Panoramica
- Familiarícese con el sistema de archivos distribuidoUn sistema de archivos distribuido (DFS) permite el almacenamiento y acceso a datos en múltiples servidores, facilitando la gestione di grandi volumi di informazioni. Este tipo de sistema mejora la disponibilidad y la redundancia, ya que los archivos se replican en diferentes ubicaciones, lo que reduce el riesgo de pérdida de datos. Cosa c'è di più, permite a los usuarios acceder a los archivos desde distintas plataformas y dispositivos, promoviendo la colaboración y... l'Hadoop (HDFSHDFS, o File system distribuito Hadoop, Si tratta di un'infrastruttura chiave per l'archiviazione di grandi volumi di dati. Progettato per funzionare su hardware comune, HDFS consente la distribuzione dei dati su più nodi, garantire un'elevata disponibilità e tolleranza ai guasti. La sua architettura si basa su un modello master-slave, dove un nodo master gestisce il sistema e i nodi slave memorizzano i dati, facilitare l'elaborazione efficiente delle informazioni..)
- Comprendere i componenti di HDFS
introduzione
Attualmente, gestire enormi quantità di dati è comune. Dal tuo prossimo messaggio WhatsApp al tuo prossimo Tweet, stai creando dati ad ogni passo quando interagisci con la tecnologia. Ora moltiplicalo per 4.5 un miliardo di persone su Internet: La matematica è semplicemente fantastica!!
Ma, Ti sei mai chiesto come gestire quei dati? È memorizzato in una singola macchina?? Cosa succede se la macchina si guasta?? Ti mancheranno i tuoi adorabili tweet dal 3 SONO * tos *?
La risposta è no. Sono abbastanza sicuro che stai già pensando ad Hadoop. Hadoop è un quadro fantastico. Con Hadoop al tuo fianco, puoi sfruttare gli incredibili poteri del file system distribuito Hadoop (HDFS), il componente di archiviazione Hadoop. È probabilmente il componente più importante di Hadoop e richiede una spiegazione dettagliata.
Quindi, in questo articolo, impareremo cos'è veramente il file system distribuito Hadoop (HDFS) e i suoi vari componenti. Cosa c'è di più, vedremo cosa fa funzionare HDFS, questo è ciò che lo rende così speciale. Scopriamolo!
Sommario
- Che cos'è il file system distribuito Hadoop? (HDFS)?
- Quali sono i componenti di HDFS?
- Blocchi in HDFS?
- NomenodoEl NameNode es un componente fundamental del sistema de archivos distribuido Hadoop (HDFS). Su función principal es gestionar y almacenar la metadata de los archivos, como su ubicación en el clúster y el tamaño. Cosa c'è di più, coordina el acceso a los datos y asegura la integridad del sistema. Sin el NameNode, el funcionamiento de HDFS se vería gravemente afectado, ya que actúa como el maestro en la arquitectura del almacenamiento distribuido.... e HDFS
- Nodi dati in HDFS
- NodoNodo è una piattaforma digitale che facilita la connessione tra professionisti e aziende alla ricerca di talenti. Attraverso un sistema intuitivo, Consente agli utenti di creare profili, condividere esperienze e accedere a opportunità di lavoro. La sua attenzione alla collaborazione e al networking rende Nodo uno strumento prezioso per chi vuole ampliare la propria rete professionale e trovare progetti in linea con le proprie competenze e obiettivi.... secundario en HDFS
- Gestione della replica
- ReplicazioneLa replicación es un proceso fundamental en biología y ciencia, que se refiere a la duplicación de moléculas, células o información genética. En el contexto del ADN, la replicación asegura que cada célula hija reciba una copia completa del material genético durante la división celular. Este mecanismo es crucial para el crecimiento, desarrollo y mantenimiento de los organismos, así como para la transmisión de características hereditarias en las generaciones futuras.... de bloques
- Che cos'è un rack in Hadoop?
- Consapevolezza del rack
Che cos'è il file system distribuito Hadoop? (HDFS)?
