Questo articolo fa riferimento a uno degli algoritmi di classificazione ML supervisionati:Algoritmo KNN (K vicini più prossimi). È uno degli algoritmi di classificazione più semplici e più utilizzati in cui viene classificato un nuovo punto dati in base alla somiglianza nel gruppo specifico di punti dati vicini. Questo dà un risultato competitivo.
Lavoro
Per un dato punto dati nel set, gli algoritmi trovano le distanze tra questo e tutti gli altri K numero di punti dati nel set di dati vicino al punto di partenza e voti per la categoria che ha la frequenza più alta. In genere, distanza euclidea sta prendendo come misura della distanza. Perciò, il modello risultante finale è solo i dati etichettati collocati in uno spazio. Questo algoritmo è popolarmente conosciuto da varie applicazioni come genetica, previsione, eccetera. L'algoritmo è migliore quando sono presenti più funzionalità e in questo caso mostra SVM.
KNN che riduce il sovradattamento è un dato di fatto. In secondo luogo, è necessario scegliere il miglior valore per K. Quindi, Come scegliamo K? Generalmente usiamo la radice quadrata del numero di campioni nel set di dati come valore per K. È necessario trovare un valore ottimale poiché un valore più basso può portare a sovradattamento e un valore più alto può richiedere una grande complicazione computazionale a distanza.. Perciò, l'uso di un grafico degli errori può aiutare. Un altro metodo è il metodo del gomito. Può preferire mettere radici, altrimenti puoi anche seguire il metodo del gomito.
Entriamo nei diversi passaggi K-NN per classificare un nuovo punto dati
passo 1: Seleziona il valore di K vicini (diciamo k = 5)
passo 2: Trova il punto dati K (5) più vicino per il nostro nuovo punto dati basato sulla distanza euclidea (di cui parleremo più avanti)
passo 3: Tra questi K punti dati, contare i punti dati in ogni categoria.
passo 4: Assegna il nuovo punto dati alla categoria che ha il maggior numero di vicini del nuovo punto dati
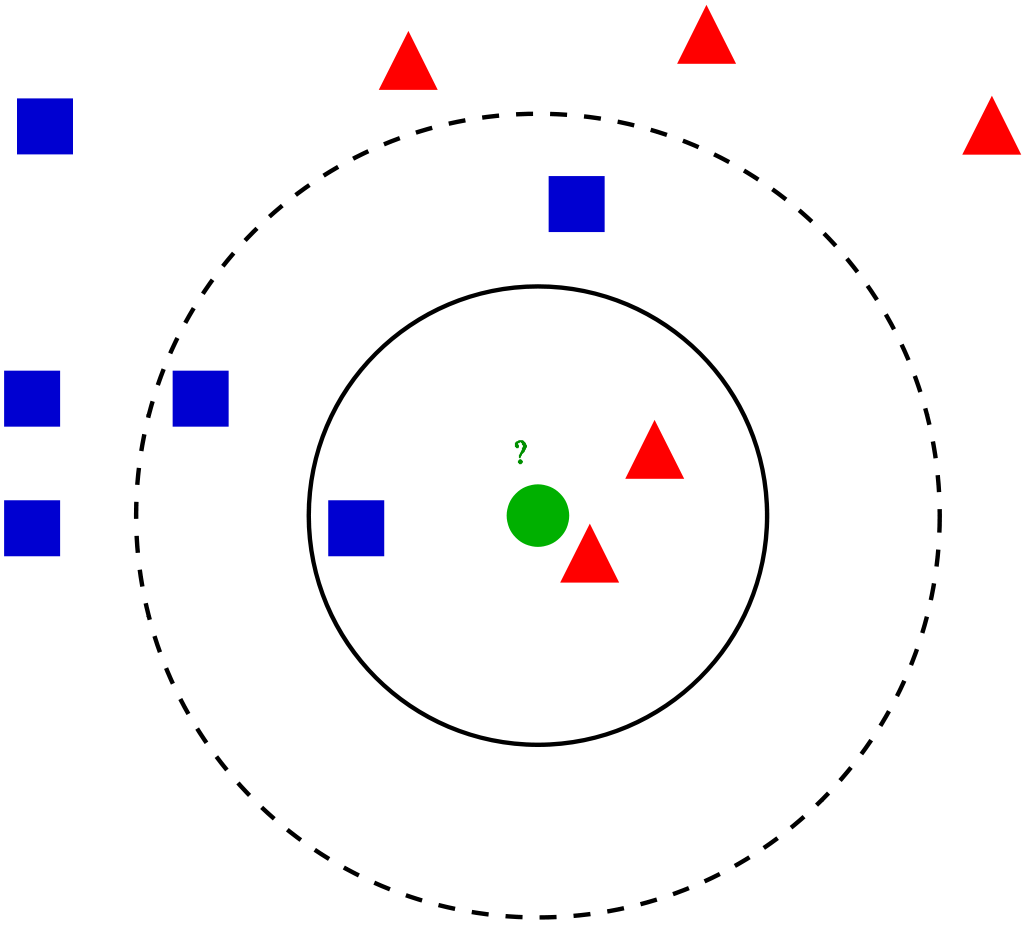
Esempio
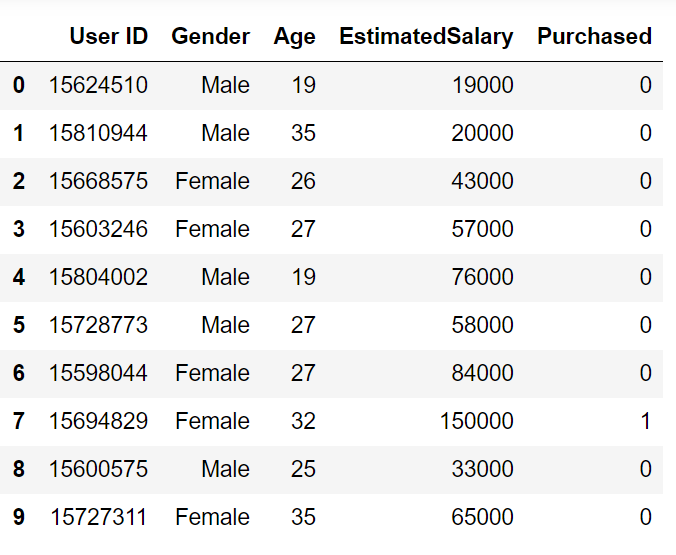
Esaminiamo un problema di esempio per avere una chiara intuizione sulla classificazione K-Nearest Neighbor. Stiamo utilizzando il set di dati degli annunci sui social media (Scarica). Il dataset contiene i dettagli degli utenti su un sito di social media per scoprire se un utente acquista un prodotto cliccando sull'annuncio sul sito in base al proprio stipendio, età e sesso.
