introduzione
Soprattutto le librerie Python per la scienza dei dati, i modelli di machine learning sono molto interessanti, facile da capire e assolutamente si può applicare subito e si può sentire le informazioni dai dati e realizzare / visualizzare la natura del set di dati.
Anche algoritmi complessi possono essere implementati in due o tre righe di codice., tutti i principali concetti matematici sono incorporati all'interno di pacchetti per il punto di vista dell'implementazione.
Certo, questo è qualcosa di diverso e interessante rispetto ad altre librerie di programmazione che ho visto finora., questo è il motivo principale per cui Python svolge un ruolo vitale nello spazio AI con questa semplicità e robustezza!! Credo di sì! Ho notato, Ho capito a fondo e mi è piaciuto.
Cos'è un pacchetto in Python? UN pacchetto è una collezione di Chiodo moduli e assiemi in un unico pacchetto. Una volta importata nelle celle del blocco appunti, È possibile iniziare a utilizzare le classi, metodi, attributi, eccetera., ma prima, È necessario utilizzare il pacchetto e importarlo nel file / pacchetto.
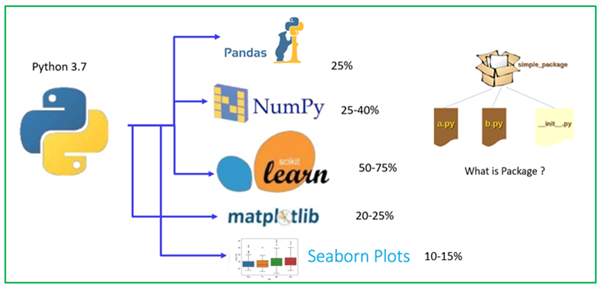
Discutiamo i pacchetti chiave in Python per la scienza dei dati e l'apprendimento automatico.
- panda
- NumPy
- Impara Scikit
- Matplotlib
- Seaborn
panda

Utilizzato principalmente per operazioni e manipolazioni di dati strutturati. Pandas offre potenti capacità di elaborazione dei dati, Non ho mai visto funzionalità così meravigliose nel mio viaggio IT. Fornisce prestazioni elevate, facile da usare e si applica nelle strutture di dati e per analizzare i dati.
Come installare la libreria Pandas? questo è molto semplice, Eseguire il seguente comando sul notebook Jupiter.
!pip installa panda
La libreria Pandas sarà installata correttamente!! Qual è il prossimo? gioca con questa libreria.
La sintassi per importare Scikit nel tuo NoteBook
importa panda come pd
Quindi, il tuo Notebook è pronto per estrarre tutte le funzioni all'interno dei panda. facciamo alcune cose qui.
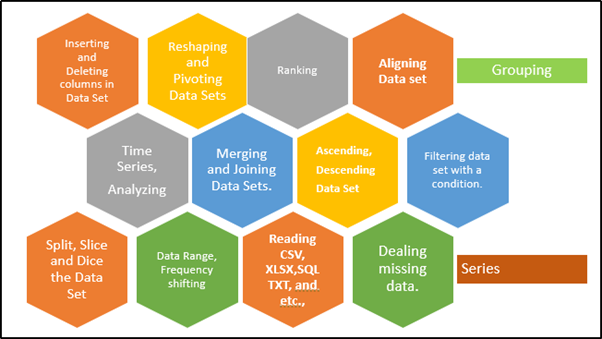
I panda hanno le seguenti funzionalità.
UN) Serie e DataFrame
I componenti principali dei panda sono Serie e Cornice dati. Diamo una rapida occhiata a questo. Series non è altro che un dizionario e una raccolta di serie, Potremmo costruire il framework di dati unendo le serie, Dare un'occhiata al seguente esempio. lo capiresti meglio.
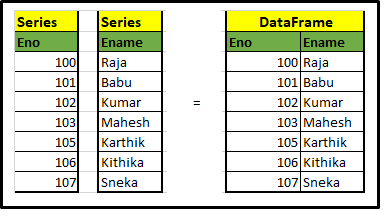
Il codice crea serie di dati e framework
import pandas as pd
Eno=[100, 101,102, 103, 104,105]
Empname= ['Raja', 'Babu', 'Kumar','Karthik','Rajesh','xxxxx']
Eno_Series = pd. Serie(Eno)
Empname_Series = pd. Serie(Nome Empname)
df = { 'Eno': Eno_Series, 'Empname': Empname_Series }
dipendente = pd. DataFrame(portafoto)
impiegato

