introduzione
Per qualche ragione, problemi di regressione e classificazione finiscono per catturare la maggior parte dell'attenzione nel mondo del machine learning. Le persone non si rendono conto dell'ampia varietà di problemi di apprendimento automatico che possono esistere.
Per me, In secondo luogo, Amo esplorare diversi tipi di problemi e condividere il mio apprendimento con la comunità qui.
In precedenza, condiviso le mie conoscenze sugli algoritmi genetici con la comunità. Continuando con la mia ricerca, Intendo trattare un argomento che ha un problema molto meno diffuso ma è un problema persistente nella comunità della scienza dei dati, qual è la classificazione di più tag?.
In questo articolo, Ti darò una spiegazione intuitiva di cosa comporta l'ordinamento multi-tag, insieme a un'illustrazione di come risolvere il problema. Spero che ti mostri l'orizzonte di ciò che la scienza dei dati comprende. Quindi andiamo avanti!
Sommario
- Che cos'è l'ordinamento multi-tag??
- Multiclasse v / s Multi-etichetta
- Caricamento e generazione di set di dati di etichette multiple
- Tecniche per risolvere un problema di classificazione di più etichette
- Metodo di trasformazione del problema
- Metodo dell'algoritmo adattato
- L'ensemble si avvicina
- Casi studio
1. Che cos'è l'ordinamento multi-tag??
Diamo un'occhiata all'immagine qui sotto.

E se ti chiedessi se questa immagine contiene una casa?? L'opzione sarà SÌ oh NO.
Considera un altro caso, come tutte le cose (o etichette) sono rilevanti per questa immagine.

Questo tipo di problemi, dove abbiamo un insieme di variabili target, sono conosciuti come classificazione di tag multipli i problemi. Quindi, C'è differenza tra questi due casi?? Chiaramente, sì, perché nel secondo caso qualsiasi immagine può contenere un diverso insieme di questi tag multipli per immagini diverse.
Ma prima di approfondire i tag multipli, Volevo solo chiarire una cosa, poiché molti di voi potrebbero essere confusi su come questo differisca dal problema delle classi multiple.
Quindi, cerchiamo di capire la differenza tra queste due serie di problemi.
2. Multi-etichetta v / s multi-classe
Considera un esempio per capire la differenza tra questi due. Per questo, Spero che l'immagine qui sotto renda le cose abbastanza chiare. Cerchiamo di capirlo.
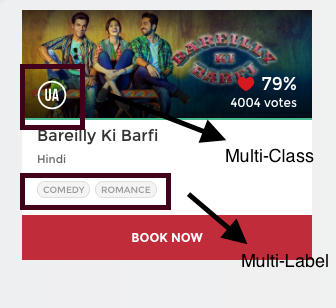
Per qualsiasi film, il Central Film Certification Board, rilascia un certificato in base al contenuto del film.
Ad esempio, se guardi in alto, questo film è stato valutato come 'U / UN’ (che significa "sorveglianza dei genitori per i bambini di età inferiore a" 12 anni’) certificato. Esistono altri tipi di classi di certificati come 'UN’ (Riservato agli adulti) oh 'U’ (Visualizzazione pubblica illimitata), ma è certo che ogni film può essere classificato solo con uno solo di questi tre tipi di certificati.
In sintesi, ci sono più categorie ma a ogni istanza ne viene assegnata una sola, così, questi problemi sono noti come classificazione multiclasse guaio.
Ancora, se guardi indietro alla foto, questo film è stato classificato nel genere della commedia e del romanticismo. Ma c'è una differenza nel fatto che questa volta ogni film potrebbe rientrare in uno o più set di categorie differenti.
Perciò, ogni istanza può essere assegnata a più categorie, ecco perché questi tipi di problemi sono noti come classificazione di tag multipli guaio, dove abbiamo una serie di etichette di destinazione.
Eccellente! Ora puoi distinguere tra un problema multi-etichetta e multi-classe. Quindi, iniziamo ad affrontare questo tipo di problemi.
3. Caricamento e generazione di set di dati di etichette multiple
Scikit-learn ha fornito una libreria separata scikit-multilearn per l'ordinamento di più tag.
Per una migliore comprensione, iniziamo a fare pratica con un set di dati multi-etichetta. Puoi trovare un set di dati del mondo reale nel deposito fornito dal pacchetto MULAN. Questi set di dati sono presenti in formato ARFF.
