Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
introduzione
macchina. Si ispira al funzionamento di un cervello umano e, così, è un insieme di algoritmi di rete neurale che cerca di imitare il funzionamento di un cervello umano e imparare dalle esperienze.
In questo articolo, impareremo come funziona una rete neurale di base e come si migliora per fare le migliori previsioni.
Sommario
- Reti neurali e loro componenti
- Perceptron e perceptron multistrato
- Lavoro passo passo della rete neurale
- Propagazione all'indietro e come funziona
- Breve sulle funzioni di attivazione
Reti neurali artificiali e loro componenti
Reti neurali è un sistema di apprendimento computazionale che utilizza una rete di funzioni per comprendere e tradurre un input di dati da un modo in un output desiderato, normalmente in un'altra forma. Il concetto di rete neurale artificiale è stato ispirato dalla biologia umana e dal modo in cui neuroni del cervello umano lavorano insieme per comprendere gli input dei sensi umani.
In parole semplici, le reti neurali sono un insieme di algoritmi che cercano di riconoscere schemi, relazioni di dati e informazioni attraverso il processo che è ispirato e funziona come il cervello / biologia umana.
Componenti (modifica) / Architettura di rete neurale
Una semplice rete neurale è composta da tre componenti :
- Livello di input
- Mantello nascosto
- Livello di output

Fonte: Wikipedia
Livello di input: Conosciuto anche come nodi di input, sono gli ingressi / informazioni dal mondo esterno fornite al modello per apprendere e trarre conclusioni. I nodi di input passano le informazioni al livello successivo, vale a dire, livello nascosto.
Mantello nascosto: Il livello nascosto è l'insieme di neuroni in cui vengono eseguiti tutti i calcoli sui dati di input. Ci può essere un numero qualsiasi di livelli nascosti in una rete neurale. La rete più semplice è costituita da un singolo livello nascosto.
Livello di output: Il livello di output è l'output / conclusioni del modello derivate da tutti i calcoli eseguiti. Potrebbero esserci uno o più nodi nel livello di output. Se abbiamo un problema di classificazione binaria, il nodo di output è 1, ma in caso di classificazione in più classi, i nodi di output possono essere più di 1.
Perceptron e perceptron multistrato
Perceptron è una semplice forma di rete neurale e consiste in un singolo strato in cui vengono eseguiti tutti i calcoli matematici.
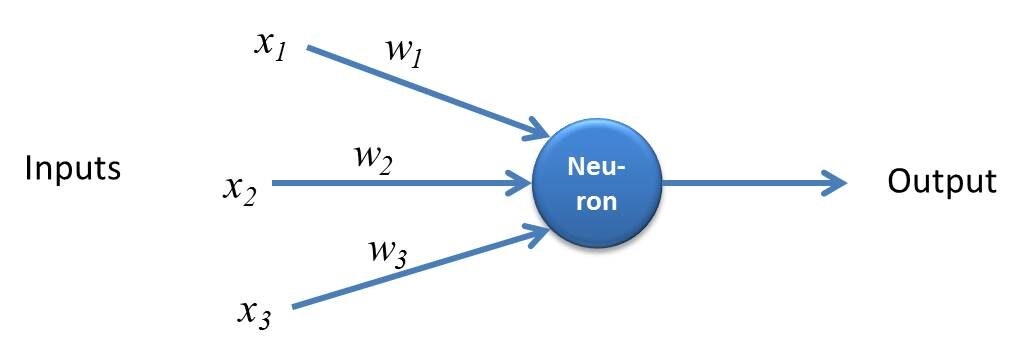
Fonte: kindsonthegenius.com
Mentre, Perceptron multistrato anche conosciuto come Reti neurali artificiali Consiste in più di una percezione che viene raggruppata per formare una rete neurale multistrato.
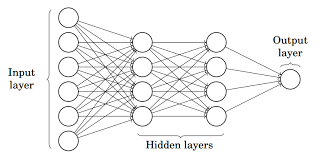
Fonte: Metà
Nella foto sopra, la rete neurale artificiale è costituita da quattro strati interconnessi:
- Un livello di input, insieme a 6 nodi di input.
