Cosa sono le anomalie e come rilevarle? Che impatto ha sui dati?
introduzione
Le anomalie sono i diversi punti del normale stato di esistenza. Questi sono qualcosa che può sorgere a causa di diverse circostanze in base ai vari fattori che ti influenzano.. Ad esempio, tumori che si sviluppano a causa di alcune malattie, come quando a una persona viene diagnosticato un cancro, più cellule si sviluppano senza alcun limite.
Nello stesso modo, Quando otteniamo tali dati, dobbiamo analizzare e rilevare queste anomalie in modo che il trattamento sia più semplice e sappiamo quali azioni intraprendere. Quando si verificano tali anomalie nell'industria automobilistica, come quando le vendite di un'auto particolare o di altri veicoli di trasporto sono alte o basse. Quindi è un'anomalia di tutti i dati. Le anomalie non sono altro che valori anomali nei dati.
Come si rilevano gli outlier o quali sono i metodi utilizzati per rilevare le anomalie?
1. Usa la visualizzazione dei dati (como hacer uso de box plotDiagrammi a scatola, Conosciuto anche come diagrammi a scatola e baffi, sono strumenti statistici che rappresentano la distribuzione di un dataset. Questi diagrammi mostrano la mediana, quartili e valori anomali, Consentire la visualizzazione della variabilità e della simmetria dei dati. Sono utili nel confronto tra diversi gruppi e nell'analisi esplorativa, Rendendo più facile identificare tendenze e modelli nei dati...., diagrammi di violino, eccetera.)
2. Utilizzare metodi statistici come i metodi dei quantili (IQR, Q1, Q3), trova il minimo, el máximo y la medianoLa mediana è una misura statistica che rappresenta il valore centrale di un insieme di dati ordinati. Per calcolarlo, I dati sono organizzati dal più basso al più alto e viene identificato il numero al centro. Se c'è un numero pari di osservazioni, I due valori fondamentali sono mediati. Questo indicatore è particolarmente utile nelle distribuzioni asimmetriche, poiché non è influenzato da valori estremi.... dei dati, il punteggio Z, eccetera.
3. Algoritmi ML come IsolationForest, LocalOutlierFactor, OneClassSVM, Busta ellittica… ecc.
1. Visualizzazione dati: Quando un elemento viene tracciato utilizzando strumenti di visualizzazione come Seaborn, matplotlib, plotly o altri software come tableau, PowerBI, Qlik Sense, Eccellere, Parola, … eccetera., ci facciamo un'idea dei dati e del loro conteggio nei dati e conosciamo anche le anomalie principalmente utilizzando i box plot, diagrammi di violino, diagrammi a dispersione.
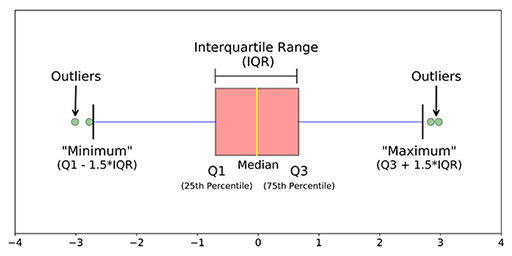
2. metodi statistici: Quando trovi la media dei dati, potrebbe non fornire il valore medio corretto quando ci sono anomalie nei dati. Quando ci sono anomalie nei dati, la mediana dà un valore corretto rispetto alla media perché la mediana ordina i valori e trova la posizione centrale nei dati, mentre la media fa solo la media dei valori nei dati. Per trovare valori anomali sul lato sinistro e destro dei dati, usa Q3 + 1.5 (IQR), Q1-1.5 (IQR). Cosa c'è di più, quando si trova il massimo, il minimo e la mediana dei dati, può dire se sono presenti o meno anomalie nei dati.
3. Algoritmi ML: Il vantaggio dell'utilizzo di algoritmi non supervisionati per il rilevamento delle anomalie è che possiamo trovare anomalie per più variabili o caratteristiche o predittori nei dati contemporaneamente piuttosto che separatamente per singole variabili.. Si può fare anche in entrambi i modi, chiamato rilevamento di anomalie univariate e rilevamento di anomalie multivariate.
un. Isolamento foresta: Questa è una tecnica non supervisionata per rilevare anomalie quando non ci sono etichette o valori veri. Sarebbe un compito complesso controllare ogni riga dei dati per rilevare quelle righe che possono essere considerate anomalie.
