introduzione
Elaborazione del linguaggio naturale (PNL) è un'area di crescente attenzione a causa del numero crescente di applicazioni come i chatbot, traduzione automatica, eccetera. In qualche modo, L'intera rivoluzione delle macchine intelligenti si basa sulla capacità di comprendere e interagire con gli esseri umani.
Sto esplorando la PNL da un po' di tempo. Il mio viaggio è iniziato con la libreria NLTK in Python, quale era la libreria consigliata per iniziare in quel momento. NLTK è una libreria perfetta per l'istruzione e la ricerca, diventa molto pesante e noioso per completare anche i compiti più semplici.
Dopo, Mi è stato presentato TextBlob, che si basa su NLTK e Pattern. Un grande vantaggio di questo è che è facile da imparare e offre molte funzionalità come l'analisi del sentiment., etichettatura POS, estrazione di frasi nominali, eccetera. Ora è diventata la mia libreria di riferimento per eseguire attività di PNL.
In una nota al margineMargine è un termine usato in una varietà di contesti, come la contabilità, Economia e stampa. In contabilità, si riferisce alla differenza tra ricavi e costi, che permette di valutare la redditività di un'impresa. Nel campo dell'editoria, Il margine è lo spazio bianco intorno al testo di una pagina, che lo rende facile da leggere e fornisce una presentazione estetica. La sua corretta gestione è fondamentale.., C'è spazio, che è ampiamente riconosciuto come una delle librerie potenti e avanzate utilizzate per implementare le attività NLP. Ma avendo trovato sia spacy che TextBlob, Suggerirei comunque TextBlob a un principiante a causa della sua semplice interfaccia.
Se è il tuo primo passo nella PNL, TextBlob è la libreria perfetta per esercitarti. Il modo migliore per leggere questo articolo è seguire il codice e svolgere i compiti da soli. Allora cominciamo!
Nota : Questo articolo non descrive in modo approfondito le attività di PNL. Se vuoi rivedere le basi e tornare qui, puoi sempre leggere questo articolo.
Sommario
- Informazioni su TextBlob?
- Configura il sistema
- Prova le attività di PNL con TextBlob
- Tokenizzazione
- Estrazione di frasi nominali
- Etichettatura POS
- Flessione e derivazione delle parole
- N-grammi
- Analisi del sentimento
- Altre cose interessanti da fare con TextBlob
- Correzione ortografica
- Crea un breve riassunto di un testo
- Traduzione e rilevamento della lingua
- Classificazione del testo utilizzando TextBlob
- Pro e contro
- Note finali
1. Informazioni su TextBlob?
TextBlob è una libreria Python e offre una semplice API per accedere ai suoi metodi ed eseguire attività NLP di base.
La cosa bella di TextBlob è che sono come stringhe di pitone. Quindi, puoi trasformarlo e giocarci come abbiamo fatto in Python. Prossimo, Ti ho mostrato di seguito alcune attività di base. Non preoccuparti della sintassi, è solo per darti un'idea di quanto il TextBlob sia correlato alle stringhe Python.
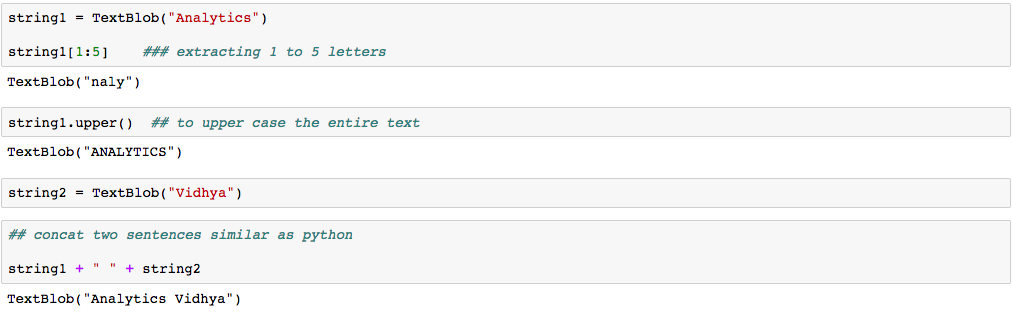 Quindi, per fare queste cose da solo, installiamo rapidamente e iniziamo a programmare.
Quindi, per fare queste cose da solo, installiamo rapidamente e iniziamo a programmare.
