Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
Panoramica
- Aprenda el concepto básico de minería de datos
- Comprender las aplicaciones de la minería de datos
Prerequisiti
- Comprensión básica de Python
- Conocimientos básicos de DataBase
¡Bienvenidos chicos!
Aquí te voy a dar una breve comprensión de los conceptos básicos de Data Mining. Sabemos que en todas partes hay datos en varios formatos que se almacenarán en una Banca datiUn database è un insieme organizzato di informazioni che consente di archiviare, Gestisci e recupera i dati in modo efficiente. Utilizzato in varie applicazioni, Dai sistemi aziendali alle piattaforme online, I database possono essere relazionali o non relazionali. Una progettazione corretta è fondamentale per ottimizzare le prestazioni e garantire l'integrità delle informazioni, facilitando così il processo decisionale informato in diversi contesti..... Según la escala de datos, podemos elegir una base de datos adecuada. Quindi, existen bases de datos populares que conocemos, como PostgreSQL, NoSQL, MongoDB, Microsoft SQL Server y muchas más.
In questo articolo, obtendrá una idea de la minería de datos.
Así que sigamos …
¿Qué es la minería de datos?
“Elaborazione dati”, que extrae los datos. In parole semplici, se define como encontrar insights ocultos (informazione) dal database, extraer patrones de los datos.
Existen diferentes algoritmos para diferentes tareas. La función de estos algoritmos es ajustarse al modelo. Estos algoritmos identifican las características de los datos. Ci sono 2 tipos de modelos.
1) Modelo predictivo
2) Modelo descriptivo
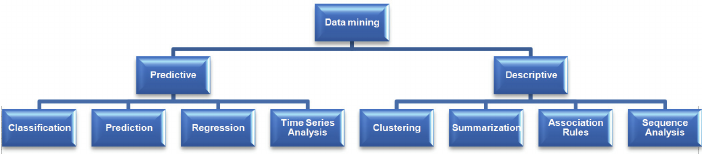
Tareas básicas de minería de datos
In questa sezione, veremos algunas de las funciones / tareas de minería.
1) Classificazione
Este término viene bajo apprendimento supervisionatoL'apprendimento supervisionato è un approccio di apprendimento automatico in cui un modello viene addestrato utilizzando un set di dati etichettati. Ogni input nel set di dati è associato a un output noto, consentendo al modello di imparare a prevedere i risultati per nuovi input. Questo metodo è ampiamente utilizzato in applicazioni come la classificazione delle immagini, Riconoscimento vocale e previsione delle tendenze, sottolineandone l'importanza in.... Los algoritmos de clasificación requieren que las clases se definan en función de variables. Las características de los datos definen a qué clase pertenece. El reconocimiento de patrones es uno de los tipos de problemas de clasificación en los que la entrada (Modello) se clasifica en diferentes clases en función de su similitud de clases definidas.
