Mentre si lavora sul problema di ottimizzazione dell'app Spark, Ho passato molto tempo a cercare di dare un senso alle visualizzazioni dell'interfaccia utente web di Spark. Spark Web UI è uno strumento molto utile per questo compito. Per principianti, diventa molto difficile ottenere informazioni su un problema solo da queste visualizzazioni. Sebbene ci siano ottime risorse sulle prestazioni di Spark, le informazioni erano sparse. Perciò, Ho sentito il bisogno di documentare e condividere i miei insegnamenti.
Destinatari e conclusioni
Questo post presuppone che i lettori abbiano una conoscenza di base dei concetti di Spark.. Questo post aiuterà i principianti a identificare potenziali problemi di prestazioni nelle loro applicazioni in esecuzione da un'interfaccia utente Web Spark.. Il focus è solo sulle informazioni che non sono ovvie dall'interfaccia utente e le inferenze che possono essere tratte da queste informazioni non ovvie. Si noti che non contiene un elenco esaustivo di informazioni da interpretare dall'interfaccia utente Web di Spark, ma solo quelli che ho trovato rilevanti per il mio progetto e, tuttavia, abbastanza generico perché il pubblico lo sappia.
Interfaccia utente web Spark
L'interfaccia utente web di Spark è disponibile solo quando l'applicazione è in esecuzione. Per analizzare le esecuzioni passate, il server della cronologia deve essere abilitato per memorizzare i registri degli eventi che possono quindi essere utilizzati per popolare l'interfaccia utente web.
L'interfaccia utente Web di Spark mostra informazioni utili sulla tua applicazione in schede, vale a dire
- esecutori
- Ambiente
- Lavori
- Etapas
- Magazzinaggio
Il post rimanente descrive le intuizioni di ciascuna delle schede, nell'ordine indicato.
Scheda Esecutori
Fornisce informazioni sulle attività eseguite da ciascun esecutore.
Fig 1: Riepilogo della scheda Esecutore
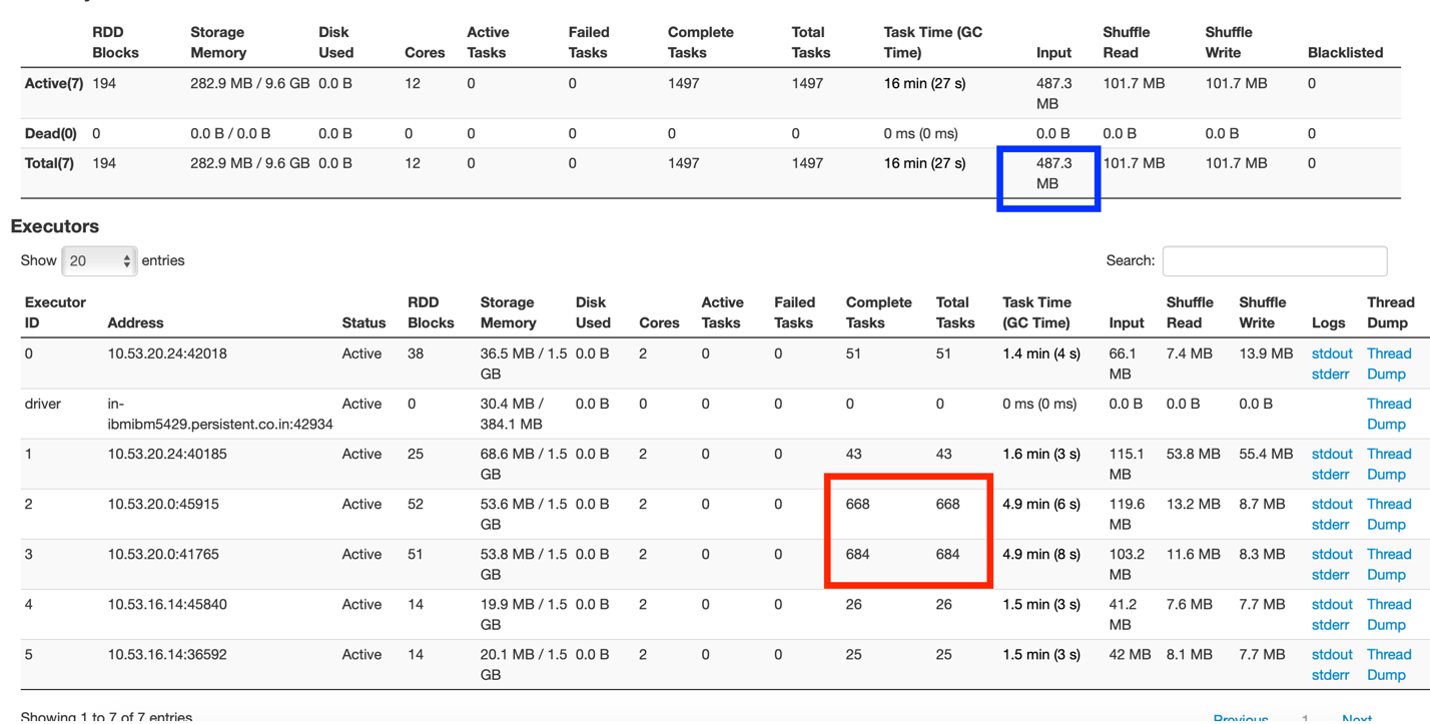
A partir de la figura"Figura" è un termine che viene utilizzato in vari contesti, Dall'arte all'anatomia. In campo artistico, si riferisce alla rappresentazione di forme umane o animali in sculture e dipinti. In anatomia, designa la forma e la struttura del corpo. Cosa c'è di più, in matematica, "figura" è legato alle forme geometriche. La sua versatilità lo rende un concetto fondamentale in molteplici discipline.... 1, si può capire che c'è un controllore e 5 esecutori, ognuno dei quali corre con 2 core e 3 GB di memoria.
