Nell'articolo precedente, discutiamo dell'ecosistema Hadoop (collegamento). Abbiamo parlato anche dei due strumenti Hadoop più utilizzati, vale a dire, MAIALEIl maiale, un mammifero addomesticato della famiglia dei Suidi, È noto per la sua versatilità in agricoltura e nella produzione alimentare. Originario dell'Asia, Il suo allevamento si è diffuso in tutto il mondo. I maiali sono onnivori e hanno un'elevata capacità di adattarsi a vari habitat. Cosa c'è di più, svolgono un ruolo importante nell'economia, Fornitura di carne, cuoio e altri prodotti derivati. Anche la loro intelligenza e il loro comportamento sociale sono ... e ALVEAREHive è una piattaforma di social media decentralizzata che consente ai suoi utenti di condividere contenuti e connettersi con gli altri senza l'intervento di un'autorità centrale. Utilizza la tecnologia blockchain per garantire la sicurezza e la proprietà dei dati. A differenza di altri social network, Hive consente agli utenti di monetizzare i propri contenuti attraverso ricompense in criptovalute, che incoraggia la creazione e lo scambio attivo di informazioni..... Entrambe le lingue hanno i loro seguaci e non c'è una preferenza specifica tra le due, generalmente. tuttavia, nei casi in cui il team che utilizza questi strumenti è più orientato alla programmazione, a volte il MAIALE viene preferito all'HIVE, in quanto dà loro più libertà durante la codifica. Nei casi in cui il team non è molto esperto nella programmazione, L'HIVE è probabilmente un'opzione migliore, data la sua somiglianza con le query SQL. Le domande su PIG sono scritte in latino PIG. In questo articolo ti presenteremo il PIG Latin usando un semplice esempio pratico.
Installazione PIG
Il motore PIG gira sul server del client. È semplicemente un interprete che trasforma il tuo semplice codice in complesse operazioni di riduzione della mappa. è Riduci mappaMapReduce è un modello di programmazione progettato per elaborare e generare in modo efficiente set di dati di grandi dimensioni. Sviluppato da Google, Questo approccio suddivide il lavoro in attività più piccole, che sono distribuiti tra più nodi in un cluster. Ogni nodo elabora la sua parte e poi i risultati vengono combinati. Questo metodo consente di scalare le applicazioni e gestire enormi volumi di informazioni, essere fondamentali nel mondo dei Big Data.... ahora se maneja en la red distribuida de Hadoop. Nota che l'intera rete non saprà nemmeno che la query è stata eseguita da un motore PIG. PIG rimane solo nell'interfaccia utente e ha lo scopo di semplificare la codifica per l'utente.

Segui i passaggi seguenti nella tua shell per installare PIG:
Per installare sistemi compatibili con Pig On Red Hat:
$ sudo yum install pig
Per installare Pig sui sistemi SLES:
$ sudo zypper install pig
Per installare Pig su Ubuntu e altri sistemi Debian:
$ sudo apt-get install pig
Se stai pensando di eseguire Pig su Windows, dovresti semplicemente far funzionare una macchina virtuale su Linux e poi lavorarci sopra. Puoi usare VMWare Player o Oracle VirtualBox per avviarne uno.
Dopo aver installato il pacchetto PIG, puoi iniziare con la shell grunt.
Per avviare il Grunt Shell (MRv1):
$ export PIG_CONF_DIR=/usr/lib/pig/conf $ export PIG_CLASSPATH=/usr/lib/hbase/hbase-0.94.2-cdh4.2.1-security.jar:/usr/lib/ zookeeper"guardiano dello zoo" es un videojuego de simulación lanzado en 2001, donde los jugadores asumen el rol de un cuidador de zoológico. La misión principal consiste en gestionar y cuidar diversas especies de animales, asegurando su bienestar y la satisfacción de los visitantes. A lo largo del juego, los usuarios pueden diseñar y personalizar su zoológico, enfrentando desafíos que incluyen la alimentación, el hábitat y la salud de los animales..../zookeeper-3.4.5-cdh4.2.1.jar $ maiale 2012-02-08 23:39:41,819 [principale] INFO org.apache.pig.Main - Registrazione dei messaggi di errore su: /home/arvind/maiale-0.9.2-cdh4b1/bin/pig_1328773181817.log 2012-02-08 23:39:41,994 [principale] INFORMAZIONI org.apache.pig.backend.hadoop.executionengine.HexecutionEngine - Connessione al file system hadoop su: hdfsHDFS, o File system distribuito Hadoop, Si tratta di un'infrastruttura chiave per l'archiviazione di grandi volumi di dati. Progettato per funzionare su hardware comune, HDFS consente la distribuzione dei dati su più nodi, garantire un'elevata disponibilità e tolleranza ai guasti. La sua architettura si basa su un modello master-slave, dove un nodo master gestisce il sistema e i nodi slave memorizzano i dati, facilitare l'elaborazione efficiente delle informazioni..://host locale/ ... grugnito> Per avviare il Grunt Shell (FILATOYARN è un gestore di pacchetti per JavaScript che consente l'installazione e la gestione efficiente delle dipendenze nei progetti di sviluppo. Sviluppato da Facebook, Si caratterizza per la sua velocità e sicurezza rispetto ad altri gestori. YARN utilizza un sistema di cache per ottimizzare le installazioni e fornisce un file di blocco per garantire la coerenza delle versioni delle dipendenze tra i diversi ambienti di sviluppo....):
$ export PIG_CONF_DIR=/usr/lib/pig/conf
$ export PIG_CLASSPATH=/usr/lib/hbase/hbase-0.94.2-cdh4.2.1 -security.jar:/usr/lib/zookeeper/zookeeper-3.4.5-cdh4.2.1.jar
$ maiale ... grugnito>
una volta che vedo “ringhio>”, puoi iniziare a programmare in PIG.
