introduzione
Gli scienziati dei dati sono una razza di animali pigri!! Detestiamo la pratica di eseguire manualmente qualsiasi lavoro ripetibile. Ci terrorizziamo al solo pensiero di svolgere noiose attività manuali e quando ci troviamo di fronte a un, cerchiamo di automatizzarlo in modo che il mondo diventi un posto migliore.
Abbiamo ospitato alcuni incontri in India negli ultimi mesi e volevamo vedere cosa stavano facendo alcuni dei migliori incontri in tutto il mondo. Per un essere umano normale, questo significherebbe sfogliare le pagine della riunione e trovare queste informazioni manualmente.
Non per uno scienziato dei dati!
Cosa sono gli incontri?
Meetup può essere meglio inteso come un incontro auto-organizzato di persone per raggiungere un obiettivo predefinito. Meetup.com è la rete di gruppi locali più grande al mondo. La missione di Meetup è “rivitalizzare la comunità locale e aiutare le persone di tutto il mondo ad organizzarsi”.
Il processo di ricerca della riunione può richiedere molto tempo (preferisco dirlo). Ci sono più limitazioni allegate (che ho spiegato nella prossima sezione). Ma, Come farebbe uno scienziato dei dati a svolgere questo compito per risparmiare tempo?? Certo, cercherebbe di automatizzare questo processo!
In questo articolo, Ti presenterò l'approccio di un data scientist per individuare i gruppi di riunioni utilizzando Python. Prendendo questo come riferimento, puoi trovare gruppi situati in qualsiasi angolo della terra. Puoi anche aggiungere il tuo livello di analisi per scoprire alcune idee interessanti.
Iscriviti a Data Hackathon 3.X: vinci un buono Amazon del valore 10.000 rupie (~ 200 dollari)
La sfida con la messa a fuoco manuale
Supponiamo che tu voglia scoprire e partecipare ad alcuni dei migliori incontri nella tua zona.. Ovviamente, puoi fare questo compito manualmente, ma ci sono alcune sfide che devi affrontare:
- Potrebbero esserci diversi gruppi con nomi e scopi simili. Diventa difficile trovare quelli corretti solo leggendo i nomi.
- Supponiamo che tu stia cercando incontri nella scienza dei dati, dovrai navigare manualmente attraverso ciascuno dei gruppi, ver varios parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... para juzgar su calidad (ad esempio, frequenza delle riunioni, appartenenza, recensione media, eccetera.) e poi prendi la decisione di unirti al gruppo o meno, Mi sembra un sacco di lavoro!
- Cosa c'è di più, se hai esigenze specifiche, come se volessi vedere gruppi presenti in più città, finirai per sfogliare manualmente i gruppi di ogni città; Già mi rimpicciolì al pensiero.
Supponiamo di essere in una località con più di 200 gruppi nella tua area di interesse. Come faresti a trovare il meglio??

La soluzione del data scientist
In questo articolo, ne ho individuati diversi Meetup di Python di città in India, EE. UU., Regno Unito, HK, TW e Australia. Di seguito sono riportati i passaggi che eseguirò:
- Ottieni informazioni da meetup.com utilizzando l'API che hanno fornito.
- Sposta i dati su un DataFrame e
- Analizzalo e unisciti ai gruppi giusti
Questi passaggi sono abbastanza facili da eseguire. Prossimo, Vi elenco i passaggi per eseguirli. Come menzionato prima, questo è solo l'inizio delle possibilità che si aprono. È possibile utilizzare queste informazioni per acquisire un patrimonio di conoscenze su varie comunità in tutto il mondo..
passo 0: importare librerie
Di seguito è riportato l'elenco delle librerie che ho utilizzato per codificare questo progetto.
import urllib import json importa panda come pd importa matplotlib.pyplot come plt da geopy.geocoders import Nominatim
Ecco una rapida panoramica di queste librerie:
- urllib: Questo modulo fornisce un'interfaccia di alto livello per ottenere dati dal World Wide Web.