B. Caricare i dati in un oggetto frame di dati
cereal_df = pd.read_csv("cereali.csv")
cereal_df.head(5)

C. Rilascia colonna dall'oggetto frame di dati
cereal_df.drop(["genere"], asse = 1, al posto = vero)
cereal_df.head(5)

D. Selezionare righe dall'oggetto frame di dati
cereal_df_filtered = cereal_df[cereal_df['valutazione'] >= 68] cereal_df_filtered.testa()
E. Raggruppa colonna nel frame di dati
cereal_df_groupby = cereal_df.groupby('scaffale')
#print the first entries
cereal_df_groupby.first()

F.Estrarre una riga dal frame di dati
# return the value
result = cereal_df.loc[0,'nome']
risultato
Fino ad ora, abbiamo discusso di più funzionalità nella libreria panda. Ce ne sono molti altri.
NumPy
NumPy è considerata una delle librerie di machine learning più popolari in Python, La caratteristica migliore e più importante di Numpy è l'interfaccia e le manipolazioni dell'array.
Hai paura della matematica durante l'implementazione del tuo modello di data science / apprendimento automatico? Non preoccuparti, NumPy rende le complesse implementazioni matematiche funzioni molto semplici. Ma ricorda di comprendere i requisiti e utilizzare il pacchetto di conseguenza.
La sintassi per importare NumPy nel NoteBook
importa numpy come np
Discutiamo alcune cose qui, come NumPy fa magia con dati dati dati.
UN. Semplice formazione di array con NumPy (1-D, 2-D e 3D)
import numpy as np #1-D arrays arr1 = np.array([1, 2, 3, 4, 5]) Stampa("1-Matrice D") Stampa(arr1) Stampa("===================") #2-D arrays print("2-Matrice D") arr2 = np.array([[1, 2, 3], [4, 5, 6]]) Stampa(arr2) Stampa("===================") #3-D arrays print("3-Matrice D") arr3 = np.array([[[1, 2, 3], [4, 5, 6]], [[1, 2, 3], [4, 5, 6]]]) Stampa(arr3) Stampa("===================")
Produzione
1-Matrice D [1 2 3 4 5] =================== 2-D Array [[1 2 3] [4 5 6]] =================== 3-D Array [[[1 2 3] [4 5 6]] [[1 2 3] [4 5 6]]] ===================
B. Array Slicing usando NumPy
#Slicing in python significa prendere elementi da un determinato intervallo di indici [cominciare:fine 1] /[cominciare:fine:fare un passo].
arr = np.array([1, 2, 3, 4, 5, 6, 7])
Stampa("Slicing all'indice 1 a 5")
Stampa(arr[1:5])
Produzione
Slicing all'indice 1 a 5 [2 3 4 5]
arr = np.array([1, 2, 3, 4, 5, 6, 7]) Stampa(arr[4:]) Produzione [5 6 7]
También tenemos Rebanado Negativo :). Eso es tan semplice, solo tenemos que mencionar [-X:-e],
¿Por qué no pruebas el tuyo propio?
C. Forma de matriz y remodelación usando NumPy
arr = np.array([[1, 2, 3, 4], [5, 6, 7, 8]])
Stampa("================================")
Stampa("Forma della matrice")
Stampa(arr.shape)
Stampa("================================")
Output
================================
Shape of the array
(2, 4)
================================
arr = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12])
Stampa("Prima di rimodellare l'array")
Stampa(arr)
Stampa("================================")
newarr = arr.reshape(4, 3)
Stampa("Dopo Rimodellare l'array")
Stampa(newarr)
Stampa("================================")
output
Before Reshape the array
[ 1 2 3 4 5 6 7 8 9 10 11 12]
================================
After Reshape the array
[[ 1 2 3]
[ 4 5 6]
[ 7 8 9]
[10 11 12]]
================================
D. Divisione a matrice con NumPy
arr = np.array([1, 2, 3, 4, 5, 6])
Stampa("Suddivisione delle matrici NumPy in 3 Matrici")
Stampa("================================")
newarr = np.array_split(arr, 3)
Stampa(newarr[0])
Stampa(newarr[1])
Stampa(newarr[2])
Stampa("================================")
output
Splitting NumPy Arrays into 3 Arrays
================================
[1 2]
[3 4]
[5 6]
Matrice di ordinamento elettronico con NumPy
arr = np.array(['Banana', 'ciliegia', 'Mela'])
Stampa("Suddivisione delle matrici NumPy in 3 Matrici")
Stampa("================================")
Stampa(np.sort(arr))
Stampa("================================")
output
Splitting NumPy Arrays into 3 Arrays
================================
['mela' 'banana' 'ciliegia']
================================
Se hai iniziato a giocare con i dati usando NumPy....
Certamente, ha bisogno di sempre più tempo … comprendere i concetti, tutti sono
estremamente organizzato in questo pacchetto. Credimi!
Impara Scikit