Sfondo del caso
Sei il leader dell'analisi in un negozio al dettaglio chiamato XYZ. XYZ tiene un registro di tutti i clienti che fanno acquisti in questo negozio. Il tuo compito per questo esercizio è creare una nuova colonna chiamata IVA., che cosa è lui 5% della vendita. Dopo, filtra le persone per le quali l'importo dell'imposta è inferiore a $ 35. Una volta terminato questo sottoinsieme, scegli il 2 principali clienti con il minor numero di clienti. Di seguito è riportata una tabella di esempio per il negozio al dettaglio che viene salvata come .csv.
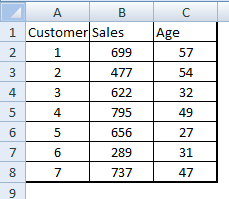
Scrivi una query in PIG Latin
Costruiamo questa query passo dopo passo. Di seguito sono riportati i passaggi che devi seguire:
passo 1 : Carica il set di dati nel formato comprensibile di PIG e archiviazione temporanea da cui la query PIG può fare riferimento direttamente alla tabella
Vendite = CARICA 'dataset.csv' UTILIZZANDO PigStorage (',') COME (Cliente,Saldi);
Tenga en cuenta que el comando anterior no carga la variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... età. Mentre si lavora con i Big Data, devi essere molto specifico sulle variabili che devi usare e, così, assicurati di scegliere solo quelle variabili che sono importanti per te nel tuo codice.
passo 2: crea una nuova tabella con i valori delle tasse.
Imposta = FOREACH Vendite GENERA Cliente,Saldi,Vendite*0.05 come imposta : galleggiante;
Il comando sopra genera una nuova tabella chiamata tasse che ha le tre colonne. La tabella sarà ora simile alla seguente:
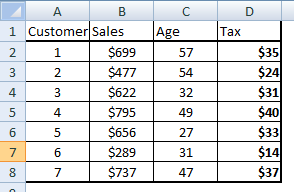 passo 3: Sottoimposta l'intera tabella sul cliente con un valore fiscale di seguito $ 35.
passo 3: Sottoimposta l'intera tabella sul cliente con un valore fiscale di seguito $ 35.
Lowtax = FILTRA Tasse PER Tasse < $35;
Il risultato di questo comando verrà visualizzato scegli le celle gialle nella tabella seguente:
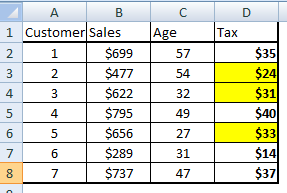 passo 4: Ora dobbiamo ordinare la tabella del sottoinsieme per Cliente (ID) e scegli i due Clienti principali.
passo 4: Ora dobbiamo ordinare la tabella del sottoinsieme per Cliente (ID) e scegli i due Clienti principali.
sortedcust = ORDER Lowtax BY Customer;
top_two = LIMIT sortedcust 2;
passo 5: memorizzare il file temporaneo in un file CSV permanente
MEMORIZZARE il cliente ordinato IN 'resoconto di vendita' USANDO PIGSTORAGE (',');
In questo passaggio, il nostro compito è completato e otterrai i numeri cliente richiesti con tutti i dettagli. Prossimo, viene mostrato il codice completo che può essere eseguito in una volta:
Vendite = CARICA 'dataset.csv' UTILIZZANDO PigStorage (',') COME (Cliente,Saldi);
Imposta = FOREACH Vendite GENERA Cliente,Saldi,Vendite*0.05 come imposta : galleggiante;
Lowtax = FILTRA Tasse PER Tasse < $35;
sortedcust = ORDER Lowtax BY Customer;
top_two = LIMIT sortedcust 2;
MEMORIZZARE il cliente ordinato IN 'resoconto di vendita' USANDO PIGSTORAGE (',');
Note finali
In questo articolo, abbiamo imparato a scrivere codice di base in PIG Latin. tuttavia, abbiamo limitato questo articolo a semplici istruzioni di filtraggio e ordinamento, parleremo anche di fusioni più complesse e altre dichiarazioni in alcuni dei prossimi articoli.
L'articolo ti è stato utile?? Condividi con noi tutte le applicazioni pratiche di PIG che hai trovato nel tuo lavoro. Fateci sapere i vostri pensieri su questo articolo nella casella sottostante..