- json (Notazione dell'oggetto script Java): la biblioteca jsonJSON, o Notazione degli oggetti JavaScript, Si tratta di un formato di scambio dati leggero e facile da leggere e scrivere per gli esseri umani, e facile da analizzare e generare per le macchine. Viene comunemente utilizzato nelle applicazioni Web per inviare e ricevere informazioni tra un server e un client. La sua struttura si basa su coppie chiave-valore, rendendolo versatile e ampiamente adottato nello sviluppo di software.. puede analizar JSON a partir de cadenas o archivos. La libreria analizza JSON in un dizionario o elenco Python.
- panda: Utilizzato per manipolazioni e operazioni di dati strutturati. Utilizzato molto per la preparazione e l'elaborazione dei dati.
- matplotlib: Utilizzato per tracciare un'ampia varietà di grafici, a partire dal istogrammiGli istogrammi sono rappresentazioni grafiche che mostrano la distribuzione di un set di dati. Sono costruiti dividendo l'intervallo di valori in intervalli, oh "Bidoni", e il conteggio della quantità di dati che cadono in ogni intervallo. Questa visualizzazione consente di identificare i modelli, tendenze e variabilità dei dati in modo efficace, facilitare l'analisi statistica e il processo decisionale informato in varie discipline.... hasta gráficos de líneas y gráficos de calor.
- geocodificatori: Libreria di geocodifica semplice e coerente scritta in Python.
passo 1: usa l'API per leggere i dati in formato JSON
Puoi ottenere dati da qualsiasi sito Web in vari modi:
- Tieni traccia delle pagine web utilizzando una combinazione di librerie come BeautifulSoup e Scrapy. Trova le tendenze sottostanti in html usando le espressioni regolari per estrarre i dati richiesti.
- Se il sito Web fornisce un'API (Interfaccia di programmazione applicazioni), usalo per ottenere i dati. Puoi capirlo come un intermediario tra un programmatore e un'applicazione. Questo broker accetta richieste e, se tale richiesta è consentita, restituisce i dati.
- Anche strumenti come import.io possono aiutarti a farlo.
Per i siti Web che forniscono un'API, di solito è il modo migliore per ottenere le informazioni. Il primo metodo sopra menzionato è suscettibile di modifiche al layout su una pagina e, A volte, può essere molto complicato. fortunatamente, Meetup.com offre diversi API per accedere ai dati richiesti. Usando questa API, possiamo accedere alle informazioni su vari gruppi.
Per accedere alla soluzione automatizzata basata su API, ci vorrebbe coraggio per sig_id e sigla (diverso per utenti diversi). Segui i passaggi seguenti per accedere a questi.
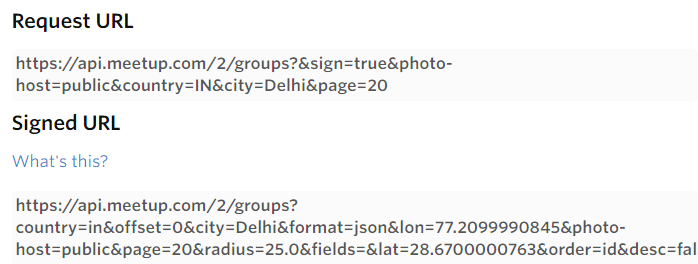
passo 2: Genera un elenco di URL firmati per tutte le città indicate
Ora, dovremmo richiedere un URL firmato per ogni ricerca (nel nostro caso, cittadina + tema) e l'output di questi URL firmati fornirà le informazioni dettagliate sui gruppi corrispondenti:
- Crea un elenco di tutte le città
- Crea un oggetto per accedere alla longitudine e alla latitudine della città.
