Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
introduzione
CSV è un tipico formato del file vale a dire usato frequentemente in domini come METROonetario Servizi, eccetera. La maggior parte delle applicazioni Maggio abilitare te per importare ed esportare conoscenza in formato CSV.
Perciò, è necessario indurre una buona comprensione dal formato CSV a un driver superiore i dati siete utilizzo insieme a quotidiano.
Quindi, lungo il Questo articolo, vedremo diversi casi di operativo con file CSV e fornire esempi per collegare tutto lungo il.
Sommario
1. Cos'è CSV?
2. Operazioni di base con file CSV
- Lavora con file CSV
- Apri un file CSV
- Salva un file CSV
3. Perché i file CSV?
4. Nozioni di base sulla funzione Read_csv () di Pandas
- Importazione di panda
- Apri un file CSV locale
- Apri un file CSV da un URL
5. Comprendere i parametri della funzione read_csv ()
- parametro settembre
- parametro index_col
- parametro di intestazione
- parametro use_cols
- parametro di compressione
- salti di parametro
- Nrows parametro
- parametro di codifica
- parametro error_bad_lines
- parametro dtype
- parametro parse_dates
- parametro convertitori
- na_values parametro
Cominciamo,
Cos'è un CSV?
CSV (valori separati da virgola) Forse un formato di file semplice Usato per memorizzare dati tabulari, Come un foglio di calcolo o un database. Il file CSV memorizza i dati tabulari (numeri e testo) in testo semplice. Ogni riga del file potrebbe essere un registro dati. Ogni record consiste a partire dal 1 o più campi, separati da virgole, l'utilizzo virgola come separatore di campo è che il nome sorgente per questo formato di file.
Operazioni di base con file CSV
Nelle operazioni di base, capiamo le seguenti tre cose:
- Come lavorare con i file CSV
- Come aprire un file CSV
- Come salvare un file CSV
Lavora con file CSV
Lavora con file CSV Non è quel compito noioso ma è abbastanza semplice. tuttavia, contando su il tuo flusso di lavoro, là Può essere avvisi che semplicemente potresti volere osservare fuori per.
Apri un file CSV
e hai un file CSV, tu aprilo in excel senza troppi problemi. Basta aprire Excel, ha aperto e trova il file CSV capire insieme a (oppure fai clic con il pulsante destro del mouse sul file CSV e scegli Apri in Excel). Dopo aver aperto il file, noterai che la info è semplice testo normale in celle diverse.
Salva un file CSV
e desideri per risparmiare un sacco di la tua cartella di lavoro corrente in un file CSV, Hai usare il posteriore comandi:
File -> Salva come … e scegli file CSV.
La maggior parte delle volte, riceverai questo avviso:

Fonte immagine: Google Immagini
Capiamo cosa ci dice questo errore.
Qui Excel sta provando menzionare è che i tuoi file CSV non ne salvano nessuno ragionevole formattazione come minimo.
Ad esempio, Le larghezze delle colonne non verranno salvate, stili di carattere, colori, eccetera.
Solo i tuoi vecchi dati è così salvato in modo eccessivamente file separato da virgole.
Nota che anche dopo di te mettilo da parte, Excel continuerà a mostrare i formati che tu solo avevo, quindi non lasciarti ingannare da questo e pensa che dopo l'apertura la cartella di lavoro di nuovo che i suoi formati saranno ancora lì. non lo saranno.
Anche dopo aver aperto un CSV Entra Eccellere, se applichi un formato sufficiente come minimo, come regolare la larghezza delle colonne esercizio la info, Excel ti avviserà comunque che tu solo Non riesco a salvare i formati che tu solo aggiuntivo, tu ricevi un avviso come questo:

Fonte immagine: Google Immagini
Quindi, l'obiettivo usa vale a dire i suoi formati non possono mai essere salvati in file CSV.
Perché i file CSV?
I file CSV vengono utilizzati come il modo più semplice parlare dati tra diverse applicazioni. Supponiamo di avere un'applicazione di database e di voler esportare la info in un file. e desideri per esportarlo in un file Excel, l'applicazione database farebbe supporta l'esportazione in file XLS *.
tuttavia, poiché il formato di file CSV è estremamente semplice e luce (tanto tanto così rispetto ai file XLS *), è più facile per vario app per supportarlo. Nel suo uso di base, ha una riga di testo, insieme a ogni colonna di dati e modi alternativi per una virgola. Questo è tutto. E per questa semplicità, è semplice per gli sviluppatori. produrre Esportazione importazione senso pratico con file CSV da trasferire conoscenza tra le app invece di tanto sofisticato formati di file.
Ad esempio,
Diamo un dati tabulati nel modulo indicato di seguito:

Se convertiamo questi dati in a Formato CSV, quindi sembra così:

Ora, abbiamo finito con tutte le basi dei file CSV. Quindi, sul retro dell'articolo, discuteremo in dettaglio come lavorare con i file CSV.
Importazione di panda
Primo, importiamo le dipendenze necessarie come panda Libreria Python.
importa panda come pd
Quindi, la dipendenza è importata, ora possiamo caricare e leggere facilmente il set di dati.
funzione read-csv
- È una funzione importante dei panda leggere i file CSV ed eseguire operazioni su di essi.
- Questa funzione ci aiuta a caricare il file dal tuo computer locale o da qualsiasi URL.
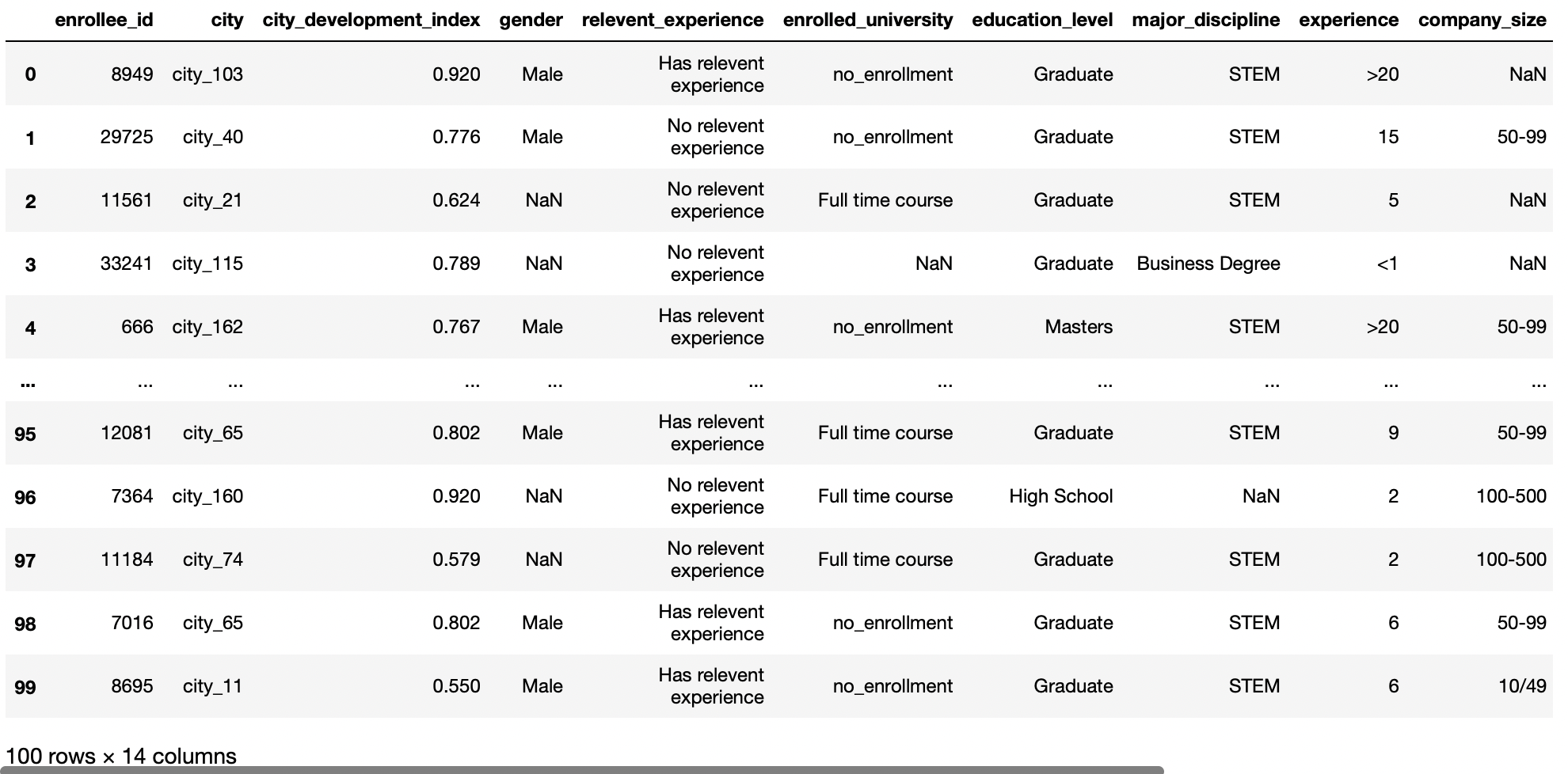
Apri un file CSV locale
Se il file è presente nella stessa posizione del nostro file Python, quindi fornisci il nome del file solo per caricare quel file; altrimenti, devi fornire il percorso relativo ad esso.