La casella contrassegnata in rosso muestra la distribución desigual de las tareas en las que un nodoNodo è una piattaforma digitale che facilita la connessione tra professionisti e aziende alla ricerca di talenti. Attraverso un sistema intuitivo, Consente agli utenti di creare profili, condividere esperienze e accedere a opportunità di lavoro. La sua attenzione alla collaborazione e al networking rende Nodo uno strumento prezioso per chi vuole ampliare la propria rete professionale e trovare progetti in linea con le proprie competenze e obiettivi.... del grappoloUn cluster è un insieme di aziende e organizzazioni interconnesse che operano nello stesso settore o area geografica, e che collaborano per migliorare la loro competitività. Questi raggruppamenti consentono la condivisione delle risorse, Conoscenze e tecnologie, promuovere l'innovazione e la crescita economica. I cluster possono coprire una varietà di settori, Dalla tecnologia all'agricoltura, e sono fondamentali per lo sviluppo regionale e la creazione di posti di lavoro.... está exagerando las tareas, mentre altri sono relativamente inattivi.
La casella contrassegnata in blu mostra che la dimensione dei dati di input era 487,3 MB. Ora, questa app è stata eseguita su una dimensione del set di dati di 83 MB. La dimensione dei dati di input comprende la lettura del set di dati originale e i trasferimenti di dati casuali tra i nodi. Questo mostra che molti dati sono stati mischiati (circa 400+ MB) nell'app.
Scheda Ambiente
Ci sono molti proprietà della scintilla per controllare e regolare l'applicazione. Queste proprietà possono essere impostate quando si invia il lavoro o quando si crea l'oggetto contesto. A meno che la proprietà non venga aggiunta esplicitamente, Non si applica. Sbagliamo nel presumere che le proprietà vengano applicate con i loro valori predefiniti, quando non esplicitamente dichiarato. Tutte le proprietà applicate possono essere visualizzate nella scheda Ambiente. Se la proprietà non si vede lì, significa che la proprietà non è stata applicata affatto.