È difficile mantenere grandi volumi di dati su una singola macchina. Perciò, i dati devono essere suddivisi in blocchi più piccoli e archiviati su più macchine.
I file system che gestiscono l'archiviazione su una rete di macchine sono chiamati file system distribuiti..
Il file system distribuito Hadoop (HDFS) è il componente di archiviazione di Hadoop. Tutti i dati archiviati in Hadoop sono archiviati in modo distribuito su un gruppo di macchine. Ma ha alcune proprietà che ne definiscono l'esistenza.
- Volumi enormi – Essendo un file system distribuito, è altamente in grado di memorizzare petabyte di dati senza problemi.
- Accesso ai dati – Si basa sulla filosofia che "il modello di elaborazione dei dati più efficiente è scrivere una volta e leggere molte volte".
- Economico – HDFS viene eseguito su un pool di hardware di base. Queste sono macchine economiche che possono essere acquistate da qualsiasi fornitore.
Quali sono i componenti del file system distribuito Hadoop (HDFS)?
HDFS ha due componenti principali, in termini generali: blocchi di dati e nodi che memorizzano quei blocchi di dati. Ma c'è più di quanto sembri. Quindi, esaminiamolo uno per uno per capirlo meglio.
Blocchi HDFS
HDFS divide un file in unità più piccole. Cada una de estas unidades se almacena en diferentes máquinas del grappoloUn cluster è un insieme di aziende e organizzazioni interconnesse che operano nello stesso settore o area geografica, e che collaborano per migliorare la loro competitività. Questi raggruppamenti consentono la condivisione delle risorse, Conoscenze e tecnologie, promuovere l'innovazione e la crescita economica. I cluster possono coprire una varietà di settori, Dalla tecnologia all'agricoltura, e sono fondamentali per lo sviluppo regionale e la creazione di posti di lavoro..... tuttavia, questo è trasparente per l'utente che lavora in HDFS. Per loro, sembra memorizzare tutti i dati su una singola macchina.
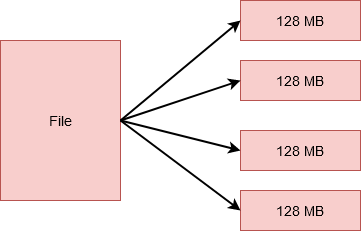
Queste unità più piccole sono le blocchi e HDFS. La dimensione di ciascuno di questi blocchi è 128 MB per impostazione predefinita, puoi facilmente cambiarlo secondo i requisiti. Perciò, se avessi un file di 512 MB, sarebbe diviso in 4 blocchi che immagazzinano 128 MB ciascuno.
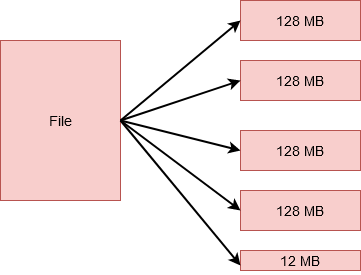
tuttavia, se avessi un file di 524 MB di dimensione, sarebbe diviso in 5 blocchi. 4 di questi conserverebbe 128 MB ciascuno, equivalente a 512 MB. E il quinto memorizzerebbe il 12 MB rimanenti. Giusto! Quest'ultimo blocco non occuperà il 128 MB completi di disco.
Ma, devi chiederti, Perché una quantità così grande in un unico blocco? Perché non più blocchi di 10 KB ciascuno? Bene, la quantità di dati che generalmente trattiamo in Hadoop è solitamente dell'ordine di petra byte o più.
Perciò, se creiamo piccoli blocchi, finiremmo con una quantità colossale di blocchi. Ciò significherebbe che avremmo a che fare con metadati altrettanto grandi riguardanti la posizione dei blocchi, che genererebbe un sacco di spese generali. E davvero non lo vogliamo!
Ci sono diversi vantaggi nell'archiviazione dei dati in blocchi piuttosto che nel salvare l'intero file.