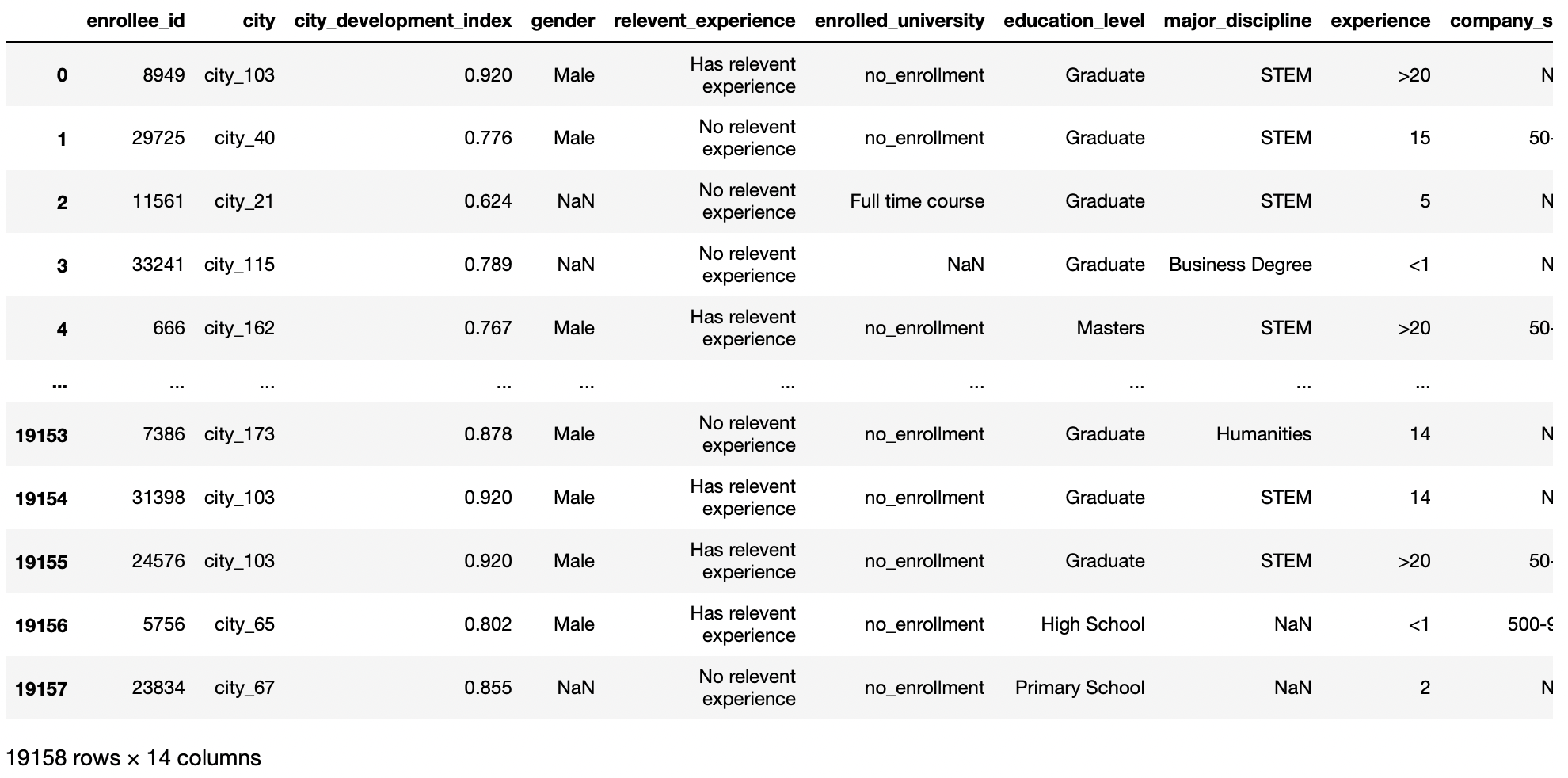
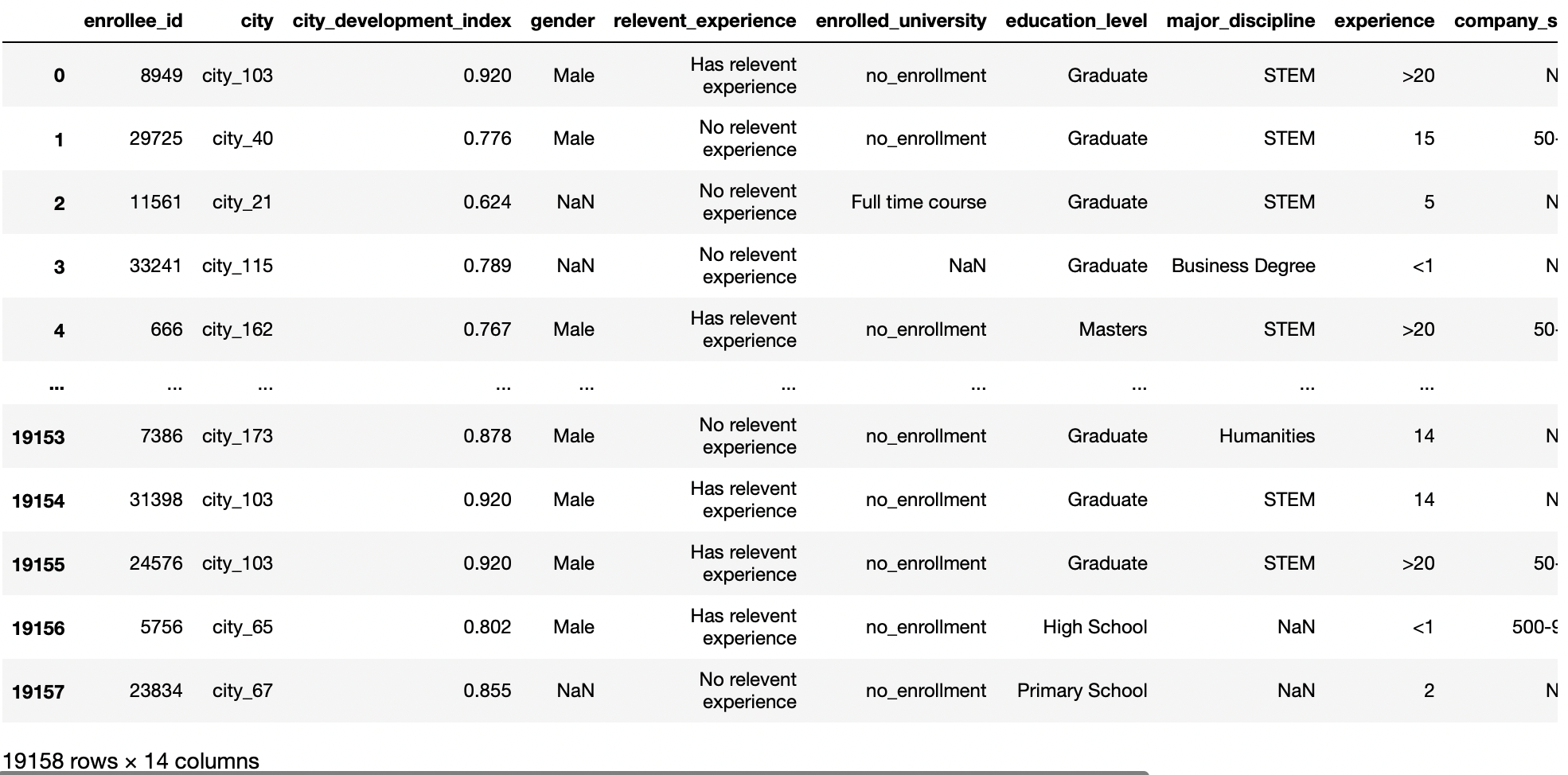
df = pd.read_csv('aug_train.csv')
df
Produzione:
Apri un file CSV da un URL
Se il file non è presente direttamente sulla nostra macchina locale, ma dobbiamo cercare i dati di un certo url, quindi prendiamo l'aiuto del modulo delle richieste per caricare quei dati.
richieste di importazione
da io import StringIO
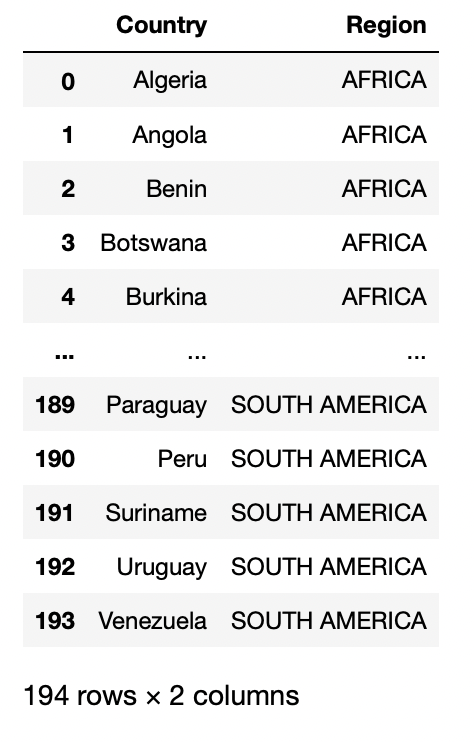
URL = "https://raw.githubusercontent.com/cs109/2014_data/master/countries.csv"
intestazioni = {"Agente utente": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:66.0) Geco/20100101 Firefox/66.0"}
