introduzione
R è uno dei linguaggi di programmazione più famosi per l'analisi statistica e l'informatica.. Perché offre molte funzionalità, ricercatori e data scientist lo usano per la scienza dei dati e l'apprendimento automatico. Alcune di queste funzionalità includono librerie di visualizzazione interattiva, veloce e open source, esecuzione del codice senza compilatore, buona comunità e molti altri.
Uno dei motivi principali per cui sta diventando molto famoso è il gran numero di pacchetti R per progetti di data science., apprendimento automatico e intelligenza artificiale. Quando si utilizzano questi pacchetti, i modelli predittivi possono essere sviluppati in modo semplice ed efficiente. Questo blog elenca il 10 I migliori pacchetti R che dovresti conoscere 2021 per la scienza dei dati e l'apprendimento automatico.

Sommario
- Dplyr
- ggplot2
- KernLab
- esploratore di dati
- Cursore
- casualeForesta
- Lucente
- potenziare
- trama
- SuperML
Dplyr
È uno dei pacchetti R più utilizzati per le attività di data science e machine learning.. Questo pacchetto è stato scritto da Hadley Wickham. Viene utilizzato per risolvere compiti di manipolazione dei dati. Ha una serie di funzioni per la manipolazione dei dati. Chiamata anche grammatica di manipolazione dei dati. Ha una serie di verbi che ci aiutano a risolvere i compiti di manipolazione dei dati più impegnativi come mutare (), selezionare (), filtro (), riprendere (), organizzare ().
Per installare questo pacchetto, usa il seguente codice:
install.packages('dplyr')


Per maggiori informazioni, vedi il link qui sotto: Introduzione a dplyr
ggplot2
Uno dei pacchetti R più popolari e ampiamente utilizzati per la visualizzazione dei dati e l'analisi esplorativa dei dati. È possibile creare visualizzazioni di dati interattive con questo pacchetto. Fornisce una vasta gamma di bellissime trame che si prendono cura dei minimi dettagli e disegnano didascalie. Questo pacchetto funziona con una grammatica profonda chiamata “Grammatica dei grafici”. Fornisce un'ampia gamma di grafici come grafici a dispersione e grafici a bolle. I diagrammi di fluttuazione sono grafici, istogrammiGli istogrammi sono rappresentazioni grafiche che mostrano la distribuzione di un set di dati. Sono costruiti dividendo l'intervallo di valori in intervalli, oh "Bidoni", e il conteggio della quantità di dati che cadono in ogni intervallo. Questa visualizzazione consente di identificare i modelli, tendenze e variabilità dei dati in modo efficace, facilitare l'analisi statistica e il processo decisionale informato in varie discipline...., grafici di densità, box plotDiagrammi a scatola, Conosciuto anche come diagrammi a scatola e baffi, sono strumenti statistici che rappresentano la distribuzione di un dataset. Questi diagrammi mostrano la mediana, quartili e valori anomali, Consentire la visualizzazione della variabilità e della simmetria dei dati. Sono utili nel confronto tra diversi gruppi e nell'analisi esplorativa, Rendendo più facile identificare tendenze e modelli nei dati...., diagrammi di violino, dendrogrammi e molti altri.
