laplacian = cv2. Laplaciano(Immagine, cv2. CV_64F) plt.sottotrama(3, 2, 5) plt.titolo("Laplaciano") plt.imshow(laplacian) ## Ci sono due valori: soglia1 e soglia2. ## I gradienti maggiori della soglia2 => considerato come un bordo ## I gradienti inferiori alla soglia1 => considerato non un vantaggio. ## Tali gradienti Valori compresi tra soglia1 e soglia2 => classificati come spigoli o non bordi # The first threshold gradient canny = cv2.Canny(Immagine, 50, 120) plt.sottotrama(3, 2, 6) plt.imshow(Astuto)

Dilatazione, apertura, chiusura ed erosione
Si tratta di due operazioni fondamentali di elaborazione delle immagini. Sono utilizzati per eliminare il rumore, trovare un foro di intensità o un urto in un'immagine e molti altri. Vedere il codice seguente per un'implementazione pratica. Per maggiori informazioni, guarda questo Collegamento.
immagine = cv2.imread('LinuxLogo.jpg')
immagine = cv2.cvtColor(Immagine, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(20, 20))
plt.sottotrama(3, 2, 1)
plt.titolo("Originale")
plt.imshow(Immagine)
kernel = np.ones((5,5), ad esempio uint8)
erosione = cv2.erode(Immagine, kernel, iterazioni = 1)
plt.sottotrama(3, 2, 2)
plt.titolo("Erosione")
plt.imshow(erosione)
dilatazione = cv2.dilata(Immagine, kernel, iterazioni = 1)
plt.sottotrama(3, 2, 3)
plt.titolo("dilatazione")
plt.imshow(dilatazione)
apertura = cv2.morfologiaEx(Immagine, cv2.MORPH_OPEN, kernel)
plt.sottotrama(3, 2, 4)
plt.titolo("Apertura")
plt.imshow(apertura)
chiusura = cv2.morfologiaEx(Immagine, cv2.MORPH_CLOSE, kernel)
plt.sottotrama(3, 2, 5)
plt.titolo("Chiusura")
plt.imshow(chiusura)

Trasformazione della prospettiva
Per ottenere informazioni migliori su un'immagine, possiamo cambiare la prospettiva di un video o di un'immagine. In questa trasformazione, dobbiamo fornire i punti in un'immagine da cui vogliamo prendere informazioni cambiando la prospettiva. En OpenCV, usiamo due funzioni per la trasformazione prospettica getPerspectiveTransform () e più tardi orditoProspettiva (). Verifique el código a continuación para una implementación completa. Per maggiori informazioni, guarda questo Collegamento.
immagine = cv2.imread('scansione.jpg')
immagine = cv2.cvtColor(Immagine, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(20, 20))
plt.sottotrama(1, 2, 1)
plt.titolo("Originale")
plt.imshow(Immagine)
punti_A = np.float32([[320,15], [700,215], [85,610], [530,780]])
points_B = np.float32([[0,0], [420,0], [0,594], [420,594]])
M = cv2.getPerspectiveTransform(punti_A, punti_B)
deformato = cv2.warpPerspective(Immagine, m, (420,594))
plt.sottotrama(1, 2, 2)
plt.titolo("orditoProspettiva")
plt.imshow(deformato)
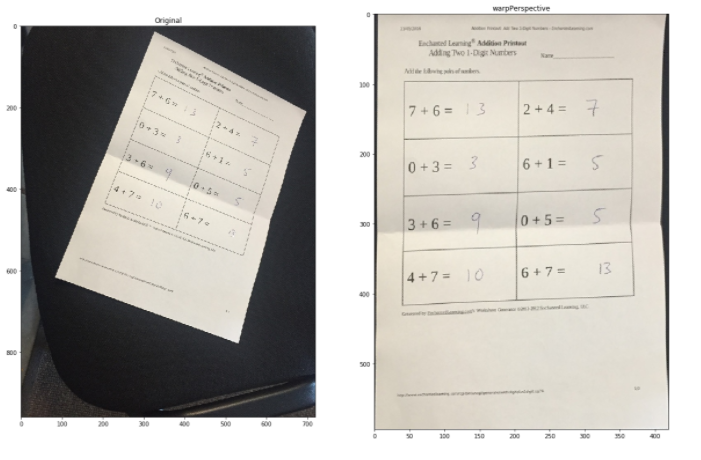
Piramidi di immagini
È una tecnica molto utile quando abbiamo bisogno di scalare nel rilevamento di oggetti. OpenCV utilizza due tipi comuni di piramidi di immagini Gaussiano e Laplaciano piramide. Utilizzare il abitare () e pyrdown () funzione in OpenCV per ridurre o ingrandire un'immagine. Vedere il codice seguente per un'implementazione pratica. Per maggiori informazioni, guarda questo Collegamento.
immagine = cv2.imread('farfalla.jpg')
immagine = cv2.cvtColor(Immagine, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(20, 20))
plt.sottotrama(2, 2, 1)
plt.titolo("Originale")
plt.imshow(Immagine)
più piccolo = cv2.pyrDown(Immagine)
più grande = cv2.pyrUp(più piccoli)
plt.sottotrama(2, 2, 2)
plt.titolo("Più piccoli")
plt.imshow(più piccoli)
plt.sottotrama(2, 2, 3)
plt.titolo("Più grandi")
plt.imshow(più grandi)