2. Configurazione di sistema
Installazione di TextBlob sul tuo sistema in una semplice operazione, tutto ciò che devi fare è aprire l'indicatore anaconda (il terminale stesso usa Mac OS o Ubuntu) e inserisci i seguenti comandi:
pip install -U textblob
Questo installerà TextBlob. Per chi non lo sapesse: il lavoro pratico nell'elaborazione del linguaggio naturale generalmente utilizza grandi quantità di dati linguistici, oh corpora. Per scaricare il corpus necessario, puoi eseguire il seguente comando
python -m textblob.download_corpora
3. Attività PNL con TextBlob
3.1 Tokenizzazione
La tokenizzazione si riferisce alla divisione del testo o di una frase in una sequenza di token, che all'incirca corrispondono a “parole”. Questo è uno dei compiti fondamentali della PNL. Per farlo usando TextBlob, segui i due passaggi:
- Creare un blob di testo oggetto e passare una corda con esso.
- Lama funzioni di textblob per eseguire un compito specifico.
Quindi, creiamo rapidamente un oggetto textblob da riprodurre.
da textblob import TextBlob
blob = TextBlob("DataPeaker è un'ottima piattaforma per imparare la scienza dei dati. n Aiuta la comunità attraverso i blog, hackathon, discussioni,eccetera.")
Ora, questo blocco di testo può essere convertito in una frase e poi in parole. Vediamo il codice mostrato di seguito.
3.2 Estrazione di frasi nominali
Come abbiamo estratto le parole nella sezione precedente, Invece, possiamo semplicemente estrarre le frasi nominali dal blocco di testo. L'estrazione delle frasi nominali è particolarmente importante quando si vuole analizzare il “chi” in una frase. Vediamo un esempio qui sotto.
blob = TextBlob("DataPeaker è un'ottima piattaforma per imparare la scienza dei dati.")
per np in blob.noun_phrases:
Stampa (per esempio)
>> analisi vidhya
ottima piattaforma
scienza dei dati
Come vediamo, i risultati non sono del tutto corretti, ma dobbiamo essere consapevoli che stiamo lavorando con le macchine.
3.3 Etichettare una parte della voce
L'etichettatura parziale del discorso o l'etichettatura grammaticale è un metodo per contrassegnare le parole presenti in un testo in base alla loro definizione e contesto. In parole semplici, dice se una parola è un sostantivo, un aggettivo, un verbo, eccetera. Questa è solo una versione completa dell'estrazione di frasi nominali, dove vogliamo trovare tutte le parti del discorso in una frase.
Controlliamo le etichette del nostro blocco di testo.
per le parole, tag in blob.tags:
Stampa (parole, etichetta)
>> Analisi NNS
Vidhya NNP
è VBZ
un DT
grande JJ
piattaforma NN
a TO
impara VB
dati NNS
scienza NN
Qui, NN rappresenta un sostantivo, DT rappresenta un determinante, eccetera. Puoi controllare l'elenco completo delle etichette su qui sapere ma.
3.4 Flessione e derivazione delle parole
Inflessione è un processo di parola formazione in cui i caratteri vengono aggiunti alla forma base di a parola esprimere significati grammaticali. La flessione delle parole in TextBlob è molto semplice, vale a dire, le parole che abbiamo tokenizzato da un textblob possono essere facilmente cambiate in singolare o plurale.
blob = TextBlob("DataPeaker è un'ottima piattaforma per imparare la scienza dei dati. n Aiuta la comunità attraverso i blog, hackathon, discussioni,eccetera.")
Stampa (blob.frasi[1].parole[1])
Stampa (blob.frasi[1].parole[1].singolarizzare())
>> aiuta
aiuto
La libreria TextBlob offre anche un oggetto integrato noto come Parola. Abbiamo solo bisogno di creare un oggetto parola e quindi applicare una funzione direttamente come mostrato di seguito.
da blob di testo importa Word
w = Parola('Piattaforma')
w.pluralizzare()
>>"Piattaforme"
Possiamo anche usare i tag per flettere un particolare tipo di parole come mostrato di seguito.
## usando i tag per parola,pos in blob.tags: se posizione == 'NN': Stampa (parola.pluralizzare()) >> piattaforme scienze
Le parole possono essere derivate usando il lematizzare funzione.