- Copertura frontale 1 nascosto, insieme a 4 nodi nascosti / 4 percettroni
- Mantello nascosto 2, insieme a 4 nodi nascosti
- Livello di output con 1 nodo di uscita
Passo dopo passo Working de la red neuronal artificiale
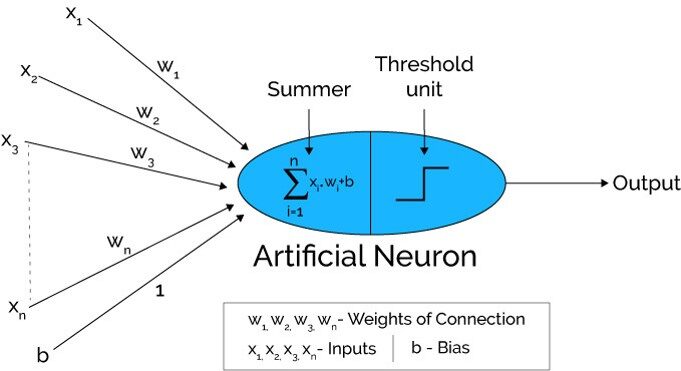
Fonte: Xenonstack.com
-
Nel primo passo Le unità di input sono passate, vale a dire, i dati vengono passati con alcuni pesi allegati al livello nascosto.. Possiamo avere un numero qualsiasi di livelli nascosti. Nella foto sopra, gli ingressi x1,X2,X3,….XNord è passato.
-
Ogni strato nascosto è costituito da neuroni. Tutti gli input sono collegati a ciascun neurone.
-
Dopo aver trasmesso i biglietti, tutti i calcoli vengono eseguiti nel livello nascosto (Ovale blu nella foto)
Il calcolo effettuato in strati nascosti viene effettuato in due fasi che sono le seguenti :
-
Primo, tutti gli input sono moltiplicati per i loro pesi. Il peso è il gradiente o coefficiente di ciascuna variabile. Mostra la forza del particolare input. Dopo aver assegnato i pesi, viene aggiunta una variabile di bias. Pregiudizio è una costante che aiuta il modello ad adattarsi nel miglior modo possibile.
INSIEME A1 = W1*Sopra1 + W2*Sopra2 + W3*Sopra3 + W4*Sopra4 + W5*Sopra5 + B
W1, W2, W3, W4, W5 sono i pesi assegnati agli ingressi In1, Sopra2, Sopra3, Sopra4, Sopra5, e b è il bias.
- Dopo, nel secondo passaggio, il La funzione di attivazione è applicata all'equazione lineare Z1. La funzione di attivazione è una trasformazione non lineare che viene applicata all'input prima di inviarlo allo strato successivo di neuroni. L'importanza della funzione di attivazione è quella di instillare non linearità nel modello.
Ci sono varie funzioni di attivazione che verranno elencate nella prossima sezione.
-
L'intero processo descritto al punto 3 eseguito su ogni livello nascosto. Dopo aver attraversato ogni livello nascosto, andiamo all'ultimo strato, vale a dire, il nostro livello di output che ci dà l'output finale.
Il processo spiegato sopra è noto come propagazione in avanti.
-
Dopo aver ottenuto le previsioni dal livello di output, l'errore è calcolato, vale a dire, la differenza tra la produzione effettiva e quella attesa.
Se l'errore è grande, quindi vengono prese misure per ridurre al minimo l'errore e per lo stesso scopo, Viene eseguita la propagazione all'indietro.
Cos'è la propagazione all'indietro e come funziona?
La propagazione inversa è il processo di aggiornamento e ricerca dei valori ottimali di pesi o coefficienti che aiuta il modello a ridurre al minimo l'errore, vale a dire, la differenza tra i valori effettivi e quelli previsti.
Ma ecco la domanda: Come vengono aggiornati i pesi e calcolati i nuovi pesi??
I pesi vengono aggiornati con l'aiuto di ottimizzatori.. Gli ottimizzatori sono i metodi / formulazioni matematiche per modificare gli attributi delle reti neurali, vale a dire, i pesi per minimizzare l'errore.