- Il file stesso sarebbe troppo grande per essere archiviato su un singolo disco. Perciò, è saggio distribuirlo tra diverse macchine nel cluster.
- Consentirebbe anche una corretta distribuzione del carico di lavoro ed eviterebbe la limitazione di una singola macchina sfruttando il parallelismo..
Ora, devi chiederti, E le macchine nel cluster?? Come vengono archiviati i blocchi e dove vengono archiviati i metadati? Scopriamolo.
Nominato in HDFS
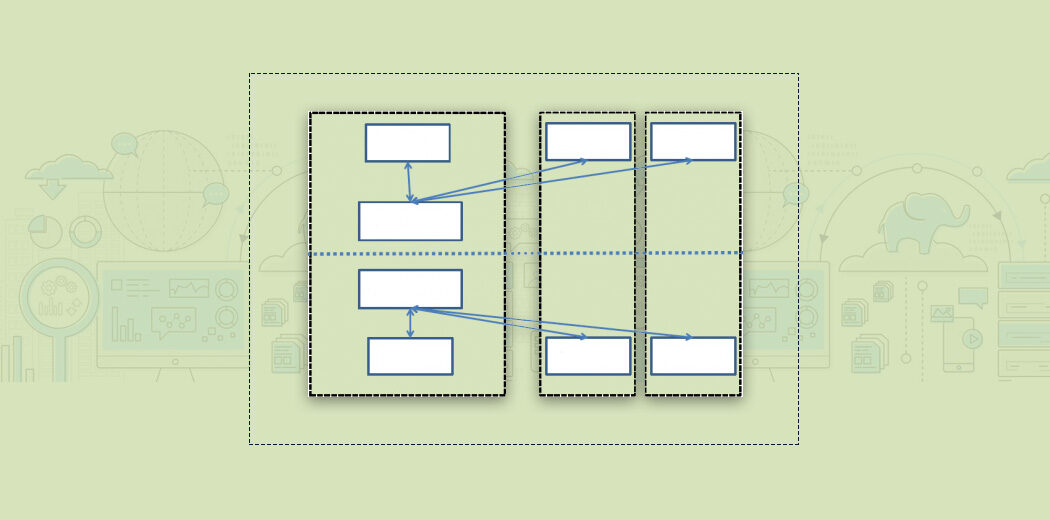
HDFS opera su un'architettura master-worker, esto significa que hay un nodo maestroIl "nodo maestro" es un componente clave en redes de computadoras y sistemas distribuidos. Se encarga de gestionar y coordinar las operaciones de otros nodos, asegurando una comunicación eficiente y el flujo de datos. Su función principal incluye la toma de decisiones, la asignación de recursos y la supervisión del rendimiento del sistema. La correcta implementación de un nodo maestro es fundamental para optimizar el funcionamiento general de la red.... y varios nodos trabajadores en el clúster. Il nodo principale è il Nomenodo.
Nomenodo è il nodo principale in esecuzione su un nodo separato nel cluster.
- Gestire lo spazio dei nomi del file system, che è l'albero del file system o la gerarchia di file e directory.
- Memorizza le informazioni come proprietari di file, permessi dei file, eccetera. per tutti i file.
- Conosce anche la posizione di tutti i blocchi in un file e la loro dimensione.
Tutte queste informazioni sono conservate in modo persistente sul disco locale sotto forma di due file: Fsimage e Modifica registrazione.
- Fsimage memorizza le informazioni su file e directory nel file system. Per i file, memorizza il livello di replica, modifica e tempi di accesso, permessi di accesso, i blocchi che compongono il file e le loro dimensioni. Per le directory, memorizza l'ora e i permessi di modifica.
- Modifica registrazione In secondo luogo, tiene traccia di tutte le operazioni di scrittura che il client esegue. Questo viene aggiornato periodicamente ai metadati in memoria per soddisfare le richieste di lettura.
