Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
introduzione:
L'estrazione dei dati è il processo di estrazione dei dati da varie fonti come i file CSV, ragnatela, PDF, eccetera. Anche se in alcuni file, i dati possono essere facilmente estratti come in CSV, mentre in file come PDF non strutturati dobbiamo eseguire attività aggiuntive per estrarre i dati.
Ci sono un paio di librerie Python con cui puoi estrarre dati da file PDF. Ad esempio, puoi usare il PyPDF2 libreria per estrarre testo da file PDF in cui il testo è sequenziale o formattato, vale a dire, in linee o forme. Puoi anche estrarre tabelle in PDF tramite il Camelot Biblioteca. In tutti questi casi, i dati sono in forma strutturata, vale a dire, sequenziale, moduli o tabelle.
tuttavia, Nel mondo reale, la maggior parte dei dati non è presente in nessuno dei moduli e non esiste un ordine dei dati. È presente in una forma non strutturata. In questo caso, non è possibile utilizzare le librerie Python di cui sopra, poiché daranno risultati ambigui. Per analizzare dati non strutturati, dobbiamo convertirli in una forma strutturata.
Come tale, non esiste una tecnica o una procedura specifica per estrarre dati da file PDF non strutturati, poiché i dati vengono archiviati in modo casuale e dipende dal tipo di dati che si desidera estrarre dal PDF.
Qui, Ti mostrerò una tecnica di maggior successo e una libreria Python attraverso la quale puoi estrarre dati da riquadri di delimitazione in file PDF non strutturati e quindi eseguire l'operazione di pulizia dei dati sui dati estratti e convertirli in un formato strutturato.
PyMuPDF:
ho usato il PyMuPDF biblioteca per questo scopo. Questa libreria ha fornito molte applicazioni, come estrarre immagini da PDF, estrarre i testi in modi diversi, fare annotazioni, disegna un riquadro di delimitazione attorno ai testi insieme a funzionalità di libreria come PyPDF2.
Ora, Ti mostrerò come ho estratto i dati dai riquadri di delimitazione in un PDF con più pagine.
Ecco il PDF e i riquadri rossi da cui estrarre i dati.
Ho provato molte librerie Python come PyPDF2, PDFMiner, luciopdf, Camelot sì tabulato. tuttavia, nessuno di loro ha funzionato tranne PyMuPDF.
Prima di inserire il codice, è importante capire il significato di 2 termini importanti che ti aiuteranno a capire il codice.
Parola: Sequenza di caratteri senza spazi. Ex – cenere, 23, 2, 3.
Annotazioni: un'annotazione associa un oggetto come una nota, un'immagine o un riquadro di delimitazione con una posizione su una pagina di un documento PDF, o fornisce un modo per interagire con l'utente utilizzando il mouse e la tastiera. Gli oggetti sono chiamati annotazioni.
Notare che, nel nostro caso, rettangolo di selezione, annotazioni e rettangoli sono gli stessi. Perciò, Questi termini verrebbero usati in modo intercambiabile.
Primo, Estrarremo il testo da uno dei riquadri di delimitazione. Quindi useremo la stessa procedura per estrarre i dati da tutti i riquadri di delimitazione pdf.
Codice:
import fitz
import pandas as pd
doc = fitz.open('Mansfield--70-21009048 - ConvertToExcel.pdf')
pagina1 = doc[0]
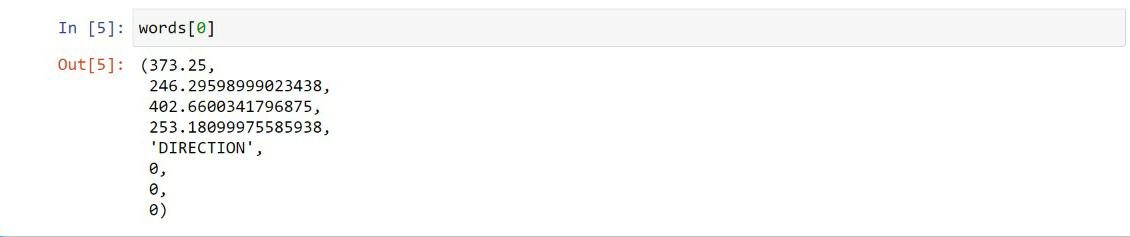
parole = page1.get_text("parole")
Primo, importiamo il Fitz modulo del PyMuPDF panda biblioteca e biblioteca. Dopo, l'oggetto file PDF viene creato e archiviato nel documento e la prima pagina del pdf viene archiviata nella pagina 1. page.get_text () estrai tutte le parole della pagina 1. Ogni parola è composta da una tupla con 8 elementi.
In parole variabili, il primo 4 gli elementi rappresentano le coordinate della parola, il quinto elemento è la parola stessa, sesto, settimo, gli ottavi elementi sono numeri di blocco, linea e parola, rispettivamente.
