Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
1. introduzione
En este trabajo, presentamos la relación del rendimiento del modelo con un tamaño de conjunto de datos variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... y un número variable de clases de destino. Hemos realizado nuestros experimentos en reseñas de productos de Amazon.
El conjunto de datos contiene el título de la reseña, el texto de la reseña y las calificaciones. Hemos considerado las calificaciones como nuestra clase de salida. Cosa c'è di più, hemos realizado tres experimentos (polarità 0/1), tres clases (positivo, negativo, neutro) y cinco clases (calificación de 1 un 5). Hemos incluido tres modelos tradicionales y tres de apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute....
Modelos de aprendizaje automático
1. Regressione logistica (LR)
2. Supporta la macchina vettoriale (SVM)
3. Naive-Bayes (NB)
Modelos de aprendizaje profundo
1. neuronale rossoLe reti neurali sono modelli computazionali ispirati al funzionamento del cervello umano. Usano strutture note come neuroni artificiali per elaborare e apprendere dai dati. Queste reti sono fondamentali nel campo dell'intelligenza artificiale, consentendo progressi significativi in attività come il riconoscimento delle immagini, Elaborazione del linguaggio naturale e previsione delle serie temporali, tra gli altri. La loro capacità di apprendere schemi complessi li rende strumenti potenti.. de convolución (CNN)
2. Memoria a corto plazo (LSTM)
3. Unidad recurrente cerrada (GRU)
2. El conjunto de datos
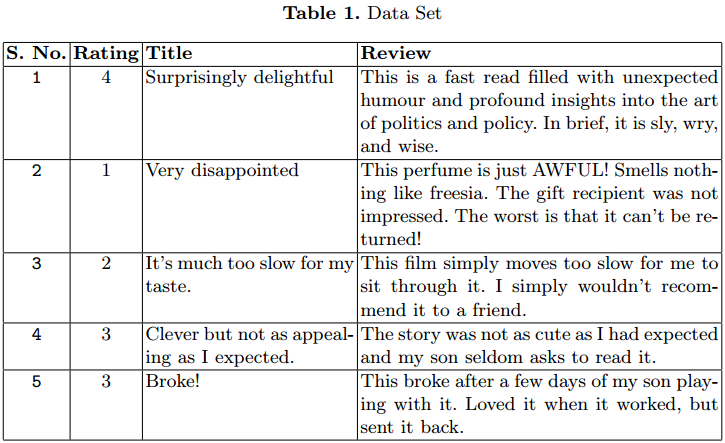
Usamos el conjunto de datos de revisión de productos de Amazon para nuestro experimento. Il set di dati contiene 3,6 millones de instancias de la revisión del producto en forma de texto.
Se han proporcionado archivos separados de tren (3m) e processo (0,6m) in formato CSV. Cada instancia tiene 3 attributi. El primer atributo es el classificazione Entra 1 e 5. El segundo atributo es el qualificazione de la revisión. El último es el texto de revisión.
En la Tabla 1 se dan algunos casos. Hemos considerado solo 1,5 m.
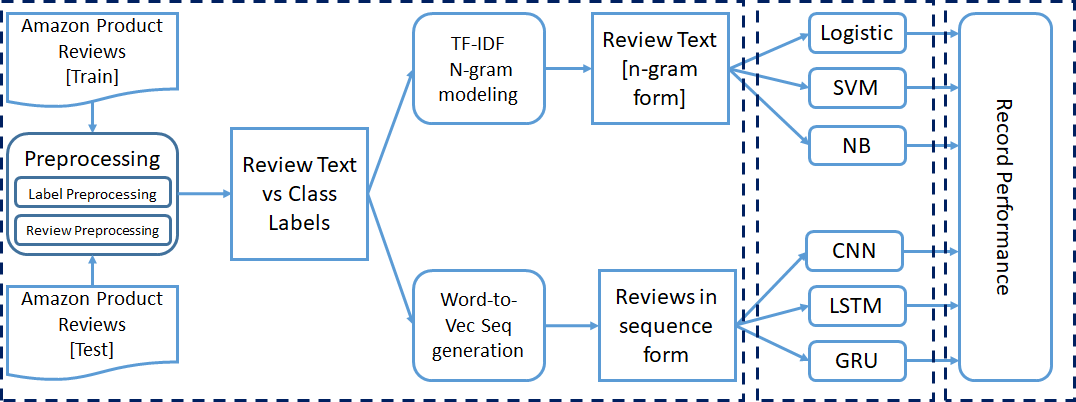
3. Experimento para análisis
Ya hemos mencionado que todo el experimento se realizó para clasificación binaria, de tres clases y de cinco clases. Hemos realizado algunos pasos de procesamiento previo en el conjunto de datos antes de pasarlo a los modelos de clasificación. Cada experimento se realizó de forma incremental.