Scheda Lavori
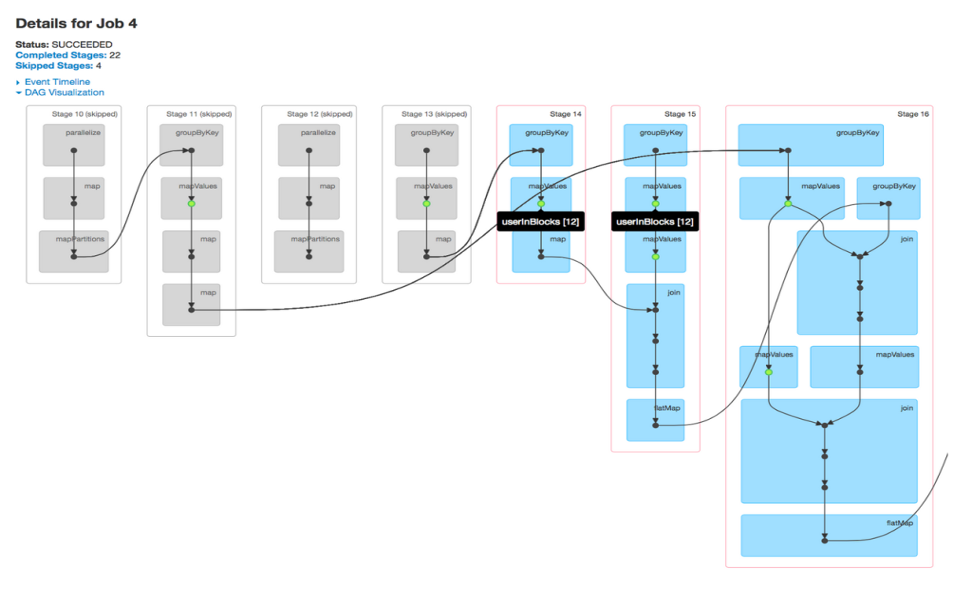
Un trabajo está asociado con una cadena de dependencias Resilient Distributed Datasetun "set di dati" o dataset è una raccolta strutturata di informazioni, che può essere utilizzato per l'analisi statistica, Apprendimento automatico o ricerca. I set di dati possono includere variabili numeriche, categorico o testuale, e la loro qualità è fondamentale per ottenere risultati affidabili. Il suo utilizzo si estende a varie discipline, come la medicina, Economia e scienze sociali, facilitare il processo decisionale informato e lo sviluppo di modelli predittivi.... organizadas en un grafico aciclico diretto (GIORNO) che assomiglia a Fig. 2. Dalle visualizzazioni DAG, puoi trovare le fasi eseguite e il numero di fasi saltate. Per impostazione predefinita, spark non riutilizza i passaggi calcolati in più fasi, a meno che non sia persistente o esplicitamente memorizzato nella cache. Le fasi saltate sono le fasi memorizzate nella cache contrassegnate in grigio, donde los valores de cálculo se almacenan en la memoria y no se vuelven a calcular después de acceder a HDFSHDFS, o File system distribuito Hadoop, Si tratta di un'infrastruttura chiave per l'archiviazione di grandi volumi di dati. Progettato per funzionare su hardware comune, HDFS consente la distribuzione dei dati su più nodi, garantire un'elevata disponibilità e tolleranza ai guasti. La sua architettura si basa su un modello master-slave, dove un nodo master gestisce il sistema e i nodi slave memorizzano i dati, facilitare l'elaborazione efficiente delle informazioni... È sufficiente uno sguardo al display DAG per sapere se i calcoli RDD vengono eseguiti ripetutamente o se vengono utilizzate fasi memorizzate nella cache.