Quindi, per iniziare con uno di questi set di dati, guarda il codice Python qui sotto per caricarlo nel tuo notebook jupyter. Qui ho scaricato il set di dati del lievito dal repository.
importa scipy
da scipy.io import arff
dati, meta = scipy.io.arff.loadarff('/Users/shubhamjain/Documents/yeast/yeast-train.arff')
df = pd.DataFrame(dati)
Ecco come appare il set di dati.
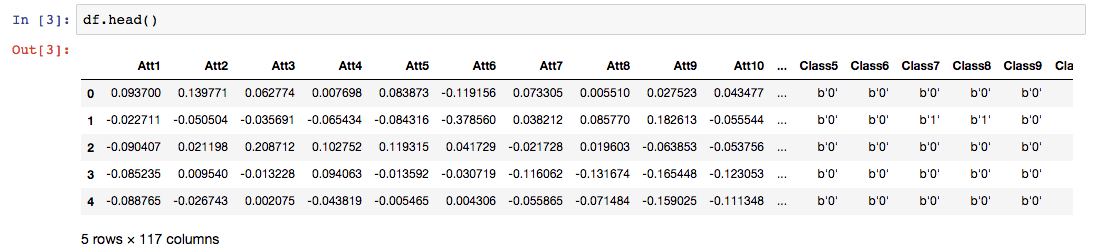
Qui, Per rappresenta gli attributi o variabili indipendenti e Classe rappresenta le variabili target.
Per scopi pratici, abbiamo un'altra opzione per generare un set di dati di tag multipli artificiali.
da sklearn.datasets import make_multilabel_classification # questo genererà un set di dati multi-etichetta casuale X, y = make_multilabel_classification(sparse = Vero, n_labels = 20, return_indicator="scarso", allow_unlabeled = False)
Comprendiamo i parametri usati sopra.
scarso: È vero, restituisce un array sparso, dove matrice sparsa indica una matrice che ha un gran numero di elementi nulli.
n_labels: Il numero medio di etichette in ogni istanza.
indicatore_ritorno: e "scarso"’ Ritorno E in formato indicatore binario sparse.
allow_unlaoted: e Certo, alcune istanze potrebbero non appartenere a nessuna classe.
Avrai notato che abbiamo usato ovunque una matrice sparsa, e scikit-multilearn consiglia inoltre di utilizzare i dati in modo sparso perché è molto raro che un set di dati del mondo reale sia denso. In genere, il numero di etichette assegnate a ciascuna istanza è molto inferiore.
Bene, ora abbiamo i nostri set di dati pronti, quindi impariamo rapidamente le tecniche per risolvere il problema multi-tag.
4. Tecniche per risolvere un problema di classificazione di più etichette
Fondamentalmente, ci sono tre metodi per risolvere un problema di classificazione di etichette multiple, vale a dire:
- Trasformazione del problema
- Algoritmo adattato
- L'ensemble si avvicina
4.1 Trasformazione del problema
In questo metodo, proveremo a trasformare il nostro problema con più etichette in un problema con una singola etichetta.
Questo metodo può essere fatto in tre modi diversi come:
- Rilevanza binaria
- catene di smistamento
- Etichetta Powerset
4.1.1 Rilevanza binaria
Questa è la tecnica più semplice, che fondamentalmente tratta ogni tag come un problema di classificazione di una singola classe separata.
Ad esempio, consideriamo un caso come mostrato di seguito. Abbiamo il set di dati in questo modo, dove X è la caratteristica indipendente e Y è la variabile target.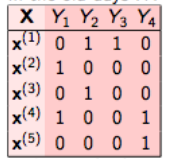
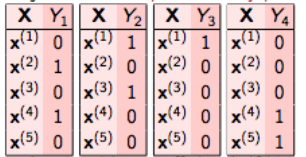
In rilevanza binaria, questo problema è diviso in 4 diversi problemi di classificazione di singole classi, come mostrato nella figura sottostante.
Non dobbiamo farlo manualmente, la libreria multi-learning fornisce la sua implementazione in Python. Quindi, vediamo rapidamente la sua implementazione nei dati generati casualmente.
# usando la rilevanza binaria da skmultilearn.problem_transform import BinaryRelevance da sklearn.naive_bayes import GaussianNB # inizializza il classificatore multi-etichetta di rilevanza binaria # con un classificatore di base gaussiano ingenuo classificatore = Rilevanza binaria(gaussianoNB()) # treno classificatore.fit(X_treno, y_train) # prevedere previsioni = classificatore.predizione(X_test)
NOTA: Qui, abbiamo usato l'algoritmo Naive Bayes, ma puoi usare qualsiasi altro algoritmo di ordinamento.
