Panoramica
- Noi presentiamo 21 strumenti open source per l'apprendimento automatico che potresti non aver incontrato
- Ogni strumento open source qui aggiunge un aspetto diverso al repertorio di uno scienziato dei dati
- Il nostro focus è principalmente sugli strumenti per cinque aspetti dell'apprendimento automatico: per i non programmatori (Ludwig, arancia, KNIME), implementazione del modello (CoreML, Tensorflow.js), Grandi dati (Hadoop, Scintilla), Visione computerizzata(SimpleCV), PNL(StanfordNLP), apprendimento audio e di rinforzo (Palestra OpenAI)
introduzione
Amo l'open source apprendimento automatico Comunità. La maggior parte del mio apprendimento come aspirante e poi come scienziato dei dati affermato proveniva da risorse e strumenti open source..
Se non hai ancora abbracciato la bellezza degli strumenti open source nell'apprendimento automatico, ti stai perdendo!! La comunità open source è enorme e ha un incredibile atteggiamento di supporto verso i nuovi strumenti e l'adozione del concetto di democratizzazione dell'apprendimento automatico..
Dovresti già conoscere i popolari strumenti open source come R, Pitone, Quaderni Jupyter, eccetera. Ma c'è un mondo oltre questi strumenti popolari.: un luogo in cui esistono strumenti di machine learning nascosti. Questi non sono così eminenti come le loro controparti., ma possono salvare la vita di molte attività di machine learning.
In questo articolo, vedremo 21 di questi strumenti open source per apprendimento automatico. Ti consiglio vivamente di prenderti un po 'di tempo per analizzare ciascuna delle categorie che ho menzionato.. C'è MOLTO da imparare oltre a ciò che normalmente impariamo in corsi e video.
Si noti che molte di queste sono librerie / Strumenti basati su Python perché siamo onesti: Python è un linguaggio di programmazione versatile come potremmo ottenere!!
Abbiamo diviso gli strumenti di machine learning open source in 5 categorie:
- Strumenti di machine learning open source per non programmatori
- Implementazione del modello di Machine Learning
- Strumenti Open Source per Big Data
- Visione artificiale, PNL e audio
- Apprendimento rinforzato
1. Strumenti di machine learning open source per non programmatori
L'apprendimento automatico può sembrare complesso per le persone che non hanno un background tecnico o di programmazione. È un campo vasto e posso immaginare quanto possa sembrare scoraggiante quel primo passo.. Una persona senza esperienza di programmazione può avere successo nell'apprendimento automatico??
Bene, si scopre che puoi! Ecco alcuni strumenti che possono aiutarti a superare l'abisso ed entrare nel famoso mondo del machine learning:
- Uber Ludwig: Ludwig di Uber è una cassetta degli attrezzi costruita su Top of TensorFlow. Ludwig nos permite entrenar y probar modelos de apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute... sin la necesidad de escribir código. Tutto ciò che devi fornire è un file CSV contenente i tuoi dati, un elenco di colonne da utilizzare come input e un elenco di colonne da utilizzare come output; Ludwig farà il resto. È molto utile per la sperimentazione, in quanto è possibile costruire modelli complessi con pochissimo sforzo e in breve tempo, ed è possibile modificarlo e giocarci prima di decidere di implementarlo nel codice.
- KNIME: KNIME consente di creare flussi di lavoro completi di data science utilizzando un'interfaccia drag-and-drop. Fondamentalmente, può implementare tutto, dall'ingegneria delle funzionalità alla selezione delle funzionalità e persino all'aggiunta di modelli di machine learning predittivo al flusso di lavoro in questo modo. Questo approccio di implementazione visiva dell'intero flusso di lavoro del modello è molto intuitivo e può essere davvero utile quando si lavora su dichiarazioni di problemi complessi..

- Arancia: Non è necessario sapere come codificare prima di poter utilizzare Orange per estrarre i dati, elaborare i numeri e ottenere informazioni. È possibile eseguire attività che vanno dalla visualizzazione di base alla manipolazione, trasformazione e data mining. Orange è diventato popolare ultimamente tra studenti e insegnanti grazie alla sua facilità d'uso e alla possibilità di aggiungere più plugin per integrare il suo set di funzionalità..
C'è molto più interessante software gratuito e open source che fornisce una grande accessibilità per eseguire l'apprendimento automatico senza scrivere (tanto) codice.
Dall'altra parte della medaglia, ci sono alcuni servizi a pagamento pronti all'uso che puoi prendere in considerazione, Che cosa Google AutoML, Azure Studio, Cognizione profonda, e Robot dati.