Fig 2: Visualizzazione DAG di un lavoro
Scheda Fasi
Fornisce una visione più approfondita dell'applicazione in esecuzione a livello di attività. Una fase rappresenta un segmento di lavoro svolto in parallelo da singole attività. C'è una mappatura 1-1 tra compiti e partizioni di dati, vale a dire, 1 attività per partizione dati. Si può approfondire un lavoro, in fasi specifiche e fino a ciascuna attività in una fase dall'interfaccia utente Web di Spark.
Il palco offre una buona panoramica delle esecuzioni: Display DAG, scadenze dell'evento, metriche di riepilogo / aggregazione dei tuoi compiti.
Preferisco guardare le tempistiche degli eventi per analizzare i compiti. Danno una rappresentazione pittorica dei dettagli del tempo investito nell'esecuzione della scena. A prima vista, potremmo trarre rapide deduzioni su come si è svolto bene il palco e su come potremmo migliorare ulteriormente i tempi di esecuzione.
Fig 3 – Esempio di cronologia dell'evento
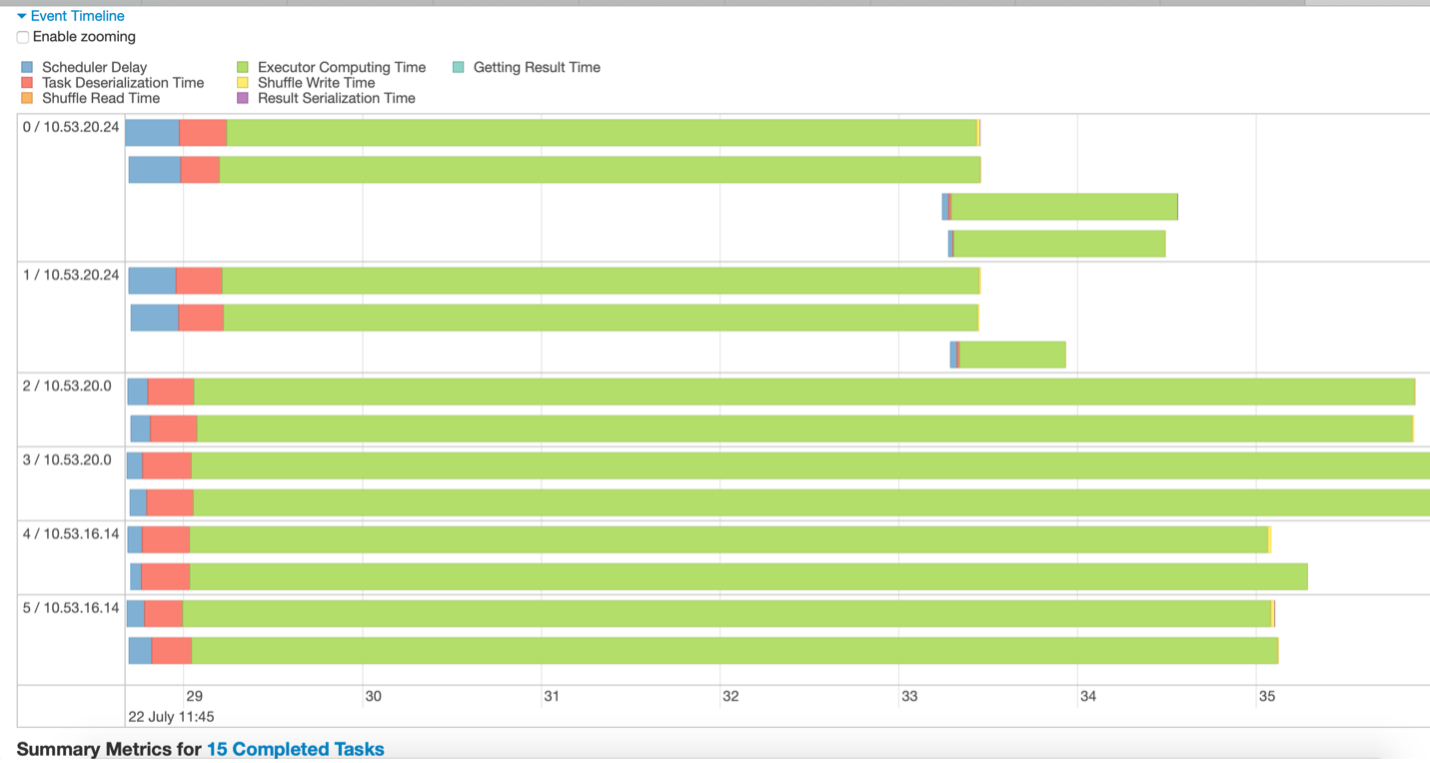
Ad esempio, le inferenze tratte dalla figura 3 potrebbero essere:
- I dati sono suddivisi in 15 partizioni. Perciò, Loro stanno correndo 15 lavoretti (rappresentato con 15 linee verdi).