2) Predizione
En la vida real, a menudo vemos predecir cosas / valores futuros / o de otra manera basados en datos pasados y datos presentes. La predicción también es un tipo de tarea de clasificación. Según el tipo de aplicación, ad esempio, predecir inundaciones donde las variables dependientes son el nivel del agua del río, su humedad, escala de lluvia, eccetera. son los atributos.
3) Regressione
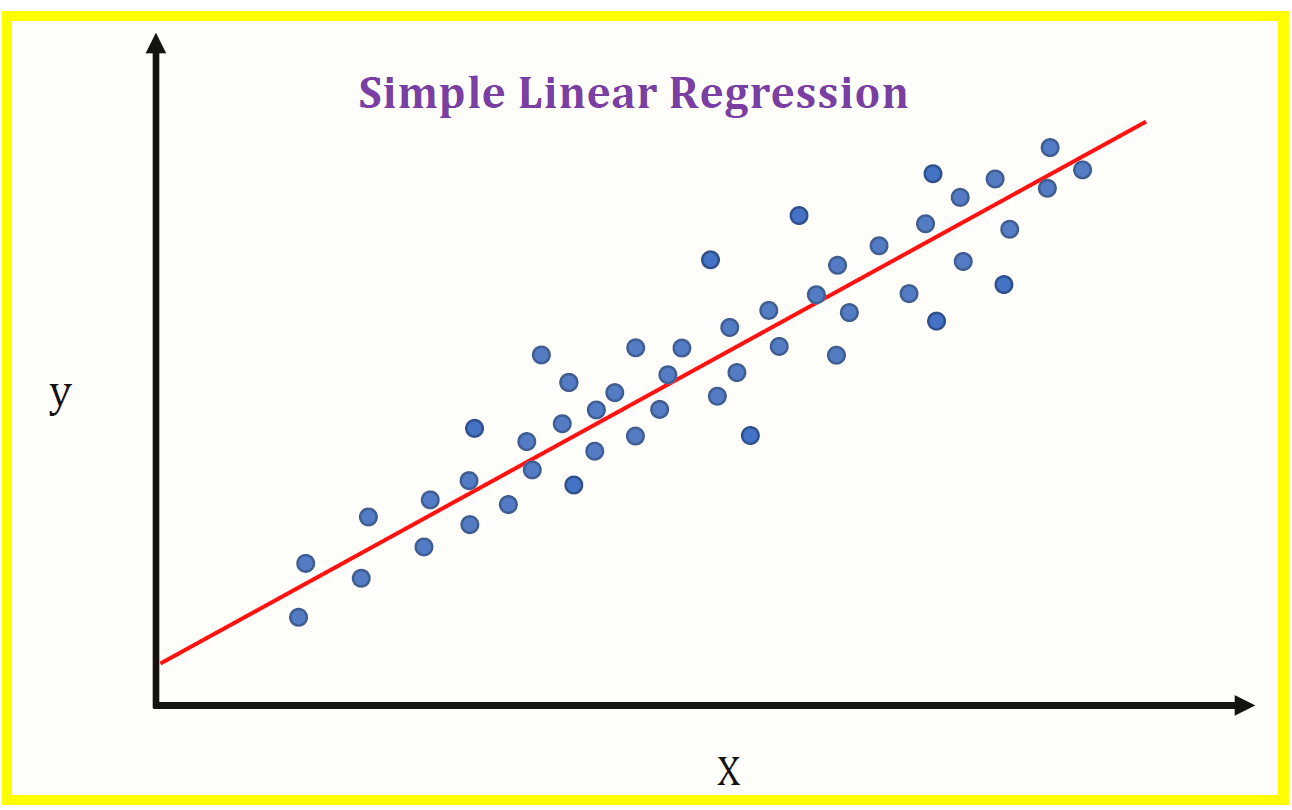
La regresión es una técnica estadística que se utiliza para determinar la relación entre las variables (X) y las variables dependientes (e). Existen pocos tipos de regresión como Lineal, Logistica, eccetera. La Regresión Lineal se usa en valores continuos (0,1,1,5,… .y así sucesivamente) y la Regresión Logística se usa cuando existe la posibilidad de solo dos eventos como pasa / fallimento, vero / impostore, sì / no, eccetera.
4) Analisi delle serie temporali
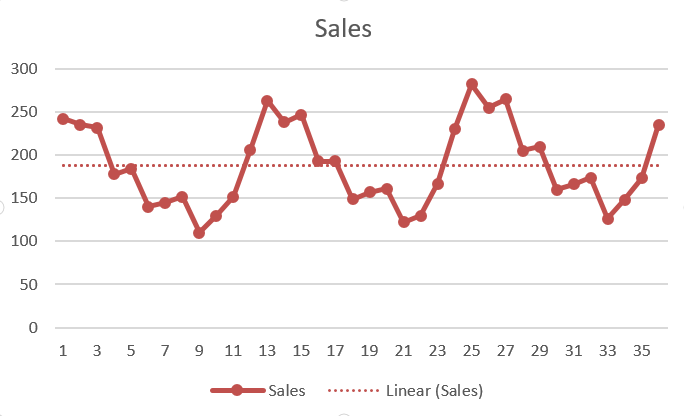
En el análisis de series de tiempo, un variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... cambia su valor según el tiempo. Significa que el análisis pasa por patrones de identificación de datos durante un período de tiempo. Puede ser variación estacional, variación irregular, tendencia secular y fluctuación cíclica. Ad esempio, lluvia anual, precio de la bolsa, eccetera.
5) Raggruppamento
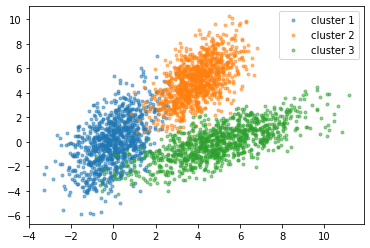
La agrupación es lo mismo que la clasificación, vale a dire, agrupa los datos. La agrupación en clústeres se incluye en el aprendizaje automático no supervisado. Es un proceso de dividir los datos en grupos basados en tipos de datos similares.
6) Riepilogo
El resumen no es más que caracterización o generalización. Recupera información significativa de los datos. También ofrece un resumen de variables numéricas como media, moda, medianoLa mediana è una misura statistica che rappresenta il valore centrale di un insieme di dati ordinati. Per calcolarlo, I dati sono organizzati dal più basso al più alto e viene identificato il numero al centro. Se c'è un numero pari di osservazioni, I due valori fondamentali sono mediati. Questo indicatore è particolarmente utile nelle distribuzioni asimmetriche, poiché non è influenzato da valori estremi...., eccetera.
