Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati.
introduzione
Big Data se refiere a una combinación de datos estructurados y no estructurados que pueden medirse en petabytes o exabytes. Generalmente, utilizamos 3V para caracterizar los 3V de big data, vale a dire, el volumen de datos, la variedad de tipos de datos y la velocidad a la que se procesan.
Estas tres características dificultan el manejo de macrodatos. Perciò, los macrodatos son costosos en términos de inversión en una gran cantidad de almacenamiento de servidor, sofisticadas máquinas de análisis y metodologías de minería de datos. METROCualquier organización encuentra esto engorroso tanto técnica como económicamente y, così, está pensando en cómo lograr Se pueden lograr resultados similares utilizando muchas menos sofisticaciones.. Perciò, están tratando de convertir macrodatos en pequeños datos., que consta de fragmentos de datos utilizables. Quanto segue figura"Figura" è un termine che viene utilizzato in vari contesti, Dall'arte all'anatomia. In campo artistico, si riferisce alla rappresentazione di forme umane o animali in sculture e dipinti. In anatomia, designa la forma e la struttura del corpo. Cosa c'è di più, in matematica, "figura" è legato alle forme geometriche. La sua versatilità lo rende un concetto fondamentale in molteplici discipline.... [1] muestra una comparación.
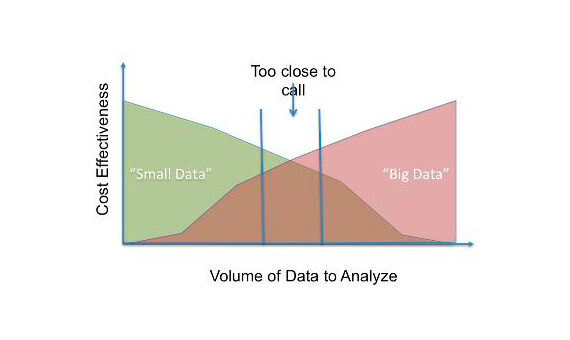
Intentemos explorar una técnica estadística simple, que se puede utilizar para crear una parte utilizable de datos a partir de big data. La muestra, que es básicamente un subconjunto de la población, debe seleccionarse de tal manera que represente adecuadamente a la población. Esto puede garantizarse empleando pruebas estadísticas.
Introducción al muestreo de yacimientos
La idea clave detrás del muestreo de reservorios es crear un ‘reservorio’ a partir de un gran océano de datos. Sea ‘N’ el tamaño de la población y ‘n’ La dimensione del campione. Cada elemento de la población tiene la misma probabilidad de estar presente en la muestra y esa probabilidad es (n / n). Con esta idea clave, tenemos que crear una submuestra. Debe tenerse en cuenta que cuando creamos una muestra, las distribuciones deben ser idénticas no solo en filas sino también en columnas.
Generalmente, nos enfocamos solo en las filas, pero también es importante mantener la distribución de las columnas. Las columnas son las características de las que aprende el algoritmo de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina..... Perciò, también tenemos que realizar pruebas estadísticas para cada característica para garantizar que la distribución sea idéntica.
El algoritmo es el siguiente: Inicialice el yacimiento con los primeros ‘n’ elementos de la población de tamaño ‘N’. Luego lea cada fila de su conjunto de datos (io> n). In ogni iterazione, calcolare (n / io). Reemplazamos los elementos del reservorio del siguiente conjunto de ‘n’ elementos con una probabilidad que disminuye gradualmente.
R[io] = S[io]
for i = n+1 to N:
j = U ~ [1, io]
si j <= n:
R[J] = S[io]
Test statistici
Come ho detto precedentemente, debemos asegurarnos de que todas las columnas (caratteristiche) del embalse se distribuyan de manera idéntica a la población. Usaremos la prueba de Kolmogorov-Smirnov para características continuas y la prueba de chi-cuadrado de Pearson para características categóricas.
La prueba de Kolmogorov-Smirnov se utiliza para verificar si las funciones de distribución acumulativa (CDF) de la población y la muestra son las mismas. Comparamos las CDF de la población F_N (X) con el de la muestra F_n (X).
𝐹𝑁?
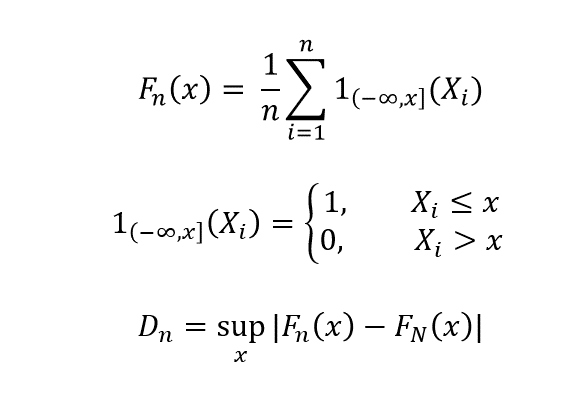
Como n -> n, D_n -> 0, si las distribuciones son idénticas. Esta prueba debe realizarse para todas las características del conjunto de datos que son continuas.
Per caratteristiche categoriali, podemos realizar la prueba de chi-cuadrado de Pearson. Sea O_i el número de observaciones de la categoría ‘i’ y ne el número de muestras. Sea E_i el recuento esperado de la categoría ‘i’. Entonces E_i = N p_i, donde p_i es la probabilidad de pertenecer a la categoría ‘i’. Entonces el valor de chi-cuadrado viene dado por la siguiente relación:
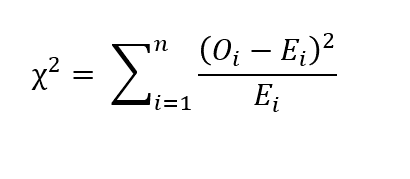
Si chi-cuadrado = 0, eso significa que los valores observados y los valores esperados son los mismos. Si el valor p de la prueba estadística es mayor que el nivel de significancia, decimos que la muestra es estadísticamente significativa.
Note finali
El muestreo de yacimientos se puede utilizar para crear una parte útil de datos a partir de big data siempre que las dos pruebas, Kolmogorov-Smirnov y chi-cuadrado de Pearson, sean exitosas. Los rumores recientes son, Certo, macrodatos. Los modelos centralizados como en la arquitectura de big data vienen acompañados de grandes dificultades. Para descentralizar las cosas y, così, hacer que el trabajo sea modular, tenemos que crear pequeños fragmentos de datos útiles y luego obtener información significativa de ellos. Creo que deberían realizarse más esfuerzos en esta dirección, en lugar de invertir en arquitectura para admitir big data.
Riferimenti
1. https://www.bbvaopenmind.com/en/technology/digital-world/small-data-vs-big-data-back-to-the-basics/