- Le attività vengono eseguite in 3 nodi, ognuno con 2 esecutori
- La fase viene completata solo quando termina l'attività in esecuzione più lunga. Gli altri esecutori rimangono inattivi fino al termine dell'attività più lunga.
- Pochi compiti a lungo termine, mentre poche attività vengono eseguite per un tempo molto breve, indicando che i dati non sono ben partizionati.
- Non è stato speso molto tempo per ritardare lo scheduler o la serializzazione in questa fase, che è buono.
Fig. 4 – Cronologia degli eventi a una fase con molte partizioni di dati.
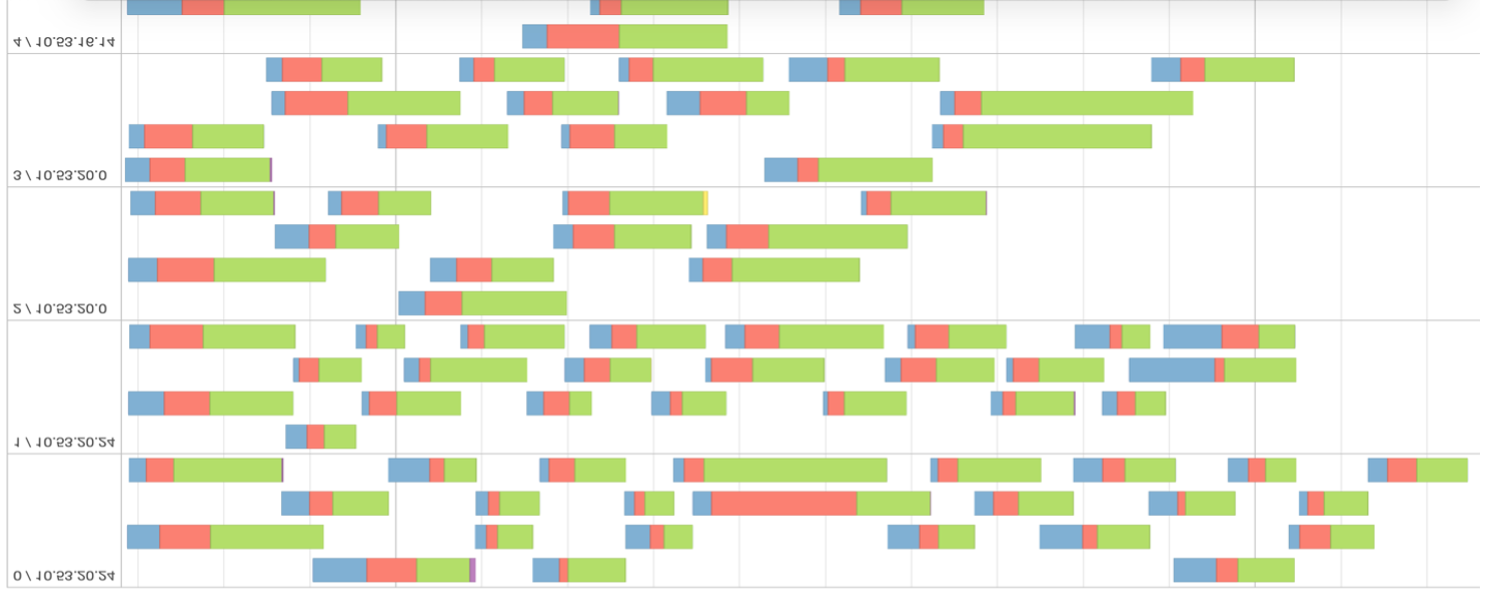
Osservando la figura 4, possiamo dedurre che i dati non sono ben distribuiti e partizionati inutilmente. Dalla metrica di valutazione, si può confermare che la pianificazione delle attività ha richiesto più tempo del tempo di esecuzione effettivo. Maggiore è la percentuale di verde nella timeline, più efficiente sarà il calcolo dello stadio.
