introduzione
Insegnamento rafforzativoL'apprendimento per rinforzo è una tecnica di intelligenza artificiale che consente a un agente di imparare a prendere decisioni interagendo con un ambiente. Attraverso il feedback sotto forma di premi o punizioni, L'agente ottimizza il proprio comportamento per massimizzare le ricompense accumulate. Questo approccio viene utilizzato in una varietà di applicazioni, Dai videogiochi alla robotica e ai sistemi di raccomandazione, distinguendosi per la sua capacità di apprendere strategie complesse...., sembra intrigante, verità? Qui, in questo articolo, vedremo di cosa si tratta e perché si parla tanto in questi giorni. Questo funge da guida all'apprendimento per rinforzo per i principianti.. L'apprendimento per rinforzo è sicuramente una delle aree di ricerca ovvie oggi che ha un buon boom da emergere nel prossimo futuro e la sua popolarità sta aumentando di giorno in giorno.. Diamoci da fare.
Fondamentalmente è il concetto in cui le macchine possono apprendere da sole a seconda dei risultati delle proprie azioni.. Senza ulteriori indugi, Iniziamo.
Che cos'è l'apprendimento per rinforzo??
L'apprendimento per rinforzo fa parte dell'apprendimento automatico. Qui, gli ufficiali si addestrano sui meccanismi di ricompensa e punizione. Si tratta di intraprendere la migliore azione o percorso possibile per ottenere i massimi premi e la minima punizione attraverso le osservazioni in una situazione specifica.. Agisce come segnale di comportamenti positivi e negativi. Essenzialmente un agente è costruito (o più) che sa percepire e interpretare l'ambiente in cui si trova, Cosa c'è di più, può intraprendere azioni e interagire con esso.
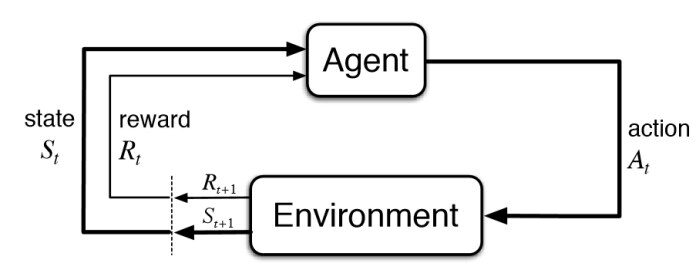
Diagramma di apprendimento dei rinforzi di base – KDNuggets
Per conoscere il significato dell'apprendimento per rinforzo, rivediamo la definizione formale.
Apprendimento rinforzato, un tipo di apprendimento automatico, in cui gli agenti agiscono in un ambiente volto a massimizzare le loro ricompense cumulative – NVIDIA
Insegnamento rafforzativo (RL) si basa sul premiare i comportamenti desiderati o sulla punizione di quelli indesiderati. Invece di un input che produce un output, l'algoritmo produce una varietà di output ed è in grado di selezionare quello corretto in base a determinate variabili: Gartner
È un tipo di tecnica di apprendimento automatico in cui un agente di calcolo impara a eseguire un'attività attraverso ripetute interazioni di prova ed errore con un ambiente dinamico.. Questo approccio di apprendimento consente all'agente di prendere una serie di decisioni che massimizzano una metrica di ricompensa per l'attività senza l'intervento umano e senza essere esplicitamente programmato per svolgere l'attività.: Matematica
tuttavia, le definizioni di cui sopra sono tecnicamente fornite da esperti in quel campo per qualcuno che ha appena iniziato con l'apprendimento per rinforzo, ma queste definizioni possono sembrare un po' difficili. In che modo questa è una guida all'apprendimento per rinforzo per principianti?, semplifichiamo la nostra definizione di apprendimento per rinforzo.
Definizione semplificata di apprendimento per rinforzo
Attraverso una serie di metodi per tentativi ed errori, un agente continua a imparare continuamente in un ambiente interattivo dalle proprie azioni ed esperienze. L'unico obiettivo è trovare un modello di azione adeguato che aumenti la ricompensa cumulativa totale dell'agente.. Impara attraverso l'interazione e il feedback.
Bene, questa è la definizione di apprendimento per rinforzo. Ora, come siamo arrivati a questa definizione, come una macchina apprende e come può risolvere problemi complessi nel mondo attraverso l'apprendimento per rinforzo, è qualcosa che vedremo più a fondo.
Spiegazione dell'apprendimento per rinforzo
Come funziona l'apprendimento per rinforzo?? Bene, lascia che ti spieghi con un esempio.