Isolation Forest è un modello basato sugli alberi. Gli alberi formati per questo non sono gli stessi di quelli fatti negli alberi decisionali. Gli alberi decisionali e le foreste di isolamento sono diverse forme di costruzione. Cosa c'è di più, una diferencia principal más es que el árbol de decisiones es un algoritmo de apprendimento supervisionatoL'apprendimento supervisionato è un approccio di apprendimento automatico in cui un modello viene addestrato utilizzando un set di dati etichettati. Ogni input nel set di dati è associato a un output noto, consentendo al modello di imparare a prevedere i risultati per nuovi input. Questo metodo è ampiamente utilizzato in applicazioni come la classificazione delle immagini, Riconoscimento vocale e previsione delle tendenze, sottolineandone l'importanza in... y el bosque de aislamiento es un algoritmo de Apprendimento non supervisionatoL'apprendimento non supervisionato è una tecnica di apprendimento automatico che consente ai modelli di identificare modelli e strutture nei dati senza etichette predefinite. Attraverso algoritmi come k-means e analisi delle componenti principali, Questo approccio viene utilizzato in una varietà di applicazioni, come la segmentazione dei clienti, Rilevamento delle anomalie e compressione dei dati. La sua capacità di rivelare informazioni nascoste lo rende uno strumento prezioso....
In questi alberi di isolamento, las particiones se crean seleccionando primero aleatoriamente una característica o variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... y luego seleccionando un valor de división aleatoria entre el valor mínimo y máximo de la característica seleccionada. Ancora, il nodoNodo è una piattaforma digitale che facilita la connessione tra professionisti e aziende alla ricerca di talenti. Attraverso un sistema intuitivo, Consente agli utenti di creare profili, condividere esperienze e accedere a opportunità di lavoro. La sua attenzione alla collaborazione e al networking rende Nodo uno strumento prezioso per chi vuole ampliare la propria rete professionale e trovare progetti in linea con le proprie competenze e obiettivi.... raíz se selecciona aleatoriamente sin ninguna condición para ser un nodo raíz como ocurre en el árbol de decisiones. Il nodo radice viene selezionato casualmente dalle variabili nei dati, poi viene preso un qualche valore casuale che sta tra il massimo e il minimo di quella particolare caratteristica.
Il punteggio di anomalia di un campione di input viene calcolato come punteggio medio di anomalia degli alberi nella foresta di isolamento. Dopo, il punteggio di anomalia viene calcolato per ogni variabile dopo aver adattato tutti i dati al modello. Quando il punteggio di anomalia aumenta, c'è un'alta probabilità che si tratti di un'anomalia rispetto alla riga con il punteggio di anomalia più basso. Ci sono tre funzioni in questo algoritmo che semplificano la visualizzazione e la memorizzazione dei punteggi utilizzando le poche righe di codice fornite di seguito.:
from sklearn.ensemble import IsolationForest
isolation_forest = IsolationForest(n_estimators=1000, contaminazione=0,08)
isolation_forest.fit(df['Tariffa'].valori.rimodellare(-1, 1))
df['anomaly_score_rate'] = isolation_forest.funzione_decisione(df['tasso'].valori.rimodellare(-1, 1))
df['outlier_univariate_rate'] = isolation_forest.predict(df['tasso'].valori.rimodellare(-1, 1))
Qui, il parametro di contaminazione svolge un ruolo importante nel rilevare più anomalie. La contaminazione è la percentuale di valori che stai dando all'algoritmo che c'è così tanta percentuale di anomalie nei dati. Ad esempio: quando ha dato 0,10 come valore di inquinamento, gli algoritmi considerano che esiste a 10% di anomalie dei dati. Trovando la contaminazione ottimale, sarai in grado di rilevare anomalie con un buon numero.