È auspicabile avere meno fasi del lavoro. Ogni volta che i dati vengono mischiati, si crea una nuova tappa. Mescolare è costoso e, così, prova a ridurre il numero di fasi di cui il tuo programma ha bisogno.
Dimensione dati di input
Un'altra informazione importante è osservare la dimensione di input dei dati che sono stati mescolati. Uno degli obiettivi è anche ridurre la dimensione di questi dati casuali.
Fig. 5 – Panoramica della scheda Fasi.
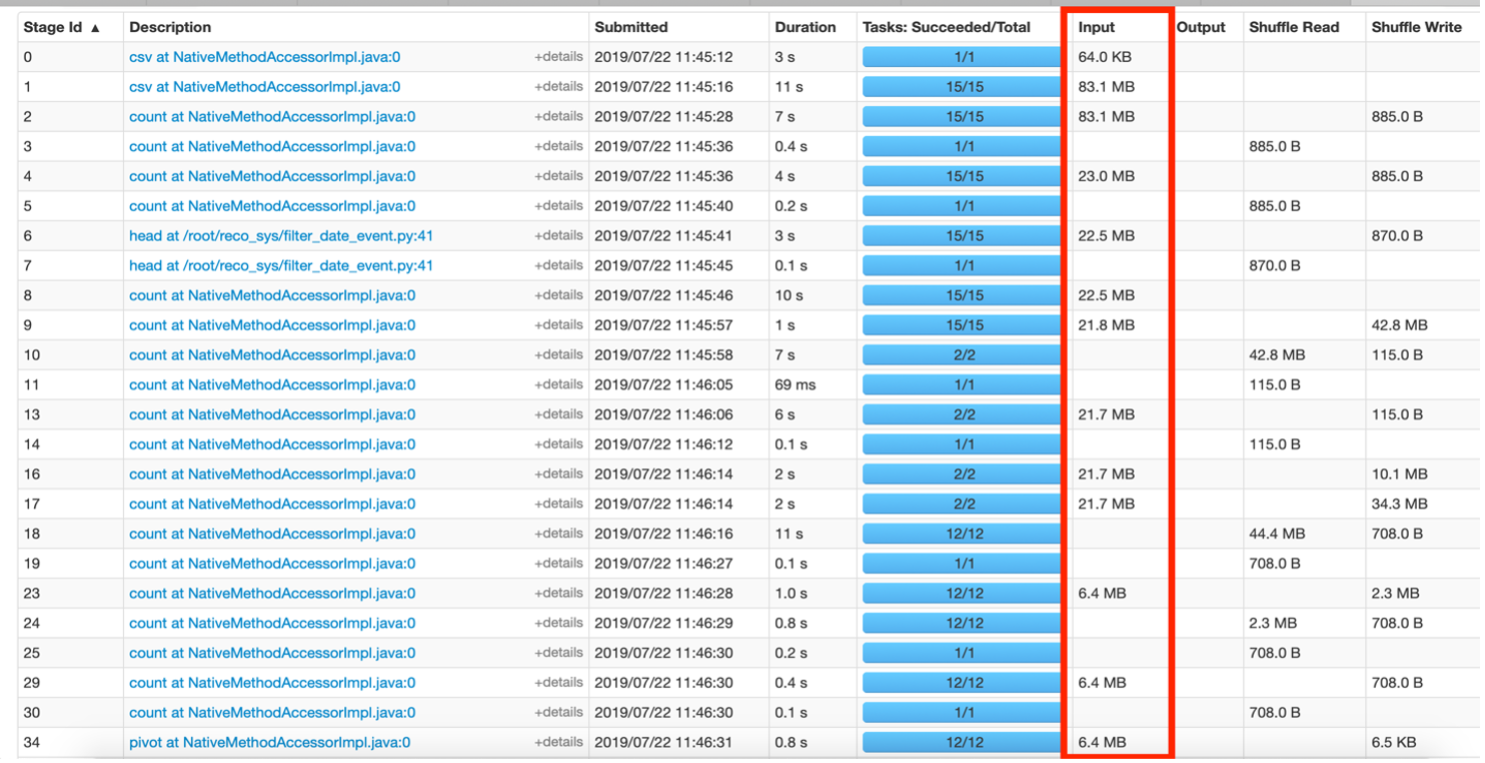
La figura 5 sopra mostra le fasi in cui i dati si muovono in MB. Ciò suggerisce che il codice può essere migliorato per ridurre la dimensione dei dati che sono stati scambiati tra le fasi. Ad esempio, Diciamo se è stato applicato un filtro su alcuni dati per un "evento x"’ dado, quindi nel risultante RDD, la colonna "evento" diventa ridondante poiché tecnicamente tutte le righe provengono dall'evento "x". Questa colonna potrebbe essere rimossa dai futuri RDD creati da questi dati filtrati per salvare ulteriori informazioni trasferite durante le operazioni di shuffle.
TokenIl "Token" es un término utilizado en diversos contextos, generalmente para referirse a un documento o tarjeta que contiene información específica sobre un tema, persona o producto. En ámbitos académicos, se utiliza para registrar datos relevantes sobre investigaciones o fuentes bibliográficas. En el ámbito empresarial, las fichas pueden ser herramientas útiles para organizar datos de clientes o productos, facilitando la gestión y el acceso a la información.... de almacenamiento