PRODUZIONE
Estrai le coordinate del primo oggetto:
first_annots=[]
rec=page1.first_annot.rect
rec
#Information of words in first object is stored in mywords
mywords = [w per w in parole se fitz. Rect(w[:4]) in rec]
ann= make_text(mywords)
first_annots.append(Ann)
Questa funzione seleziona le parole contenute nella casella, ordina le parole e restituisce sotto forma di catena:
def make_text(parole):
line_dict = {}
parole.ordina(chiave=lambda w: w[0])
per w in parole:
y1 = rotondo(w[3], 1)
parola = w[4]
linea = line_dict.get(e1, [])
line.append(parola)
line_dict[e1] = line
lines = list(line_dict.items())
lines.sort()
Restituzione "n".aderire([" ".aderire(linea[1]) per linea in righe])
PRODUZIONE

page.first_annot () dà il primo punteggio, vale a dire, il riquadro di delimitazione della pagina.
.Giusto dà le coordinate di un rettangolo.
Ora, abbiamo ottenuto le coordinate del rettangolo e tutte le parole sulla pagina. Quindi filtriamo le parole che sono presenti nel nostro riquadro di delimitazione e le memorizziamo in le mie parole variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.....
Abbiamo tutte le parole nel rettangolo con le loro coordinate. tuttavia, queste parole sono in ordine casuale. Poiché abbiamo bisogno del testo in sequenza e questo ha senso, usiamo una funzione make_text () che prima ordina le parole da sinistra a destra e poi dall'alto verso il basso. Restituisce testo in formato stringa.
evviva! Abbiamo estratto i dati da un commento. Il nostro prossimo compito è quello di estrarre i dati da tutte le annotazioni pdf, cosa si farebbe con lo stesso approccio.
Estrazione di ogni pagina del documento e di tutte le annotazioni / rettangoli:
per pageno nell'intervallo(0,len(documento)-1):
pagina = doc[pageno]
parole = page.get_text("parole")
per annot in Page.annots():
se annot!=Nessuno:
rec=annot.rect
mywords = [w per w in parole se fitz. Rect(w[:4]) in rec]
ann= make_text(mywords)
all_annots.append(Ann)
all_annots, viene inizializzato un elenco per memorizzare il testo di tutte le annotazioni nel pdf.
La funzione del ciclo esterno nel codice sopra è di scorrere ogni pagina del PDF, mentre quello del ciclo interno è quello di rivedere tutte le annotazioni sulla pagina ed eseguire il compito di aggiungere testi all'elenco all_annots come discusso sopra.
La stampa di all_annots ci dà il testo di tutte le annotazioni del pdf che puoi vedere qui sotto.
PRODUZIONE
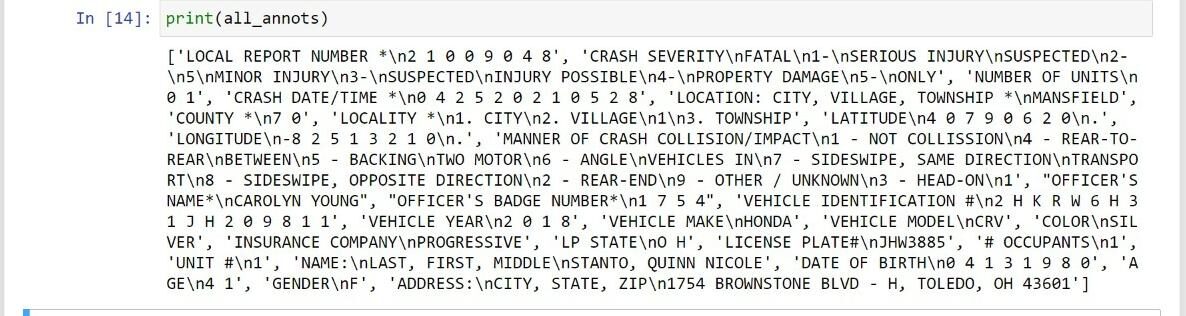
Finalmente, abbiamo estratto i testi di tutte le annotazioni / riquadri di delimitazione.
È tempo di ripulire i dati e portarli in modo comprensibile.
Pulizia ed elaborazione dei dati
Suddivisione per formare il nome della colonna e i relativi valori:
cont=[]
per io nel raggio d'azione(0,len(all_annots)):
cont.append(all_annots[io].diviso('n',1))
Rimuovere i simboli non necessari *, # ,:
liss=[]
per io nel raggio d'azione(0,len(Cont)):
lis=[]
for j in cont[io]:
j=j.replace('*','')
j=j.replace('#','')
j=j.replace(':','')
j=j.strip()
#Stampa(J)
lis.append(J)
liss.append(Lis)
Dividere in chiavi e valori ed eliminare gli spazi nei valori che contengono solo cifre:
chiavi=[]
valori=[]
for i in liss:
keys.append(io[0])
values.append(io[1])
per io nel raggio d'azione(0, len(valori)):
per j nell'intervallo(0,len(valori[io])):
se valori[io][J]>='A' e valori[io][J]<='Z':
break
if j==len(valori[io])-1:
valori[io]=valori[io].sostituire(' ','')
Dividiamo ogni stringa in base a un nuovo carattere di riga (n) Per separare il nome della colonna dai relativi valori. Pulendo di più, simboli non necessari come (*, #, ?. Gli spazi tra le cifre vengono rimossi.