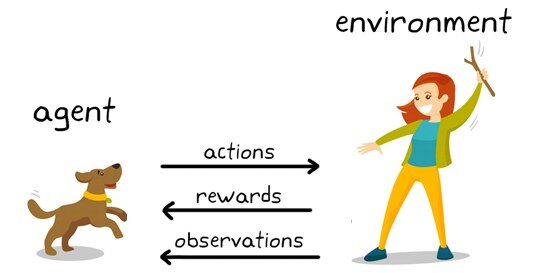
Esempio di apprendimento per rinforzo: KDNuggets
Qui cosa vedi?
Puoi vedere un cane e un padrone. Immaginiamo che tu stia addestrando il tuo cane a raccogliere il bastone. Ogni volta che il cane ottiene con successo un bastone, gli offri un banchetto (un osso, Diciamo). Eventualmente, il cane capisce lo schema, che ogni volta che l'insegnante lancia un bastone, devi farlo al più presto per ottenere una ricompensa (un osso) da un insegnante in meno tempo.
Terminologie utilizzate nell'apprendimento per rinforzo
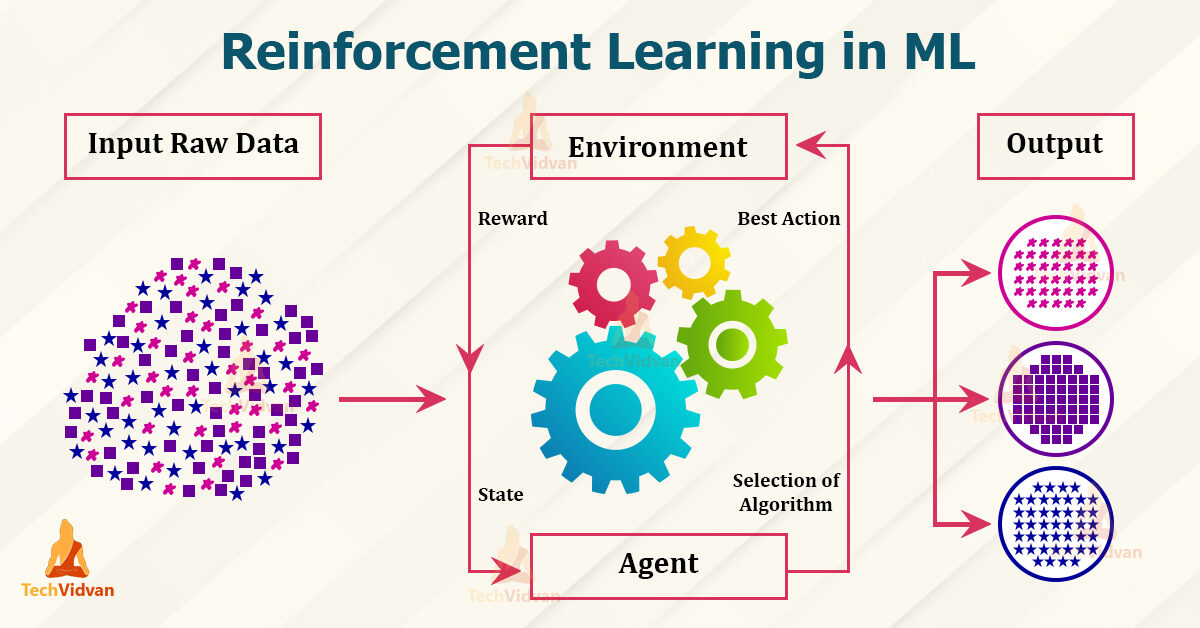
Terminologie in RL – Techvidvan
Agente – è l'unico che prende le decisioni e impara
Ambiente – un mondo fisico in cui un agente apprende e decide le azioni da intraprendere
Azione – un elenco di azioni che un agente può eseguire
Stato – la situazione attuale dell'agente nell'ambiente
Ricompensa – Per ogni azione selezionata dall'agente, l'ambiente premia. Generalmente, è un valore scalare e nient'altro che commenti sull'ambiente.
Politica – l'agente prepara la strategia (il processo decisionale) assegnare situazioni alle azioni.
Funzione valore – Il valore dello stato mostra la ricompensa ottenuta dallo stato fino all'esecuzione della politica.