req = richieste.get(URL, intestazioni=intestazioni)
data = StringIO(req.testo)
pd.read_csv(dati)
Produzione:
parametro settembre
Se abbiamo un set di dati in cui le entità in una particolare riga non sono separate da una virgola, quindi dobbiamo usare il parametro sep per specificare il separatore o il delimitatore.
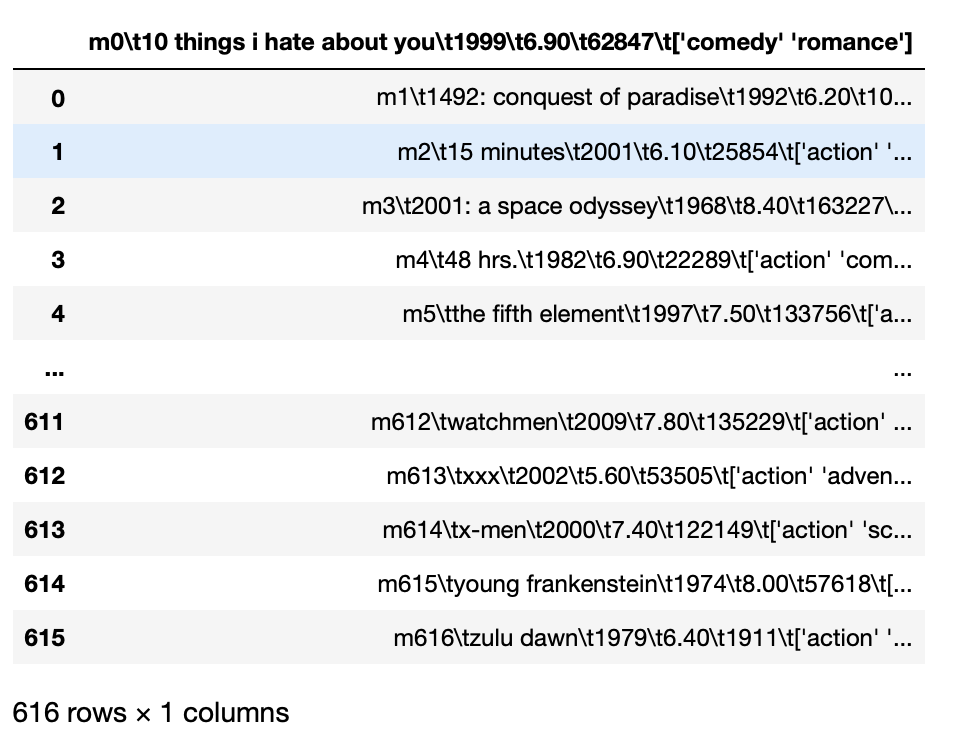
Ad esempio, Se abbiamo un file tsv, vale a dire, le entità sono separate da tab e se proviamo a caricare direttamente questi dati, tutte le entità vengono caricate combinate.