Con coppie chiave-valore, creiamo un dizionario mostrato di seguito:
Conversione in dizionario:
report=dict(cerniera lampo(chiavi,valori))
conto[«IDENTIFICAZIONE DEL VEICOLO»]= informare[«IDENTIFICAZIONE DEL VEICOLO»].reemplazar(‘ ',”)
dic=[rapporto['LOCALITÀ'],rapporto[«MODALITÀ DI COLLISIONE/IMPATTO DELL'INCIDENTE»],rapporto['GRAVITÀ DELL'ARRESTO ANOMALO']] l=0 val_after=[] per locale in dic: li=[] lii=[] k='' extract="" l=0 for i in range(0,len(Locale)-1): se locale[i+1]>='0' e locale[i+1]<='9': li.append(Locale[io:i+1]) l=i+1 li.append(Locale[io:]) Stampa(al) for i in li: se io[0] in lii: k=i[0] break lii.append(io[0]) for i in li: se io[0]==k:
extraer = yo
val_after.append(estratto)
break
report['LOCALITÀ']=val_after[0]
rapporto[«MODALITÀ DI COLLISIONE/IMPATTO DELL'INCIDENTE»]=val_after[1]
rapporto['GRAVITÀ DELL'ARRESTO ANOMALO']=val_after[2]
PRODUZIONE
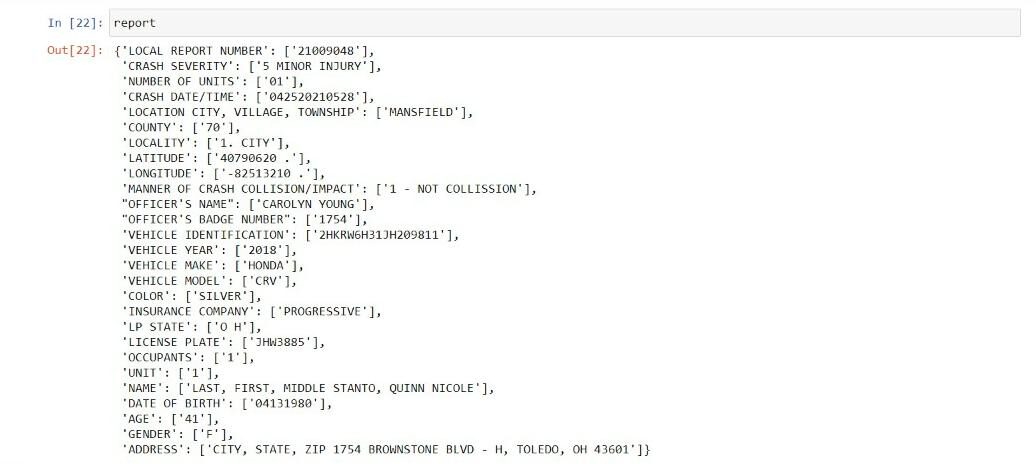
Finalmente, el diccionario se convierte en marco de datos con la ayuda de pandas.
Conversión a DataFrame y exportación a CSV:
data=pd. DataFrame.from_dict(rapporto)
data.to_csv(«finale.csv»,indice=Falso)
PRODUZIONE
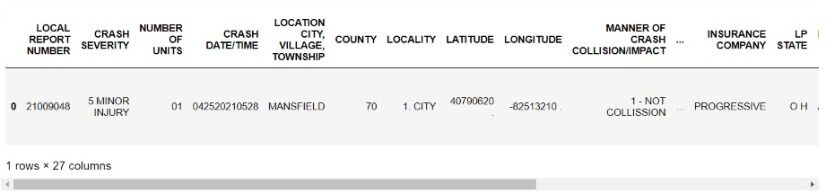
Ora, podemos realizar análisis de nuestros datos estructurados o exportarlos a Excel.
Spero che ti sia piaciuto leggere questo blog e che ti abbia dato un'idea di come gestire i dati non strutturati..
Riferimenti:
Fonte immagine in primo piano: vero pitone https://realpython.com/python-data-engineer/
Documentazione PyMuPDF: https://pymupdf.readthedocs.io/en/latest/
Circa l'autore:
Ciao! Soy Ashish Choudhary. Sto studiando B.Tech alla JC Bose University of Science and Technology. La scienza dei dati è la mia passione e sono orgoglioso di scrivere blog interessanti ad essa correlati. Non esitate a contattarmi su Linkedin linkedin.com/in/ashish-choudhary-7b6029166.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