Comenzamos nuestra capacitación con 50000 instancias y aumentamos a 1,5 millones de instancias para capacitación. Finalmente, registramos los parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... de rendimiento de cada modelo.
3.1 Pre-elaborazione
3.1.1 Mapeo de etiquetas:
Hemos considerado las calificaciones como la clase para el texto de revisión. El rango del atributo de calificación está entre 1 e 5. Necesitamos asignar estas calificaciones al número de clases, consideradas para el experimento en particular.
un) Clasificación binaria: –
Qui, asignamos la calificación 1 e 2 a la clase 0 y calificación 4 e 5 a clase 1. Esta forma de clasificación puede tratarse como un problema de clasificación de sentimientos, donde las reseñas con 1 e 2 calificaciones están en clase negativa y 4 e 5 están en clase positiva.
No hemos considerado las revisiones con una calificación de 3 para el experimento de clasificación binaria. Perciò, obtenemos menos instancias para el addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... en comparación con los otros dos experimentos.
B) Clasificación de tres clases: –
Qui, ampliamos nuestro experimento de clasificación anterior. Ahora consideramos la calificación 3 como una nueva clase separada. La nueva asignación de calificaciones a clases es la siguiente: Qualificazione 1 e 2 asignada a la clase 0 (Negativo), Classificazione 3 asignada a la clase 1 (Neutro) y calificación 4 e 5 asignados a la clase 2 (Positivo).
Instancias para clase 1 son muy inferiores a la clase 0 e 2, lo que crea un problema de desequilibrio de clases. Perciò, noi usiamo micropromedio al calcular las medidas de rendimiento.
C) Clasificación de cinco clases: –
Qui, consideramos cada calificación como una clase separada. La asignación es la siguiente: Classificazione 1 asignada a la clase 0, Classificazione 2 asignada a la clase 1, Classificazione 3 asignada a la clase 2, Classificazione 4 asignada a la clase 3y la clasificación 5 asignada a la clase 4.
3.1.2 Revisar el procesamiento previo de texto:
Las reseñas de productos de Amazon están en formato de texto. Necesitamos convertir los datos de texto a un formato numérico, que se puede utilizar para entrenar los modelos.
Para los modelos de aprendizaje automático, convertimos el texto de revisión en formato vectorial TF-IDF con la ayuda de el sklearn Biblioteca. En lugar de tomar cada palabra individualmente, consideramos el modelo de n-gramas mientras creamos los vectores TF IDF. El rango de N-gramos se establece en 2 – 3, y el valor de función máxima se establece en 5000.
Para los modelos de aprendizaje profundo, necesitamos convertir los datos de secuencia de texto en datos de secuencia numérica. Aplicamos el palabra a vector modelado para convertir cada palabra en el vector equivalente.
El conjunto de datos contiene una gran cantidad de palabras; così, la codificación en caliente 1- es muy ineficaz. Aquí hemos utilizado un pre-entrenado word2Vec modelo para representar cada palabra con un vector de columna de tamaño 300. Establecemos la longitud máxima de la secuencia igual a 70.
Las reseñas con una longitud de palabra inferior a 70 se rellenan con ceros al principio. Para las reseñas con una longitud de palabra superior a 70, seleccionamos las primeras 70 palabras para el procesamiento de word2Vec.
3.2 Entrenamiento del modelo de clasificación
Hemos mencionado anteriormente que hemos tomado tres modelos tradicionales de aprendizaje automático (LR, SVM, NB) y tres modelos de aprendizaje profundo (CNN, LSTM, GRU). El texto preprocesado con la información de la etiqueta se pasa a modelos para su entrenamiento.
All'inizio, entrenamos los seis modelos con 50000 instancias y los probamos con 5000 Istanze. Para la próxima iteración, agregamos 50000 e 5000 instancias más en el tren y el conjunto de prueba, rispettivamente. Realizamos 30 iterazioni; così, Noi consideriamo 1.5 m, 150000 instancias para el tren y el conjunto de prueba en la última iteración.
La formación mencionada anteriormente se realiza para los tres tipos de experimentos de clasificación.