Per installare questo pacchetto, usa il seguente codice:
install.packages('gglpot2')
Di seguito sono riportati alcuni esempi di grafici che utilizzano questo pacchetto:
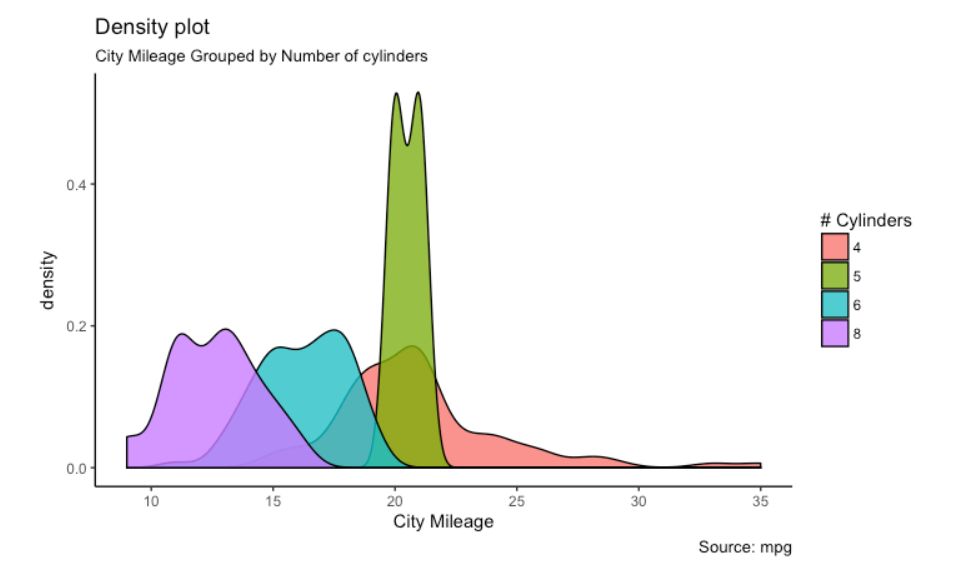

Per maggiori informazioni, vedi il link qui sotto: ggplot2
KernLab
Questo pacchetto è anche chiamato laboratorio di apprendimento automatico basato su kernel. Questo pacchetto viene utilizzato per la regressione, classificazione, riduzione dimensionale, rilevamento anomalie, raggruppamentoIl "raggruppamento" È un concetto che si riferisce all'organizzazione di elementi o individui in gruppi con caratteristiche o obiettivi comuni. Questo processo viene utilizzato in varie discipline, compresa la psicologia, Educazione e biologia, per facilitare l'analisi e la comprensione di comportamenti o fenomeni. In ambito educativo, ad esempio, Il raggruppamento può migliorare l'interazione e l'apprendimento tra gli studenti incoraggiando il lavoro... Se vuoi usare algoritmi che implicano un approccio basato sul kernel, puoi usarlo come SVM, algoritmo di classificazione, analisi delle funzionalità del kernel e molti altri. È ampiamente utilizzato per le implementazioni SVM. Ha una vasta gamma di funzioni del kernel, come per la funzione kernel polinomiale, possiamo usare polydot (), la funzione del kernel tangente iperbolica per tanhdot (), eccetera.
Per installare questo pacchetto, usa il seguente codice:
install.packages('kernlab')
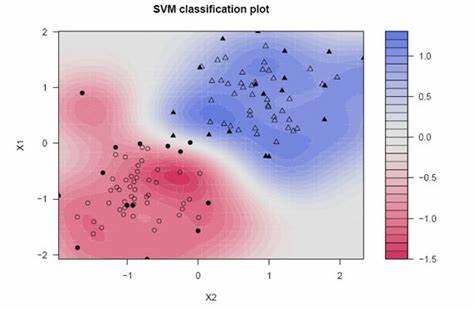
Per maggiori informazioni, vedi il link qui sotto: pacchetto kernellab
esploratore di dati
Questo pacchetto R è uno dei più facili da usare per la scienza dei dati e l'apprendimento automatico. Questo pacchetto si concentra principalmente su tre obiettivi:
- Analisi esplorativa dei dati
- Ingegneria delle funzioni
- rapporto sui dati
Questo pacchetto ha automatizzato l'analisi esplorativa dei dati per la modellazione predittiva e le attività di analisi visualizzando ogni caratteristica presente nel nostro set di dati.
Per installare questo pacchetto, usa il seguente codice:
install.packages("Esplora dati")