Quando si desidera eseguire il rilevamento di anomalie multivariate, devi prima normalizzare i valori nei dati in modo che l'algoritmo possa dare previsioni corrette. Il standardizzazioneLa standardizzazione è un processo fondamentale in diverse discipline, che mira a stabilire norme e criteri uniformi per migliorare la qualità e l'efficienza. In contesti come l'ingegneria, Istruzione e amministrazione, La standardizzazione facilita il confronto, Interoperabilità e comprensione reciproca. Nell'attuazione degli standard, si promuove la coesione e si ottimizzano le risorse, che contribuisce allo sviluppo sostenibile e al miglioramento continuo dei processi.... o estandarización es esencial cuando se trata de valores continuos.
minmax = MinMaxScaler(feature_range=(0, 1)) X = minmax.fit_transform(df[['tasso',"punteggi"]]) clf = IsolationForest(n_estimatori = 100, contaminazione=0.01, stato_casuale=0) clf.fit(X) df['multivariate_anomaly_score'] = clf.decision_function(X) df['multivariate_outlier'] = clf.predict(X)
Per saperne di più vai su sklearn isolamento foresta
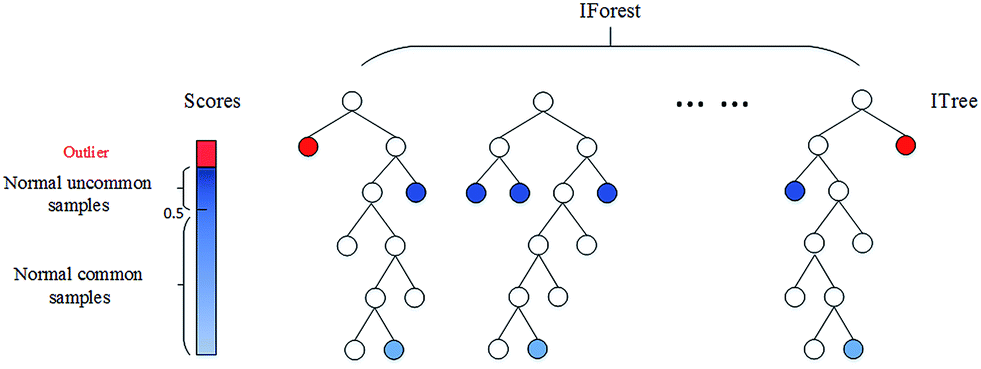
L'immagine sopra corrisponde a: https://pubs.rsc.org/en/content/articlelanding/2016/ay/c6ay01574c#!divAbstract
B. LocalOutlierFactor: Anche questo è un algoritmo non supervisionato e non è basato su alberi ma su un algoritmo basato sulla densità come KNN, Ksignifica. Quando un punto dati è considerato un valore anomalo a seconda del tuo quartiere, è un valore anomalo locale. LOF identificherà un outlier considerando la densità del vicino. LOF funziona bene quando la densità del punto dati non è costante in tutto il set di dati.
Esistono due tipi di rilevamento che vengono eseguiti con questo algoritmo. Sono il rilevamento di valori anomali e il rilevamento di novità, dove il rilevamento dei valori anomali non è supervisionato e il rilevamento delle novità è semi-sorvegliato, poiché utilizza i dati del treno per fare le sue previsioni sui dati di prova, sebbene i dati del treno non contengano previsioni esatte.
Anche LocalOutlierFactor usa lo stesso codice, quindi il codice viene utilizzato solo per il rilevamento della novità quando il parametro della novità è True in questo modello. Quando il suo valore predefinito False, il rilevamento dei valori anomali verrebbe utilizzato dove l'unico fit_predict funzionerebbe. Quando novità = Vero, questa funzione è disabilitata.
