Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati.
introduzione
E impariamo strada facendo.
Le compagnie, allo stesso modo, applicare il loro apprendimento passato al processo decisionale relativo alle operazioni e alle nuove iniziative, ad esempio, relativi alla classificazione dei clienti, prodotti, eccetera. tuttavia, qui diventa un po' più complesso poiché ci sono più parti interessate coinvolte. Cosa c'è di più, le decisioni devono essere precise a causa del loro impatto più ampio.
Con l'evoluzione della tecnologia digitale, gli esseri umani hanno sviluppato molteplici risorse; le macchine sono una di queste. Abbiamo imparato (e continuiamo) utilizzare macchine per analizzare i dati utilizzando le statistiche per generare informazioni utili per aiutare a prendere decisioni e previsioni.
Le macchine non fanno magie con i dati, ma applicano semplici statistiche.
In tale contesto, Esaminiamo un paio di algoritmi di apprendimento automatico comunemente usati per la classificazione e cerchiamo di capire come funzionano e come si confrontano tra loro.. Ma prima, capiamo alcuni concetti correlati.
Concetti basilari
Il apprendimento supervisionatoL'apprendimento supervisionato è un approccio di apprendimento automatico in cui un modello viene addestrato utilizzando un set di dati etichettati. Ogni input nel set di dati è associato a un output noto, consentendo al modello di imparare a prevedere i risultati per nuovi input. Questo metodo è ampiamente utilizzato in applicazioni come la classificazione delle immagini, Riconoscimento vocale e previsione delle tendenze, sottolineandone l'importanza in... se define como la categoría de análisis de datos donde el resultado objetivo es conocido o etiquetado, ad esempio, indipendentemente dal fatto che il cliente abbia acquistato o meno un prodotto. tuttavia, quando l'intenzione è di raggrupparli in base a ciò che tutti hanno acquistato, quindi diventa Incustodito. Questo può essere fatto per esplorare la relazione tra i clienti e ciò che acquistano.
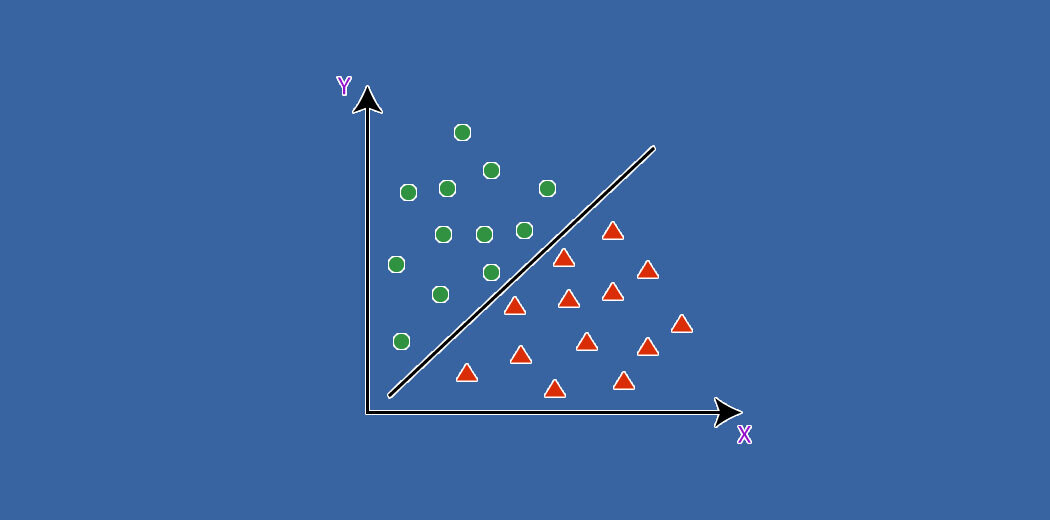
Sia la classificazione che la regressione appartengono all'apprendimento supervisionato, ma il primo si applica quando il risultato è finito, mentre l'ultimo è per infiniti possibili valori di risultato (ad esempio, prevedere il valore in dollari dell'acquisto).