3.3 Configuraciones del modelo
Hemos utilizado la configuración predeterminada de hiperparámetros de todos los clasificadores tradicionales utilizados en este experimento. e la CNN, el tamaño de entrada es 70 con un tamaño de incrustación de 300. La omisión de la capa de incrustación se establece en 0.3. Se ha aplicado una convolución 1-D en la entrada, con el tamaño de salida de la convolución establecido en 100. El tamaño del kernel se mantiene en 3. riprendereLa funzione di attivazione ReLU (Unità lineare rettificata) È ampiamente utilizzato nelle reti neurali grazie alla sua semplicità ed efficacia. Definito come ( F(X) = massimo(0, X) ), ReLU consente ai neuroni di attivarsi solo quando l'input è positivo, che aiuta a mitigare il problema dello sbiadimento del gradiente. È stato dimostrato che il suo utilizzo migliora le prestazioni in varie attività di deep learning, rendendo ReLU un'opzione.. Il funzione svegliaLa funzione di attivazione è un componente chiave nelle reti neurali, poiché determina l'output di un neurone in base al suo input. Il suo scopo principale è quello di introdurre non linearità nel modello, Consentendo di apprendere modelli complessi nei dati. Ci sono varie funzioni di attivazione, come il sigma, ReLU e tanh, Ognuno con caratteristiche particolari che influiscono sulle prestazioni del modello in diverse applicazioni.... se ha utilizado en la capa de convolución. Para el proceso de agrupación, se utiliza la agrupación máxima. El Optimizador de Adam se utiliza con una Funzione di perditaLa funzione di perdita è uno strumento fondamentale nell'apprendimento automatico che quantifica la discrepanza tra le previsioni del modello e i valori effettivi. Il suo obiettivo è quello di guidare il processo di formazione minimizzando questa differenza, consentendo così al modello di apprendere in modo più efficace. Esistono diversi tipi di funzioni di perdita, come l'errore quadratico medio e l'entropia incrociata, ognuno adatto a compiti diversi e... de entropía cruzada.
LSTM y GRU también tienen la misma configuración de hiperparámetros. El tamaño de la Livello di outputIl "Livello di output" è un concetto utilizzato nel campo della tecnologia dell'informazione e della progettazione di sistemi. Si riferisce all'ultimo livello di un modello o di un'architettura software che è responsabile della presentazione dei risultati all'utente finale. Questo livello è fondamentale per l'esperienza dell'utente, poiché consente l'interazione diretta con il sistema e la visualizzazione dei dati elaborati.... cambia con el experimento en ejecución.
3.4 Medidas de desempeño

Fórmula de puntuación F
Hemos tomado la puntuación F1 para analizar el rendimiento de los modelos de clasificación con diferentes etiquetas de clase y recuento de instancias. Existe una compensación entre Precision y Recall si intentamos mejorar Recall, Precision se vería comprometida, y lo mismo se aplica a la inversa.
La puntuación F1 combina precisión y recuerdo en forma de media armónica.
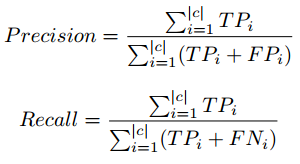
Precisione, fórmula de recuperación en micropromedio
En la clasificación de tres y cinco clases, observamos que el recuento de instancias con calificación 3 es muy inferior en la comparación de otras calificaciones, lo que crea el problema de desequilibrio de clases.
Perciò, utilizamos el concepto de micropromedio al calcular los parámetros de rendimiento. El micropromedio se encarga del desequilibrio de clases al calcular la precisión y la recuperación. Para obtener información detallada sobre Precision, Recall, visite el siguiente enlace: enlace wiki.
4 Resultados y observación
In questa sezione, hemos presentado los resultados de nuestros experimentos con diferentes tamaños de conjuntos de datos y el número de etiquetas de clase. Se ha presentado un gráfico separado para cada experimento. Los gráficos se trazan entre el tamaño del conjunto de pruebas y la puntuación F1.
Cosa c'è di più, proporcionamos la Figura"Figura" è un termine che viene utilizzato in vari contesti, Dall'arte all'anatomia. In campo artistico, si riferisce alla rappresentazione di forme umane o animali in sculture e dipinti. In anatomia, designa la forma e la struttura del corpo. Cosa c'è di più, in matematica, "figura" è legato alle forme geometriche. La sua versatilità lo rende un concetto fondamentale in molteplici discipline.... 5, que contiene seis subparcelas. Cada subparcela corresponde a un clasificador. Hemos presentado la tasa de cambio entre las puntuaciones de rendimiento de dos experimentos con respecto al tamaño variable del conjunto de pruebas.
Figura 2
La figura 2 presenta el desempeño de los clasificadores en la tarea de clasificación binaria. In questo caso, el tamaño real de la prueba es menor que los datos que hemos tomado para la prueba porque se eliminaron las reseñas con calificación 3.
