Quanti algoritmi di impulso conosci?
Puoi nominare almeno due algoritmi di impulso nell'apprendimento automatico??
Gli algoritmi Boost esistono da anni e, tuttavia, solo di recente sono diventati mainstream nella comunità del machine learning. Ma, Perché questi algoritmi boost sono diventati così popolari??
Uno dei motivi principali per l'aumento dell'adozione di algoritmi di impulso sono le competenze di apprendimento automatico. Gli algoritmi di potenziamento danno ai modelli di machine learning superpoteri per migliorare la loro precisione di previsione. Una rapida occhiata alle competizioni Kaggle e DataHack Hackatones è una prova sufficiente – Gli algoritmi Boost sono molto popolari!
In poche parole, gli algoritmi di momentum spesso superano i modelli più semplici come la regressione logistica e alberi decisionali. Infatti, La maggior parte dei finalisti della nostra piattaforma DataHack utilizza un algoritmo boost o una combinazione di diversi algoritmi boost.

In questo articolo, Ti presenterò quattro popolari algoritmi di boost che puoi usare nel tuo prossimo apprendimento automatico hackathon o progetto.
4 Guida gli algoritmi nell'apprendimento automatico
- Máquina de aumento de gradienteGradiente è un termine usato in vari campi, come la matematica e l'informatica, per descrivere una variazione continua di valori. In matematica, si riferisce al tasso di variazione di una funzione, mentre in progettazione grafica, Si applica alla transizione del colore. Questo concetto è essenziale per comprendere fenomeni come l'ottimizzazione negli algoritmi e la rappresentazione visiva dei dati, consentendo una migliore interpretazione e analisi in... (GBM)
- Macchina per l'aumento del gradiente estremo (XGBM)
- LuceGBM
- CatBoost
Introduzione rapida a Boosting (Cos'è il potenziamento??)
Immagina questo scenario:
Hai creato un modello di regressione lineare che ti offre una precisione decente del 77% nel set di dati di convalida. Prossimo, decide di espandere il proprio portafoglio creando un modello k-nerest neighbor (KNN) e un albero decisionale modello sullo stesso set di dati. Questi modelli gli davano una precisione del 62% e il 89% nel set di convalida, rispettivamente.
È ovvio che i tre modelli funzionano in modi completamente diversi.. Ad esempio, il modello di regressione lineare tenta di catturare le relazioni lineari nei dati, mentre il modello dell'albero decisionale cerca di catturare la non linearità nei dati.
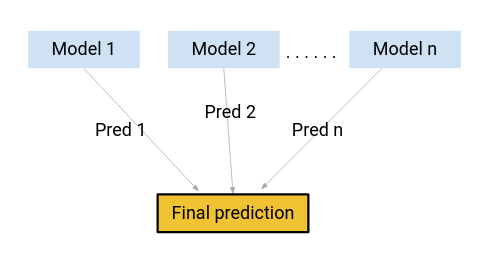
Cosa succede se, invece di utilizzare uno di questi modelli per fare le previsioni finali, usiamo una combinazione di tutti questi modelli?
Sto pensando a una media delle previsioni di questi modelli. Facendo questo, potremmo acquisire più informazioni dai dati, verità?
Questa è principalmente l'idea alla base dell'apprendimento insieme.. E da dove arriva la voglia??
L'impulso è una delle tecniche utilizzate dal concetto di apprendimento congiunto. Un algoritmo di impulso combina diversi modelli semplici (noti anche come studenti deboli o stimatori di base) per generare il risultato finale.
In questo articolo esamineremo alcuni degli algoritmi importanti per il momentum..