Scikit La libreria Learn è una delle librerie più ricche della famiglia Python, contiene un gran numero di algoritmi di machine learning e altre librerie chiave correlate alle prestazioni. Python Scikit-learn consente agli utenti di eseguire varie attività specifiche di machine learning. Al lavoro, deve funzionare insieme alle librerie SciPy e NumPy, questo è qualcosa di interno, in ogni caso, Tienilo a mente. Pochi algoritmi qui per le tue opinioni.
- Regressione
- Classificazione
- Raggruppamento
- Selezione del modello
- Riduzione della dimensionalità
La sintassi per importare Scikit nel tuo NoteBook
da sklearn.linear_model importare LinearRegression da sklearn.model_selection import train_test_split
Pacchetti di visualizzazione Python
Biblioteche Matplotlib e Seaborn

Python fornisce funzioni grafiche 2D con la libreria Matplotlib. questo è molto semplice e facile da capire. puoi ottenerlo con 1 oh 2 Linee. Anche la visualizzazione 3D è lì.
La sintassi per l'importazione di Scikit nel notebook
importa matplotlib.pyplot come plt import seaborn come sns
Spero che tu abbia lavorato su vari grafici in fogli di calcolo Excel e altri strumenti di BI. Ma in Python, I pacchetti di visualizzazione interni forniscono grafici e tabelle di altissima qualità.
Matplotlib e Seaborn
Matplotlib è uno dei pacchetti di visualizzazione principali e di base, che fornisce istogrammiGli istogrammi sono rappresentazioni grafiche che mostrano la distribuzione di un set di dati. Sono costruiti dividendo l'intervallo di valori in intervalli, oh "Bidoni", e il conteggio della quantità di dati che cadono in ogni intervallo. Questa visualizzazione consente di identificare i modelli, tendenze e variabilità dei dati in modo efficace, facilitare l'analisi statistica e il processo decisionale informato in varie discipline.... (Livello di frequenza), Istogramma (Grafici univariati e bivariati), Grafico a dispersioneUn grafico a dispersione è una rappresentazione visiva che mostra la relazione tra due variabili numeriche utilizzando punti su un piano cartesiano. Ogni asse rappresenta una variabile, e la posizione di ciascun punto indica il suo valore in relazione ad entrambi. Questo tipo di grafico è utile per identificare i modelli, Correlazioni e tendenze nei dati, facilitare l'analisi e l'interpretazione delle relazioni quantitative.... (Raggruppamento), eccetera.,
