Questo post è stato pubblicato come parte del Blogathon sulla scienza dei dati.
Panoramica
introduzione
Apache SparkApache Spark è un motore di elaborazione dati open source che consente l'analisi di grandi volumi di informazioni in modo rapido ed efficiente. Il suo design si basa sulla memoria, che ottimizza le prestazioni rispetto ad altri strumenti di elaborazione batch. Spark è ampiamente utilizzato nelle applicazioni di big data, Apprendimento automatico e analisi in tempo reale, grazie alla sua facilità d'uso e... es un marco de procesamiento de datos que puede realizar rápidamente tareas de procesamiento en conjuntos de datos muy grandes y además puede repartir tareas de procesamiento de datos en múltiples computadoras, da solo o in combinazione con altri strumenti IT distribuiti. È un motore di analisi unificato ultraveloce per big data e machine learning.
Per supportare Python con Spark, La community di Apache Spark ha rilasciato uno strumento, PySpark. Con PySpark, puoi lavorare con RDD nel linguaggio di programmazione Python.
I componenti di Spark sono:
- Nucleo Scintilla
- Spark SQL
- Spark in streaming
- Spark MLlib
- GraficoX
- Scintilla R
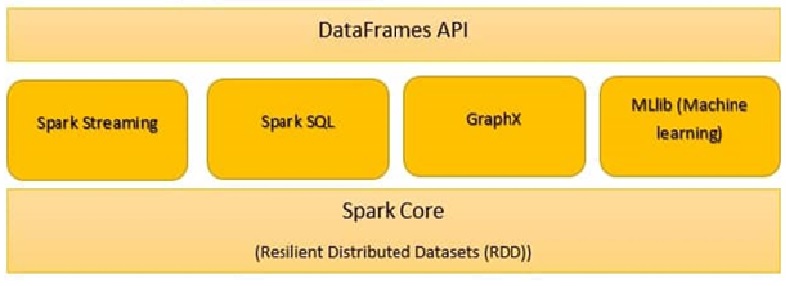
Nucleo Scintilla
Tutte le funzionalità fornite da Apache Spark sono centrate su Spark Core. Gestisci tutte le funzionalità di E / S essenziale. Utilizzato per l'invio delle attività e il ripristino in caso di arresto anomalo. Spark Core è integrato con una collezione speciale chiamata RDD (set di dati distribuiti resilienti). RDD è tra le astrazioni di Spark. Spark RDD maneja la partición de datos en todos los nodos de un grappoloUn cluster è un insieme di aziende e organizzazioni interconnesse che operano nello stesso settore o area geografica, e che collaborano per migliorare la loro competitività. Questi raggruppamenti consentono la condivisione delle risorse, Conoscenze e tecnologie, promuovere l'innovazione e la crescita economica. I cluster possono coprire una varietà di settori, Dalla tecnologia all'agricoltura, e sono fondamentali per lo sviluppo regionale e la creazione di posti di lavoro..... Li mantiene nel pool di memoria del cluster come una singola unità. Ci sono due operazioni eseguite in RDD:
Trasformazione: È una funzione che produce nuovi RDD da RDD esistenti.
Azione: in trasformazione, Gli RDD si creano a vicenda. Ma quando vogliamo lavorare con il set di dati effettivo, poi, a quel punto, usiamo Action.
Spark SQL
Il componente Spark SQL è un framework distribuito per l'elaborazione di dati strutturati. Spark SQL lavora per inserire informazioni strutturate e semi-strutturate. Consente inoltre applicazioni analitiche potenti e interattive su dati storici e in streaming.. DataFrame e SQL forniscono un modo comune per accedere a una serie di origini dati. La sua caratteristica principale è quella di essere un ottimizzatore basato su costi e tolleranza ai guasti di media query.
Spark in streaming
È un plug-in per l'API di base di Spark che consente l'elaborazione di flussi scalabili, alte prestazioni e tolleranza ai guasti delle trasmissioni di dati in tempo reale. Spark in streaming, raggruppa i dati in tempo reale in piccoli batch. Viene quindi consegnato al sistema batch per l'elaborazione.. Fornisce inoltre caratteristiche di tolleranza agli errori.
Grafico scintilla X:
GraphX su Spark è un'API per grafici ed esecuzione parallela di grafici. È un motore di analisi della grafica di rete e un data warehouse. Nei grafici è anche possibile raggruppare, classificare, viaggiare, cerca e trova percorsi.
SparkR:
SparkR fornisce un'implementazione di frame di dati distribuiti. Supporta operazioni come selezione, filtrato, aggregazione, ma in grandi set di dati.