Ordinare
È una delle tecniche più importanti e fondamentali nell'elaborazione delle immagini, il ritaglio viene utilizzato per ottenere una parte particolare di un'immagine. Per ritagliare un'immagine. Hai solo bisogno delle coordinate di un'immagine in base alla tua area di interesse. Per un'analisi completa, vedere il seguente codice in OpenCV.
immagine = cv2.imread('messi.jpg')
immagine = cv2.cvtColor(Immagine, cv2.COLOR_BGR2RGB)
plt.figure(
Aigsize=(20, 20))
plt.sottotrama(2, 2, 1)
plt.titolo("Originale")
plt.imshow(Immagine)
Hgt, wdt = immagine.forma[:2]
start_row, start_col = int(Hgt * .25), int(Wdt * .25)
end_row, end_col = int(altezza * .75), int(larghezza * .75)
ritagliata = immagine[start_row:end_row , start_col:end_col]
plt.sottotrama(2, 2, 2)
plt.imshow(ritagliata)

scalato, interpolazioni e ridimensionamento
Ridimensionamento è uno dei compiti più semplici in OpenCV. Fornisce un ridimensionare () función que toma parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... Como imagen, immagine in formato output, interpolazione, scala x e scala y. Verifique el código a continuación para una implementación completa.
immagine = cv2.imread('/kaggle/input/opencv-samples-images/data/fruits.jpg')
immagine = cv2.cvtColor(Immagine, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(20, 20))
plt.sottotrama(2, 2, 1)
plt.titolo("Originale")
plt.imshow(Immagine)
image_scaled = cv2.resize(Immagine, Nessuno, fx=0.75, fy=0.75)
plt.sottotrama(2, 2, 2)
plt.titolo("Ridimensionamento - Interpolazione lineare")
plt.imshow(image_scaled)
img_scaled = cv2.resize(Immagine, Nessuno, fx=2, fy=2, interpolazione = cv2.INTER_CUBIC)
plt.sottotrama(2, 2, 3)
plt.titolo("Ridimensionamento - Interpolazione cubica")
plt.imshow(img_scaled)
img_scaled = cv2.resize(Immagine, (900, 400), interpolazione = cv2.INTER_AREA)
plt.sottotrama(2, 2, 4)
plt.titolo("Ridimensionamento - Dimensione distorta")
plt.imshow(img_scaled)

Soglia, soglia adattativa e binarizzazione
Verifique el código a continuación para una implementación completa. Per maggiori informazioni, guarda questo Collegamento.
# Load our new image
image = cv2.imread('Origin_of_Species.jpg', 0)
plt.figure(figsize=(30, 30))
plt.sottotrama(3, 2, 1)
plt.titolo("Originale")
plt.imshow(Immagine)
Giusto,thresh1 = cv2.threshold(Immagine, 127, 255, cv2. THRESH_BINARY)
plt.sottotrama(3, 2, 2)
plt.titolo("Soglia Binaria")
plt.imshow(trebbiatura1)
immagine = cv2. GaussianBlur(Immagine, (3, 3), 0)
thresh = cv2.adaptiveThreshold(Immagine, 255, cv2. ADAPTIVE_THRESH_MEAN_C, cv2. THRESH_BINARY, 3, 5)
plt.sottotrama(3, 2, 3)
plt.titolo("Soglia media adattiva")
plt.imshow(Trebbiare)
_, th2 = cv2.threshold(Immagine, 0, 255, cv2. THRESH_BINARY + cv2. THRESH_OTSU)
plt.sottotrama(3, 2, 4)
plt.titolo("Soglia di Otsu")
plt.imshow(th2)
plt.sottotrama(3, 2, 5)
sfocatura = cv2. GaussianBlur(Immagine, (5,5), 0)
_, th3 = cv2.threshold(sfocatura, 0, 255, cv2. THRESH_BINARY + cv2. THRESH_OTSU)
plt.titolo("Soglia di Guassian Otsu")
plt.imshow(th3)
plt.mostra()