importa panda come pd
pd.read_csv('film_titles_metadata.tsv')
Produzione:
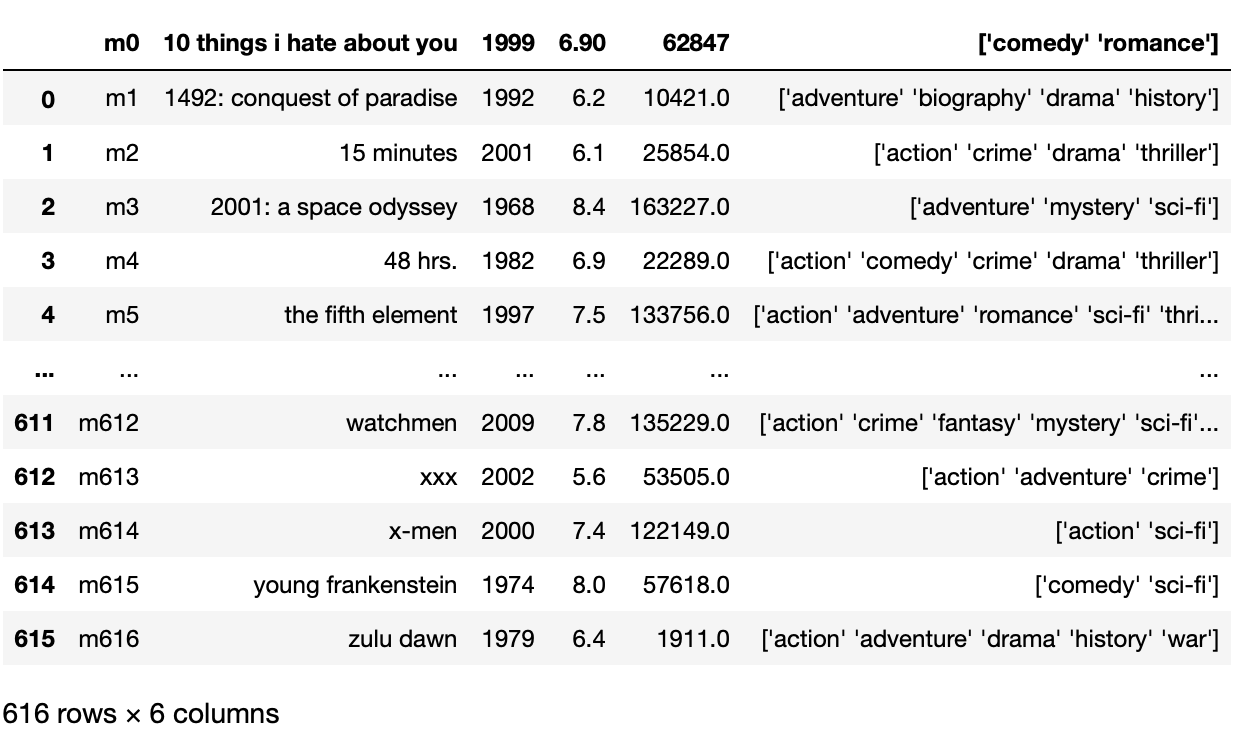
Per risolvere il problema di cui sopra per il file CSV, dobbiamo sovrascrivere il parametro sep a 'T’ invece di ',’ che è un separatore predefinito.
importa panda come pd
pd.read_csv('film_titles_metadata.tsv',settembre = 't')
Produzione:
Nell'esempio sopra, abbiamo osservato che la prima riga è trattata come il nome della colonna, e per risolvere questo problema e creare il nostro nome personalizzato per le colonne, dobbiamo specificare l'elenco di parole con nomi come nome dell'elenco.
pd.read_csv('film_titles_metadata.tsv',settembre = 't',nomi=['no','nome','Anno di pubblicazione','valutazione',"voti",'generi'])
Produzione:
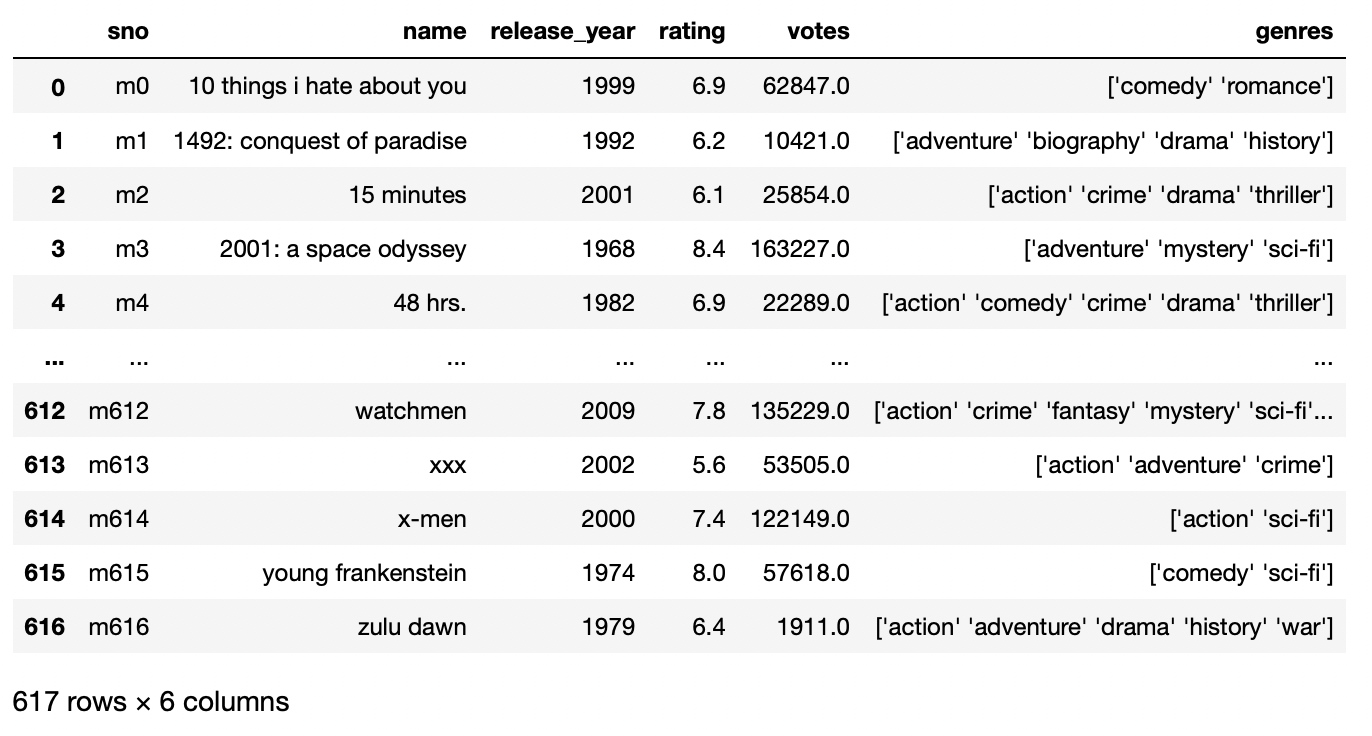
parametro index-col
Questo parametro ci consente di impostare quali colonne verranno utilizzate come indice del frame di dati. Il valore predefinito per questo parametro è Nessuno, e i panda aggiungeranno automaticamente una nuova colonna a partire da 0 per descrivere la colonna indice.