Modello – Ogni agente RL non utilizza un modello del proprio ambiente. La vista agente mappa le distribuzioni di probabilità delle coppie stato-azione sugli stati
Flusso di lavoro per l'apprendimento del rinforzo
Flusso di lavoro di apprendimento rinforzato – KDNuggets
– Crea l'ambiente
– Definisci la ricompensa
– Crea l'agente
– Formare e convalidare l'agente
– Attuare la politica
¿En qué se diferencia el aprendizaje por refuerzo del apprendimento supervisionatoL'apprendimento supervisionato è un approccio di apprendimento automatico in cui un modello viene addestrato utilizzando un set di dati etichettati. Ogni input nel set di dati è associato a un output noto, consentendo al modello di imparare a prevedere i risultati per nuovi input. Questo metodo è ampiamente utilizzato in applicazioni come la classificazione delle immagini, Riconoscimento vocale e previsione delle tendenze, sottolineandone l'importanza in...?
Nell'apprendimento supervisionato, el modelo se entrena con un conjunto de datos de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... que tiene una clave de respuesta correcta. La decisione viene presa in base all'input iniziale fornito, poiché ha tutti i dati necessari per addestrare la macchina. Le decisioni sono indipendenti l'una dall'altra, quindi ogni decisione è rappresentata da un'etichetta. Esempio: riconoscimento di oggetti
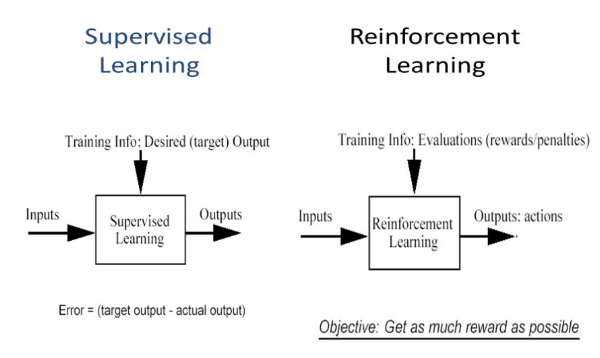
Differenza tra apprendimento supervisionato e rinforzato – studio puro
Nell'apprendimento per rinforzo, non c'è risposta e l'agente di backup decide cosa fare per eseguire l'attività richiesta. Poiché il set di dati di allenamento non è disponibile, l'agente ha dovuto imparare dalla sua esperienza. Si tratta di raccogliere le decisioni in sequenza. Per dirla in parole più semplici, l'uscita si basa sullo stato dell'ingresso corrente e l'ingresso successivo si basa sull'uscita dell'ingresso precedente. Etichettiamo la sequenza delle decisioni dipendenti. Le decisioni dipendono. Esempio: gioco di scacchi
Caratteristiche di apprendimento per rinforzo
– non supervisionato, solo un valore reale o un segnale di ricompensa
– Il processo decisionale è sequenziale
– Il tempo gioca un ruolo importante nei problemi di rinforzo.
– Il feedback non è veloce ma in ritardo
– I seguenti dati che ricevi sono determinati dalle azioni dell'agente
Algoritmi di apprendimento per rinforzo
Ci sono 3 approcci per implementare algoritmi di apprendimento per rinforzo
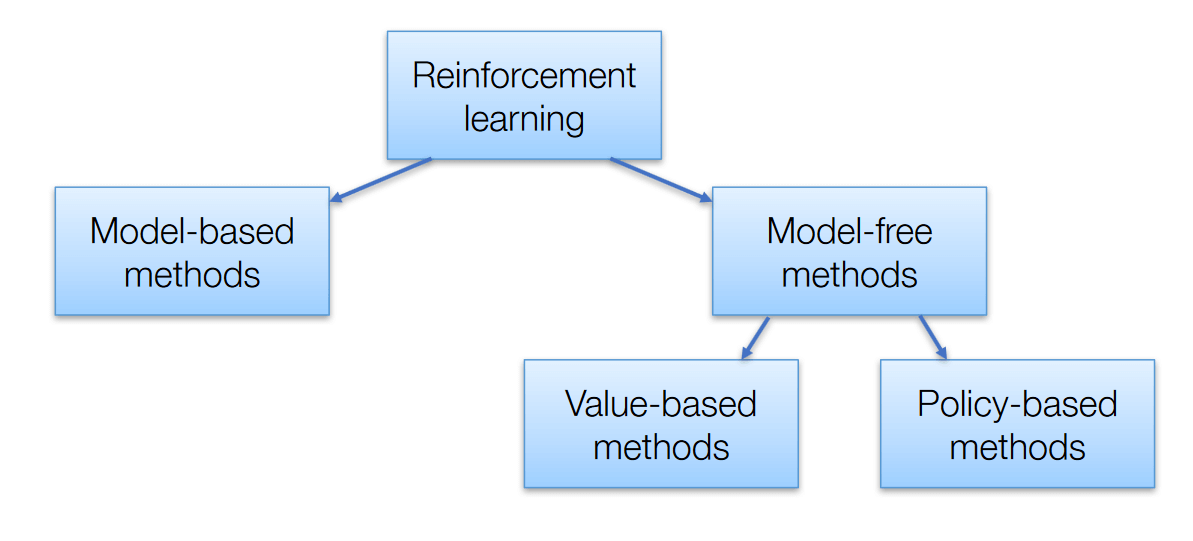
Algoritmi di apprendimento per rinforzo – AISummer
Basato sul valore – L'obiettivo principale di questo metodo è massimizzare una funzione di valore. Qui, un agente attraverso una polizza si aspetta un ritorno a lungo termine dagli stati attuali.