1. Macchina per l'aumento del gradiente (GBM)
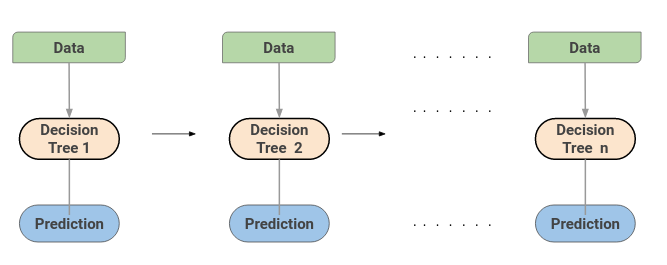
Una macchina per l'aumento del gradiente o GBM combina le previsioni di diversi alberi decisionali per generare le previsioni finali. Nota che tutti gli studenti deboli su una macchina per l'aumento del gradiente sono alberi decisionali.
Ma se usiamo lo stesso algoritmo, Com'è meglio usare un centinaio di alberi decisionali piuttosto che utilizzare un singolo albero decisionale?? In che modo i diversi alberi decisionali catturano segnali diversi? / informazioni sui dati?
Ecco il trucco: i nodi in ogni albero decisionale prendono un diverso sottoinsieme di caratteristiche per selezionare la migliore suddivisione. Ciò significa che i singoli alberi non sono tutti uguali e, così, può catturare segnali diversi dai dati.
Cosa c'è di più, ogni nuovo albero tiene conto degli errori o degli errori commessi dagli alberi precedenti. Perciò, ogni successivo albero decisionale si basa sugli errori degli alberi precedenti. Ecco come vengono costruiti in sequenza gli alberi in un algoritmo di macchina per l'aumento del gradiente.
Ecco un articolo che spiega il processo di ottimizzazione degli iperparametri per l'algoritmo GBM:
2. Macchina per l'aumento del gradiente estremo (XGBM)
Extreme Gradient Boosting o XGBoost è un altro algoritmo di boost popolare. Infatti, XGBoost è semplicemente una versione improvvisata dell'algoritmo GBM!! La procedura di lavoro di XGBoost è la stessa di GBM. Gli alberi in XGBoost sono costruiti in sequenza, cercando di correggere gli errori degli alberi sopra.
Ecco un articolo che spiega intuitivamente la matematica dietro XGBoost e implementa anche XGBoost in Python:

Ma ci sono alcune caratteristiche che rendono XGBoost un po' migliore di GBM:
- Uno dei punti più importanti è che XGBM implementa la preelaborazione parallela (a nivel de nodoNodo è una piattaforma digitale che facilita la connessione tra professionisti e aziende alla ricerca di talenti. Attraverso un sistema intuitivo, Consente agli utenti di creare profili, condividere esperienze e accedere a opportunità di lavoro. La sua attenzione alla collaborazione e al networking rende Nodo uno strumento prezioso per chi vuole ampliare la propria rete professionale e trovare progetti in linea con le proprie competenze e obiettivi....) che lo rende più veloce di GBM.
- XGBoost también incluye una variedad de técnicas de regolarizzazioneLa regolarizzazione è un processo amministrativo che cerca di formalizzare la situazione di persone o entità che operano al di fuori del quadro giuridico. Questa procedura è essenziale per garantire diritti e doveri, nonché a promuovere l'inclusione sociale ed economica. In molti paesi, La regolarizzazione viene applicata in contesti migratori, Lavoro e fiscalità, consentire a chi si trova in situazione irregolare di accedere ai benefici e tutelarsi da possibili sanzioni.... que reducen el sobreajuste y mejoran el rendimiento general. Puoi selezionare la tecnica di regolarizzazione impostando gli iperparametri dell'algoritmo XGBoost
Obtenga información sobre los diferentes hiperparámetros de XGBoost y cómo juegan un papel en el proceso de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... del modelo aquí:
Cosa c'è di più, se stai usando l'algoritmo XGBM, non devi preoccuparti di imputare valori mancanti nel tuo set di dati. Il modello XGBM può gestire da solo i valori mancanti. Durante il processo di formazione, il modello apprende se i valori mancanti devono essere nel nodo sinistro o destro.