Per trovare un'ampia panoramica del nostro set di dati, possiamo usare il seguente codice:
introdurre(dati)
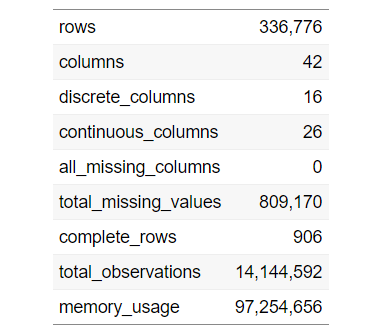
Per visualizzare la tabella precedente, usa il seguente codice:
trama_introduzione(dati)
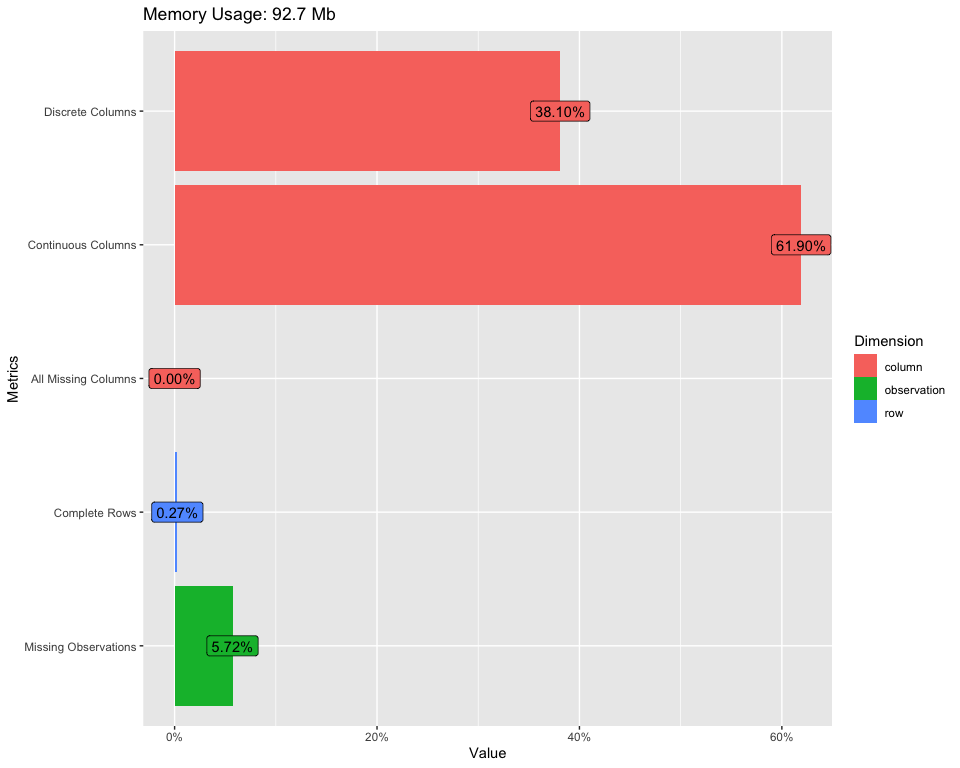
Per maggiori informazioni, vedi il link qui sotto: Introduzione a DataExplorer
Cursore
Questo è anche chiamato addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... Classificazione e regressione. È uno dei migliori pacchetti per attività di data science e machine learning. Contiene un insieme di funzioni utilizzate per creare modelli predittivi. Ha altre caratteristiche, così come la selezione delle caratteristiche, suddivisione dei dati, pre-elaborazione dei dati, vestibilità del modello, importanza delle funzionalità e molto altro.
Per installare questo pacchetto, usa il seguente codice:
install.packages('accento circonflesso')
Per maggiori informazioni, vedi il link qui sotto: punto di inserimento del pacchetto
casualeForesta
Random Forest è uno dei pacchetti R più popolari per l'apprendimento automatico.. Questo pacchetto viene utilizzato per creare foreste casuali in R. Può essere utilizzato sia per attività di classificazione che di regressione. Possiamo anche usarlo per addestrare valori mancanti e valori anomali. Questo pacchetto utilizza l'algoritmo della foresta casuale di Breiman per costruire alberi decisionali..
Per trovare un'ampia panoramica del nostro set di dati, possiamo usare il seguente codice:
install.packages('foresta casuale')
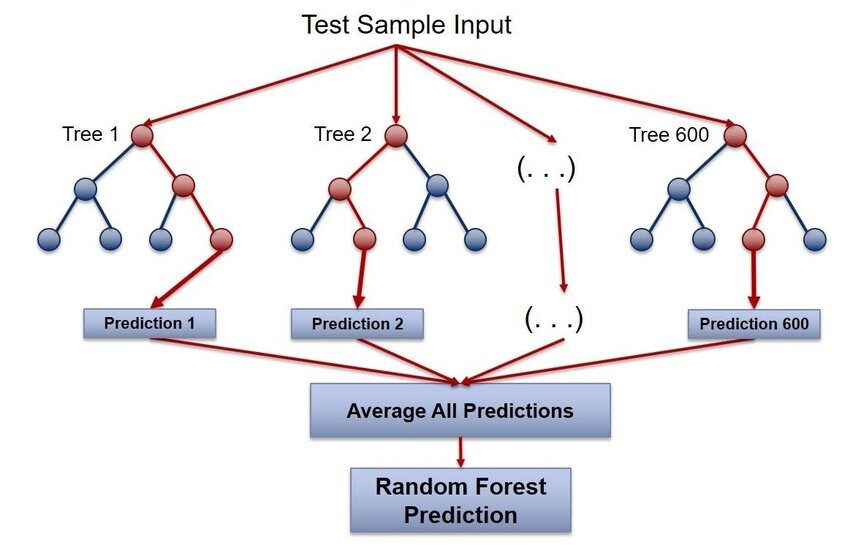
Per maggiori informazioni, vedi il link qui sotto: foresta casuale
Lucente

È un pacchetto R utilizzato per creare un'applicazione Web interattiva per la scienza dei dati. Ci aiuta a creare applicazioni web R senza troppi sforzi. Shiny crea applicazioni Web che vengono distribuite sul Web utilizzando il tuo server o i servizi di hosting Shiny R. Le funzionalità di Shiny R includono la creazione di un'applicazione con una minore conoscenza degli strumenti Web, fornisce viste dal vivo, funzioni di rendering e molto altro.