Quindi, ci consente di utilizzare una colonna come etichette di riga per un determinato DataFrame. Questa funzione è utile quando ci consente di avere una colonna ID presente con il nostro set di dati e quella colonna non è influenzata dalle nostre previsioni, quindi rendiamo quella colonna il nostro indice di riga invece del valore predefinito.
pd.read_csv('aug_train.csv',index_col="id_iscrizione")
Produzione:
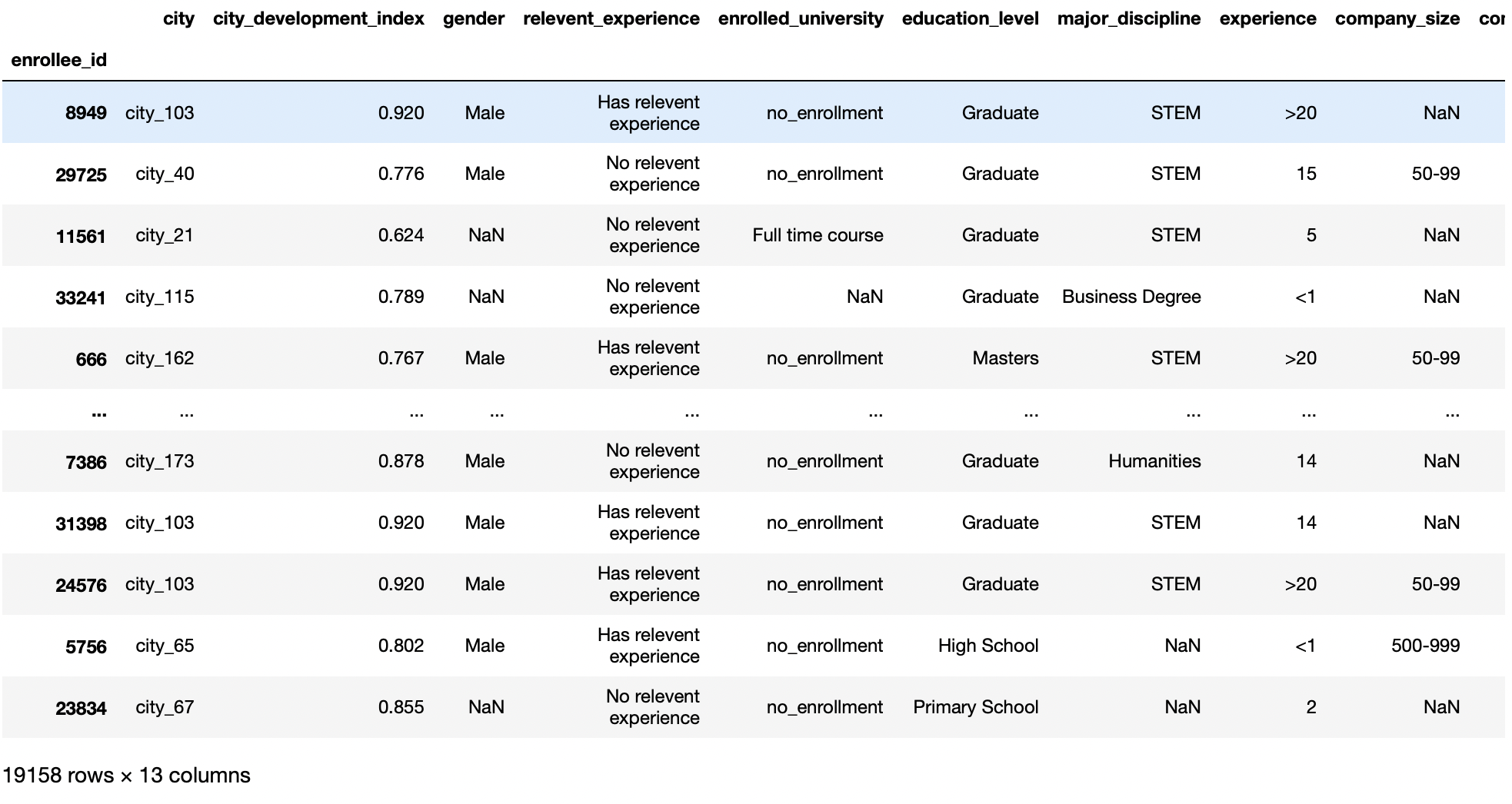
parametro di intestazione
Questo ci consente di specificare quale riga verrà utilizzata come nomi di colonna per il frame di dati. Aspettati un input come valore int o un elenco di valori int.
Il valore predefinito per questo parametro è intestazione = 0, il che implica che la prima riga del file CSV sarà considerata come nomi di colonna.
pd.read_csv('prova.csv',intestazione=1)
Produzione:
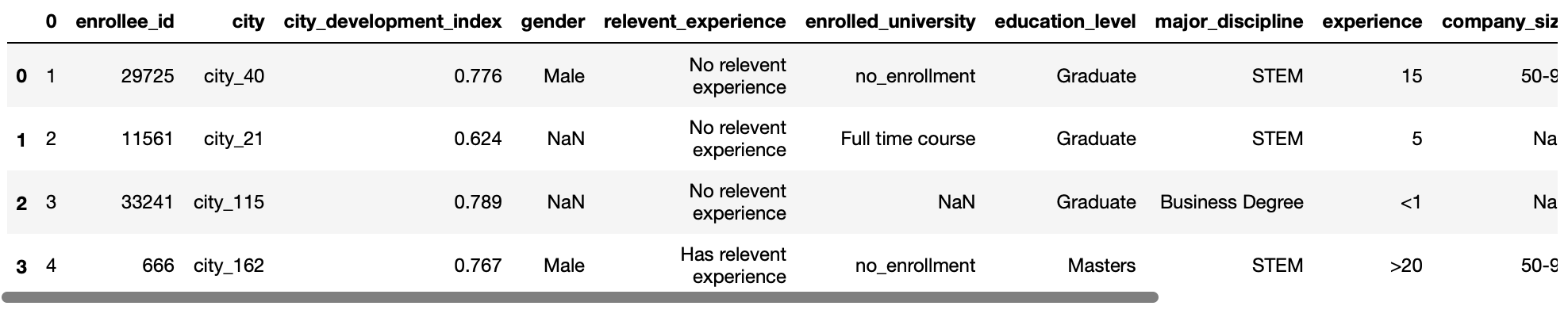
parametro use-cols
Specificare quali colonne importare dal set di dati completo al frame di dati. Puoi inserire una lista di valori int o direttamente i nomi delle colonne.
Questa funzione è utile quando dobbiamo fare la nostra analisi solo su alcune colonne, non in tutte le colonne del nostro set di dati.
Quindi, questo parametro restituisce un sottoinsieme delle colonne nel tuo set di dati.
pd.read_csv('aug_train.csv',usecols =['id_iscrizione','Genere','Livello scolastico'])
Produzione:
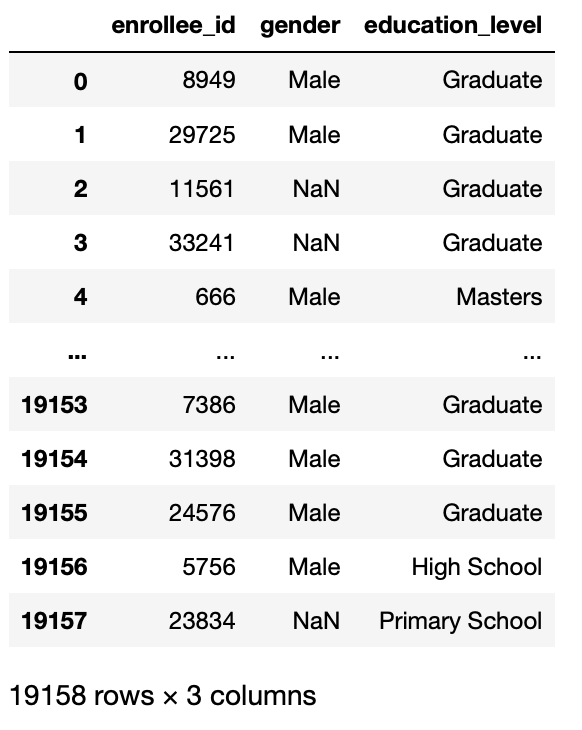
parametro di compressione
Se true e viene passata solo una colonna, restituisce la stringa panda invece di un DataFrame.