Basato sulla politica – Nelle politiche policy-based, permette di ideare una strategia che aiuti ad ottenere i massimi premi in futuro attraverso le possibili azioni svolte in ogni stato. Due tipi di metodi basati su policy sono deterministici e stocastici.
Basato su modelli – In questo metodo, abbiamo bisogno di creare un modello virtuale per l'agente per aiutare a imparare ad esibirsi in ogni ambiente specifico.
Tipi di apprendimento per rinforzo
Ci sono due tipi :
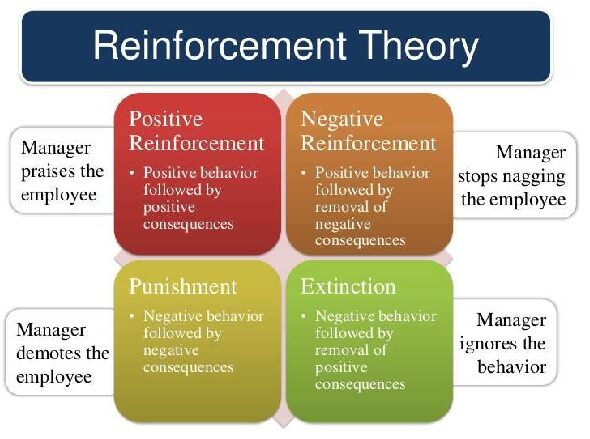
Esempio di teoria del rinforzo – punto tutorial
1. Rinforzo positivo
Il rinforzo positivo è definito come quando un evento, a causa di un comportamento specifico, aumenta la forza e la frequenza del comportamento. Ha un impatto positivo sul comportamento.
Vantaggio
– Massimizza la performance di un titolo.
– Conserva il resto per un periodo più lungo
Svantaggio
– Un rinforzo eccessivo può portare a un sovraccarico di stato che minimizzerebbe i risultati.
2. Rinforzo negativo
Il rinforzo negativo è rappresentato come il rafforzamento di un comportamento. In altre parole, quando una condizione negativa è proibita o evitata, prova a fermare questa azione in futuro.
Vantaggio
– Comportamento massimizzato
– Fornire uno standard di prestazioni decente al minimo
Svantaggio
– È semplicemente abbastanza limitato da soddisfare un comportamento minimo.
Modelli ampiamente utilizzati per l'apprendimento per rinforzo.
1. Processo decisionale di Markov (MDP) – sono quadri matematici per la mappatura di soluzioni in RL. El conjunto de parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... que incluye Conjunto de estados finitos – S, Insieme di possibili azioni in ogni stato – UN, Ricompensa – R, Modello – T, Politica – Pi. Il risultato dell'attuazione di un'azione in uno stato non dipende da azioni o stati precedenti, ma dell'azione e dello stato attuali.
