Una delle domande più comuni, che si fa in diversi forum sulla scienza dei dati è:
Qual è la differenza tra machine learning e modellazione statistica?
Ho cercato per l'ultimo 2 anni. In genere, Non mi ci vuole più di un giorno per avere una risposta chiara all'argomento che sto ricercando. Nonostante questo, questo è stato sicuramente uno dei dadi più difficili da decifrare. Quando mi sono imbattuto in questa domanda all'inizio, Difficilmente ho trovato una risposta chiara che possa determinare in che modo l'apprendimento automatico differisce dalla modellazione statistica. Data la somiglianza in termini di obiettivo che entrambi cercano di risolvere, l'unica differenza sta nel volume dei dati coinvolti e nella partecipazione umana per costruire un modello. Ecco un interessante diagramma di Venn sulla copertura dell'apprendimento automatico e della modellazione statistica nell'universo della scienza dei dati (Riferimento: Istituto SAS)
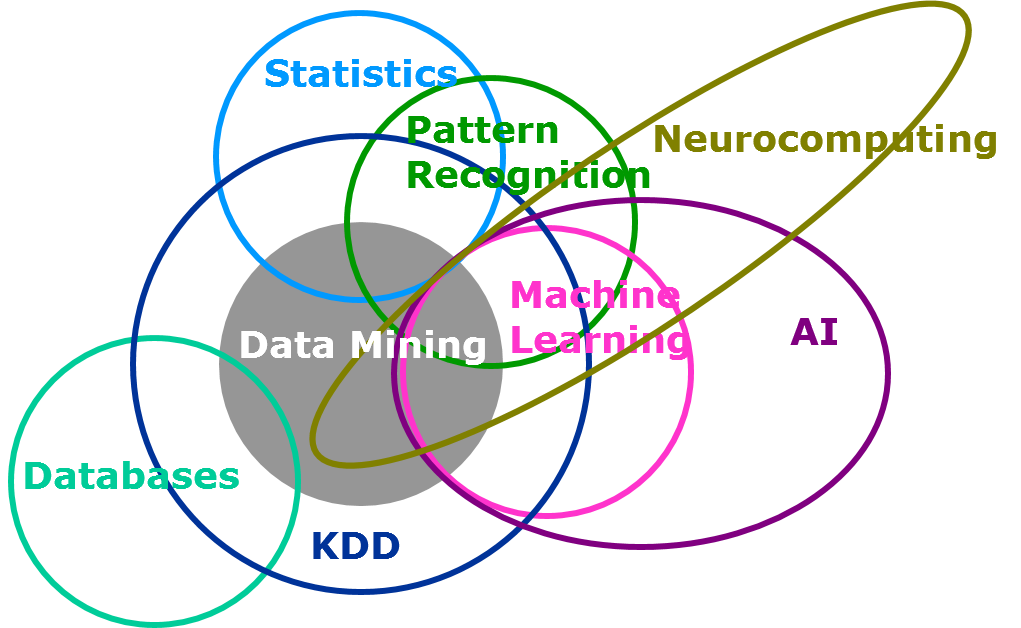
In questo post, Cercherò di evidenziare la differenza tra i due nel miglior modo possibile.. Incoraggio le persone più esperte in questo settore ad aggiungere a questo post per evidenziare la differenza.
Prima di cominciare, capiamo l'obiettivo dietro ciò che stiamo cercando di risolvere per utilizzare uno di questi strumenti. L'obiettivo comune dietro l'utilizzo di entrambi gli strumenti è Imparare dai dati. Entrambi gli approcci mirano a conoscere i fenomeni sottostanti attraverso l'uso dei dati generati nella procedura..
Ora che è chiaro che l'obiettivo dietro entrambi gli approcci è lo stesso, Rivediamo la sua definizione e le differenze.
prima di continuare: Nozioni di base sull'apprendimento automatico per principianti
Definizione:
Iniziamo con definizioni semplici:
L'apprendimento automatico è …
un algoritmo che può imparare dai dati senza fare affidamento sulla programmazione basata su regole.
La modellazione statistica è …
formalizzazione delle relazioni tra variabili sotto forma di equazioni matematiche.
Per le persone come me, che amano comprendere concetti da applicazioni pratiche, queste definizioni non aiutano molto. Quindi, vediamo un caso aziendale qui.
Un caso aziendale
Vediamo ora un interessante esempio reso pubblico da McKinsey differenziando i due algoritmi:
Caso : Comprendere il livello di rischio di abbandono dei clienti in un periodo di tempo per una società di telecomunicazioni.
Dati disponibili : Due conduttori: A e B
Quello che McKinsey mostra di seguito è un'assoluta delizia!! Basta guardare il grafico sottostante per comprendere la differenza tra un modello statistico e un algoritmo di machine learning..