Los clasificadores de aprendizaje automático (LR, SVM, NB) funcionan de manera constante excepto por ligeras variaciones en los puntos de partida.
El clasificador de aprendizaje profundo (GRU y CNN) comienza con menos rendimiento en comparación con SVM y LR. Después de tres iteraciones iniciales, GRU y CNN dominan continuamente los clasificadores de aprendizaje automático.
El LSTM realiza el aprendizaje más eficaz. LSTM comenzó con el rendimiento más bajo. UN misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... que el conjunto de entrenamiento cruza 0.3 m, LSTM ha mostrado un crecimiento continuo y terminó con GRU.
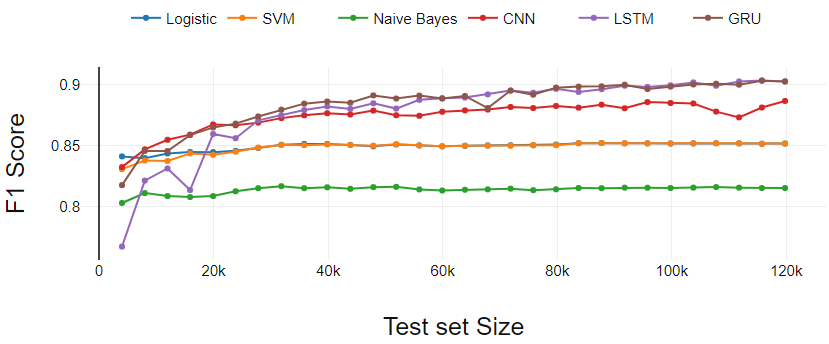
Fig 2. Análisis de rendimiento de clasificación binaria
figura 3
La figura 3 presenta los resultados del experimento de clasificación de tres clases. El rendimiento de todos los clasificadores se degrada a medida que aumentan las clases. El rendimiento es similar a la clasificación binaria si comparamos un clasificador en particular con otros.
La única diferencia está en el rendimiento de LSTM. Qui, LSTM ha aumentado continuamente el rendimiento a diferencia de la clasificación binaria. LR funcionó un poco mejor en comparación con SVM. Tanto LR como SVM se desempeñaron por igual en el experimento de clasificación binaria.
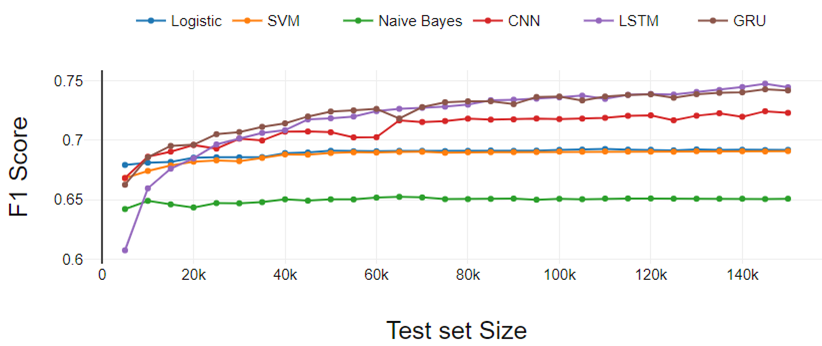
Fig 3. Análisis de rendimiento de clasificación de tres clases
Figura 4
La figura 4 representa los resultados del experimento de clasificación de cinco clases. Los resultados siguen las mismas tendencias que aparecieron en el experimento de clasificación binaria y de tres clases. Aquí la diferencia de rendimiento entre LR y SVM aumentó un poco más.
Perciò, podemos concluir que la brecha de desempeño de LR y SVM aumenta a medida que aumenta el número de clases.
A partir del análisis general, los clasificadores de aprendizaje profundo funcionan mejor a medida que aumenta el tamaño del conjunto de datos de entrenamiento y los clasificadores tradicionales muestran un rendimiento constante.
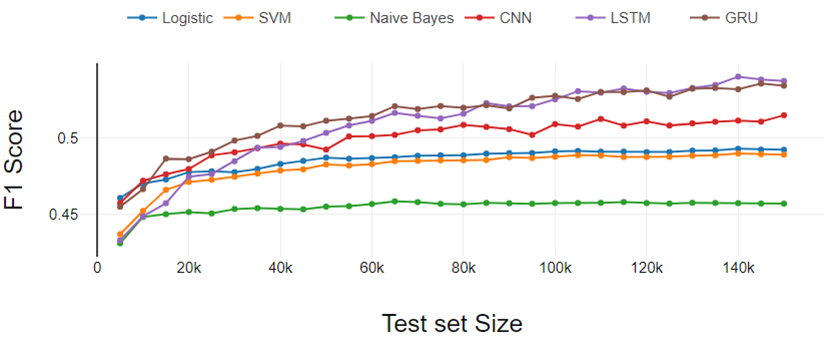
Fig 4. Análisis de rendimiento de clasificación de cinco clases
Figura 5
La figura 5 representa la relación de rendimiento con respecto al cambio en el número de clases y el tamaño del conjunto de datos. La figura contiene seis subparcelas, una para cada clasificador. Cada subtrama tiene dos líneas; una línea muestra la relación de rendimiento entre la clasificación de tres clases y la clase binaria en diferentes tamaños de conjuntos de datos.