Esempio di applicazione web con shiny:
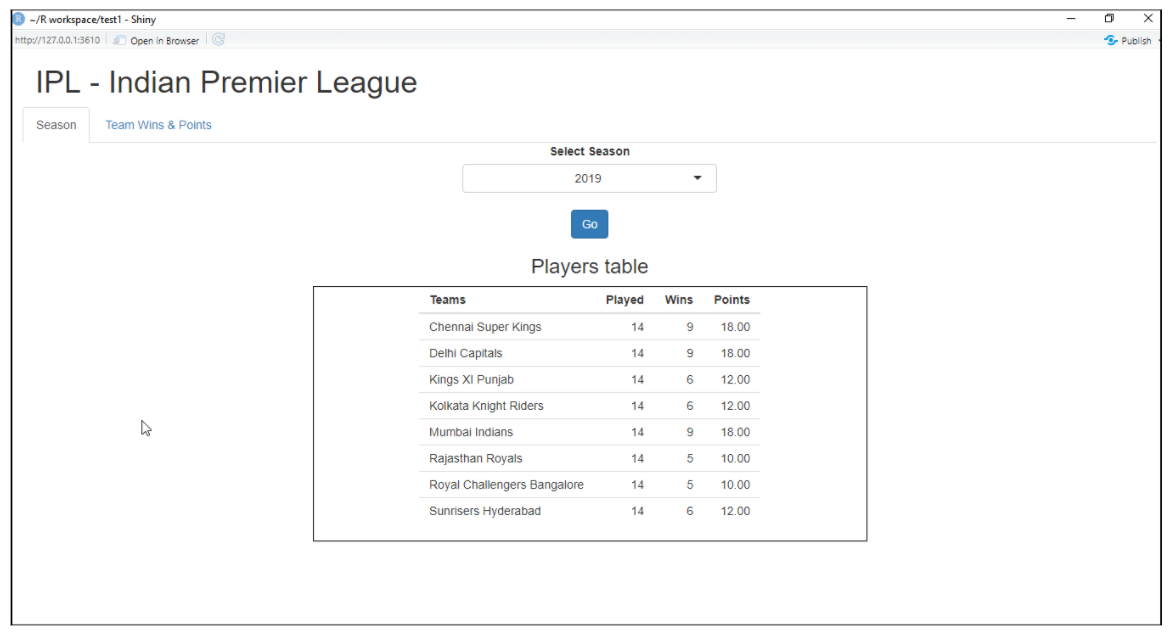
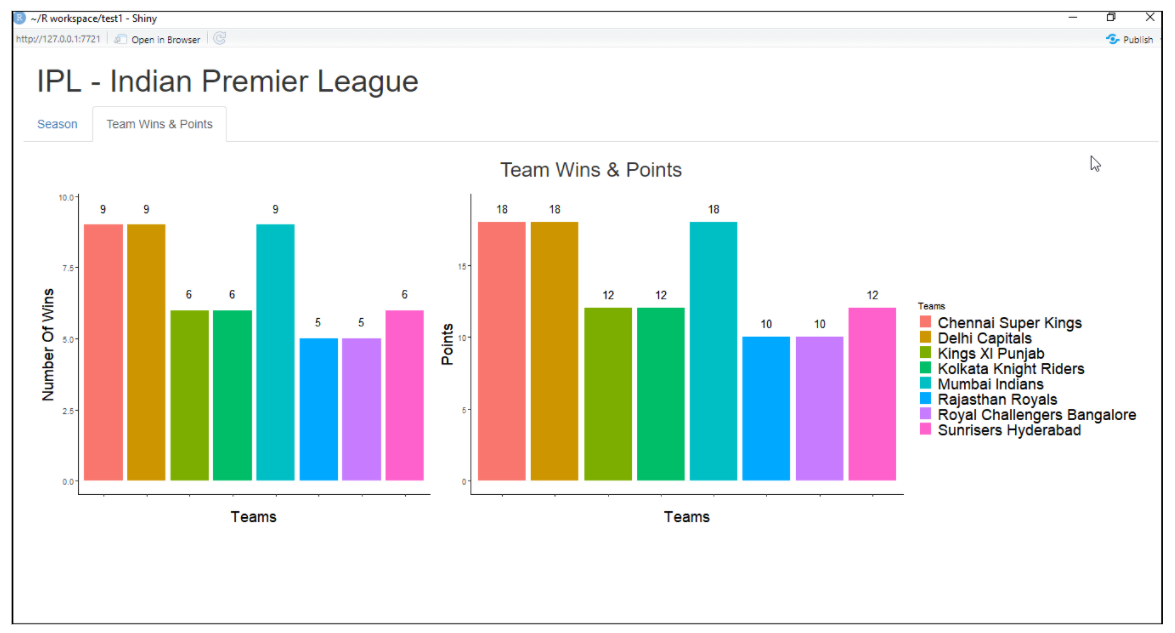
Per maggiori informazioni, vedi il link qui sotto: Lucente
potenziare
Questo pacchetto viene utilizzato nella scienza dei dati per pacchetti di impulsi basati su modelli e dispone di un algoritmo downstream funzionale di gradienteGradiente è un termine usato in vari campi, come la matematica e l'informatica, per descrivere una variazione continua di valori. In matematica, si riferisce al tasso di variazione di una funzione, mentre in progettazione grafica, Si applica alla transizione del colore. Questo concetto è essenziale per comprendere fenomeni come l'ottimizzazione negli algoritmi e la rappresentazione visiva dei dati, consentendo una migliore interpretazione e analisi in... per ottimizzare gli alberi decisionali. Fornisce inoltre un modello di interazione per dati potenzialmente di alta qualità. dimensione"Dimensione" È un termine che viene utilizzato in varie discipline, come