La distribución normal es la conocida distribución en forma de campana de una variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... continuo. Questa è una naturale estensione dei valori che normalmente assume un parametro..
Poiché i predittori possono avere diversi intervalli di valori, ad esempio, il peso umano può essere fino a 150 (kg), ma l'altezza tipica è solo fino a 6 (torte); i valori hanno bisogno di scala (sulla rispettiva media) per renderli comparabili.
La collinearità è quando due o più predittori sono correlati., vale a dire, i loro valori si muovono insieme.
I valori anomali sono valori eccezionali di un predittore, che può o non può essere vero.
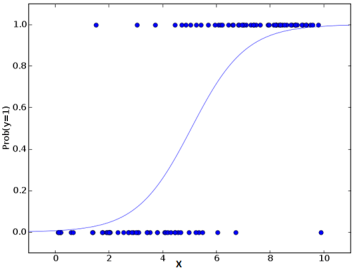
Regressione logistica
La regressione logistica utilizza il potere della regressione per eseguire la classificazione e lo fa molto bene da diversi decenni., per rimanere tra i modelli più popolari. Uno dei motivi principali del successo del modello è il suo potere di spiegabilità., vale a dire, evidenziare il contributo dei singoli predittori, quantitativamente.
A differenza della regressione che utilizza i minimi quadrati, il modello utilizza la massima verosimiglianza per adattare una curva sigmoidea sulla distribuzione della variabile target.
Data la suscettibilità del modello alla multicollinearità, applicarlo passo dopo passo risulta essere un approccio migliore per finalizzare i predittori scelti del modello.
L'algoritmo è una scelta popolare in molte attività di elaborazione del linguaggio naturale., ad esempio, rilevamento del linguaggio tossico, classificazione degli argomenti, eccetera.
Reti neurali artificiali
Reti neurali artificiali (ANN), così chiamati perché cercano di imitare il cervello umano, sono adatti per set di dati grandi e complessi. La sua struttura è composta da strati di nodi intermedi (simile ai neuroni) che sono assegnati insieme ai più ingressi e all'uscita di destinazione.
È un algoritmo di autoapprendimento, poiché inizia con una mappatura iniziale (a caso) e, da allora, adatta in modo iterativo i relativi pesi per ottimizzare l'output desiderato per tutti i record. Las múltiples capas brindan una capacidad de apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute... para poder extraer características de nivel superior de los datos sin procesar.
L'algoritmo fornisce un'elevata precisione di previsione, ma è necessario ridimensionare le funzioni numeriche. Ha ampie applicazioni in campi futuri, inclusa la visione artificiale, PNL, riconoscimento vocale, eccetera.

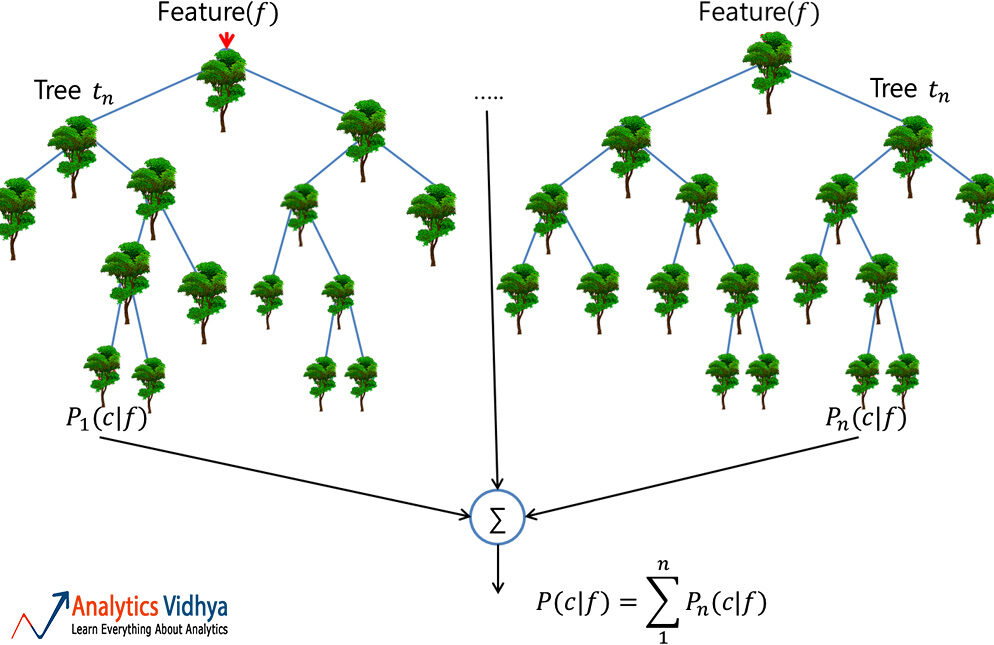
foresta casuale