Ora, in un problema di classificazione di più tag, non possiamo semplicemente usare le nostre normali metriche per calcolare l'accuratezza delle nostre previsioni. Per quello scopo, noi useremo punteggio di precisione metrica. Questa funzione calcola la precisione del sottoinsieme, il che significa che l'insieme di etichette previsto deve corrispondere esattamente al vero insieme di etichette.
Quindi, calcoliamo la precisione delle previsioni.
da sklearn.metrics import precision_score precision_score(y_test,predizioni)
Perciò, abbiamo ottenuto un punteggio di precisione di 45%, non è poi così male. Vediamo rapidamente i suoi pro e contro.
È il metodo più semplice ed efficiente, pero el único inconveniente de este método es que no considera la correlación de etiquetas porque trata cada variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... de destino de forma independiente.
4.1.2 catene di smistamento
In questo, il primo classificatore viene addestrato solo sui dati di input e quindi ogni classificatore successivo viene addestrato sullo spazio di input e tutti i classificatori precedenti nella catena.
Cerchiamo di capirlo con un esempio. Nel set di dati mostrato di seguito, abbiamo X come spazio di input e Y come etichette.
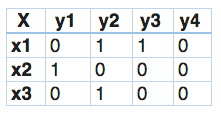
Nelle catene di classificatori, questo problema diventerebbe 4 diversi problemi di tag singolo, come mostrato di seguito. Qui il colore giallo è lo spazio di input e la parte bianca rappresenta la variabile di destinazione.

Questo è abbastanza simile alla rilevanza binaria, l'unica differenza è che forma stringhe per preservare la mappatura delle etichette. Quindi, proviamo a implementarlo usando la libreria multi-learning.
# usando catene di classificatori da skmultilearn.problem_transform import ClassifierChain da sklearn.naive_bayes import GaussianNB # inizializza le catene di classificatori classificatore multi-etichetta # con un classificatore di base gaussiano ingenuo classificatore = ClassificatoreCatena(gaussianoNB()) # treno classificatore.fit(X_treno, y_train) # prevedere previsioni = classificatore.predizione(X_test) precision_score(y_test,predizioni)
0.21212121212121213
Possiamo vedere che usando questo abbiamo ottenuto una precisione di circa 21%, che è molto meno del binario Rilevanza. Ciò potrebbe essere dovuto all'assenza di correlazione dei tag, poiché abbiamo generato i dati in modo casuale.
4.1.3 Etichetta Powerset
In questo, trasformiamo il problema in un problema multiclasse con un classificatore multiclasse addestrato su tutte le combinazioni di etichette univoche trovate nei dati di training.
Capiamo con un esempio.
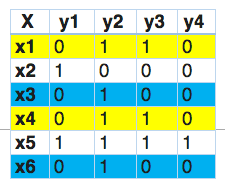
In questo, troviamo che x1 e x4 hanno le stesse etichette, allo stesso modo, x3 e x6 hanno lo stesso set di etichette. Perciò, il gruppo di alimentazione delle etichette trasforma questo problema in un unico problema multiclasse, come mostrato di seguito.
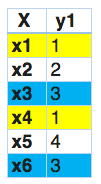
Perciò, label powerset ha assegnato una classe univoca a ogni possibile combinazione di etichette presente nel training set.
Vediamo la sua implementazione in Python.
# utilizzando Label Powerset da skmultilearn.problem_transform import LabelPowerset da sklearn.naive_bayes import GaussianNB # inizializza il classificatore multi-etichetta Label Powerset # con un classificatore di base gaussiano ingenuo classificatore = LabelPowerset(gaussianoNB()) # treno classificatore.fit(X_treno, y_train) # prevedere previsioni = classificatore.predizione(X_test) precision_score(y_test,predizioni)
0.5757575757575758
Questo ci dà la massima precisione tra i tre di cui abbiamo discusso finora.. L'unico aspetto negativo di questo è che con l'aumento dei dati di allenamento, aumentare il numero delle classi. Perciò, aumenta la complessità del modello e porterebbe a una minore precisione.
Ora, Diamo un'occhiata al secondo metodo per risolvere il problema della classificazione multi-etichetta.