la fisica, Matematica e filosofia. Si riferisce alla misura in cui un oggetto o un fenomeno può essere analizzato o descritto. In fisica, ad esempio, Si parla di dimensioni spaziali e temporali, mentre in matematica può riferirsi al numero di coordinate necessarie per rappresentare uno spazio. Comprenderlo è fondamentale per lo studio e....
Per installare questo pacchetto, usa il seguente codice:
install.packages('stimolare')
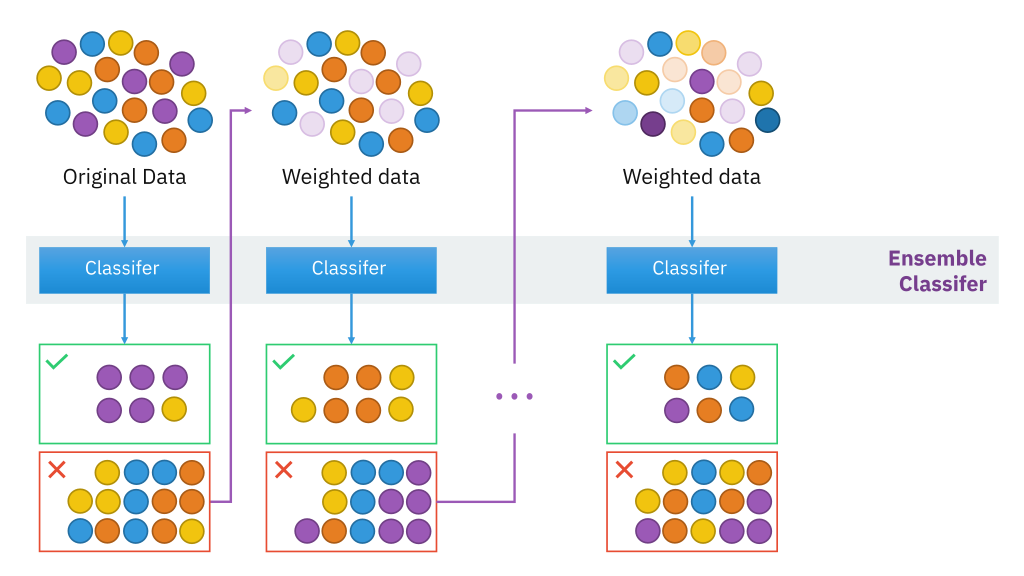
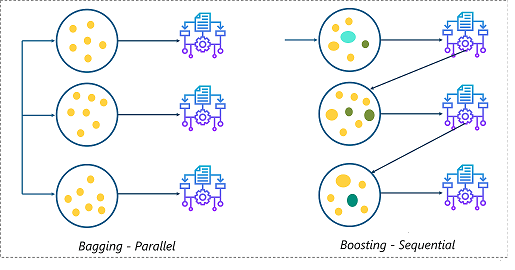
Per maggiori informazioni, vedi il link qui sotto: potenziare
trama
È una libreria di grafici che crea grafici interattivi. È un'interfaccia di alto livello per plotly.js, basato su d3.js. Fornisce un'interfaccia utente facile da usare per generare eleganti grafici D3 interattivi. Questi grafici interattivi forniscono molte funzionalità, come la possibilità di ingrandire e rimpicciolire la grafica, passa il mouse sopra un punto per ulteriori informazioni, filtrare i dati e molto altro.