Ogni volta che un client desidera scrivere informazioni su HDFS o leggere informazioni da HDFS, si connette con lui Nomenodo. Il Namenode restituisce la posizione dei blocchi al client e l'operazione viene eseguita.
sì, è vero, il Namenode non memorizza i blocchi. Per quello, abbiamo nodi separati.
Nodi dati in HDFS
Nodi dati sono i nodi di lavoro. Sono hardware entry-level a basso costo che possono essere facilmente aggiunti al cluster.
Nodi dati sono responsabili della conservazione, riaverlo, replicare, rimuovere, eccetera. di blocchi quando richiesto dal Namenode.
Inviano periodicamente battiti cardiaci al Namenode in modo che sia consapevole della sua salute. Con quello, un Nodo datiDataNode es un componente clave en arquitecturas de big data, utilizado para almacenar y gestionar grandes volúmenes de información. Su función principal es facilitar el acceso y la manipulación de datos distribuidos en clústeres. A través de su diseño escalable, DataNode permite a las organizaciones optimizar el rendimiento, mejorar la eficiencia en el procesamiento de datos y garantizar la disponibilidad de la información en tiempo real.... también envía una lista de bloques que se almacenan en él para que Namenode pueda mantener la asignación de bloques a Datanodes en su memoria.
Ma oltre a questi due tipi di nodi nel cluster, c'è anche un altro nodo chiamato nodo del nome secondario. Vediamo di cosa si tratta.
Nodo del nome secondario in HDFS
Supponiamo di dover riavviare il Nomenodo, cosa può succedere in caso di guasto. Ciò significherebbe che dobbiamo copiare Fsimage dal disco alla memoria. Cosa c'è di più, dovremmo anche copiare l'ultima copia di Edit Log in Fsimage per tenere traccia di tutte le transazioni. Ma se riavviamo il nodo dopo molto tempo, quindi il registro delle modifiche potrebbe essere diventato più grande. Ciò significherebbe che ci vorrebbe molto tempo per applicare le transazioni del registro di modifica. E in questo periodo, il filesystem sarebbe offline. Perciò, risolvere questo problema, portiamo il Nodo del nome secondario.
Nodo del nome secondario è un altro nodo presente nel cluster il cui compito principaleèunire regolarmente il registro di modifica con Fsimage e produrre punti di controllo dei metadati del file system in memoria del primario. Questo è anche noto come Checkpoint.

Ma la procedura del checkpoint è molto costosa dal punto di vista computazionale e richiede molta memoria, motivo per cui il nodo del nome secondario viene eseguito su un nodo separato del cluster.
tuttavia, nonostante il nome, il Namenode secondario non agisce come Namenode. È lì solo per fare Checkpoint e conservare una copia dell'ultimo Fsimage.
Gestione della replica in HDFS
Ora, una delle migliori caratteristiche di HDFS è la replica a blocchi, il che lo rende molto affidabile. Ma, Come replichi i blocchi e dove li conservi? Rispondiamo a queste domande ora.
Replica a blocchi
HDFS è un componente di archiviazione affidabile di Hadoop. Questo perché ogni blocco archiviato nel file system viene replicato su diversi nodi di dati nel cluster. Questo rende HDFS fault tolerant.
Il fattore di replica predefinito in HDFS è 3. Ciò significa che ogni blocco avrà altre due copie, ciascuno memorizzato in DataNode separati sul cluster. tuttavia, questo numero è configurabile.
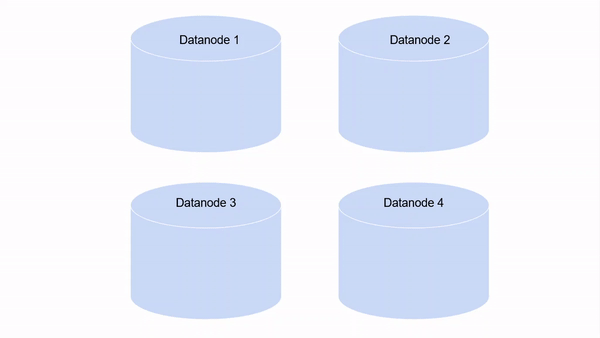
Ma ti starai chiedendo, Ciò non significa che stiamo occupando troppo spazio di archiviazione? Ad esempio, se abbiamo 5 blocchi di 128 MB ciascuno, che equivale a 5 * 128 * 3 = 1920 MB. Vero. Ma questi nodi sono hardware di base. Possiamo facilmente ridimensionare il cluster per aggiungere più di queste macchine. Il costo dell'acquisto delle macchine è molto inferiore al costo della perdita di dati!!