Propagazione all'indietro inclinata verso il basso
Gradient Descent è uno degli ottimizzatori che aiuta a calcolare i nuovi pesi. Capiamo passo dopo passo come Gradient Descent ottimizza la funzione di costo.
Nell'immagine qui sotto, la curva è la nostra curva della funzione di costo e il nostro obiettivo è minimizzare l'errore tale che Jmin vale a dire, vengono raggiunti i minimi globali.
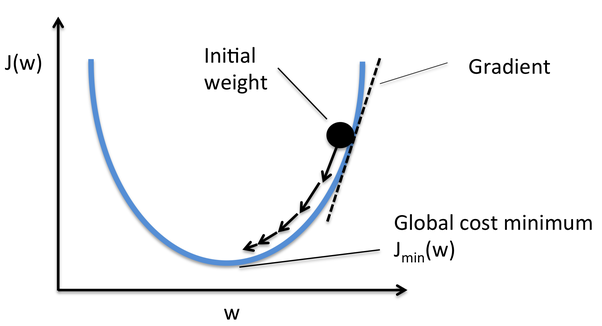
Fonte: Quora
Passi per raggiungere i minimi globali:
-
Primo, i pesi sono inizializzati casualmente vale a dire, il valore casuale del peso e le intersezioni sono assegnati al modello mentre la propagazione in avanti e gli errori sono calcolati dopo tutto il calcolo. (Come discusso sopra)
-
Così lui il gradiente è calcolato, vale a dire, derivato da errore con pesi correnti
-
Dopo, i nuovi pesi sono calcolati utilizzando la seguente formula, dove a è il tasso di apprendimento che è il parametro noto anche come dimensione del passo per controllare la velocità o i passaggi della propagazione all'indietro. Fornisce un controllo aggiuntivo sulla velocità con cui vogliamo muoverci lungo la curva per raggiungere i minimi globali.
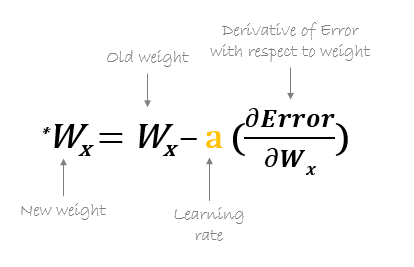
Fonte: hmkcode.com
4.Questo processo di calcolo dei nuovi pesi, poi gli errori dei nuovi pesi e poi l'aggiornamento dei pesi. continua fino a quando non raggiungiamo i minimi globali e la perdita è ridotta al minimo.
Un punto da tenere a mente qui è che il tasso di apprendimento, vale a dire, a nel nostro aggiornamento del peso L'equazione deve essere scelta con saggezza. Il tasso di apprendimento è la quantità di cambiamento o la dimensione del passo compiuto per raggiungere i minimi globali. Non dovrebbe essere troppo piccolo poiché ci vorrà del tempo per convergere, così come non dovrebbe essere troppo grande che non raggiunge affatto i minimi globali. Perciò, il tasso di apprendimento è l'iperparametro che dobbiamo scegliere in base al modello.