Fornisce un esempio di grafici come i grafici a dispersione, diagrammi a linee, grafici a barre, carrelli circolari, diagrammi a bolle, box plot, istogrammi, Barre di errore, diagrammi di violino e molto altro.
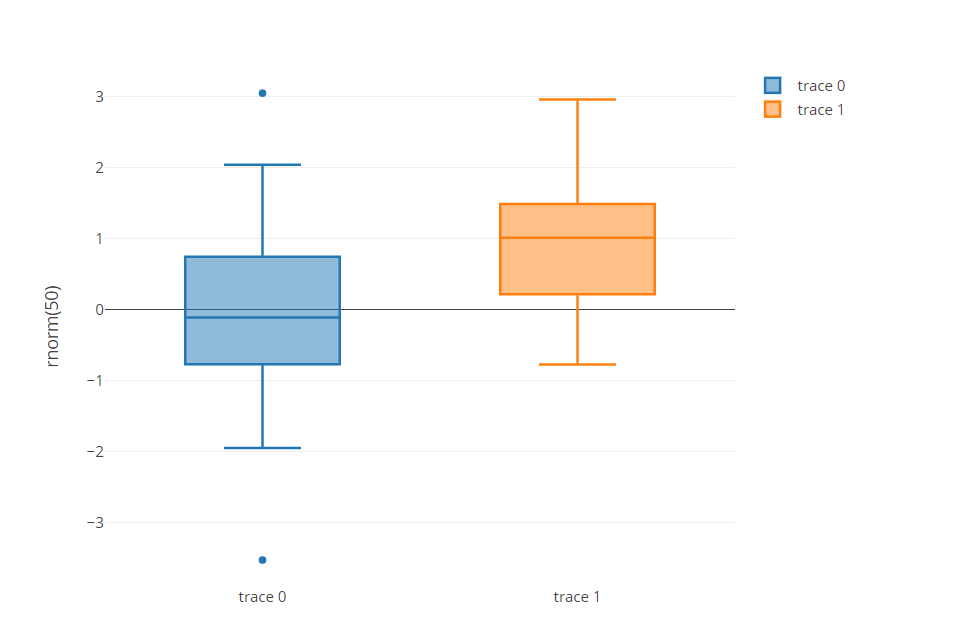
Per maggiori informazioni, vedi il link qui sotto: trama
SuperML
Superml è uno dei famosi pacchetti R per l'intelligenza artificiale che fornisce un'interfaccia standard ai client che utilizzano i dialetti di programmazione Python e R per creare modelli di intelligenza artificiale.. Questo pacchetto fornisce essenzialmente i punti salienti dell'interfaccia Scikit Learn and predict per la preparazione di modelli di intelligenza artificiale in R. Oltre a costruire modelli di IA, ci sono funzionalità utili per eseguire l'ingegneria delle funzioni.
Per installare questo pacchetto, usa il seguente codice:
install.packages('superml')
Per maggiori informazioni, vedi il link qui sotto: SuperML
Grazie per aver letto questo articolo e per la tua pazienza.. Lasciami nella sezione commenti sui commenti. Condividi questo articolo, mi darà la motivazione per scrivere più blog per la comunità di data science.
Grazie per aver letto questo. se ti piace questo articolo, Condividi con i tuoi amici. In caso di qualsiasi suggerimento / dubbio, commenta qui sotto.
Identificazione e-mail: [e-mail protetta]
Seguimi su LinkedIn: LinkedIn
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