- Accedi alla città dall'elenco fornito e genera la latitudine e la longitudine utilizzando “geolocalizzatore “ oggetto
- Genera stringa URL con gli attributi richiesti come formato dati (json), Radio (numero di miglia dal centro della città, 50), tema (Pitone), latitudine e longitudine
- Ripeti questo passaggio per ogni città e aggiungi tutti gli URL in un elenco
posti = [ "San Francisco", "California", "boston ", "New York" , "Pennsylvania", "Colorado", "Seattle", "Washington","gli angeli", "San Diego", "Houston", "austin", "Kansas", "delhi", "chennai", "bangalore", "Mumbai" , "Sydney","Melbourne", "Perth", "Adelaide", "Brisbane", "Launceston", "Newcastle" , "pechino", "shanghai", "Suzhou", "Shenzhen","Guangzhou","Dongguan", "Taipei", "Chengdu", "Hong Kong"] URL = [] #elenchi di URL raggio = 50.0 #aggiungi il raggio in miglia data_format = "json" argomento = "Pitone" #aggiungi la tua scelta di argomento qui sig_id = "########" # inizializza con il tuo ID segno, controlla la chiave firmata campione sig = "##############" # inizializza con il tuo segno, controlla la chiave firmata campione
per posto in posti:
posizione = geolocator.geocode(luogo)
URL.append("https://api.meetup.com/2/groups?offset=0&formato=" + formato dei dati + "&lon=" + str(posizione.longitudine) + "&argomento=" + argomento + "&photo-host=pubblico&pagina=500&raggio=" + str(raggio)+"&campi=&anni =" + str(posizione.latitudine) + "&ordine=id&disc = falso&sig_id=" +sig_id + "&sig =" + sigla)
passo 3: leggere i dati dall'URL e accedere alle funzioni pertinenti in un DataFrame
Ora, abbiamo un elenco di URL per tutte le città. Prossimo, useremo la libreria urllib per leggere i dati in formato JSON. Dopo, leggeremo i dati in una lista prima di convertirli in un DataFrame.
città,nazione,valutazione,nome,membri = [],[],[],[],[] per URL negli URL: risposta = urllib.urlopen(URL) data = json.loads(risposta.leggi()) dati = dati["risultati"] #accesso solo ai dati della chiave dei risultati per i dati : città.append(io['città']) country.append(io['nazione']) valutazione.append(io['valutazione']) nome.append(io['nome']) membri.append(io['membri']) df = pd.DataFrame([città,nazione,valutazione,nome,membri]).T df.columns=['città','nazione','valutazione','nome','membri']
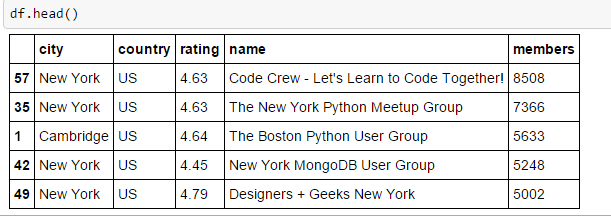
passo 4: confronta i gruppi Meetup in varie città
È ora di analizzare i dati ora e trovare i gruppi giusti in base a varie metriche, come il numero dei membri, Le qualifiche, la città e gli altri. Ecco alcuni risultati di base, che ho generato per gruppi di pitoni in diverse città dell'India, EE. UU., Regno Unito, HK, TW e Australia.
Per saperne di più su questi codici Python, Puoi leggere articoli sull'esplorazione e la visualizzazione dei dati usando Python
Numero di gruppi Python in sei paesi
freq = df.groupby('nazione').città.conta()
fig = plt.figure(figsize=(8,4))
ax1 = fig.add_subplot(121)
ax1.set_xlabel('Nazione')
ax1.set_ylabel("Conteggio dei gruppi")
ax1.set_title("Numero di gruppi Meetup Python")
freq.plot(tipo='bar')  Sopra puoi notare che gli Stati Uniti sono il leader nei gruppi di incontri Python. This stats can also help us to estimate the penetration of python in US data science industry compare to others.
Sopra puoi notare che gli Stati Uniti sono il leader nei gruppi di incontri Python. This stats can also help us to estimate the penetration of python in US data science industry compare to others.
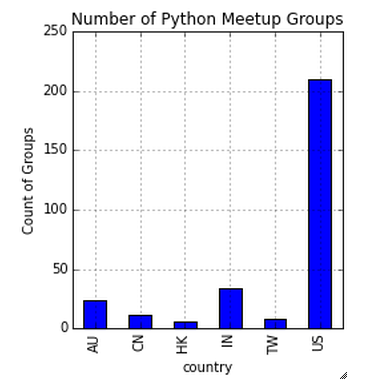 Sopra puoi notare che gli Stati Uniti sono il leader nei gruppi di incontri Python.