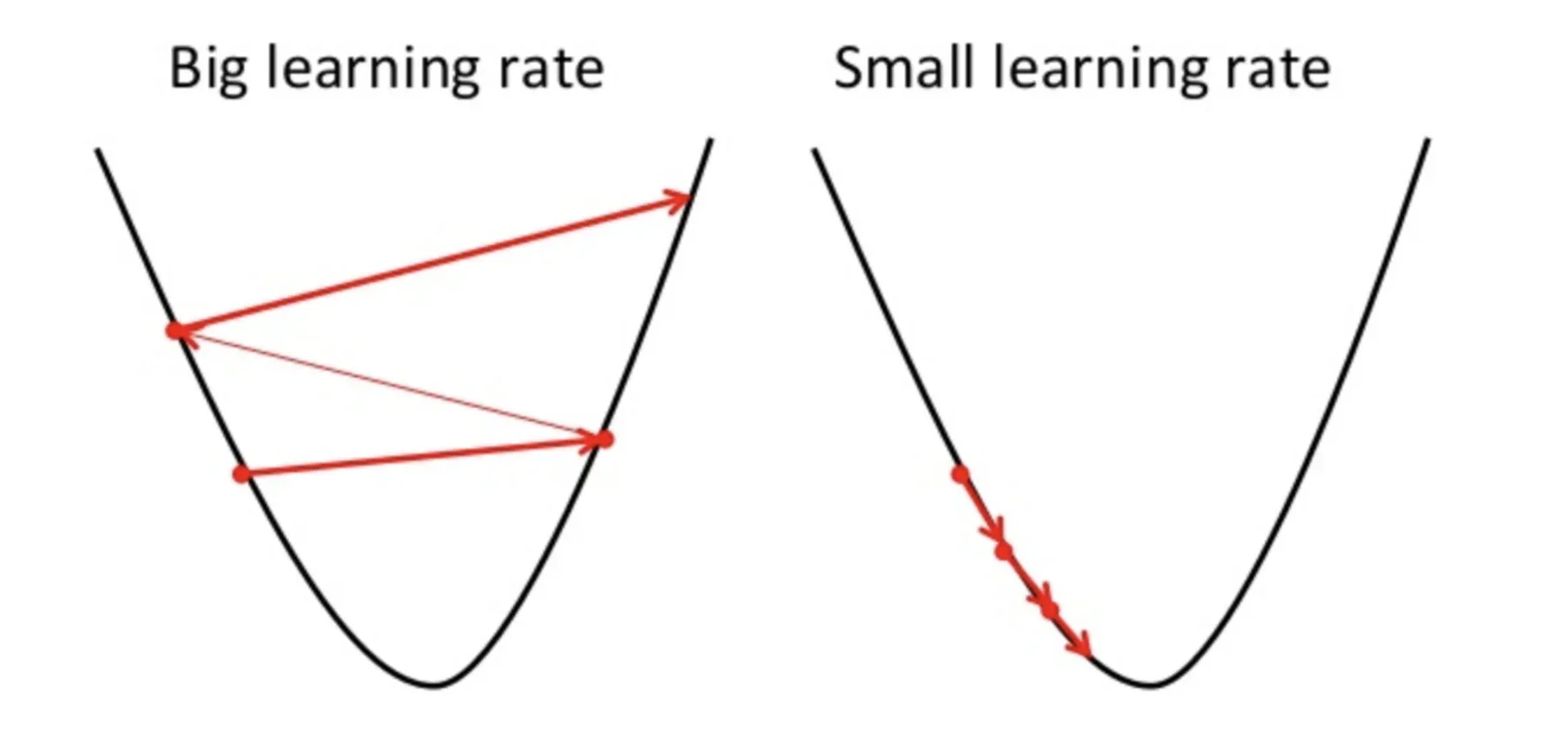
Fonte: Educativo.io
Per conoscere la matematica dettagliata e la regola della catena di retropropagazione, vedi allegato tutorial.
Breve sulle funzioni di attivazione
Funzioni trigger sono collegati a ciascun neurone e sono equazioni matematiche che determinano se un neurone dovrebbe attivarsi o meno in base al fatto che l'input del neurone sia rilevante o meno per la previsione del modello. Lo scopo della funzione di attivazione è introdurre non linearità nei dati.
Vari tipi di funzioni trigger sono:
- Funzione di attivazione sigmoide
- Funzione di attivazione TanH / tangente iperbolica
- Funzione unità lineare rettificata (riprendere)
- ReLU . che perde
- Softmax
Dai un'occhiata a questo blog per una spiegazione dettagliata delle funzioni di attivazione.
Note finali
Qui concludo la mia spiegazione passo passo della prima rete neurale di Deep Learning che è ANA. Ho cercato di spiegare il processo di Propagation Forwarding e Backpropagation nel modo più semplice possibile. Spero che valga la pena leggere questo articolo 🙂
Per favore, sentiti libero di connetterti con me su LinkedIn e condividi il tuo prezioso contributo. Per favore, dai un'occhiata agli altri miei articoli qui.
Circa l'autore
Soy Deepanshi Dhingra, Attualmente lavoro come ricercatore di data science e ho un background in analisi, analisi esplorativa dei dati, machine learning e deep learning.
Il supporto mostrato in questo articolo sulla rete neurale artificiale non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