2. Strumenti di machine learning open source per la distribuzione di modelli
L'implementazione di modelli di machine learning è uno dei compiti più dimenticati ma importanti da considerare. Quasi certamente emergerà nelle interviste, quindi potresti essere esperto nell'argomento.
Ecco alcuni framework che possono semplificare la distribuzione del progetto preferito su un dispositivo reale.
- MLflusso: MLFlow è progettato per funzionare con qualsiasi libreria o algoritmo di machine learning e gestire l'intero ciclo di vita, compresa la sperimentazione, riproducibilità e implementazione di modelli di machine learning. MLFlow è attualmente in alpha e ha 3 componenti: azione supplementare, progetti e modelli.

- CoreML de Apple: CoreML è un framework popolare che può essere usato per integrare modelli di machine learning nella tua app iOS / Apple Watch / Apple TV / MacOS ·. La parte migliore di CoreML è che non richiede una vasta conoscenza delle reti neurali o dell'apprendimento automatico.. Una soluzione vantaggiosa per tutti!
- TensorFlow Lite: TensorFlow Lite è un set di strumenti per aiutare gli sviluppatori a eseguire modelli TensorFlow su dispositivi mobili (Android e iOS), integrato e IoT. È progettato per semplificare l'esecuzione dell'apprendimento automatico sui dispositivi, “sul bordo” della rete, invece di inviare e ricevere dati da un server.
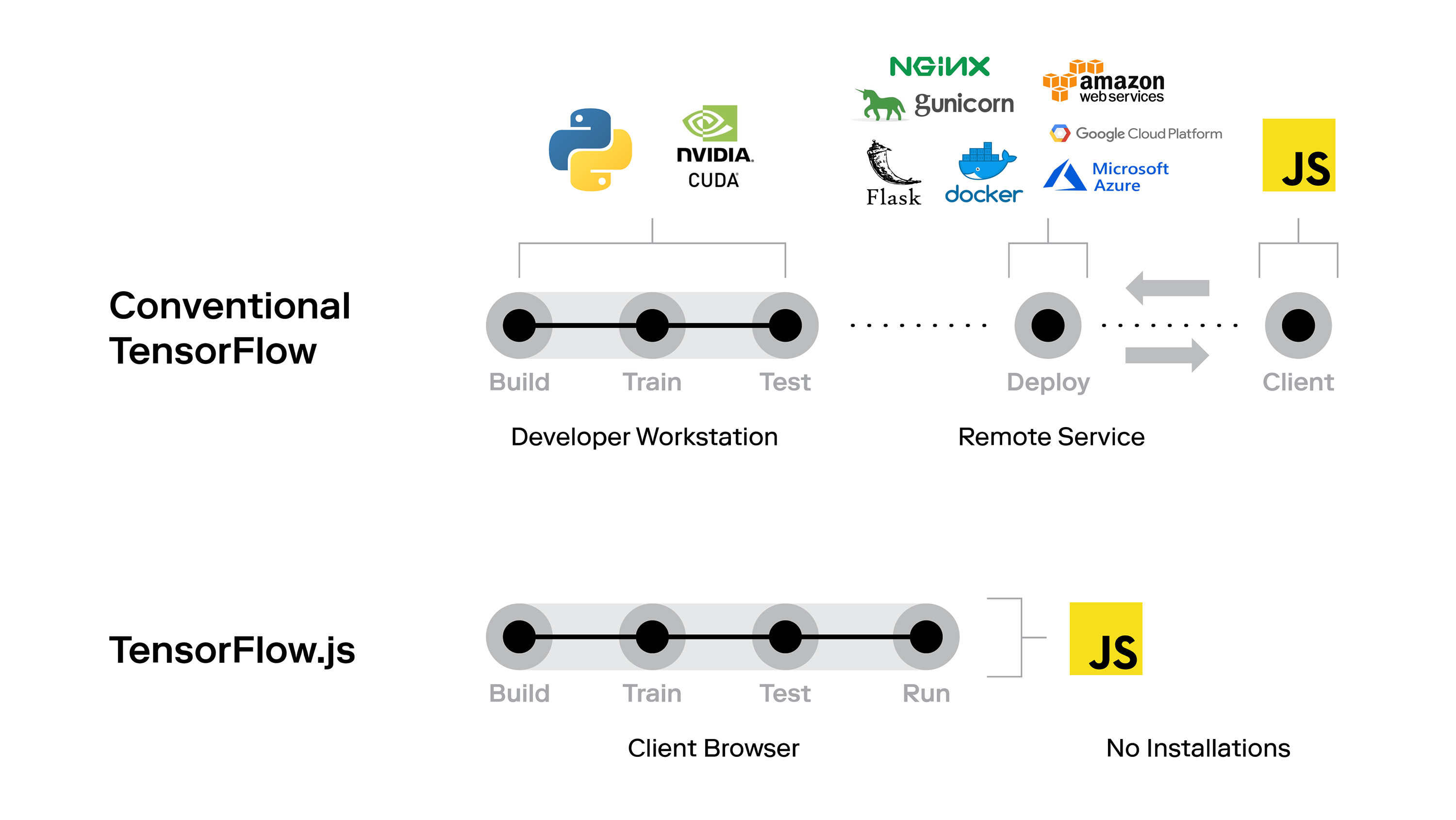
- TensorFlow.js – TensorFlow.js potrebbe essere la scelta preferita per la distribuzione del modello di machine learning sul Web. Si tratta di una libreria open source che consente di creare e addestrare modelli di machine learning nel browser. È disponibile con accelerazione GPU e supporta automaticamente anche WebGL. È possibile importare modelli pre-addestrati esistenti e anche riqualificare i modelli di machine learning esistenti completi nel browser stesso!!