Spark MLlib:
Spark MLlib viene utilizzato per eseguire l'apprendimento automatico su Apache Spark. MLlib è costituito da algoritmi e utilità popolari. MLlib su Spark è una libreria di machine learning scalabile che analizza algoritmi sia di alta qualità che ad alta velocità. Algoritmi di apprendimento automatico come regressione, classificazione, raggruppamentoIl "raggruppamento" È un concetto che si riferisce all'organizzazione di elementi o individui in gruppi con caratteristiche o obiettivi comuni. Questo processo viene utilizzato in varie discipline, compresa la psicologia, Educazione e biologia, per facilitare l'analisi e la comprensione di comportamenti o fenomeni. In ambito educativo, ad esempio, Il raggruppamento può migliorare l'interazione e l'apprendimento tra gli studenti incoraggiando il lavoro.., estrazione di modelli e filtraggio collaborativo. Primitive di apprendimento automatico di livello inferiore, come algoritmo generico di ottimizzazione della discesa del gradiente, sono presenti anche in MLlib.
Spark.ml è l'API di apprendimento automatico principale per Spark. Biblioteca Spark.ml offre un'API di primo livello basata su DataFrames per creare pipeline ML.
Gli strumenti Spark MLlib sono forniti di seguito:
- Algoritmi ML
- Caratterizzazione
- Condutture
- Persistenza
- Utilità
-
Algoritmi ML
Gli algoritmi ML costituiscono il nucleo di MLlib. Questi includono algoritmi di apprendimento comuni come la classificazione, regressione, raggruppamento collaborativo e filtraggio.
MLlib standardizza le API per aiutare a combinare più algoritmi in un'unica pipeline o flusso di lavoro. I concetti chiave sono le API Pipelines, dove il concept della pipeline si ispira al progetto scikit-learn.
Trasformatore:
Un trasformatore è un algoritmo che può trasformare un DataFrame in un altro DataFrame. tecnicamente, un trasformatore implementa un metodo di trasformazione (), che converte un DataFrame in un altro, generalmente aggiungendo una o più colonne. Come esempio:
Un trasformatore di funzionalità può accettare un DataFrame, leggere una colonna (come esempio, testo), assegnalo a una nuova colonna (come esempio, vettori di caratteristiche) e genera un nuovo DataFrame con la colonna mappata allegata.
Un modello di apprendimento può prendere un DataFrame, leggi la colonna contenente i vettori delle caratteristiche, prevedere l'etichetta per ogni vettore di feature e generare un nuovo DataFrame con etichette previste aggiunte come colonna.
EstimatoreIl "Estimatore" è uno strumento statistico utilizzato per dedurre le caratteristiche di una popolazione da un campione. Si basa su metodi matematici per fornire stime accurate e affidabili. Esistono diversi tipi di stimatori, come l'imparzialità e la coerenza, che vengono scelti in base al contesto e all'obiettivo dello studio. Il suo corretto utilizzo è essenziale nella ricerca scientifica, Sondaggi e analisi dei dati....:
Uno stimatore è un algoritmo che può essere adattato a un DataFrame per produrre un trasformatore. tecnicamente, uno stimatore implementa un metodo di adattamento (), che accetta un DataFrame e produce un Modello, cos'è un trasformatore?. Come esempio, un algoritmo di apprendimento come LogisticRegression è uno stimatore, e chiama in forma () addestrare un modello di regressione logistica, cos'è un modello e, perché, un trasformatore.
Transformer.transform () e Estimator.fit () sono apolidi. Nel futuro, gli algoritmi stateful possono essere compatibili con concetti alternativi.
Ogni istanza di un trasformatore o stimatore ha un ID univoco, que es útil para especificar parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... (descritto sotto).
-
Caratterizzazione
La caratterizzazione include l'estrazione, trasformazione, diminuzione della dimensionalità e selezione delle caratteristiche.
- L'estrazione delle funzionalità riguarda l'estrazione delle funzionalità dai dati grezzi.
- La trasformazione delle feature include il ridimensionamento, rinnovare o modificare le funzionalità
- La selezione delle funzionalità implica la scelta di un sottoinsieme di funzionalità indispensabili da un ampio set di funzionalità.
-
Condutture:
Una pipeline concatena più trasformatori e stimatori per specificare un flusso di lavoro AA. Fornisce anche strumenti per costruire, esaminare e regolare le pipeline ML.