Sopra puoi notare che gli Stati Uniti sono il leader nei gruppi di incontri Python. Dimensione media dei gruppi in tutti i paesi
freq = df.groupby('nazione').membri.sum()/df.groupby('nazione').membri.conta()
fig = plt.figure(figsize=(8,4))
ax1 = fig.add_subplot(121)
ax1.set_xlabel('Nazione')
ax1.set_ylabel("Membri medi in ogni gruppo")
ax1.set_title("Gruppi Meetup Python")
freq.plot(tipo='bar')
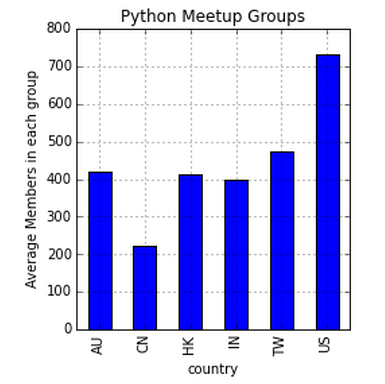
Un'altra volta, EE. UU. Emerge come leader nel numero medio di membri in ogni gruppo, mentre CN ha la media più bassa.
Valutazione media dei gruppi in tutti i paesi
freq = df.groupby('nazione').rating.sum()/df.groupby('nazione').rating.count()
fig = plt.figure(figsize=(8,4))
ax1 = fig.add_subplot(121)
ax1.set_xlabel('Nazione')
ax1.set_ylabel('Voto medio')
ax1.set_title("Gruppi Meetup Python")
freq.plot(tipo='bar')
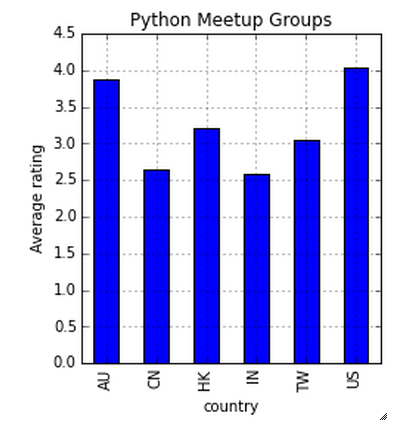 AU e EE. UU. Hanno una valutazione media simile (~ 4) in tutti i gruppi.
AU e EE. UU. Hanno una valutazione media simile (~ 4) in tutti i gruppi.
Il 2 i migliori gruppi di ogni paese
df=df.sort(['nazione','membri'], ascendente=[falso,falso])
df.groupby('nazione').testa(2)
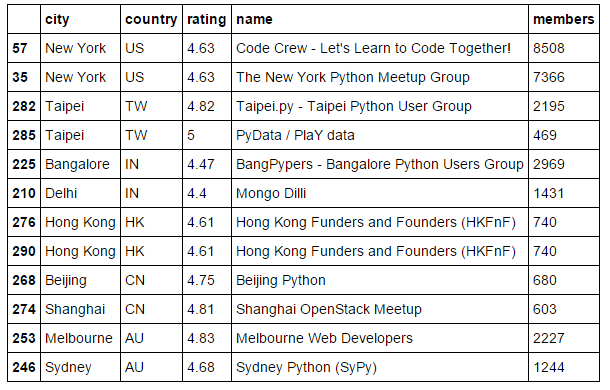
È tempo di identificare i due gruppi principali in ogni paese in base al numero di membri. Puoi anche identificare i gruppi in base alla valutazione. Qui ho fatto un'analisi di base per illustrare questo approccio. Puoi accedere anche ad altre API per trovare informazioni come eventi imminenti, numero di eventi, durata degli eventi e altri e quindi unire tutte le informazioni pertinenti in base a group_id (o valore chiave).
Codice finale
Di seguito è riportato il codice finale per questo esercizio, puoi giocare con esso inserendo il tuo sig_id e sig chiave e cercare più risultati da diversi argomenti in diverse città. L'ho anche caricato su GitHub.