3. Strumenti di machine learning open source per big data
I Big Data sono un campo che si occupa di modi per analizzare, estrarre informazioni sistematicamente o, altrimenti, gestione di set di dati troppo grandi o complessi per essere trattati con software applicativi tradizionali per l'elaborazione dati. Immagina di elaborare milioni di tweet in un giorno per l'analisi del sentiment. Questo sembra un compito enorme., Non è così?
Non preoccuparti! Prossimo, Sono inclusi alcuni strumenti che possono aiutarti a lavorare con i Big Data.
- Hadoop: Uno degli strumenti più importanti e rilevanti per lavorare con i Big Data è il progetto Hadoop. Hadoop è un framework che consente l'elaborazione distribuita di grandi set di dati su gruppi di computer utilizzando semplici modelli di programmazione. È progettato per scalare da singoli server a migliaia di macchine, ognuno dei quali offre elaborazione e archiviazione locali.
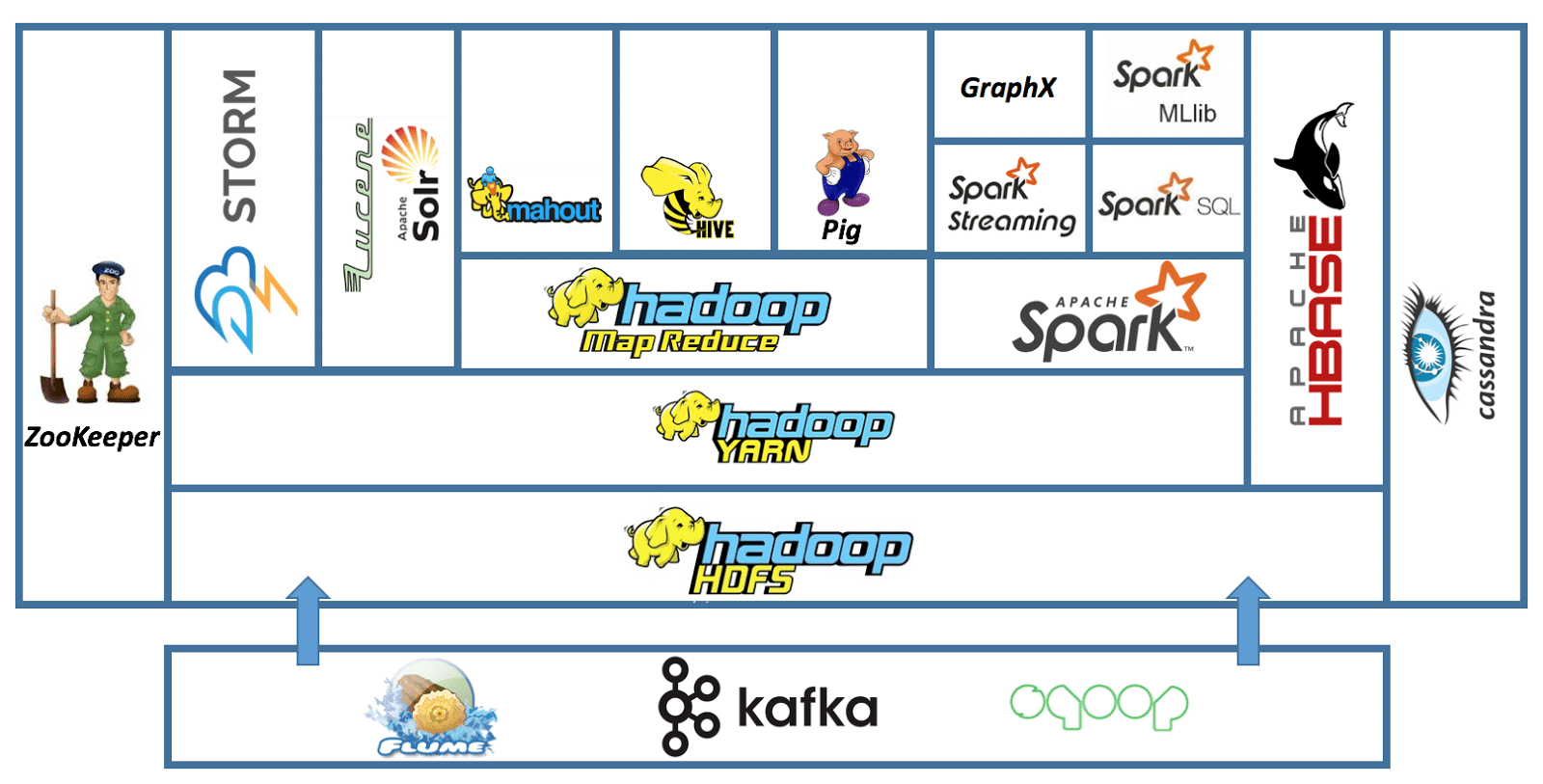
- Scintilla – scintilla: Apache SparkApache Spark è un motore di elaborazione dati open source che consente l'analisi di grandi volumi di informazioni in modo rapido ed efficiente. Il suo design si basa sulla memoria, che ottimizza le prestazioni rispetto ad altri strumenti di elaborazione batch. Spark è ampiamente utilizzato nelle applicazioni di big data, Apprendimento automatico e analisi in tempo reale, grazie alla sua facilità d'uso e... se considera un sucesor natural de Hadoop para aplicaciones de big data. Il punto chiave di questo strumento open source per i big data è che colma le lacune di Apache Hadoop per quanto riguarda l'elaborazione dei dati.. curiosamente, Spark è in grado di gestire sia i dati batch che i dati in tempo reale.