Affilato
Controllare il codice seguente per mettere a fuoco un'immagine utilizzando OpenCV. Per maggiori informazioni, guarda questo Collegamento
immagine = cv2.imread('edificio.jpg')
immagine = cv2.cvtColor(Immagine, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(20, 20))
plt.sottotrama(1, 2, 1)
plt.titolo("Originale")
plt.imshow(Immagine)
kernel_sharpening = np.array([[-1,-1,-1],
[-1,9,-1],
[-1,-1,-1]])
affilato = cv2.filter2D(Immagine, -1, kernel_sharpening)
plt.sottotrama(1, 2, 2)
plt.titolo("Nitidezza dell'immagine")
plt.imshow(affilato)
plt.mostra()

Macchia
Controlla il seguente codice per sfocare un'immagine usando OpenCV. Per maggiori informazioni, guarda questo Collegamento
immagine = cv2.imread('casa.jpg')
immagine = cv2.cvtColor(Immagine, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(20, 20))
plt.sottotrama(2, 2, 1)
plt.titolo("Originale")
plt.imshow(Immagine)
kernel_3x3 = np.ones((3, 3), ad esempio float32) / 9
sfocato = cv2.filter2D(Immagine, -1, kernel_3x3)
plt.sottotrama(2, 2, 2)
plt.titolo("3x3 Sfocatura del kernel")
plt.imshow(sfocato)
kernel_7x7 = np.ones((7, 7), ad esempio float32) / 49
sfocato2 = cv2.filter2D(Immagine, -1, kernel_7x7)
plt.sottotrama(2, 2, 3)
plt.titolo("7Sfocatura del kernel x7")
plt.imshow(sfocato2)