7) Regole dell'associazione
Es la tarea principal de Data Mining. Ayuda a encontrar patrones apropiados y conocimientos significativos de la base de datos. La regla de asociación es un modelo que extrae tipos de asociaciones de datos. Ad esempio, Market Basket Analysis donde las reglas de asociación se aplican a la base de datos para saber qué artículos compran juntos el cliente.
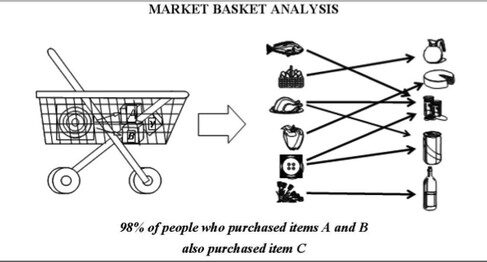
8) Descubrimiento de secuencia
También se llama análisis secuencial. Se utiliza para descubrir o encontrar el patrón secuencial en los datos.
Patrón secuencial significa el patrón que se basa puramente en una secuencia de tiempo. Estos patrones son similares a las reglas de asociación encontradas en la base de datos o los eventos están relacionados pero su relación se basa únicamente en el “Tiempo”.
Finora, hemos visto todas las funciones o tareas básicas de Data Mining. Sigamos adelante para saber más sobre la minería de datos …
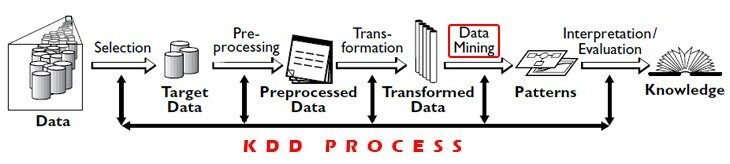
Minería de datos VS KDD (descubrimiento de conocimientos en la base de datos)
Elaborazione dati: Proceso de uso de algoritmos para extraer información significativa y patrones derivados del proceso KDD. Es un paso involucrado en KDD.
KDD: Es un proceso significativo de identificación de patrones e información significativa en los datos. La entrada que se le da a este proceso son los datos y la salida proporciona información útil a partir de los datos.
El proceso KDD consta de 5 Passi:
1) Selezione: Necesidad de obtener datos de diversas fuentes de datos, banche dati.
2) Pre-elaborazione: Este proceso de limpieza de datos en términos de datos incorrectos, valori mancanti, datos erróneos.
3) Trasformazione: Los datos de diversas fuentes deben convertirse y codificarse en algún formato para su preprocesamiento.
4) Estrazione dei dati: In questo processo, se aplican algoritmos a los datos transformados para lograr la salida o los resultados deseados.
5) Interpretazione / valutazione: Tiene que realizar algunas visualizaciones para presentar resultados de minería de datos que son muy importantes.
Aplicaciones de minería de datos
1) E-commerce
El comercio electrónico es una de sus aplicaciones en la vida real. Las empresas de comercio electrónico son como Amazon, Flipkart, Myntra, eccetera. Utilizan técnicas de minería de datos para ver la funcionalidad de cada producto de tal manera que “qué producto es visto más por el cliente también qué otro le gustó”.
2) Venta al por menor
Es otra aplicación de minería de datos del mercado minorista. Los minoristas encuentran el patrón de “frescura, frequenza, monetario (en términos de moneda)”. Los minoristas realizan un seguimiento de las ventas de productos y transacciones.
3) Formazione scolastica
La educación es un campo emergente y de tendencia en la actualidad. Se trata del descubrimiento de conocimientos a partir de datos educativos. El objetivo principal de esta aplicación es estudiar o identificar el patrón de comportamiento del estudiante en términos de aprendizaje futuro, efectos del estudio, conocimiento avanzado del aprendizaje, eccetera. Estas técnicas de minería de datos son utilizadas por las instituciones para tomar decisiones precisas y también predecir resultados adecuados.
Herramientas para minería de datos
– KNIME
-WEKA
-NARANJA
Algoritmos de minería de datos
- Raggruppamento di K-calze
- Supporta macchine vettoriali
- A priori
- KNN
- Bayes ingenuo
- CART y muchos más …
Estos son algunos algoritmos.
* Ahora le voy a dar información sobre las bibliotecas requeridas a continuación.
– A priori:
from apyori import apriori
– Raggruppamento di K-calze:
from kneed import KneeLocator
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.preprocessing import StandardScaler– Supporta macchine vettoriali:
from sklearn import svm
-Ingenuo Bayes:
from sklearn.naive_bayes import GaussianNB
-CARRO:
from sklearn.tree import DecisionTreeRegressor
-KNN:
fromsklearn.neighborsimportKNeighborsClassifier
Así que aquí hay algunas bibliotecas que deben instalarse mientras se realiza el algoritmo.
conclusione
Spero che il mio articolo ti sia piaciuto. Se hai qualche domanda, puede dejar comentarios a continuación. Grazie!
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