- Neo4j: Hadoop potrebbe non essere una buona scelta per tutti i problemi relativi ai big data. Ad esempio, Quando è necessario gestire un grande volume di dati di rete o problemi relativi alla grafica, come i social media o i modelli demografici, un Banca datiUn database è un insieme organizzato di informazioni che consente di archiviare, Gestisci e recupera i dati in modo efficiente. Utilizzato in varie applicazioni, Dai sistemi aziendali alle piattaforme online, I database possono essere relazionali o non relazionali. Una progettazione corretta è fondamentale per ottimizzare le prestazioni e garantire l'integrità delle informazioni, facilitando così il processo decisionale informato in diversi contesti.... de gráficos puede ser la elección perfecta.

4. Strumenti di machine learning open source per la visione artificiale, PNL e audio
“Se vogliamo che le macchine pensino, dobbiamo insegnare loro a vedere”.
– Dr. Fei-Fei Li sulla visione artificiale
- SimpleCV: Devi aver usato OpenCV se hai lavorato su progetti di visione artificiale. Ma, Ti sei mai imbattuto in SimpleCV? SimpleCV consente di accedere a diverse librerie di visione artificiale ad alta potenza, come OpenCV, senza dover prima conoscere le profondità di bit, formati di file, spazi colore, gestione del buffer, Autovalori o archiviazione di matrice rispetto a bitmap. Questa è la visione artificiale semplificata.

- Tesseract OCR: Hai utilizzato app creative che ti consentono di scansionare documenti o acquistare fatture utilizzando la fotocamera del tuo smartphone o depositare denaro sul tuo conto bancario semplicemente scattando una foto di un assegno? Tutte queste applicazioni utilizzano ciò che chiamiamo OCR o software di riconoscimento ottico dei caratteri.. Tesseract è uno di quei motori OCR che ha la capacità di riconoscere più di 100 Le lingue pronto all'uso. Puoi anche imparare a riconoscere altre lingue.
- Rilevato: Detectron è il sistema software di Facebook AI Research che implementa algoritmi di rilevamento degli oggetti all'avanguardia, Compreso Vari modelli di rilevamento di oggetti pre-addestrati come. È scritto in Python e funziona con Caffè2 framework di deep learning.