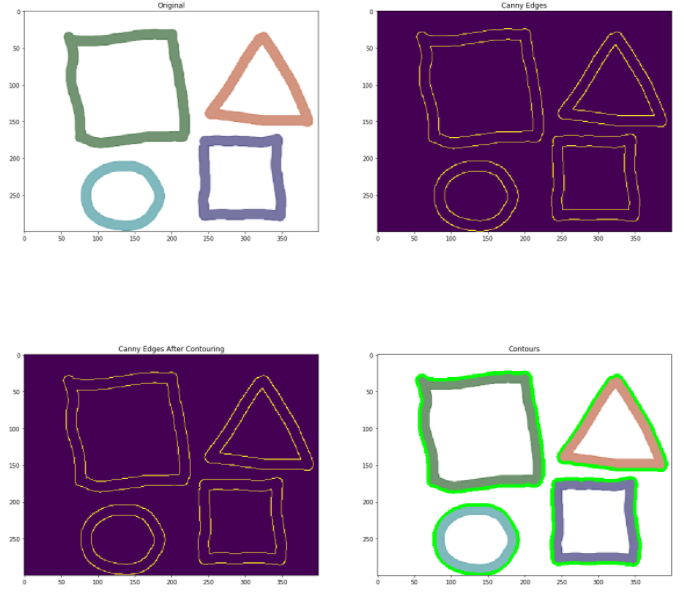
contorni
Contorni dell'immagine: è un modo per identificare i contorni strutturali di un oggetto in un'immagine. È utile identificare la forma di un oggetto. OpenCV fornisce un findContours funzione in cui è necessario passare spigoli astuti come parametro. Verifique el código a continuación para una implementación completa. Per maggiori informazioni, guarda questo Collegamento.
# Carica i dati immagine = cv2.imread('foto.png') immagine = cv2.cvtColor(Immagine, cv2.COLOR_BGR2RGB) plt.figure(figsize=(20, 20)) plt.sottotrama(2, 2, 1) plt.titolo("Originale") plt.imshow(Immagine) # Grayscale gray = cv2.cvtColor(Immagine,cv2.COLOR_BGR2GRAY) # Canny edges edged = cv2.Canny(grigio, 30, 200) plt.sottotrama(2, 2, 2) plt.titolo("Bordi astuti") plt.imshow(Taglio) # Finding Contours contour, hier = cv2.findContours(Taglio, cv2. RETR_EXTERNAL, cv2. CHAIN_APPROX_NONE) plt.sottotrama(2, 2, 3) plt.imshow(Taglio) Stampa("Conteggio dei contorni = " + str(len(contorno))) # All contours cv2.drawContours(Immagine, contorni, -1, (0,255,0), 3) plt.sottotrama(2, 2, 4) plt.titolo("Contorni") plt.imshow(Immagine)
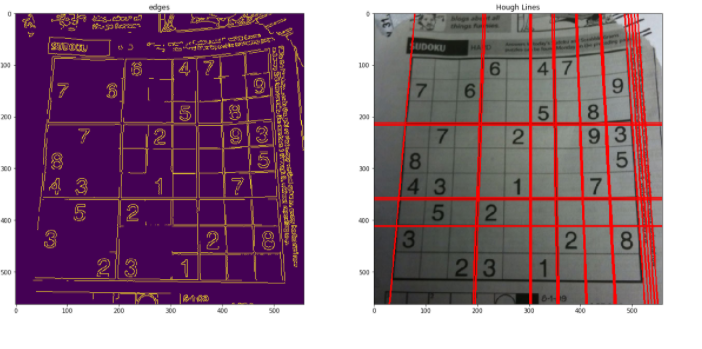
Detección de líneas mediante líneas duras
Le linee possono essere rilevate in un'immagine utilizzando le linee di Hough. OpenCV fornisce un Funzione HouhLines in cui è necessario superare il valore di soglia. La soglia è il voto minimo per una linea da considerare. Per una descrizione dettagliata, Vedere il codice riportato di seguito per una distribuzione completa. Per il rilevamento della linea utilizzando le linee Hough in OpenCV. Per maggiori informazioni, guarda questo Collegamento.
# Load the image image = cv2.imread('sudoku.png') immagine = cv2.cvtColor(Immagine, cv2.COLOR_BGR2RGB) plt.figure(figsize=(20, 20)) # Grayscale gray = cv2.cvtColor(Immagine, cv2.COLOR_BGR2GRAY) # Canny Edges edges = cv2.Canny(grigio, 100, 170, apertureDimensioni = 3) plt.sottotrama(2, 2, 1) plt.titolo("Bordi") plt.imshow(Bordi) # Run HoughLines Fucntion lines = cv2.HoughLines(Bordi, 1, np.pi/180, 200) # Run for loop through each line for line in lines: Rho, theta = linea[0] a = np.cos(theta) b = np.sin(theta) x0 = a * rho y0 = b * rho x_1 = int(x0 + 1000 * (-B)) y_1 = int(y0 + 1000 * (un)) x_2 = int(x0 - 1000 * (-B)) y_2 = int(y0 - 1000 * (un)) cv2.line(Immagine, (x_1, y_1), (x_2, y_2), (255, 0, 0), 2) # Show Final output plt.subplot(2, 2, 2) plt.imshow(Immagine)
Encontrar esquinas
Per trovare gli angoli di un'immagine, usa el cornerHarris funzione da OpenCV. Per una panoramica dettagliata, vedere il codice qui sotto per un'implementazione completa per trovare gli angoli utilizzando OpenCV. Per maggiori informazioni, guarda questo Collegamento.
# Load image image = cv2.imread('scacchiera.png') # Grayscaling image = cv2.cvtColor(Immagine, cv2.COLOR_BGR2RGB) plt.figure(figsize=(10, 10)) grigio = cv2.cvtColor(Immagine, cv2.COLOR_BGR2GRAY) # CornerHarris function want input to be float gray = np.float32(grigio) h_corners = cv2.cornerHarris(grigio, 3, 3, 0.05) kernel = np.ones((7,7),ad esempio uint8) h_corners = cv2.dilate(harris_corners, kernel, iterazioni = 10) Immagine[h_corners > 0.024 * h_corners.max() ] = [256, 128, 128] plt.sottotrama(1, 1, 1) # Final Output plt.imshow(Immagine)