Ora, devi chiederti, In che modo Namenode decide in quale Datanode memorizzare le repliche?? Bene, prima di rispondere a questa domanda, dovremmo dare un'occhiata a cosa è un Rack in Hadoop.
Che cos'è un rack in Hadoop?
UN Lo scaffale è un insieme di macchine (30-40 e Hadoop) che sono memorizzati nella stessa posizione fisica. Ci sono più rack in un cluster Hadoop, tutti collegati tramite interruttori.
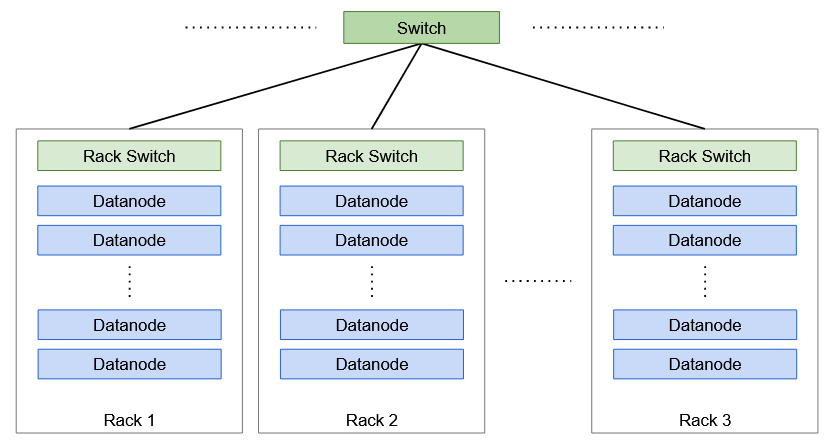
Consapevolezza del rack
Lo storage di replica è un compromesso tra affidabilità e larghezza di banda di lettura / scrivere. Per aumentare l'affidabilità, dobbiamo archiviare le repliche dei blocchi in diversi rack e Datanodes per aumentare la tolleranza ai guasti. Mentre la larghezza di banda di scrittura è inferiore quando le repliche sono archiviate sullo stesso nodo. Perciò, Hadoop ha una strategia predefinita per affrontare questo enigma, anche conosciuto come Consapevolezza del rack algoritmo.
Ad esempio, se il fattore di replicazione di un blocco è 3, la prima replica è memorizzata nello stesso Datanode su cui scrive il client. La seconda replica è archiviata in un Datanode diverso ma in un rack diverso, scelto a caso. Mentre la terza replica è archiviata nello stesso rack della seconda ma in un Datanode diverso, di nuovo scelto a caso. tuttavia, se il fattore di replica fosse più alto, le seguenti repliche verrebbero archiviate su nodi di dati casuali nel cluster.
Note finali
Spero che tu abbia già una solida comprensione di cosa sia il file system distribuito Hadoop (HDFS), quali sono i suoi componenti importanti e come memorizza i dati. tuttavia, ci sono ancora alcuni altri concetti che dobbiamo trattare riguardo al Hadoop Distributed File System (HDFS), ma questa è una storia per un altro articolo.
Per adesso, Ti consiglio di leggere i seguenti articoli per capire meglio Hadoop e questo mondo di Big Data.
Finalmente, ma non meno importante, consiglio di leggere Hadoop: La guida definitiva di Tom White. Questo articolo è stato molto ispirato da lui.