Otra línea representa la relación de rendimiento entre la clasificación de cinco clases y la de tres clases en diferentes tamaños de conjuntos de datos. Hemos encontrado que los clasificadores tradicionales tienen una tasa de cambio constante. Para clasificadores tradicionales, ritmo de cambio es independiente del tamaño del conjunto de datos. No podemos comentar sobre el comportamiento de los modelos de aprendizaje profundo con respecto al cambio en las clases numéricas y el tamaño del conjunto de datos debido al patrón variable en la tasa de cambio.
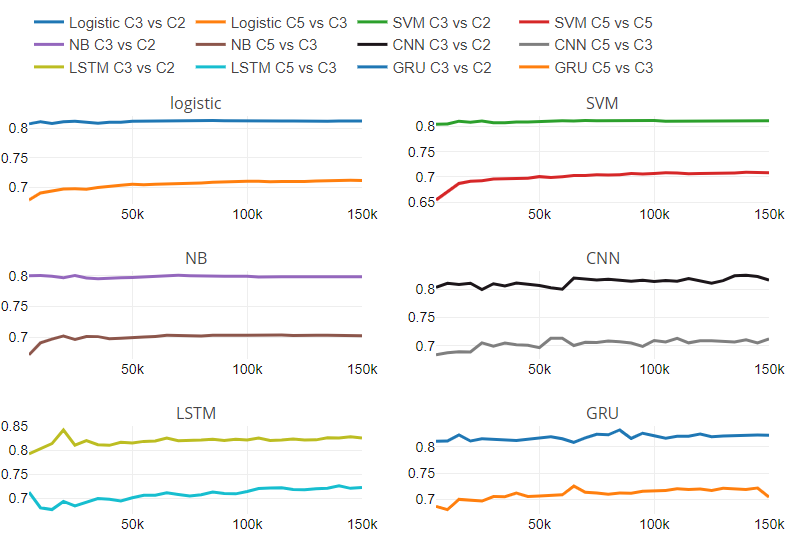
Además del análisis experimental mencionado anteriormente, hemos analizado los datos de texto clasificados erróneamente. Encontramos observaciones interesantes que afectaron la clasificación.
Palabras sarcásticas: –
Los clientes escribieron reseñas sarcásticas sobre los productos. Le han dado la calificación 1 oh 2, pero usaron muchas palabras de polaridad positiva. Ad esempio, un cliente calificó a 1 y escribió la siguiente reseña: “¡Oh! ¡¡Qué cargador tan fantástico tengo !! ". El clasificador se confundió con este tipo de palabras y frases de polaridad.
Uso de palabras de alta polaridad: –
Los clientes han otorgado una calificación promedio (3) pero utilizaron palabras muy polarizadas en sus reseñas. Ad esempio, fantástico, tremendo, notable, patético, eccetera.
Uso de palabras raras: –
Teniendo un conjunto de datos de tamaño 3.6M, todavía encontramos muchas palabras poco comunes, que afectaron el desempeño de la clasificación. Los errores ortográficos, los acrónimos, las palabras de formas cortas utilizadas por los revisores también son factores importantes.
5. Nota finale
Hemos analizado el rendimiento de los modelos tradicionales de aprendizaje automático y aprendizaje profundo con diferentes tamaños de conjuntos de datos y el número de la clase objetivo.
Hemos descubierto que los clasificadores tradicionales pueden aprender mejor que los clasificadores de aprendizaje profundo si el conjunto de datos es pequeño. Con el aumento en el tamaño del conjunto de datos, los modelos de aprendizaje profundo obtienen un impulso en el rendimiento.
Hemos investigado la tasa de cambio en el desempeño del clasificador de binario a tres clases e tres clases a cinco clases problema con el tamaño variable del conjunto de datos.
Abbiamo usato Duro biblioteca de aprendizaje profundo para la experimentación. Los resultados y los scripts de Python están disponibles en el siguiente enlace: Collegamento GitHub.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