Mostra solo gli RDD che sono stati conservati, vale a dire, chi usa persiste () nasconditi (). Per renderlo più leggibile, puoi nominare l'RDD mentre lo memorizzi usando setName (). Solo gli RDD che si desidera conservare dovrebbero essere visualizzati nella scheda Archiviazione e potrebbero essere facilmente riconoscibili con i nomi personalizzati forniti.
Riepilogo
Questo articolo aiuta a fornire informazioni per identificare i problemi dell'interfaccia utente Web di Spark, come la dimensione dei dati che sono stati mescolati, il tempo di esecuzione delle fasi, Ricalcolo RDD a causa della mancanza di memorizzazione nella cache. Se si comprendono i suoi dati e la sua applicazione, quindi la distribuzione ideale dei dati e il numero desiderato di partizioni potrebbero essere misurati deducendo dall'interfaccia utente in esecuzione. Il sovraccarico di un nodo rispetto ad altri nel cluster è un'altra area di miglioramento che potrebbe essere vista in questa interfaccia utente. Il risoluzioneIl "risoluzione" si riferisce alla capacità di prendere decisioni ferme e raggiungere gli obiettivi prefissati. In contesti personali e professionali, Implica la definizione di obiettivi chiari e lo sviluppo di un piano d'azione per raggiungerli. La risoluzione è fondamentale per la crescita personale e il successo in vari ambiti della vita, In quanto ti permette di superare gli ostacoli e mantenere la concentrazione su ciò che conta davvero.... de algunos de estos problemas se discute más en el Articolo sull'ottimizzazione delle prestazioni di Apache Spark.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