pd.read_csv('aug_train.csv',usecols =['Genere'],spremere=Vero)
Produzione:
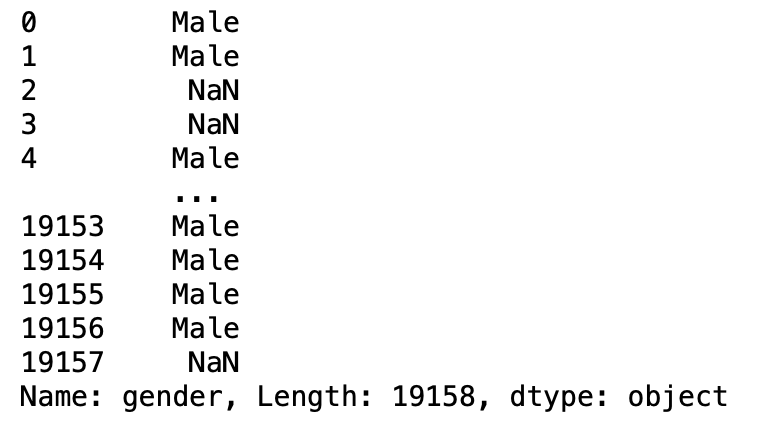
salti di parametro
Questo parametro viene utilizzato per saltare le righe passate nel nuovo frame di dati.
pd.read_csv('aug_train.csv',saltatori =[0,1])
Produzione:
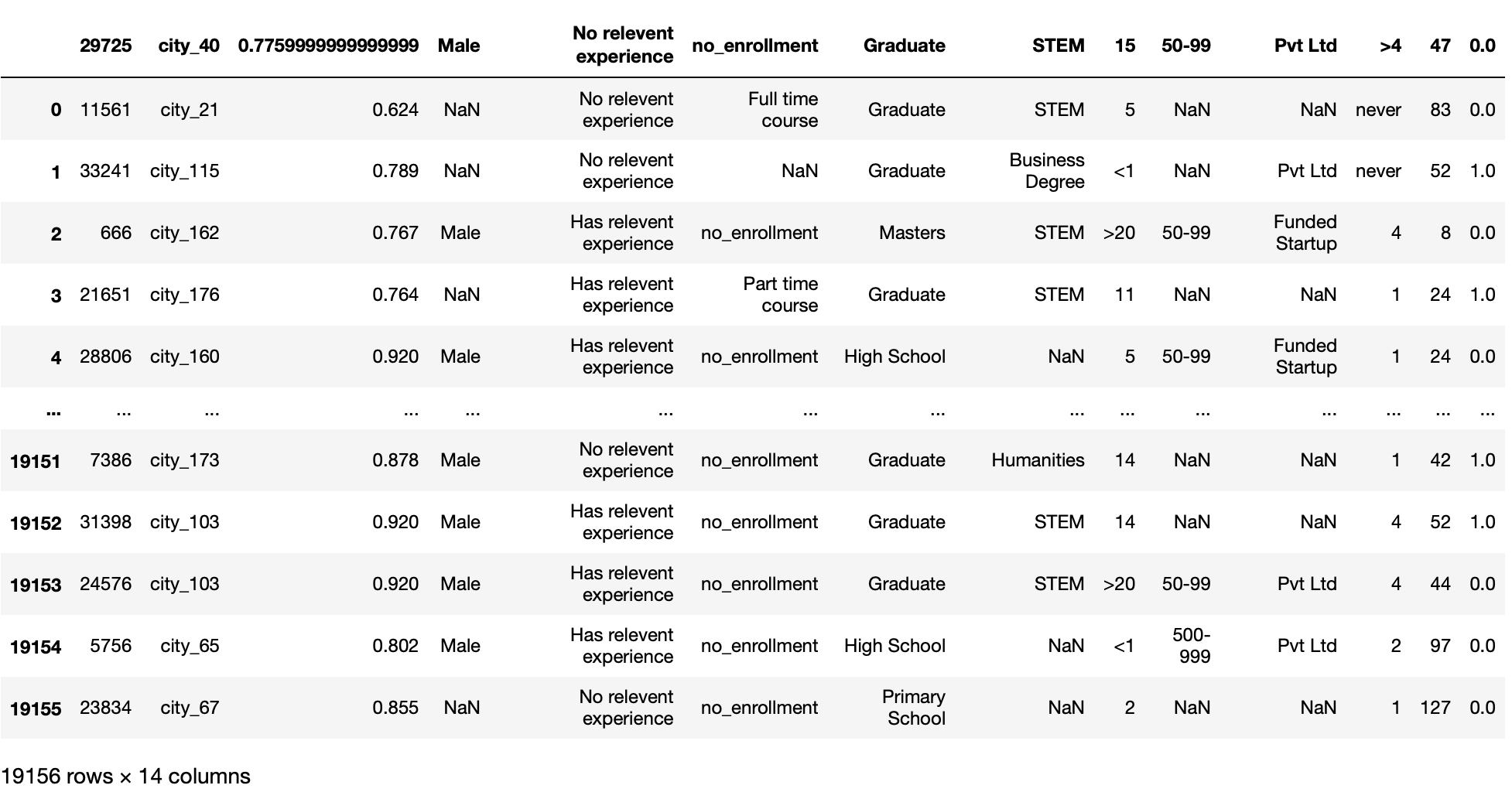
Nrows parametro
Questa funzione legge solo il numero fisso (deciso dall'utente) delle prime righe del file. Hai bisogno di un valore int.
Questo parametro è utile quando abbiamo un enorme set di dati e vogliamo caricare il nostro set di dati in blocchi invece di caricare direttamente l'intero set di dati.
pd.read_csv('aug_train.csv',righe = 100)
Produzione:
parametro di codifica
Questo parametro aiuta a determinare quale codifica utilizzare per UTF durante la lettura o la scrittura di file.
Qualche volta, quello che succede è che i nostri file non sono codificati nel modo predefinito, vale a dire, UTF-8. Quindi, salvalo con un editor di testo o aggiungi il parametro “Codifica = 'utf-8 ′ non funziona. In entrambi i casi, restituisce l'errore.
Quindi, risolvere questo problema, chiamiamo la nostra funzione read_csv con codifica = 'latino1 ′, codifica =’ iso-8859-1 ′ o codifica = 'cp1252 ′ (queste sono alcune delle varie codifiche che si trovano in Windows).
pd.read_csv('zomato.csv',codifica='latino-1')
Produzione:
parametro error-bad-lines
Se abbiamo un set di dati in cui alcune righe hanno troppi campi (Ad esempio, una riga CSV con troppe virgole), dopo, per impostazione predefinita, viene generata un'eccezione e causa, e nessun DataFrame verrà restituito.