Una foresta casuale è un insieme affidabile di più alberi decisionali. (o CARRELLO); sebbene più popolare per la classificazione rispetto alle applicazioni di regressione. Qui, i singoli alberi sono costruiti mediante insacco (vale a dire, aggregazione di bootstrap che non sono altro che set di dati di treni multipli creati dal campionamento dei registri con sostituzione) e dividi usando meno funzioni. La risultante foresta diversificata di alberi non correlati mostra una variazione ridotta; così, è più robusto contro il cambiamento dei dati e traduce la sua precisione di previsione in nuovi dati.
tuttavia, l'algoritmo non funziona bene per set di dati che hanno molti valori anomali, qualcosa che deve essere affrontato prima di costruire il modello.
Ha ampie applicazioni in campo finanziario., Al dettaglio, aeronautico e molti altri.
Bayes ingenuo
Anche se potremmo non rendercene conto, questo è l'algoritmo più comunemente usato per filtrare le email di spam!!
Applicare quella che è nota come probabilità a posteriori usando il teorema di Bayes per fare la categorizzazione dei dati non strutturati. e così facendo, presuppone ingenuamente che i predittori siano indipendenti, cosa potrebbe non essere vero.
El modelo funciona bien con un pequeño conjunto de datos de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina...., a condizione che tutte le classi del predittore categoriale siano presenti.
KNN
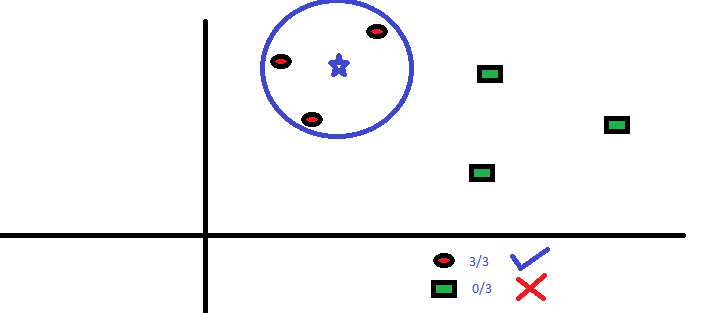
L'algoritmo K-Nemost Neighbor (KNN) prevede in base al numero specificato (K) dei punti dati vicini più vicini. Qui, la preelaborazione dei dati è significativa in quanto influisce direttamente sulle misurazioni della distanza. Non come gli altri, il modello non ha formula matematica, nessuna capacità descrittiva.
Qui, il parametro 'k’ deve essere scelto con saggezza; poiché un valore inferiore a quello ottimale porta a una distorsione, mentre un valore più alto influisce sull'accuratezza della previsione.
Si tratta di un modello semplice e abbastanza accurato, preferito principalmente per insiemi di dati più piccoli, a causa degli enormi calcoli coinvolti nei predittori continui.
a livello semplice, KNN può essere utilizzato in un ambiente predittivo bivariato, ad esempio, altezza e peso, per determinare il sesso dato un campione.
Mettere tutto insieme
Le prestazioni di un modello dipendono principalmente dalla natura dei dati. Poiché i set di dati aziendali hanno più predittori e sono complessi, è difficile identificare un algoritmo che funzioni sempre bene. Perciò, la prassi abituale è provare diversi modelli e trovare quello giusto.