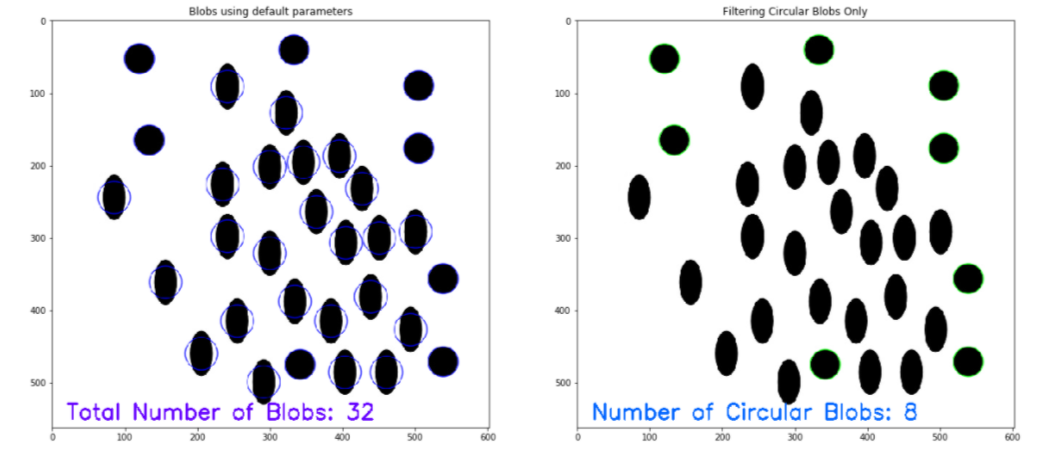
Contando círculos y elipses
Para contar círculos y elipse en una imagen, usa el Función SimpleBlobDetector da OpenCV. Per una panoramica dettagliata, consulte el código a continuación para ver la implementación completa To Count Circles and Ellipse en una imagen usando OpenCV. Per maggiori informazioni, guarda questo Collegamento.
# Load image image = cv2.imread('BLOB.jpg') immagine = cv2.cvtColor(Immagine, cv2.COLOR_BGR2RGB) plt.figure(figsize=(20, 20)) rilevatore = cv2. SimpleBlobDetector_create() # Detect blobs points = detector.detect(Immagine) blank = np.zeros((1,1)) BLOB = cv2.drawKeypoints(Immagine, scambio ferroviario, vuoto, (0,0,255), cv2. DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS) number_of_blobs = len(punti chiave) testo = "BLOB totali: " + str(len(punti chiave)) cv2.putText(Blob, testo, (20, 550), cv2.FONT_HERSHEY_SIMPLEX, 1, (100, 0, 255), 2) plt.sottotrama(2, 2, 1) plt.imshow(Blob) # Parametri di filtraggio # Initialize parameter settiing using cv2.SimpleBlobDetector params = cv2.SimpleBlobDetector_Params() # Area filtering parameters params.filterByArea = True params.minArea = 100 # Circularity filtering parameters params.filterByCircularity = True params.minCircularity = 0.9 # Convexity filtering parameters params.filterByConvexity = False params.minConvexity = 0.2 # inertia filtering parameters params.filterByInertia = True params.minInertiaRatio = 0.01 # detector with the parameters detector = cv2.SimpleBlobDetector_create(parametri) # Detect blobs keypoints = detector.detect(Immagine) # Draw blobs on our image as red circles blank = np.zeros((1,1)) BLOB = cv2.drawKeypoints(Immagine, punti chiave, vuoto, (0,255,0), cv2. DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS) number_of_blobs = len(punti chiave) testo = "No. BLOB circolari: " + str(len(punti chiave)) cv2.putText(Blob, testo, (20, 550), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 100, 255), 2) # Show blobs plt.subplot(2, 2, 2) plt.titolo("Filtraggio solo di BLOB circolari") plt.imshow(Blob)
Note finali
Quindi, in questo articolo, abbiamo avuto una discussione dettagliata su Procesamiento de imágenes mediante OpenCV. Spero che tu impari qualcosa da questo blog e ti aiuti in futuro. Grazie per la lettura e la pazienza. Buona fortuna!
Puoi controllare i miei articoli qui: Articoli
Identificazione e-mail: [e-mail protetta]
Connettiti con me su LinkedIn: LinkedIn
I media mostrati in questo articolo sull'elaborazione delle immagini OpenCV non sono di proprietà di DataPeaker e vengono utilizzati a discrezione dell'autore.