Di seguito è riportato il codice per trovare anomalie utilizzando l'algoritmo outlier locale
minmax = MinMaxScaler(feature_range=(0, 1)) X = minmax.fit_transform(df[['tasso',"punteggi"]]) # Novelty detection clf = LocalOutlierFactor(n_neighbors=100, contaminazione=0.01,novità=Vero) #when novelty = True clf.fit(X_treno) df['multivariate_anomaly_score'] = clf.decision_function(X_test) df['multivariate_outlier'] = clf.predict(X_test) # Outlier detection local_outlier_factor_multi=LocalOutlierFactor(n_neighbors=15,contaminazione=0.20.n_jobs=-1) # when novelty = False multi_pred=local_outlier_factor_multi.fit_predict(X) DF1['Multivariate_pred']=multi_pred
Per saperne di più su questo, vedere Fattore di anomalia locale Sklearn
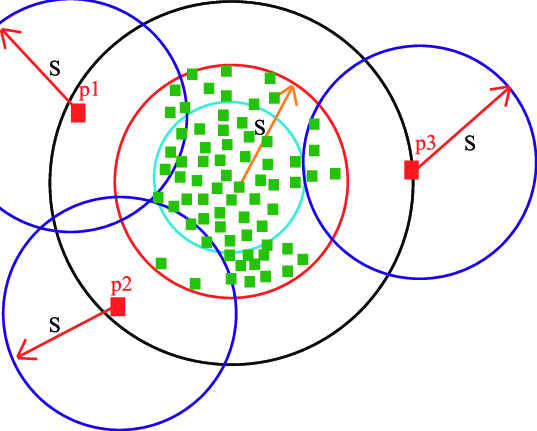
C. SVM di una classe: Esiste un SVM supervisionato che gestisce le attività di regressione e classificazione. Ecco un SVM a classe singola non supervisionato, poiché le etichette sono sconosciute. Le SVM di una classe sono un tipo speciale di macchina vettoriale di supporto. Primo, i dati vengono modellati e l'algoritmo viene addestrato. Dopo, quando vengono trovati nuovi dati, la sua posizione rispetto ai dati normali (o inliers) la formazione può essere utilizzata per determinare se sei fuori classe o no. Come possono essere addestrati con dati non etichettati o senza variabili di destinazione, sono un esempio di non supervisionato apprendimento automatico.
Ha solo poche righe di codice come altri algoritmi:
from sklearn.svm import OneClassSVM
pred=clf.predict(X)
anomaly_score=clf.score_samples(X)
clf = OneClassSVM(gamma="auto",nu=0,04,gamma=0,0004).in forma(X)
Per saperne di più, vedi questo sito di sklearn per SVM di classe singola
D. Algoritmo di inviluppo ellittico: Questo algoritmo viene utilizzato quando i dati hanno una distribuzione gaussiana. Ecco come questo modello converte i dati in forma ellittica e i punti che sono lontani dalle coordinate di questa forma sono considerati outlier e per questo si trova il determinante minimo di covarianza. È come quando si trova la covarianza nel set di dati, quindi il minimo è escluso e quale è maggiore, quei punti sono considerati anomalie. L'immagine seguente mostra la spiegazione di questo rilevamento dell'algoritmo.
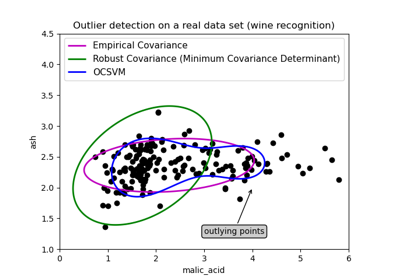
Ha la stessa linea di codice del solo per regolare i dati e prevedere in esso che identifica anomalie nei dati in cui è assegnato. -1 per anomalie e +1 per dati normali o in-liers.
from sklearn.covariance import EllipticEnvelope model1 = EllipticEnvelope(contaminazione = 0.1) # fit model model1.fit(X_treno) model1.predict(X_test)
Para obtener más información sobre los parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... y la tabla de comparación, vedere Informazioni sull'ellittica sklearn
Queste sono alcune delle tecniche utilizzate nel rilevamento delle anomalie che aiutano a conoscere i punti che sono lontani dalla normalità e che portano molti cambiamenti imprevisti nei dati. A seconda del luogo o del tipo di dati, Ha vari effetti ed è utilizzato in molti luoghi e settori come l'industria medica, l'industria automobilistica, il settore edile, l'industria alimentare (anomalie diverse dagli standard prescritti), industria della difesa, eccetera.
Fatemi sapere se avete domande.. Grazie per aver letto. 👩🕵️♀️👩🎓 Buona giornata.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





