Mappa piccola es un modelo de programación para procesar grandes conjuntos de datos con un paralelo, distribuito algoritmo en un clúster (fonte: Wikipedia). Map Reduce cuando se combina con HDFS se puede usar para manejar big data. Los principios fundamentales de este sistema HDFS-MapReduce, que comúnmente se conoce como Hadoop, se discutieron en nuestro post anterior.
La unidad básica de información que se utiliza en Riduci mappaMapReduce è un modello di programmazione progettato per elaborare e generare in modo efficiente set di dati di grandi dimensioni. Sviluppato da Google, Questo approccio suddivide il lavoro in attività più piccole, che sono distribuiti tra più nodi in un cluster. Ogni nodo elabora la sua parte e poi i risultati vengono combinati. Questo metodo consente di scalare le applicazioni e gestire enormi volumi di informazioni, essere fondamentali nel mondo dei Big Data.... es un par (chiave, valore). Todos los tipos de datos estructurados y no estructurados deben traducirse a esta unidad básica, antes de alimentar los datos al modelo MapReduce. Come suggerisce il nome, el modelo MapReduce consta de dos rutinas separadas, vale a dire, función de mapa y función de disminución. Este post lo ayudará a comprender la funcionalidad paso a paso del modelo Map-Reduce. El cálculo de una entrada (In altre parole, en un conjunto de pares) en el modelo MapReduce ocurre en tres etapas:
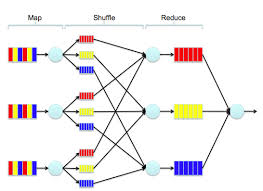
passo 1: la etapa del mapa
passo 2: la etapa de reproducción aleatoria
passo 3: la etapa de disminución.
Semánticamente, las fases de mapa y barajado distribuyen los datos, y la etapa de disminución realiza el cálculo. En este post analizaremos en detalle cada una de estas etapas.
[stextbox id=”section”] La etapa del mapa [/stextbox]
La lógica de MapReduce, a diferencia de otros marcos de datos, no se limita a conjuntos de datos estructurados. Además cuenta con una amplia capacidad para manejar datos no estructurados. La etapa del mapa es el paso crítico que lo hace factible. MapperMapper è uno strumento che facilita la visualizzazione e l'analisi dei dati geospaziali. Consente agli utenti di creare mappe interattive e personalizzabili, l'integrazione di informazioni diverse come i dati demografici, Infrastrutture e risorse naturali. Il suo utilizzo si estende in settori come l'urbanistica, Ricerca ambientale e gestione delle risorse, contribuire a un processo decisionale informato e allo sviluppo sostenibile. Mapper è diventato una soluzione essenziale in... aporta una estructura a los datos no estructurados. Come esempio, si quiero contar la cantidad de fotografías en mi computadora portátil por la ubicación (cittadina), donde se tomó la foto, necesito analizar datos no estructurados. El asignador crea pares (chiave, valore) a partir de este conjunto de datos. Per questo caso, la clave será la ubicación y el valor será la fotografía. Una vez que el asignador termina con su tarea, tenemos una estructura para todo el conjunto de datos.
En la etapa de mapa, el asignador toma un solo par (chiave, valore) como entrada y produce cualquier número de pares (chiave, valore) come uscita. Es esencial pensar en la operación del mapa como sin estado, In altre parole, su lógica opera en un solo par al mismo tiempo (inclusive si en la práctica se envían varios pares de entrada al mismo asignador). Per riassumere, para la etapa de mapa, el usuario simplemente diseña una función de mapa que asigna un par de entrada (chiave, valore) a cualquier número (inclusive ninguno) de pares de salida. La maggior parte delle volte, la etapa de mapa se utiliza simplemente para especificar la ubicación deseada del valor de entrada cambiando su clave.
[stextbox id=”section”] La etapa de barajar [/stextbox]
La etapa de reproducción aleatoria es manejada automáticamente por el marco MapReduce, In altre parole, el ingeniero no tiene nada que hacer en esta etapa. El sistema subyacente que implementa MapReduce enruta todos los valores asociados con una clave individual al mismo reductor.
[stextbox id=”section”] La etapa Reducir [/stextbox]
En la etapa de disminución, el reductor toma todos los valores asociados con una sola clave k y genera cualquier número de pares (chiave, valore). Esto resalta uno de los aspectos secuenciales del cálculo de MapReduce: todos los mapas deben finalizar antes de que pueda comenzar la etapa de disminución. Dado que el reductor tiene acceso a todos los valores con la misma clave, puede realizar cálculos secuenciales sobre estos valores. En el paso de disminución, el paralelismo se explota al observar que los reductores que operan en diferentes teclas pueden ejecutarse simultáneamente. Per riassumere, para la etapa de disminución, el usuario diseña una función que toma como entrada una lista de valores asociados con una sola tecla y genera cualquier número de pares. Spesso, las teclas de salida de un reductor son iguales a la tecla de entrada (in realtà, en el papel MapReduce original, la tecla de salida deve igual a la clave de entrada, pero Hadoop relajó esta restricción).