Come confronto di alto livello, los aspectos más destacados que se encuentran generalmente para cada uno de los algoritmos anteriores se anotan a continuación en algunos parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... comunes; per servire come un'istantanea di riferimento rapido.
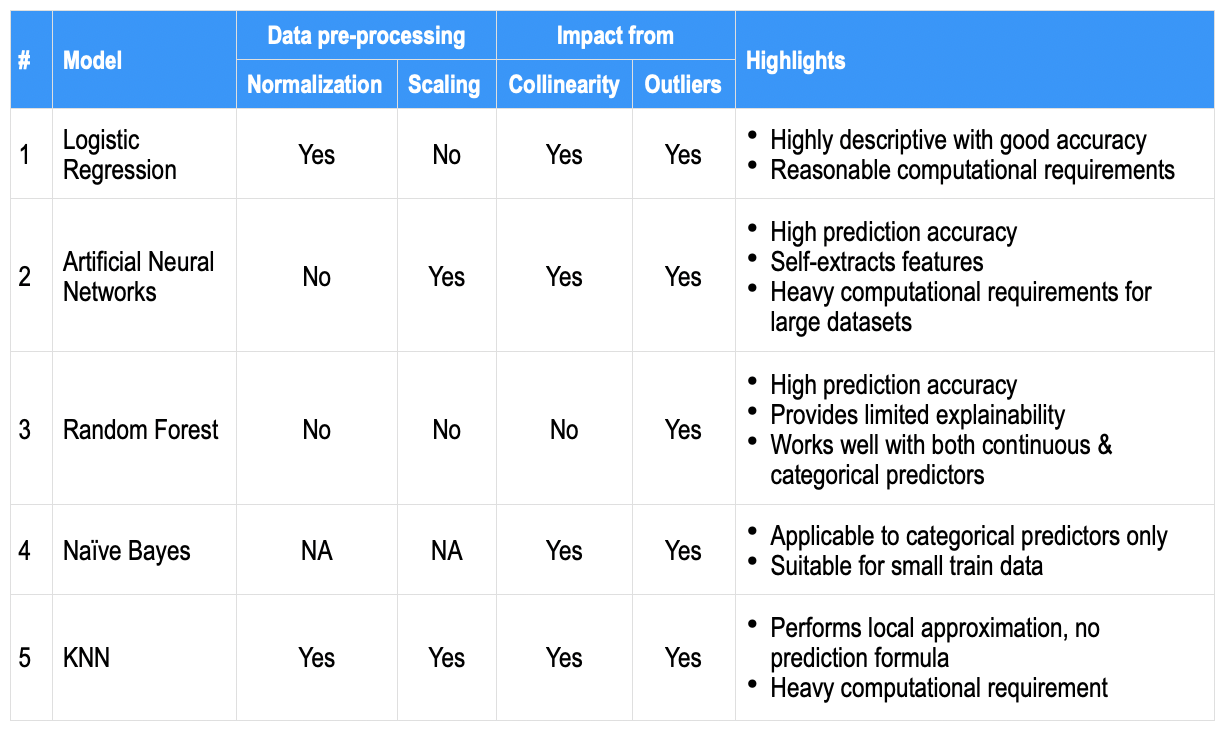
Cosa c'è di più, ci sono più leve, ad esempio, bilancio dei dati, imputazione, convalida incrociata, impostato tra algoritmi, più grande set di dati del treno, eccetera. più l'ottimizzazione dell'iperparametro del modello, che può essere utilizzato per ottenere precisione. Mentre l'accuratezza della previsione può essere più desiderabile, le aziende cercano anche predittori eccezionali che contribuiscano (vale a dire, un modello descrittivo o la sua conseguente spiegabilità).
Finalmente, l'apprendimento automatico consente agli esseri umani di decidere quantitativamente, prevedere e guardare oltre l'ovvio, anche se a volte anche in aspetti precedentemente sconosciuti.





