Tabelle dinamiche: il coltellino svizzero dell'analisi dei dati
Adoro la velocità con cui posso analizzare i dati utilizzando le tabelle pivot. Con un clic del mio mouse, Posso approfondire i dettagli granulari su una determinata categoria di prodotti, o rimpicciolisci e ottieni una panoramica di alto livello dei dati disponibili.
Le tabelle pivot mi offrono molta flessibilità come data scientist. sarò onesto: Mi affido molto a loro durante la fase di analisi esplorativa dei dati di un progetto di data science.
Gli utenti di Excel conosceranno intimamente queste tabelle pivot. Sono la funzionalità più utilizzata di Excel, Ed è facile capire perché! Ma sapevi che puoi costruire queste tabelle pivot usando Pandas in Python??

Giusto! La meravigliosa libreria Pandas offre una funzione chiamata pivot_table che riassume i valori di una caratteristica in una tabella bidimensionale ordinata.. Vedremo come costruire un tabella dinamicaLa tabella pivot è un potente strumento nei programmi per fogli di calcolo, come Microsoft Excel e Fogli Google. Permette di riassumere, Analizza e visualizza grandi volumi di dati in modo efficiente. Attraverso la sua interfaccia intuitiva, Gli utenti possono riorganizzare le informazioni, Applica filtri e crea report personalizzati, facilitare un processo decisionale informato in vari contesti, Dal campo dell'impresa alla ricerca accademica.... di questo tipo in Python qui.
crema, molto presto utilizzerai queste tabelle pivot nei tuoi progetti. Nota che questo tutorial presuppone una conoscenza di base di Panda e Python. Se sei nuovo su questi argomenti, puoi ritirarli nei corsi gratuiti qui sotto:
Sommario
- Esplorare il set di dati del Titanic con Pandas in Python
- Costruisci una tabella pivot usando Pandas
- Come raggruppare i dati utilizzando il pulsante indiceIl "Indice" È uno strumento fondamentale nei libri e nei documenti, che consente di individuare rapidamente le informazioni desiderate. In genere, Viene presentato all'inizio di un'opera e organizza i contenuti in modo gerarchico, compresi capitoli e sezioni. La sua corretta preparazione facilita la navigazione e migliora la comprensione del materiale, rendendolo una risorsa essenziale sia per gli studenti che per i professionisti in vari settori.... nella tabella pivot?
- Come eseguire un pivot con un indice multiplo?
- Funzione di aggregazione diversa per caratteristiche diverse.
- Aggiungi funzionalità specifiche con parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... di valori
- Trova la relazione tra le caratteristiche con il parametro delle colonne
- Gestione dei dati mancanti
Esplorare il set di dati del Titanic usando Pandas in Python
Sono sicuro che ti sei imbattuto nel set di dati del Titanic nel tuo viaggio nella scienza dei dati. È uno dei primi set di dati che raccogliamo quando siamo pronti per esplorare un progetto.. Lo userò per mostrarti l'efficacia di tabella dinamica funzione.
Importiamo le librerie rilevanti:
importa panda come pd
importa numpy come np
importa matplotlib.pyplot come plt
plt.style.use('ggplot')
Per tutti coloro che hanno dimenticato come appare il set di dati del Titanic, Vi presento il dataset!
df = pd.read_csv('drive/My Drive/AV/train.csv')
df.head()

Lascerò alcune funzioni per facilitare l'analisi dei dati e dimostrare le capacità del tabella dinamica funzione:
df.drop(['ID passeggero','Biglietto','Nome'],inplace=Vero,asse=1)
È ora di costruire una tabella pivot in Python usando la fantastica libreria Pandas!! Esploreremo le diverse sfaccettature di una tabella pivot in questo articolo e creeremo da zero una tabella pivot straordinaria e flessibile.
Come raggruppare i dati utilizzando l'indice su una tabella pivot?
- tabella dinamica richiede un dati e un indice parametro
- dati è il frame di dati di Pandas che passa alla funzione
- indice è la funzione che ti permette di raggruppare i tuoi dati. La funzione indice apparirà come indice nella tabella risultante.
userò il 'Sesso’ colonna come la indice per adesso:
#a single index
table = pd.pivot_table(dati=df,indice=['Sesso'])
tavolo

Possiamo confrontare istantaneamente tutti i valori caratteristici per entrambi i sessi. Ora, visualizziamo il ritrovamento:

Bene, i passeggeri di sesso femminile hanno pagato molto di più per i biglietti rispetto agli uomini.
Puoi ottenere maggiori informazioni su come visualizzare i tuoi dati qui.
Come eseguire un pivot con un indice multiplo?
Puoi anche utilizzare più di una funzione come indice per raggruppare i tuoi dati. Ciò aumenta il livello di granularità nella tabella risultante e puoi essere più specifico con i tuoi risultati:
#multiple indexes
table = pd.pivot_table(df,indice=['Sesso','classe'])
tavolo