4.2 Algoritmo adattato
Algoritmo adattato, Come suggerisce il nome, adattare l'algoritmo per eseguire direttamente la classificazione di più etichette, invece di trasformare il problema in diversi sottoinsiemi di problemi.
Ad esempio, la versione multi-tag di kNN è rappresentata da MLkNN. Quindi, implementiamolo rapidamente nel nostro set di dati generato casualmente.
da skmultilearn.adapt import MLkNN classificatore = MLkNN(k=20) # treno classificatore.fit(X_treno, y_train) # prevedere previsioni = classificatore.predizione(X_test) precision_score(y_test,predizioni)
0.69
Eccellente! Ha raggiunto un punteggio di precisione di 69% nei tuoi dati di prova.
Sci-kit learn fornisce un supporto per la classificazione multi-tag integrato in alcuni algoritmi come Random Forest e Ridge regression. Perciò, può chiamarli direttamente e prevedere l'output.
Puoi controllare il libreria di apprendimento multiplo per maggiori informazioni su altri tipi di algoritmi personalizzati.
4.3 L'ensemble si avvicina
Ensemble produce sempre risultati migliori. La libreria Scikit-Multilearn fornisce diverse funzioni di classificazione degli insiemi, che puoi usare per ottenere i migliori risultati.
Per l'attuazione diretta, puoi consultare qui.
5. Casi studio
I problemi di classificazione di più tag sono molto comuni nel mondo reale. Quindi, diamo un'occhiata ad alcune delle aree in cui possiamo trovarne l'uso.
1. Classificazione audio
Abbiamo già visto canzoni classificate in diversi generi. Sono anche classificati sulla base di emozioni o stati d'animo come “calma rilassante”, “tristezza-solitudine”, eccetera.
Fonte: Collegamento
2. Classificazione delle immagini
Anche l'ordinamento di più etichette utilizzando le immagini ha una vasta gamma di applicazioni. Le immagini possono essere etichettate per indicare oggetti diversi, persone o concetti.

3. Bioinformatica
La classificazione di etichette multiple è ampiamente utilizzata nel campo della bioinformatica, ad esempio, la classificazione dei geni nel dataset del lievito.
Viene anche utilizzato per prevedere più funzioni proteiche utilizzando varie proteine non etichettate.. Puoi controllare questo carta per maggiori informazioni.
4. Categorizzazione del testo
Tutti dovrebbero controllare le notizie di Google una volta. Quindi, ciò che fa Google News è taggare tutte le notizie in una o più categorie in modo che vengano visualizzate in categorie diverse. Ad esempio, Guarda la foto sotto.
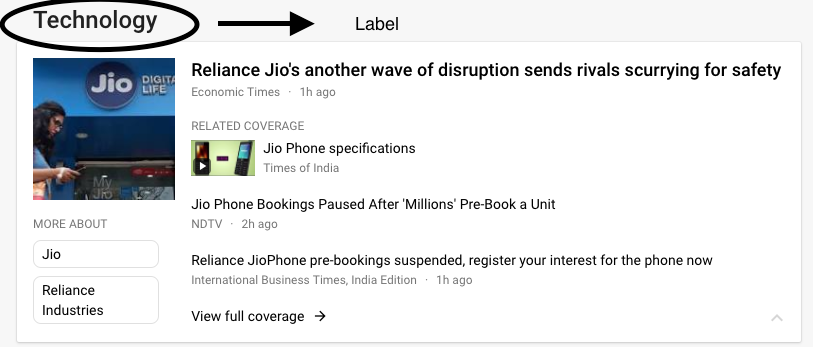
Fonte immagine: Google News
Quella stessa notizia è presente nelle categorie dell'India, Tecnologia, Più recente, eccetera. perché è stato classificato in queste diverse etichette. Perciò, è un problema di classificazione di più tag.
Ci sono molte altre aree, quindi esplora e commenta qui sotto se vuoi condividerlo con la community.
6. Note finali
In questo articolo, ti ha introdotto al concetto di più problemi di classificazione dei tag. Ho anche trattato gli approcci per risolvere questo problema e casi d'uso pratici in cui potrebbe essere necessario gestirlo utilizzando la libreria multi-learning in Python.
Spero che questo articolo ti dia un vantaggio quando ti trovi di fronte a questo tipo di problemi. Se hai dei dubbi / suggerimento, Sentiti libero di contattarmi qui sotto!