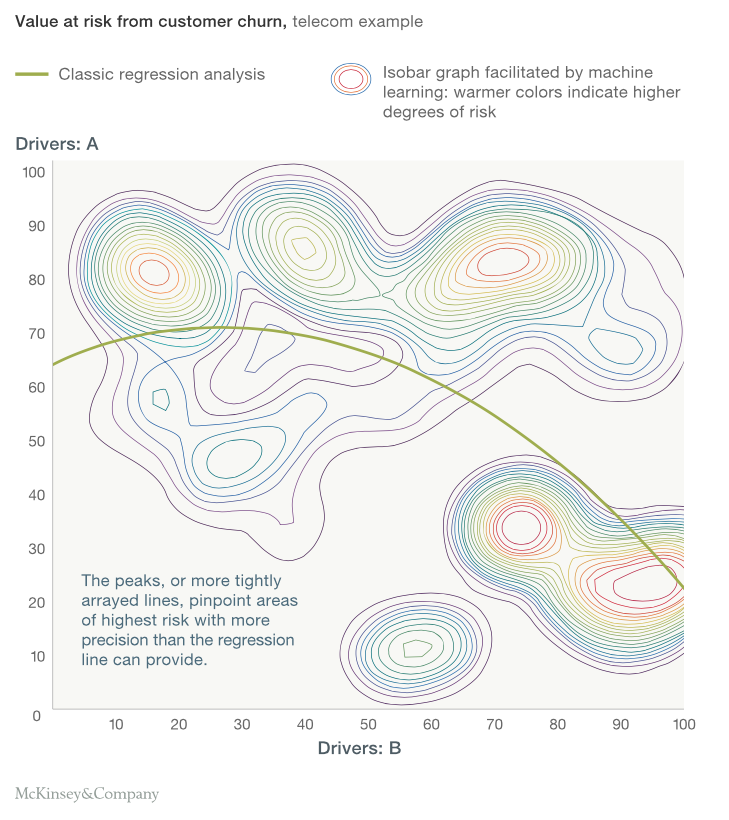
Cosa hai osservato nel grafico precedente? Il modello statistico riguarda l'ottenimento di una semplice formulazione di un confine in un modello di classificazione ostacolo. Qui vediamo un limite non lineare che, en cierta misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica...., separa le persone a rischio da quelle senza rischio. Ma quando vediamo i contorni generati dall'algoritmo di Machine Learning, assistiamo che la modellazione statistica non è confrontabile per il problema in questione con l'algoritmo di Machine Learning. I contorni dell'apprendimento automatico sembrano catturare tutti i modelli oltre i limiti della linearità o persino la continuità dei limiti. Ecco cosa può fare per te il machine learning.
Se questa non è abbastanza ispirazione, l'algoritmo di apprendimento automatico viene utilizzato nei motori di raccomandazione di YouTube / Google, eccetera., che può generare trilioni di osservazioni in un secondo per arrivare a una raccomandazione quasi perfetta. Anche con un laptop di 16 GB di RAM, trabajo a diario en conjuntos de datos de millones de filas con cientos de parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... y construyo un modelo completo en no más de 30 minuti. Un modello statistico, d'altra parte, hai bisogno di un supercomputer per eseguire un milione di osservazioni con mille parametri.

Differenze tra apprendimento automatico e modellazione statistica:
Dato il gusto della differenza nella produzione di questi due approcci, capiamo la differenza tra i due paradigmi, anche se entrambi fanno un lavoro quasi equivalente:
- Scuole da cui provengono
- Quando sono nate??
- Ipotesi in cui funzionano
- Tipo di dati che trattano
- Nomenclature di funzioni e oggetti
- Tecniche utilizzate
- Potere predittivo e sforzi umani coinvolti per metterlo in pratica
Tutte le differenze menzionate in precedenza separano i due in una certa misura., ma non c'è una linea dura tra l'apprendimento automatico e la modellazione statistica.
Appartengono a scuole diverse
L'apprendimento automatico è …
un sottocampo dell'informatica e dell'intelligenza artificiale responsabile della costruzione di sistemi in grado di apprendere dai dati, invece di istruzioni esplicitamente programmate.
La modellazione statistica è …
un sottocampo della matematica responsabile della ricerca di relazioni tra le variabili per prevedere un risultato
Sono sorti in tempi diversi
La modellazione statistica esiste da secoli. Nonostante questo, l'apprendimento automatico è uno sviluppo molto recente. È emerso nel decennio di 1990 quando i costanti progressi nella digitalizzazione e la potenza di calcolo a basso costo hanno permesso ai data scientist di smettere di costruire modelli finiti e, Invece, allenare i computer per farlo. Il volume ingestibile e la complessità dei big data in cui sta nuotando il mondo hanno aumentato il potenziale e la necessità dell'apprendimento automatico.