Nell'apprendimento automatico, è comune eseguire una sequenza di algoritmi per elaborare e apprendere dai dati. MLlib representa un flujo de trabajo como OleodottoPipeline è un termine che viene utilizzato in una varietà di contesti, principalmente nella tecnologia e nella gestione dei progetti. Si riferisce a un insieme di processi o fasi che consentono il flusso continuo di lavoro dal concepimento di un'idea alla sua realizzazione finale. Nel campo dello sviluppo software, ad esempio, Una pipeline può includere la programmazione, Test e distribuzione, garantendo così una maggiore efficienza e qualità nel..., che è una sequenza di Fasi Pipeline (Trasformatori e Stimatori) da eseguire in un ordine specifico. Useremo questo semplice flusso di lavoro come esempio di esecuzione in questa sezione.
Esempio: l'esempio di pipeline mostrato di seguito esegue la preelaborazione dei dati in un ordine specifico come indicato di seguito:
1. Aplicar el método String Indexer para hallar el indiceIl "Indice" È uno strumento fondamentale nei libri e nei documenti, che consente di individuare rapidamente le informazioni desiderate. In genere, Viene presentato all'inizio di un'opera e organizza i contenuti in modo gerarchico, compresi capitoli e sezioni. La sua corretta preparazione facilita la navigazione e migliora la comprensione del materiale, rendendolo una risorsa essenziale sia per gli studenti che per i professionisti in vari settori.... de las columnas categóricas
2. Applicare la codifica OneHot per le colonne categoriali
3. Applica l'indicizzatore di stringhe per la colonna “etichetta” da variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... de salida
4. VectorAssembler si applica sia alle colonne categoriali che alle colonne numeriche. VectorAssembler è un trasformatore che combina un determinato elenco di colonne in un'unica colonna vettoriale.
Il flusso di lavoro della pipeline eseguirà la modellazione dei dati nell'ordine specifico sopra.
da pyspark.ml.feature importa oneHotEncoderEstimator, Metodo StringIndexer, VectorAssembler
categoricoColonne = ['lavoro', «coniugale», «istruzione», 'predefinito', 'abitazione', 'prestito'] fasi = [] for categoricalCol in categoricalColumns: stringIndexer = StringIndexer(inputCol = categoricicalCol, outputCol = categoricicalCol + 'Indicizzatore') encoder = OneHotEncoderEstimator(inputCols=[stringIndexer.getOutputCol()], outputCols=[categoricicalCol + "Vec ·"]) fasi += [stringIndexer, codificatore] label_stringIdx = StringIndexer(inputCol="depositare", outputCol="etichetta") fasi += [label_stringIdx] numericoColonne = ['età', 'equilibrio', 'durata'] assemblerInputs = [C + "Vec ·" for c in categoricColumns] + numericColumns Vassembler = VectorAssembler(inputCols = assemblerInputs, outputCol="caratteristiche") fasi += [Vassembler]from pyspark.ml import Pipeline pipeline = Pipeline(fasi = fasi) pipelineModel = pipeline.fit(df) df = pipelineModel.transform(df) selectedCols = ['etichetta', 'caratteristiche'] + cols df = df.select(selectedCols)
Cornice dati
I framework di dati forniscono un'API più facile da usare rispetto agli RDD. L'API basata su DataFrame per MLlib fornisce un'API coerente tra gli algoritmi ML e in più lingue. I framework di dati facilitano le pipeline pratiche di machine learning, in particolare le trasformazioni delle feature.
from pyspark.sql import SparkSession spark = SparkSession.builder.appName('mlearnsample').getOrCreate() df = spark.read.csv('loan_bank.csv', header = Vero, inferSchema = True) df.printSchema() -
Persistenza:
La persistenza aiuta a salvare e caricare gli algoritmi, modelli e pipeline. Questo aiuta a ridurre i tempi e gli sforzi, Poiché il modello è persistente, può essere caricato / riutilizzare in qualsiasi momento quando necessario.
from pyspark.ml.classification import LogisticRegression lr = LogisticRegression(featuresCol="caratteristiche", labelCol="etichetta") lrModel = lr.fit(treno)de pyspark.ml.evaluation import BinaryClassificationEvaluator
valutatore = BinaryClassificationEvaluator ()
Stampa ("Area di prova sotto ROC", valutatore.valutare (predizioni))
previsioni = lrModel.transform(test) previsioni.seleziona('età', 'etichetta', 'previsione grezza', 'predizione').mostrare() -
Utilità:
Utilità per l'algebra lineare, statistiche e gestione dei dati. Esempio: mllib.linalg sono le utility MLlib per l'algebra lineare.
Materiale di riferimento:
https://spark.apache.org/docs/latest/ml-guide.html
Note finali
Spark MLlib è necessario se si tratta di big data e machine learning. In questo post, appreso i dettagli di Spark MLlib, frame di dati e pipeline. In futuro post, lavoreremo su codice pratico per implementare Pipeline e costruire modelli di dati utilizzando MLlib.