## lemmatizzazione
w = Parola('in esecuzione')
w.lemmatize("v") ## v qui rappresenta verbo
>> 'correre'
3,5 N-grammi
Una combinazione di più parole insieme è chiamata N-Grams. Gli N grammi (n> 1) sono generalmente più informativi rispetto alle parole e possono essere utilizzati come funzionalità per la modellazione del linguaggio. È possibile accedere facilmente a N-grammi in TextBlob utilizzando il pulsante nggrammi funzione, che restituisce una tupla di n parole successive.
per ngram in blob.ngrams(2):
Stampa (ngram)
>> ["Analisi", 'Vidhya']
['Vidhya', 'è']
['è', 'un']
['un', 'Grande']
['Grande', 'piattaforma']
['piattaforma', 'a']
['a', 'imparare']
['imparare', 'dati']
['dati', 'scienza']
3.6 Analisi del sentimento
L'analisi del sentimento è fondamentalmente il processo di determinazione dell'atteggiamento o dell'emozione dello scrittore, vale a dire, si è positivo, negativo o neutro.
il sentimento la funzione textblob restituisce due proprietà, polarità, e soggettività.
La polarità è fluttuante che è nell'intervallo di [-1,1] dove 1 significa affermazione positiva e -1 significa affermazione negativa. Le frasi soggettive generalmente si riferiscono a opinioni, emozioni o giudizi personali, mentre quelli oggettivi si riferiscono a informazioni fattuali. La soggettività è anche un galleggiante che è nel raggio di [0,1].
Rivediamo il sentimento del nostro blob.
Stampa (blob) blob.sentiment >> DataPeaker è un'ottima piattaforma per imparare la scienza dei dati. Sentimento(polarità=0.8, soggettività=0.75)
Possiamo vedere che la polarità è 0,8, il che significa che l'affermazione è positiva e 0,75 la soggettività si riferisce al fatto che si tratta principalmente di un'opinione pubblica e non di un'informazione fattuale.
4. Altre cose interessanti da fare
4.1 Correzione ortografica
Il controllo ortografico è una funzionalità interessante offerta da TextBlob, puoi accedervi utilizzando il Destra lavorare come mostrato di seguito.
blob = TextBlob("DataPeaker è un'ottima piattaforma per imparare la scena dei dati")
blob.corretto()
>> TestoBlob("DataPeaker è un'ottima piattaforma per imparare la scienza dei dati")
Possiamo anche controllare l'elenco delle parole suggerite e la tua sicurezza utilizzando il correttore ortografico funzione.
blob.parole[4].controllo ortografico()
>> [('Grande', 0.5351351351351351),
('ottenere', 0.3162162162162162),
('cresciuto', 0.11216216216216217),
('grigio', 0.026351351351351353),
('salutare', 0.006081081081081081),
('agitare', 0.002702702702702703),
('grinta', 0.0006756756756756757),
('Riccio', 0.0006756756756756757)]
4.2 Crea un breve riassunto di un testo
Questo è un semplice trucco che useremo le cose che abbiamo imparato in precedenza. Primo, dai un'occhiata al codice mostrato di seguito e capisci te stesso.
importa casuale
blob = TextBlob("DataPeaker è una fiorente comunità per l'industria basata sui dati. Questa piattaforma consente
persone per saperne di più sull'analisi dai suoi articoli, Q&un forum, e percorsi di apprendimento. Anche, aiutiamo
professionisti & dilettanti per affinare le loro competenze fornendo una piattaforma per partecipare a Hackathon.')
sostantivi = lista()
per parola, tag in blob.tags:
if tag == 'NN':
sostantivi.append(word.lemmatize())
Stampa ("Questo testo parla di...")
per articolo in random.sample(nomi, 5):
parola = Parola(articolo)
Stampa (parola.pluralizzare())
>> Questo testo parla di...
comunità
piattaforme
forum
piattaforme
industrie
Semplice, Non è così? Quello che abbiamo fatto prima è estrarre un elenco di nomi dal testo per dare al lettore un'idea generale delle cose a cui il testo si riferisce..
4.3 Traduzione e rilevamento della lingua
Riesci a indovinare cosa c'è scritto nella riga seguente??