3. LuceGBM
L'algoritmo boost LightGBM sta diventando sempre più popolare di giorno in giorno grazie alla sua velocità ed efficienza. LightGBM può gestire facilmente grandi quantità di dati. Ma nota che questo algoritmo non funziona bene con un piccolo numero di punti dati.
Prendiamoci un momento per capire perché è così..
Gli alberi in LightGBM hanno la crescita delle foglie, invece di una crescita di livelli. Dopo la prima divisione, la divisione successiva viene eseguita solo sul nodo foglia che ha la perdita delta più alta.
Considera l'esempio che ho illustrato nell'immagine seguente:
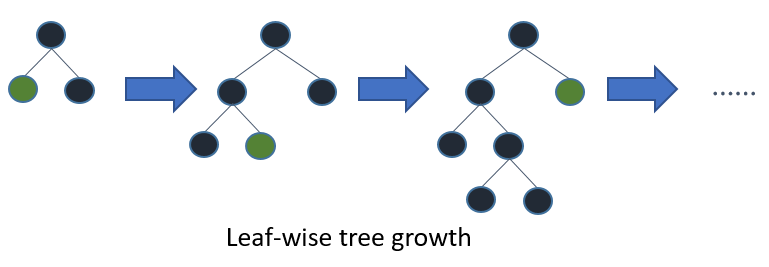
Dopo la prima divisione, il nodo sinistro ha avuto una perdita maggiore ed è selezionato per la divisione successiva. Ora, abbiamo tre nodi foglia e il nodo foglia centrale ha avuto la perdita maggiore. L'algoritmo di divisione per fogli di LightGBM consente di lavorare con grandi insiemi di dati.
Per accelerare il processo di formazione, LightGBM utiliza un método basado en istogrammiGli istogrammi sono rappresentazioni grafiche che mostrano la distribuzione di un set di dati. Sono costruiti dividendo l'intervallo di valori in intervalli, oh "Bidoni", e il conteggio della quantità di dati che cadono in ogni intervallo. Questa visualizzazione consente di identificare i modelli, tendenze e variabilità dei dati in modo efficace, facilitare l'analisi statistica e il processo decisionale informato in varie discipline.... para seleccionar la mejor división. Para cualquier variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... continuo, invece di usare i singoli valori, questi si dividono in contenitori o secchi. Ciò accelera il processo di formazione e riduce l'utilizzo della memoria..
Ecco un eccellente articolo che confronta gli algoritmi LightGBM e XGBoost:
4. CatBoost
Come suggerisce il nome, CatBoost è un algoritmo boost in grado di gestire variabili categoriali nei dati. La maggior parte degli algoritmi di apprendimento automatico non può funzionare con stringhe o categorie nei dati. Perciò, la conversione delle variabili categoriali in valori numerici è un passaggio essenziale di pre-elaborazione.
CatBoost può gestire internamente variabili categoriali nei dati. Queste variabili vengono trasformate in numeriche utilizzando varie statistiche su combinazioni di caratteristiche.
Se vuoi capire la matematica dietro come queste categorie vengono convertite in numeri, puoi leggere questo articolo:

Un altro motivo per cui CatBoost è ampiamente utilizzato è che funziona bene con il set predefinito di iperparametri. Perciò, come utente, non dobbiamo perdere molto tempo a regolare gli iperparametri.
Ecco un articolo che implementa CatBoost in una sfida di apprendimento automatico:
Note finali
In questo articolo, Copriamo le basi dell'apprendimento d'insieme e discutiamo il 4 tipi di algoritmi di rinforzo. Sei interessato a conoscere altri metodi di co-learning?? Dovresti fare riferimento al seguente articolo:
Con quali altri algoritmi di boost hai lavorato?? Hai avuto successo con questi algoritmi di boost?? Condividi i tuoi pensieri ed esperienze con me nella sezione commenti qui sotto..