Ricca e lussuosa libreria di visualizzazione dei dati di Seaborn. Fornisce un'interfaccia di alto livello per disegnare grafici statistici interessanti e informativi. Diagrammi scatolariDiagrammi a scatola, Conosciuto anche come diagrammi a scatola e baffi, sono strumenti statistici che rappresentano la distribuzione di un dataset. Questi diagrammi mostrano la mediana, quartili e valori anomali, Consentire la visualizzazione della variabilità e della simmetria dei dati. Sono utili nel confronto tra diversi gruppi e nell'analisi esplorativa, Rendendo più facile identificare tendenze e modelli nei dati.... (Distribuzione dei dati con quartili diversi), Trame per violino (Distribuzione dei dati e Densità di probabilità), Grafici a barre (Confronti tra caratteristiche categoriche), Mappa di caloreun "mappa di calore" è una rappresentazione grafica che utilizza i colori per mostrare la densità dei dati in un'area specifica. Comunemente usato nell'analisi dei dati, Marketing e studi comportamentali, Questo tipo di visualizzazione consente di identificare rapidamente modelli e tendenze. Attraverso variazioni cromatiche, Le mappe di calore facilitano l'interpretazione di grandi volumi di informazioni, aiutando a prendere decisioni informate.... (Correlazione delle caratteristiche in termini di rappresentazione matriciale), nuvola di parole (Rappresentazione visiva dei dati di testo)
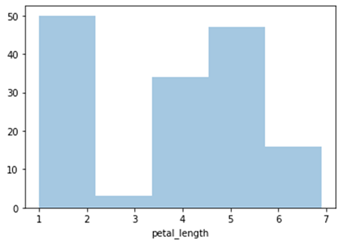
Seaborn – Istogramma
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.distplot(df['petal_length'],kde = Falso)
plt.mostra()
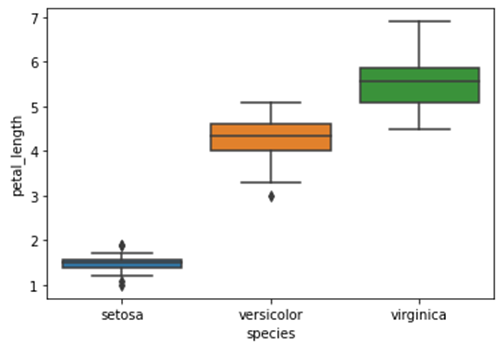
Seaborn – Trama scatola
df = sb.load_dataset('iris')
sb.boxplot(x = "specie", y = "petalo_lunghezza", dati = df)
plt.mostra()
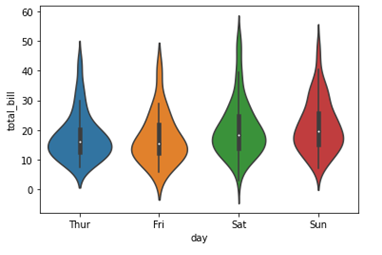
Seaborn – Violinplot
sdf = sb.load_dataset('suggerimenti')
sb.violinplot(x = "giorno", y = "total_bill", dati=df)
plt.mostra()
Quindi, tutte queste librerie ci stanno aiutando a costruire un buon modello e giocare con i dati!!
Ma ricorda sempre, prima dell'uso dei pacchetti industriali, È necessario comprendere la necessità e i requisiti del pacchetto e quindi importarlo nel file / pacchetto e giocare con quello.

Spero che ora tu abbia la sensazione e un certo livello di dettaglio sui pacchetti Python per la scienza dei dati. Vedremo concetti più dettagliati nei prossimi giorni! Grazie per il vostro tempo!
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