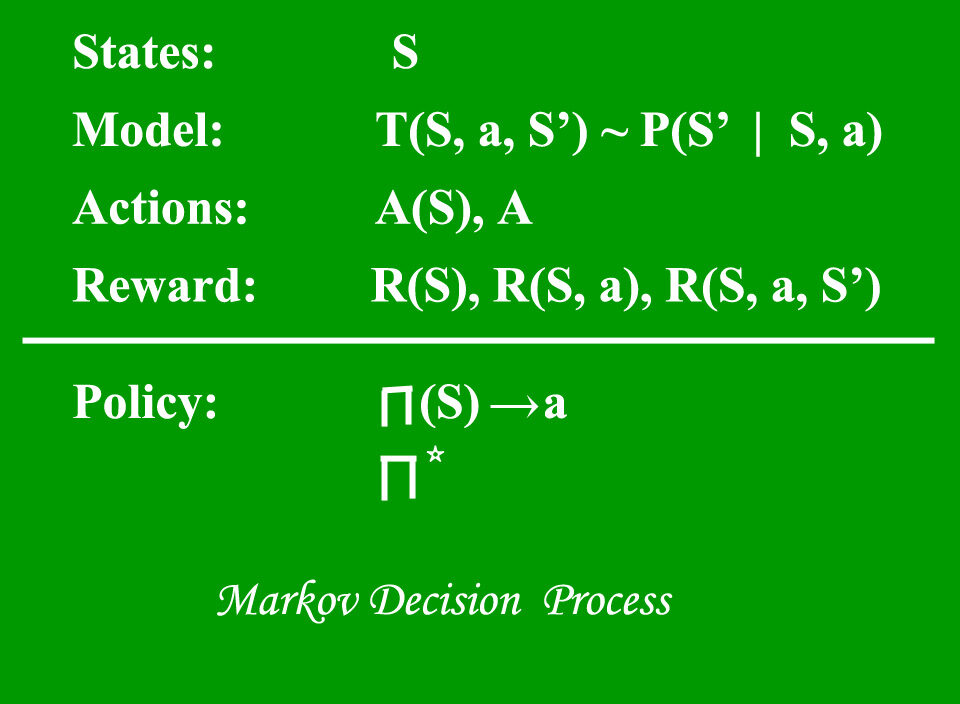
Processo decisionale di Markov – Geeks4geeks
2. Q apprendimento – È un approccio privo di modelli e basato sul valore per fornire informazioni per indicare quale azione dovrebbe intraprendere un agente. Ruota attorno alla nozione di aggiornare i valori di Q mostrando il valore dell'esecuzione dell'azione A nello stato S. La regola di aggiornamento del valore è l'aspetto principale dell'algoritmo di Q-learning.
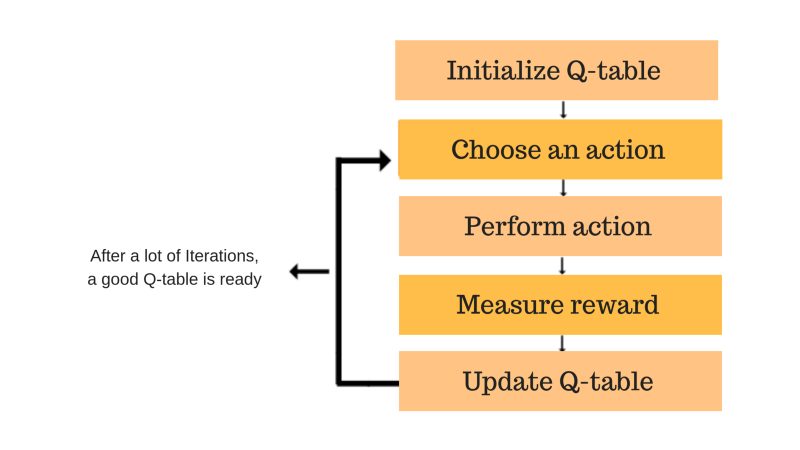
QApprendimento – Freecodecamp
Applicazioni pratiche dell'apprendimento per rinforzo
– Robotica per l'automazione industriale
– Motori di sintesi del testo, agenti di dialogo (testo, voce), Giochi
– Auto autonome autonome
– Apprendimento automatico ed elaborazione dei dati
– Sistema di formazione in grado di fornire istruzioni e materiali personalizzati relativi ai requisiti degli studenti.
– Toolkit di intelligenza artificiale, produzione, settore automobilistico, servizi igienico-sanitari e bot
– Controllo aereo e controllo del movimento del robot
– Costruire l'intelligenza artificiale per i giochi per computer.
conclusione
La conclusione di questo argomento è semplicemente per aiutarci a scoprire quale azione potrebbe produrre la maggior ricompensa per il tempo più lungo.. Gli ambienti realistici possono avere osservabilità parziale ed essere anche non stazionari. Non è molto utile applicare quando si hanno dati pratici sufficienti per risolvere il problema attraverso l'apprendimento supervisionato. La sfida principale di questo metodo è che i parametri possono influenzare la velocità di apprendimento.
Spero che ora tu conosca e comprenda un certo livello della descrizione dell'apprendimento per rinforzo. Grazie per il tuo tempo.
A proposito di me
Soy Prathima Kadari, un ex ingegnere integrato che lavora per sfruttare le mie conoscenze e migliorare le mie capacità.
Per favore, sentiti libero di connetterti con me su https://www.linkedin.com/in/prathima-kadari
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