L'utilizzo di più indici nel set di dati ci consente di concordare sul fatto che la disparità nella tariffa del biglietto per donna e maschile passeggeri era valido in tutto Pclass sul titanico.
Funzione di aggregazione diversa per caratteristiche diverse.
I valori riportati in tabella sono il risultato della sintesi che aggressiva si applica ai dati di funzione. aggressiva Tipi di database Funzione aggiuntaLa funzione aggregata è un concetto chiave in economia che rappresenta la relazione tra la produzione totale di beni e servizi in un'economia e il livello dei prezzi. Questa funzione aiuta a capire come variano la domanda e l'offerta aggregate in risposta ai cambiamenti di fattori come la politica fiscale e monetaria. La sua analisi è essenziale per la formulazione di strategie economiche e la previsione dei cicli economici.... Quello tabella dinamica si applica ai tuoi dati raggruppati.
Predefinito, è np.significa (), Ma puoi anche utilizzare diverse funzioni aggiuntive per diverse funzionalità!! Fornisci semplicemente un dizionario come input per il aggressiva parametro con il nome della funzione come chiave e la funzione aggregata corrispondente come valore.
userò np.significa () Per lui 'Età’ caratteristico e np.sum () Per lui 'Sopravvissuto’ caratteristica:
#different aggregate functions
table = pd.pivot_table(df,indice=['Sesso','classe'],aggfunc={'Età':np.significa,'Sopravvissuto':np.sum})
tavolo

La tabella risultante ha più senso quando si utilizzano funzioni di aggregazione diverse per caratteristiche diverse.
Aggiungi caratteristiche specifiche con parametri di valore
Ma, Cosa stai aggiungendo? Puoi dire a Panda le caratteristiche su cui applicare la funzione di aggregazione, a valore parametro.
valore Il parametro è dove dice alla funzione a quali funzionalità aggiungere. È un campo facoltativo e se non specifichi questo valore, la funzione aggiungerà tutte le caratteristiche numeriche dal set di dati:
tabella = pd.pivot_table(df,indice=['Sesso','classe'],valori=['Sopravvissuto'], aggfunc=np.mean) tavolo
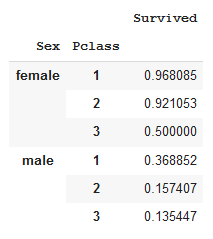
tabella.trama(tipo='bar');
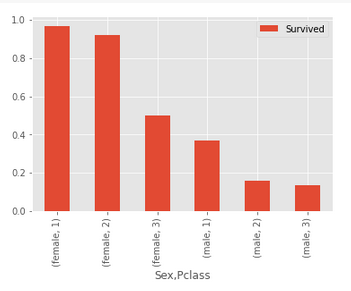
Il tasso di sopravvivenza dei passeggeri a bordo del Titanic è diminuito con una degradante classe P tra entrambi i sessi. Cosa c'è di più, il tasso di sopravvivenza dei passeggeri di sesso maschile era inferiore a quello delle donne in una data classe P.
Trova la relazione tra le caratteristiche con il parametro delle colonne
Usare più funzioni come indici va bene, ma usare alcune funzioni come colonne ti aiuterà a capire intuitivamente la relazione tra di loro. Cosa c'è di più, la tabella risultante può sempre essere visualizzata meglio incorporando il colonne parametro di tabella dinamica.
Questo colonne Il parametro è facoltativo e visualizza i valori orizzontalmente nella parte superiore della tabella risultante.
Entrambi colonne e il indice I parametri sono facoltativi, ma il suo uso efficace ti aiuterà a capire intuitivamente la relazione tra le funzioni.
#columns
table = pd.pivot_table(df,indice=['Sesso'],colonne=['classe'],valori=['Sopravvissuto'],aggfunc=np.sum)
tavolo

Usando Pclass poiché una colonna è più facile da capire che usarla come indice:
tabella.trama(tipo='bar');
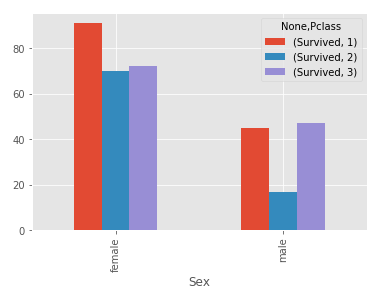
tabella dinamica ti permette anche di gestire i valori mancanti attraverso i parametri gocciolare e fill_value:
- gocciolare consente di rimuovere i valori null nella tabella cluster i cui valori sono null
- fill_value Il parametro può essere utilizzato per sostituire i valori NaN nella tabella cluster con i valori forniti qui.
#visualizza valori nulli tabella = pd.pivot_table(df,indice=['Sesso','Sopravvissuto','classe'],colonne=["Imbarcato"],valori=['Età'],aggfunc=np.mean) tavolo

Sostituirò i valori NaN con il valore medio del 'Età’ colonna:
#handling null values
table = pd.pivot_table(df,indice=['Sesso','Sopravvissuto','classe'],colonne=["Imbarcato"],valori=['Età'],aggfunc=np.mean,fill_value=np.mean(df['Età']))
tavolo

In questo articolo, esploriamo i diversi parametri dell'incredibile tabella dinamica funzione e come ti permette di riassumere facilmente le caratteristiche nel tuo set di dati attraverso una singola riga di codice.
Se non conosci la programmazione Python e vuoi saperne di più sull'analisi dei dati con Python, Ti consiglio di esplorare il nostro Python per la scienza dei dati e Panda per l'analisi dei dati in Python corsi.