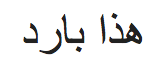
E e! Riesci a indovinare di che lingua si tratta?? Non preoccuparti, lo rileviamo usando textblob...
blob.detect_language() >> 'Insieme a'
Quindi, È arabo. Ora, proviamo a tradurlo in inglese così possiamo sapere cosa è scritto usando TextBlob.
blob.translate(from_lang='ar', a = 'en')
>> TestoBlob("questo è figo")
Anche se non definisci esplicitamente la lingua di partenza, TextBlob rileverà automaticamente la lingua e la tradurrà nella lingua desiderata.
blob.translate(a = 'en') ## oppure puoi fare direttamente così
>> TestoBlob("questo è figo")
Questo è davvero fantastico !!! ?
5. Classificazione del testo utilizzando TextBlob
Costruiamo un semplice modello di classificazione del testo usando TextBlob. Per questo, primo, dobbiamo preparare un allenamento e testare i dati.
allenamento = [
("Tom Holland è un terribile uomo ragno.",'pos'),
('un terribile Javert (Russell Crowe) mi ha rovinato Les Miserables...','pos'),
("Il cavaliere oscuro - Il ritorno è il più grande film di supereroi di sempre"!','negativo'),
("I Fantastici Quattro non avrebbero mai dovuto essere realizzati.",'pos'),
("Wes Anderson è il mio regista preferito"!','negativo'),
('Capitano America 2 è piuttosto impressionante.','negativo'),
('Fingiamo che "Batman e Robin" mai accaduto..','pos'),
]
test = [
("Superman non è mai stato un personaggio interessante.",'pos'),
('Fantastic Mr Fox è un film fantastico!','negativo'),
('Dragonball Evolution è semplicemente terribile!!','pos')
]
Textblob fornisce un modulo classificatori integrato per creare un classificatore personalizzato. Quindi, importiamolo velocemente e creiamo un classificatore di base.
dai classificatori di importazione textblob classificatore = classificatori.NaiveBayesClassifier(addestramento)
Come puoi vedere sopra, abbiamo passato i dati di addestramento al classificatore.
Nota che qui abbiamo usato il classificatore Naive Bayes, ma TextBlob offre anche il classificatore dell'albero decisionale mostrato di seguito.
## classificatore albero decisionale dt_classifier = classificatori.DecisionTreeClassifier(addestramento)
Ora, controlliamo l'accuratezza di questo classificatore sul set di dati di test e anche TextBlob ci fornisce per verificare le funzionalità più informative.
Stampa (classificatore.accuratezza(test))
classifier.show_informative_features(3)
>> 1.0
Caratteristiche più informative
contiene(è) = Vero negativo : pos = 2.9 : 1.0
contiene(terribile) = Falso negativo : pos = 1.8 : 1.0
contiene(mai) = Falso negativo : pos = 1.8 : 1.0
Che cosa, possiamo vedere che se il testo contiene “è”, allora c'è un'alta probabilità che l'affermazione sia negativa.
Per dare un'idea in più, controlliamo il nostro classificatore su un testo casuale.
blob = TextBlob('il tempo è terribile!', classificatore=classificatore)
Stampa (blob.classify())
>> negativo
Quindi, basato sull'allenamento nel set di dati sopra, il nostro classificatore ci ha dato il risultato corretto.
Nota che qui avremmo potuto fare un po' di pre-elaborazione e pulizia dei dati, ma qui il mio obiettivo era darti un'idea di come possiamo fare la classificazione del testo usando TextBlob.
6. Pro e contro
Professionisti:
- dato che, è costruito sulle spalle di NLTK e Pattern, così, lo rende semplice per i principianti fornendo un'interfaccia intuitiva per NLTK.
- Fornisce la traduzione e il rilevamento della lingua che funziona con Google Translate (non fornito con Spacy).
Contro:
- È un po' più lento rispetto allo spazio, ma più veloce di NLTK. (Spazio> TestoBlob> NLTK)
- Non fornisce funzionalità come l'analisi delle dipendenze, vettori di parole, eccetera. che fornisce spazio.
7. Note finali
Spero che ti diverta a conoscere questa libreria. TestoBlob, in realtà, ha fornito un'interfaccia molto semplice per i principianti per imparare le attività di base della PNL.
Consiglierei a tutti i principianti di iniziare con questa libreria e poi, fare un lavoro avanzato, possono anche imparare ad essere distanziati. Continueremo a utilizzare TextBlob per la prototipazione iniziale in quasi tutti i progetti di PNL.
Puoi trovare il codice completo per questo articolo nel mio github deposito.
Cosa c'è di più, Hai trovato questo articolo utile? Condividi le tue opinioni / pensieri nella sezione commenti qui sotto.