Quindi, per risolvere questo tipo di problema, dobbiamo rendere questo parametro False, allora sei “linee difettose” verrà rimosso dal DataFrame che viene restituito. (Valido solo con analizzatore C)
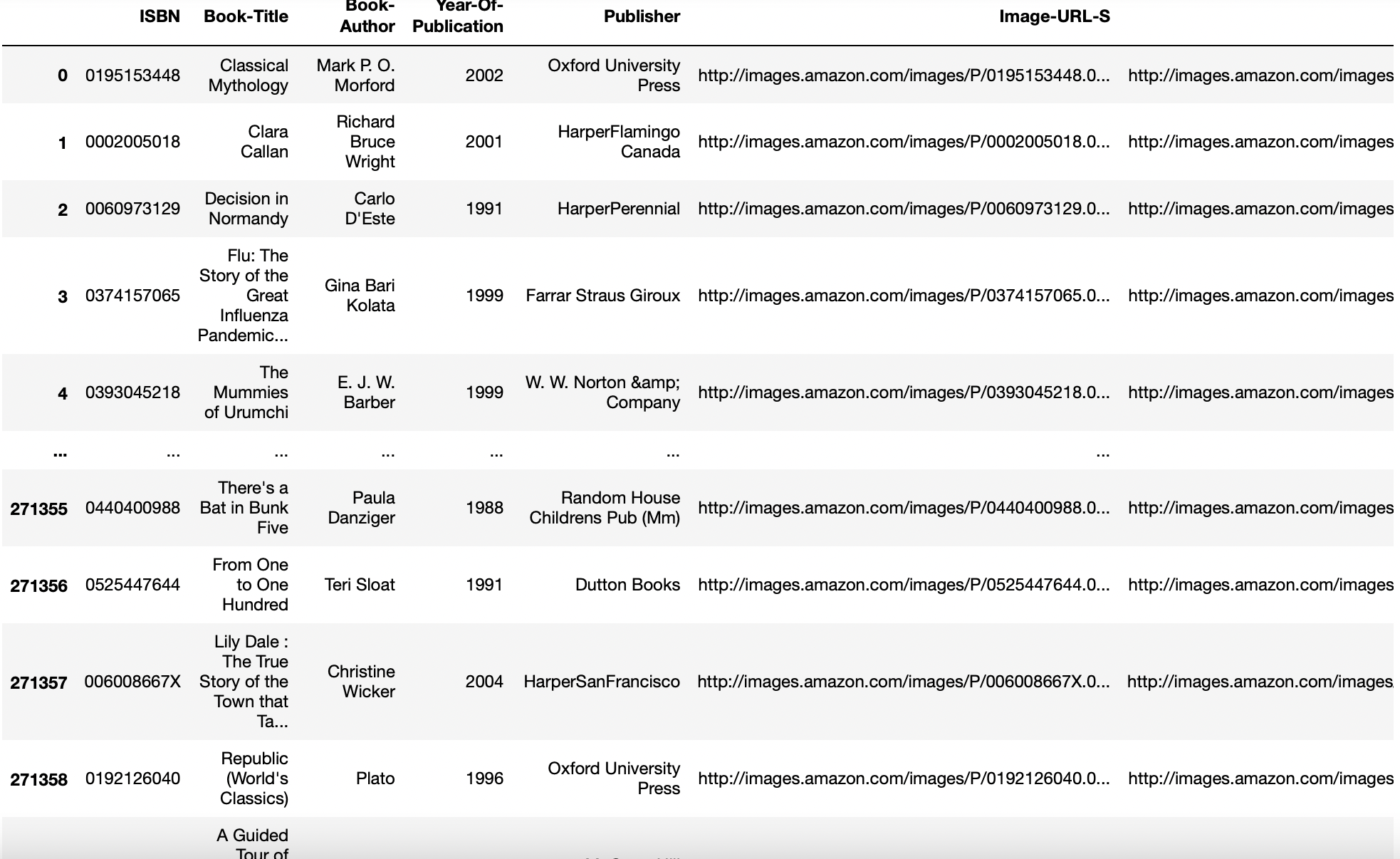
pd.read_csv('BX-Books.csv', settembre=';', codifica="latino-1",error_bad_lines=Falso)
Produzione:
parametro dtype
Tipo di dati per dati o colonne. Ad esempio, {'un': ad esempio float64, 'B': ad esempio int32}
Qualche volta, per convertire le nostre colonne dal tipo di dati float al tipo di dati int, questa funzione è utile.
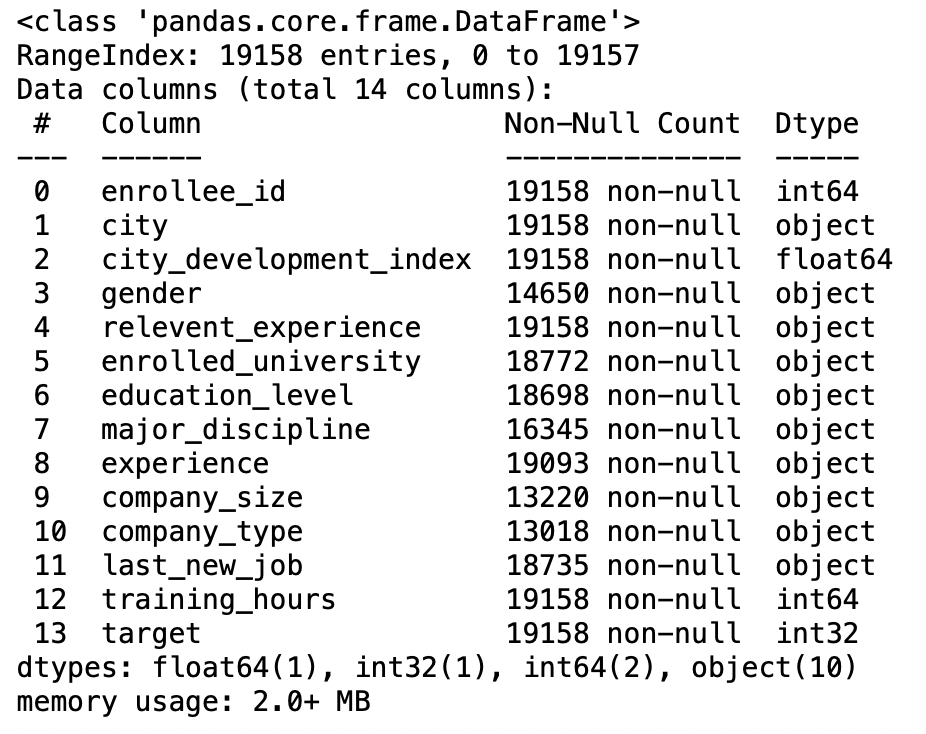
pd.read_csv('aug_train.csv',dtype={'obbiettivo':int}).Informazioni()
Produzione:
parametro parse-dates
Se rendiamo vero questo parametro, quindi prova ad analizzare l'indice.
Ad esempio, e [1, 2, 3] -> prova ad analizzare le colonne 1, 2, 3 ciascuno come una colonna data separata e se dobbiamo combinare le colonne 1 e 3 e analizza come una singola colonna di data, utilizzo [[1,3]].