Ambito delle ipotesi coinvolte
La modellazione statistica funziona con una serie di ipotesi. Come esempio, una regressione lineare assume:
- Vinculación lineal entre variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... independiente y dependiente
- Omocedasticità
- Errore medio a zero per ogni valore dipendente
- Indipendenza delle osservazioni
- L'errore deve essere distribuito uniformemente per ogni valore della variabile dipendente.
Equivalentemente, le regressioni logistiche sono dotate di una propria serie di ipotesi. Anche un modello non lineare deve soddisfare un limite di segregazione continua. Gli algoritmi di apprendimento automatico presuppongono alcune di queste cose, ma in generale si salvano dalla maggior parte di questi presupposti. Il più grande vantaggio dell'utilizzo di un algoritmo di apprendimento automatico è che non è fattibile alcuna continuità di confine come mostrato nel caso di studio sopra.. Allo stesso tempo, non è necessario specificare la distribuzione della variabile dipendente o indipendente in un algoritmo di apprendimento automatico.
Tipi di dati con cui trattano
Gli algoritmi di apprendimento automatico sono strumenti ad ampio raggio. Gli strumenti di apprendimento online prevedono dati al volo. Questi strumenti sono in grado di apprendere da miliardi di osservazioni una per una. Fanno previsioni e imparano contemporaneamente. Anche altri algoritmi come Random Forest e Gradient Boosting sono eccezionalmente veloci con i big data.. L'apprendimento automatico funziona alla grande con wide (gran numero di attributi) e profondo (gran numero di osservazioni). Nonostante questo, i modelli statistici sono generalmente applicati per dati più piccoli con meno attributi o finiscono per sovrapporsi.
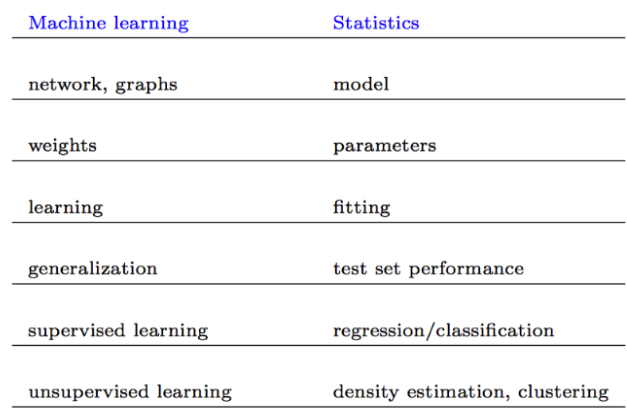
Convenzione di denominazione
Ecco i nomi che si riferiscono quasi alle stesse cose:
Formulazione
Anche quando l'obiettivo finale sia per l'apprendimento automatico che per la modellazione statistica è lo stesso, la formulazione di due è significativamente diversa.
In un modello statistico, proviamo semplicemente a stimare la funzione f in
Variabile dipendente ( E ) = f(Variabile indipendente) + funzione di errore
L'apprendimento automatico elimina la funzione deterministica “F” dell'equazione. diventa semplicemente
Produzione(E) ----- > Ingresso (X)
Cercherà di trovare sacchi di X in n dimensioni (dove n è il numero di attributi), dove l'occorrenza di Y è significativamente diversa.
Potere predittivo e sforzo umano
La natura non assume nulla prima di forzare il verificarsi di un evento.
Quindi, le ipotesi minime in un modello predittivo, maggiore è il potere predittivo. Apprendimento automatico, Come suggerisce il nome, richiede il minimo sforzo umano. L'apprendimento automatico funziona in iterazioni in cui il computer cerca di scoprire modelli nascosti nei dati. Perché la macchina fa questo lavoro con dati completi ed è indipendente da tutte le ipotesi, il potere predittivo è generalmente molto forte per questi modelli. Il modello statistico è intensivo in matematica e si basa sulla stima dei coefficienti. È necessario che il modellatore comprenda il legame tra le variabili prima di inserirle.
Note finali
Nonostante questo, può sembrare che l'apprendimento automatico e la modellazione statistica siano due rami diversi della modellazione predittiva, sono quasi uguali. La differenza tra questi due si è notevolmente ridotta nell'ultimo decennio. Entrambi i rami hanno imparato molto l'uno dall'altro e si avvicineranno in futuro. Spero di averti motivato abbastanza per acquisire competenze in ciascuno di questi due domini e quindi confrontare il modo in cui si completano a vicenda..
Se sei interessato a ottenere algoritmi di apprendimento automatico, Abbiamo quello che ti serve. Stiamo costruendo un percorso di apprendimento per l'apprendimento automatico che sarà pubblicato presto..
Facci sapere cosa pensi sia la differenza tra machine learning e modellazione statistica. Hai qualche caso di studio per evidenziare le differenze tra i due??