Iniziamo a programmare importando le librerie essenziali
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import sklearn
Importare il set di dati e dividerlo in variabili indipendenti e dipendenti
set di dati = pd.read_csv('Social_Network_Ads.csv')
X = dataset.iloc[:, [1, 2, 3]].values
y = dataset.iloc[:, -1].valori
Poiché il nostro set di dati contiene variabili di carattere, dobbiamo codificarlo usando LabelEncoder
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
X[:,0] = le.fit_transform(X[:,0])
Stiamo conducendo un test split train sul set di dati. Forniamo una dimensione di prova di 0,20, il che significa che il nostro esempio di formazione contiene 320 set di training e l'esempio di test contiene 80 set di test
da sklearn.model_selection import train_test_split
X_treno, X_test, y_train, y_test = train_test_split(X, e, test_size = 0.20, stato_casuale = 0)
Prossimo, eseguiremo un ridimensionamento delle funzionalità in base al set di training e test di variabili indipendenti per ridurre le dimensioni a valori più piccoli.
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_treno)
X_test = sc.transform(X_test)
Ora dobbiamo creare e addestrare il modello K Closest Neighbor con il set di training
from sklearn.neighbors import KNeighborsClassifier
classifier = KNeighborsClassifier(n_neighbors = 5, metrica="Minkowski", p = 2)
classificatore.fit(X_treno, y_train)
stiamo usando 3 nella creazione del modello. n_neighbors è impostato su 5, il che significa che sono richiesti 5 punti di vicinato per classificare un determinato punto. La metrica della distanza che stiamo usando è Minkowski, l'equazione per esso è data di seguito
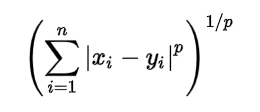
Secondo l'equazione, dobbiamo anche selezionare il p-value.
p = 1, Distanza da Manhattan
p = 2, distanza euclidea
p = infinito, distanza di Cheybchev
Nel nostro problema, scegliamo p come 2 (puoi anche scegliere la metrica come “euclideo”)
Il nostro modello è stato creato, ora dobbiamo prevedere l'output per il test set
y_pred = classificatore.predict(X_test)
Confronto tra valore vero e previsto:
y_test
Vettore([0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1,
0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0,
1, 0, 0, 1, 0, 1, 1, 0, 0, 0, 1, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1,
0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 1, 1, 0, 1,
1, 0, 0, 1, 0, 0, 0, 1, 0, 1, 1, 1], dtype=int64)
y_pred
Vettore([0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1,
0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0,
1, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1,
0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 1, 0, 0, 1,
1, 0, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1], dtype=int64)
Possiamo valutare il nostro modello utilizzando la matrice di confusione e il punteggio di precisione confrontando i valori del test previsti e quelli effettivi
da Sklearn.metrics importare confusion_matrix,accuracy_score
cm = confusion_matrix(y_test, y_pred)
ac = accuracy_score(y_test,y_pred)
matrice di confusione –
[[64 4] [ 3 29]]
la precisión es 0,95
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Importing the dataset
dataset = pd.read_csv('Social_Network_Ads.csv')
X = dataset.iloc[:, [2, 3]].values
y = dataset.iloc[:, -1].valori
# Splitting the dataset into the Training set and Test set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, e, test_size = 0.20, stato_casuale = 0)
# Feature Scaling
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_treno)
X_test = sc.transform(X_test)
# Training the K-NN model on the Training set
from sklearn.neighbors import KNeighborsClassifier
classifier = KNeighborsClassifier(n_neighbors = 5, metrica="Minkowski", p = 2)
classificatore.fit(X_treno, y_train)
# Predicting the Test set results
y_pred = classifier.predict(X_test)
# Making the Confusion Matrix
from sklearn.metrics import confusion_matrix, accuracy_score
cm = confusion_matrix(y_test, y_pred)
ac = accuracy_score(y_test, y_pred)
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