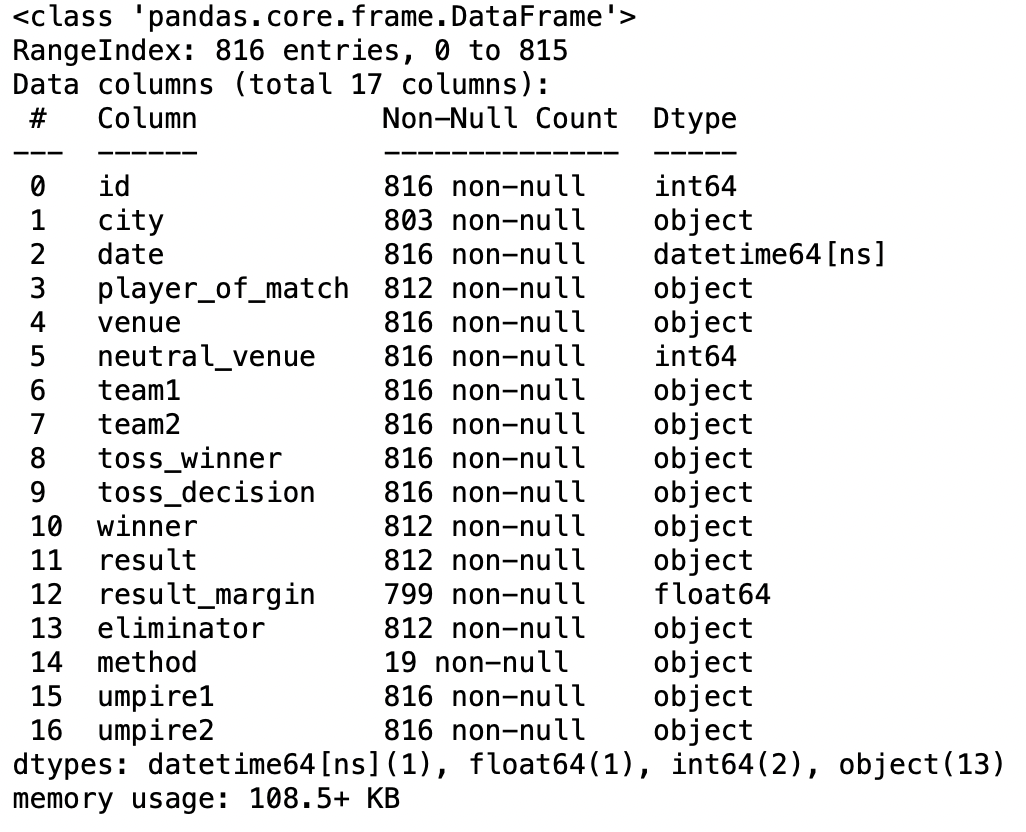
pd.read_csv("Partite IPL 2008-2020.csv",parse_dates=['Data']).Informazioni()
Produzione:
parametro convertitori
Questo parametro ci aiuta a convertire i valori nelle colonne in base a una funzione personalizzata fornita dall'utente.
def rinominare(nome):
se nome == "Royal Challengers Bangalore":
Restituzione "RCB"
altro:
nome di ritorno
rinominare("Royal Challengers Bangalore")
Produzione:
'RCB'’
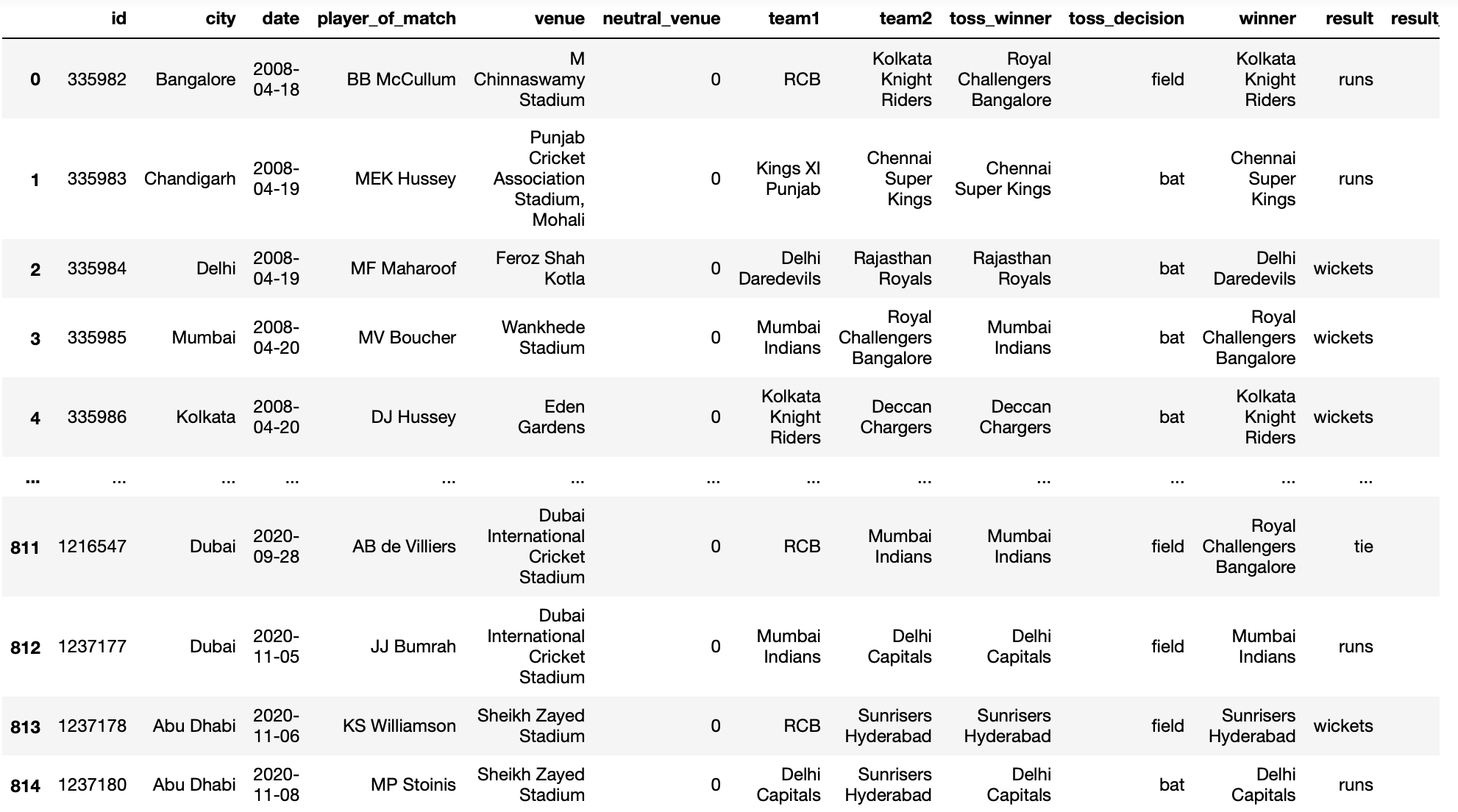
pd.read_csv("Partite IPL 2008-2020.csv",convertitori={'squadra1':rinominare})
Produzione:
valori dei parametri in
Come sappiamo, i valori mancanti di default saranno NaN. Se vogliamo che altre stringhe siano considerate come NaN, allora dobbiamo usare questo parametro. Aspettati un elenco di stringhe come input.
Qualche volta, nel nostro set di dati, un altro tipo di simbolo viene utilizzato per convertirli in valori mancanti, quindi in quel momento per capire quei valori come persi, usiamo questo parametro.
pd.read_csv('aug_train.csv',na_values=['Maschio',])
Produzione:
Questo completa la nostra discussione!!
NOTA: In questo articolo, Discuteremo solo quei parametri che sono molto utili quando si lavora con i file CSV su base giornaliera.. Ma se sei interessato a conoscere più parametri, dai un'occhiata al sito ufficiale di Pandas qui.
Oppure puoi fare riferimento a questo Collegamento Cosa c'è di più.
Note finali
Grazie per aver letto!
Se ti è piaciuto e vuoi saperne di più, vai agli altri miei articoli su data science e machine learning facendo clic su Collegamento
Sentiti libero di contattarmi a Linkedin, E-mail.
Tutto ciò che non è stato menzionato o vuoi condividere i tuoi pensieri? Sentiti libero di commentare qui sotto e ti ricontatterò.
Circa l'autore
Chirag Goyal
Attualmente, Sto perseguendo il mio Bachelor of Technology (B.Tech) in informatica e ingegneria da Istituto indiano di tecnologia Jodhpur (IITJ). Sono molto entusiasta dell'apprendimento automatico, deep learning e intelligenza artificiale.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