import urllib import json importa panda come pd importa matplotlib.pyplot come plt da geopy.geocoders import Nominatim
geolocator = Per nome() #creare oggetto
posti = [ "San Francisco", "California", "boston ", "New York" , "Pennsylvania", "Colorado", "Seattle", "Washington","gli angeli", "San Diego", "Houston", "austin", "Kansas", "delhi", "chennai", "bangalore", "Mumbai" , "Sydney","Melbourne", "Perth", "Adelaide", "Brisbane", "Launceston", "Newcastle" , "pechino", "shanghai", "Suzhou", "Shenzhen","Guangzhou","Dongguan", "Taipei", "Chengdu", "Hong Kong"]
# accedi a meetup.com. se non hai un account, allora per favore registrati # Vai su https://secure.meetup.com/meetup_api/console/?percorso=/2/gruppi # Negli argomenti come "Pitone", inserisci un argomento a tua scelta. e clicca su mostra risposta # copia la chiave firmata. nella chiave cantata, copiare sig_id e sig e inizializzare le variabili sig_id e sig # chiave firmata campione : "https://api.meetup.com/2/groups?offset=0&formato=json&topic=python&photo-host=pubblico&pagina=20&raggio=25,0&campi=&ordine=id&disc = falso&sig_id=******&sig = ****************"
URL = [] #elenchi di URL raggio = 50.0 #aggiungi il raggio in miglia data_format = "json" #puoi aggiungere un altro formato come XML argomento = "Pitone" #aggiungi la tua scelta di argomento qui
sig_id = "186640998" # inizializza con il tuo ID segno, controlla la chiave firmata campione sig = "6dba1b76011927d40a45fcbd5147b3363ff2af92" # inizializza con il tuo segno, controlla la chiave firmata campione
per posto in posti:
posizione = geolocator.geocode(luogo)
URL.append("https://api.meetup.com/2/groups?offset=0&formato=" + formato dei dati + "&lon=" + str(posizione.longitudine) + "&argomento=" + argomento + "&photo-host=pubblico&pagina=500&raggio=" + str(raggio)+"&campi=&anni =" + str(posizione.latitudine) + "&ordine=id&disc = falso&sig_id=" +sig_id + "&sig =" + sigla)
città,nazione,valutazione,nome,membri = [],[],[],[],[] per URL negli URL: risposta = urllib.urlopen(URL) data = json.loads(risposta.leggi()) dati = dati["risultati"] per i dati : città.append(io['città']) country.append(io['nazione']) valutazione.append(io['valutazione']) nome.append(io['nome']) membri.append(io['membri']) df = pd.DataFrame([città,nazione,valutazione,nome,membri]).T df.columns=['città','nazione','valutazione','nome','membri'] df.sort(['membri','valutazione'], ascendente=[falso, falso])
freq = df.groupby('nazione').città.conta()
fig = plt.figure(figsize=(8,4))
ax1 = fig.add_subplot(121)
ax1.set_xlabel('Nazione')
ax1.set_ylabel("Conteggio dei gruppi")
ax1.set_title("Numero di gruppi Meetup Python")
freq.plot(tipo='bar')
freq = df.groupby('nazione').membri.sum()/df.groupby('nazione').membri.conta()
ax1.set_xlabel('Nazione')
ax1.set_ylabel("Membri medi in ogni gruppo")
ax1.set_title("Gruppi Meetup Python")
freq.plot(tipo='bar')
freq = df.groupby('nazione').rating.sum()/df.groupby('nazione').rating.count()
ax1.set_xlabel('Nazione')
ax1.set_ylabel('Voto medio')
ax1.set_title("Gruppi Meetup Python")
freq.plot(tipo='bar')
df=df.sort(['nazione','membri'], ascendente=[falso,falso])
df.groupby('nazione').testa(2)
Note finali
In questo articolo, Analizziamo l'applicazione Python per automatizzare un processo manuale e il livello di precisione per trovare i gruppi Meetup giusti. Usiamo l'API per accedere alle informazioni dal web e trasferirle su un DataFrame. Successivamente, analizziamo queste informazioni per generare approfondimenti pratici.
Possiamo rendere questa app più intelligente aggiungendo ulteriori informazioni come eventi imminenti, numero di eventi, RSVP e varie altre metriche. Puoi anche utilizzare questi dati per ottenere informazioni interessanti sulla comunità e sulle persone. Ad esempio, L'RSVP al tasso di partecipazione per rivedere la canalizzazione del tasso differisce da paese a paese?? Quali paesi pianificano in anticipo i loro incontri?
Fai un tentativo alla fine e condividi le tue conoscenze nella sezione commenti qui sotto.