Generalmente, un programa en el paradigma MapReduce puede constar de muchas rondas (de forma general llamadas lavori) de diferentes funciones de mapa y disminución, hechas secuencialmente una tras otra.
[stextbox id=”section”] Un esempio [/stextbox]
Consideremos un ejemplo para comprender Map-Reduce en profundidad. Tenemos las siguientes 3 frasi:
1. El zorro marrón veloz
2. El zorro se comió al ratón
3. ¿Cómo ahora vaca marrón
Nuestro objetivo es contar la frecuencia de cada palabra en todas las frases. Imagine que cada una de estas oraciones adquiere una gran cantidad de memoria y, perché, se asignan a diferentes nodos de datos. Mapper se hace cargo de estos datos no estructurados y crea pares clave-valor. Per questo caso, la clave es la palabra y el valor es el recuento de esta palabra en el texto disponible en este nodoNodo è una piattaforma digitale che facilita la connessione tra professionisti e aziende alla ricerca di talenti. Attraverso un sistema intuitivo, Consente agli utenti di creare profili, condividere esperienze e accedere a opportunità di lavoro. La sua attenzione alla collaborazione e al networking rende Nodo uno strumento prezioso per chi vuole ampliare la propria rete professionale e trovare progetti in linea con le proprie competenze e obiettivi.... di dati. Come esempio, el nodo 1st Map genera 4 pares clave-valor: (il, 1), (brown, 1), (fox, 1), (quick, 1). Il primo 3 pares clave-valor van al primer reductor y el último valor clave al segundo reductor.
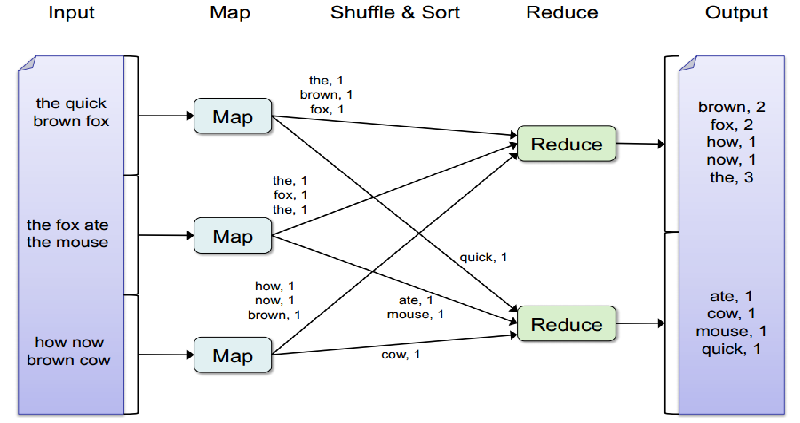
Allo stesso modo, las funciones de mapa 2 e 3 hacen el mapa de las otras dos oraciones. Al mezclar, todas las palabras similares llegan al mismo final. Una vez que se ordenan los pares clave-valor, la función reductora opera sobre estos datos estructurados para generar un resumen.
[stextbox id=”section”] Note finali: [/stextbox]
Tomemos un ejemplo del uso de la función Map-Reduce en la industria:
• En el buscador de Google:
– Construcción de índices para la búsqueda de Google
– Agrupación de posts para Google News
– Traducción automática estadística
• ¡En Yahoo !:
– Creación de índices para Yahoo! Cercare
– Detección de spam para Yahoo! Posta
• En Facebook:
– Elaborazione dati
– Optimización de anuncios
– Ejemplo de detección de spam
• En Amazon:
– Agrupación de productos
– Traducción automática estadística
La restricción de utilizar la función Map-reduce es que el usuario tiene que seguir un formato lógico. Esta lógica es generar pares clave-valor usando la función Mapa y después resumir usando la función Reducir. Ma, fortunatamente, la mayoría de las operaciones de manipulación de datos se pueden engañar en este formato. En el próximo post tomaremos algunos ejemplos como cómo hacer una fusión de conjuntos de datos, multiplicación de matrices, transposición de matrices, eccetera. usando Map-Reduce.
Il post ti è stato utile?? Comparta con nosotros otros ejemplos prácticos de la función Map-Reduce. Fateci sapere i vostri pensieri su questo post nella casella qui sotto..