- StanfordNLP: StanfordNLP è un pacchetto di analisi del linguaggio naturale Python. La parte migliore di questa libreria è che supporta più di 70 lingue umane! Contiene strumenti che possono essere utilizzati in una pipeline per
- Convertire una stringa contenente testo in linguaggio umano in elenchi di frasi e parole
- Generare forme di base di tali parole, le sue parti del discorso e le caratteristiche morfologiche, e
- Fornire un'analisi delle dipendenze della struttura sintattica

- BERT come servizio: Tutti gli appassionati di PNL avranno già sentito parlare di BERT, L'innovativa architettura NLP di Google, ma probabilmente non ti sei imbattuto in questo progetto molto utile. Bert-as-a-service utilizza BERT come codificatore di frasi e lo ospita come servizio tramite ZeroMQ, consente di mappare frasi in rappresentazioni a lunghezza fissa in sole due righe di codice.
- Google Magenta: Questa libreria fornisce utilità per la modifica dei dati di origine (principalmente musica e immagini), Utilizzare questi dati per addestrare modelli di Machine Learning e, Finalmente, generare nuovi contenuti da questi modelli.
- LibROSA ·: LibROSA è un pacchetto Python per l'analisi audio e musicale. Fornisce i componenti di base necessari per creare sistemi di recupero delle informazioni musicali. È ampiamente utilizzato nella pre-elaborazione dei segnali audio quando lavoriamo su applicazioni come la conversione da voce a testo con deep learning., eccetera.
Strumenti open source per l'apprendimento per rinforzo
RL è il nuovo talk della città quando si parla di Machine Learning. El objetivo del Apprendimento per rinforzoL'apprendimento per rinforzo è una tecnica di intelligenza artificiale che consente a un agente di imparare a prendere decisioni interagendo con un ambiente. Attraverso il feedback sotto forma di premi o punizioni, L'agente ottimizza il proprio comportamento per massimizzare le ricompense accumulate. Questo approccio viene utilizzato in una varietà di applicazioni, Dai videogiochi alla robotica e ai sistemi di raccomandazione, distinguendosi per la sua capacità di apprendere strategie complesse.... (RL) è quello di formare agenti intelligenti in grado di interagire con il loro ambiente e risolvere compiti complessi, con applicazioni reali alla robotica, auto autonome e altro ancora.
I rapidi progressi in questo campo sono stati guidati dal convincere gli agenti a giocare a giochi come gli iconici giochi per console Atari., il vecchio gioco del Go, o videogiochi giocati professionalmente come Dota 2 o Starcraft 2, tutto ciò fornisce ambienti difficili in cui nuovi algoritmi e idee possono essere rapidamente testati in modo sicuro e riproducibile. Ecco alcuni degli ambienti di allenamento più utili per RL:
- Google Ricerca Calcio: Google Research Football Environment è un nuovo ambiente RL in cui gli agenti mirano a dominare lo sport più popolare al mondo: calcio. Questo ambiente ti dà un grande controllo per addestrare i tuoi agenti RL., guarda il video per saperne di più:
- Palestra OpenAI: Gym è un insieme di strumenti per sviluppare e confrontare algoritmi di apprendimento per rinforzo. Sostiene l'insegnamento degli agenti di tutto, dal camminare a giocare a giochi come Pong o Flipper. Nella gif seguente, vedrai un agente che sta imparando a camminare.

- Unity AA Agenti: The Unity Machine Learning Agent Toolkit (ML-Agenti) è un componente aggiuntivo unity open source che consente a giochi e simulazioni di fungere da ambienti per la formazione intelligente degli agenti. Gli agenti possono essere addestrati attraverso l'apprendimento per rinforzo, apprendimento di imitazione, neuroevoluzione o altri metodi di apprendimento automatico attraverso un'API Python facile da usare.

- Progetto Malmo: La piattaforma Malmo è una sofisticata piattaforma di sperimentazione AI costruita su Minecraft e progettata per supportare la ricerca fondamentale nell'AI.. È sviluppato da Microsoft.
Note finali
Come deve essere stato evidente dal toolkit precedente, l'open source è la strada da percorrere quando consideriamo la scienza dei dati e i progetti relativi all'intelligenza artificiale. Probabilmente ho appena raschiato la punta dell'iceberg, ma ci sono numerosi strumenti disponibili per una varietà di attività che ti semplificano la vita come scienziato dei dati, hai solo bisogno di sapere dove guardare.
In questo articolo, abbiamo coperto 5 aree interessanti della scienza dei dati che nessuno parla molto di ML senza codice, Distribuzione ML, Grandi dati, Visione / PNL / Apprendimento del suono e del rinforzo. Personalmente, Penso che questi 5 le aree hanno il maggiore impatto quando si tiene conto del valore reale dell'IA.
Quali sono gli strumenti che pensi avrebbero dovuto essere in questa lista?? Scrivi i tuoi preferiti qui sotto per la comunità da conoscere!!





