introduzione
La mayoría de ustedes habría escuchado cosas emocionantes que suceden usando el apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute.... Inoltre avrei sentito dire che il Deep Learning ha bisogno di molto hardware. Ho visto persone addestrare un semplice modello di deep learning per giorni sui loro laptop (generalmente senza GPU), che dà l'impressione che il deep learning abbia bisogno di grandi sistemi per funzionare.
Nonostante questo, questo è solo parzialmente vero e crea un mito intorno all'apprendimento profondo che crea un ostacolo per i principianti. Molte persone mi hanno chiesto quale tipo di hardware sarebbe il migliore per il deep learning. Con questo post spero di darvi una risposta.
Nota: Presumo che tu abbia una comprensione fondamentale dei concetti di deep learning. Se non è così, dovrebbe leggere questo post.
Sommario
- Fatto # 101: DL ha bisogno
tantohardware - Formazione di un modello di deep learning
- Come addestrare il tuo modello più velocemente?
- CPU contro GPU
- Breve storia delle GPU: Come siamo arrivati qui?
- Quale GPU usare oggi?
- Il futuro sembra eccitante
Fatto # 101: Esigenze di apprendimento profondo tanto hardware
Quando sono stato introdotto per la prima volta al deep learning, Pensavo che il deep learning necessitasse necessariamente di un grande data center per funzionare, e il “esperti di deep learning” sedevano nelle loro sale di controllo per far funzionare questi sistemi.

Questo perché in ogni libro che ho citato o in ogni discorso che ho sentito, l'autore o il relatore commenta sempre che l'apprendimento profondo richiede molta potenza di calcolo per funzionare. Ma quando ho costruito il mio primo modello di deep learning sulla mia piccola macchina, mi sono sentito sollevato! Non devo prendere il controllo di Google per essere un esperto di deep learning 😀
Questo è un errore comune che tutti i principianti affrontano quando si immergono nell'apprendimento profondo.. Anche se è vero che il deep learning richiede hardware considerevole per funzionare in modo efficiente, non devi essere infinito per fare i compiti. Puoi persino eseguire modelli di deep learning sul tuo laptop!!
Solo un piccolo disclaimer; più piccolo è il tuo sistema, più tempo ci vorrà per ottenere un modello addestrato che funzioni abbastanza bene. Semplicemente, può assomigliare a questo:

Poniamoci una semplice domanda; Perché abbiamo bisogno di più hardware per il deep learning??
La soluzione è semplice, l'apprendimento profondo è un algoritmo – un software build. Definimos una neuronale rossoLe reti neurali sono modelli computazionali ispirati al funzionamento del cervello umano. Usano strutture note come neuroni artificiali per elaborare e apprendere dai dati. Queste reti sono fondamentali nel campo dell'intelligenza artificiale, consentendo progressi significativi in attività come il riconoscimento delle immagini, Elaborazione del linguaggio naturale e previsione delle serie temporali, tra gli altri. La loro capacità di apprendere schemi complessi li rende strumenti potenti.. artificial en nuestro lenguaje de programación favorito que posteriormente se convertiría en un conjunto de comandos que se ejecutan en la computadora.
Se dovessi indovinare quali componenti della rete neurale ritieni richiedano risorse hardware intense, Quale sarebbe la tua risposta??
Alcuni dei candidati che ho in mente sono:
- Pre-elaborazione dei dati di input
- Addestrare il modello di deep learning
- Archiviazione del modello di deep learning addestrato
- Distribuzione del modello
Tra tutti questi, addestrare il modello di deep learning è il compito più intenso. Vediamo nel dettaglio perché è così.
Formazione di un modello di deep learning
Quando alleni un modello di deep learning, vengono eseguite due operazioni principali:
- Passaggio anticipato
- Passa indietro
Sul passo avanti, l'input viene passato attraverso la rete neurale e, dopo l'elaborazione dell'input, viene generato un output. Mentre sul retro passa, aggiorniamo i pesi della rete neurale in base all'errore che otteniamo nel passaggio in avanti.
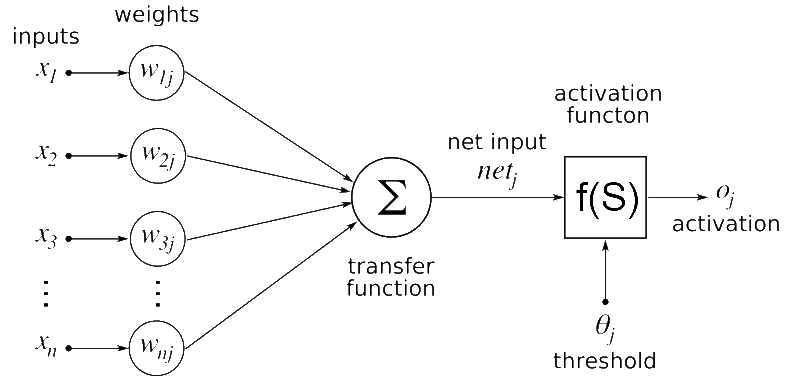
Entrambe le operazioni sono essenzialmente moltiplicazioni matriciali. Una semplice moltiplicazione di matrici può essere rappresentata con la seguente immagine
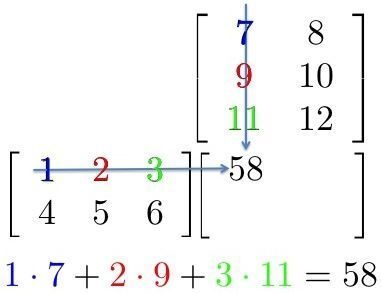
Qui, possiamo vedere che ogni elemento di una riga della prima matrice viene moltiplicato per una colonna della seconda matrice. Quindi, in una rete neurale, possiamo considerare la prima matrice come input alla rete neurale, e la seconda matrice può essere considerata come pesi della rete.
Questo sembra essere un compito semplice.. Ora, solo per darti un'idea di che tipo di scale di deep learning: VGG16 (un convolucional neuronale rossoReti neurali convoluzionali (CNN) sono un tipo di architettura di rete neurale progettata appositamente per l'elaborazione dei dati con una struttura a griglia, come immagini. Usano i livelli di convoluzione per estrarre le caratteristiche gerarchiche, il che li rende particolarmente efficaci nelle attività di riconoscimento e classificazione dei modelli. Grazie alla sua capacità di apprendere da grandi volumi di dati, Le CNN hanno rivoluzionato campi come la visione artificiale.. a partire dal 16 strati nascosti spesso utilizzati nelle applicazioni di deep learning) ha ~ 140 millones de parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto....; noto anche come pesi e pregiudizi. Ora pensa a tutte le moltiplicazioni di matrici che dovresti fare per passare un solo input a questa rete!! Ci vorrebbero anni per addestrare questi tipi di sistemi se adottiamo approcci tradizionali.
Come addestrare la tua rete neurale più velocemente?
Abbiamo visto che la parte computazionalmente intensiva della rete neurale è costituita da moltiplicazioni multiple di matrici. Quindi, Come possiamo renderlo più veloce??
Possiamo semplicemente farlo eseguendo tutte le operazioni contemporaneamente invece di eseguirle una dopo l'altra.. Brevemente, questo è il motivo per cui usiamo la GPU (unità di elaborazione grafica) invece di una CPU (Unità centrale di elaborazione) addestrare una rete neurale.
Per darti un piccolo assaggio, torniamo alla storia quando abbiamo testato che le GPU erano migliori delle CPU per l'attività.
Prima del boom del deep learning, Google aveva un sistema estremamente potente per eseguire la sua elaborazione, che avevano appositamente costruito per addestrare enormi reti. Questo sistema era mostruoso e aveva un costo totale di $ 5 miliardi, con più gruppi di CPU.
Ora, los investigadores de Stanford construyeron el mismo sistema en términos de computación para entrenar sus Reti profondeReti profonde, Conosciute anche come reti neurali profonde, sono strutture computazionali ispirate al funzionamento del cervello umano. Queste reti sono composte da più livelli di nodi interconnessi che consentono di apprendere rappresentazioni complesse dei dati. Sono fondamentali nel campo dell'intelligenza artificiale, soprattutto in attività come il riconoscimento delle immagini, Elaborazione del linguaggio naturale e guida autonoma, migliorando così la capacità delle macchine di comprendere e... usando GPU. E indovina cosa; Costi ridotti a solo $ 33K! Questo sistema è stato realizzato con GPU e ha fornito la stessa potenza di elaborazione del sistema di Google.. Molto impressionante, verità?
| Stanford | ||
| Numero di core | 1K CPU = 16K core | 3GPU = 18K nuclei |
| Costo | $ 5 miliardi | $ 33 mille |
| Tiempo de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... | settimana | settimana |
Possiamo vedere che le GPU regnano. Ma, Qual è esattamente la differenza tra una CPU e una GPU??
Differenza tra CPU e GPU
Per capire la differenza, prendiamo un'analogia classica che spiega la differenza in modo intuitivo.
Supponiamo di dover trasferire merci da un luogo all'altro. Hai la possibilità di scegliere tra una Ferrari e un camion merci.
La Ferrari sarebbe estremamente veloce e ti aiuterebbe a trasferire un lotto di merci in pochissimo tempo. Ma la quantità di merci che può trasportare è piccola e il consumo di carburante sarebbe molto alto..
Un camion merci sarebbe lento e richiederebbe molto tempo per trasferire le merci. Ma la quantità di merce che può trasportare è maggiore rispetto alla Ferrari. Allo stesso tempo, è più efficiente nel consumo di carburante, quindi l'uso è minore.
Quindi, Quale sceglieresti per il tuo lavoro?
Evidentemente, prima vedrai qual è il compito; Se devi venire a prendere urgentemente la tua ragazza, sceglierei sicuramente una Ferrari rispetto a un camion merci. Ma se stai cambiando casa, Userei un camion merci per trasferire i mobili.
Ecco come differenziare tecnicamente i due:

Ecco un altro video che chiarirebbe ulteriormente il tuo concetto.
Nota: La GPU viene utilizzata principalmente per giochi e simulazioni complesse. Questi compiti e principalmente calcoli grafici, quindi la GPU è un'unità di elaborazione grafica. Se la GPU viene utilizzata per l'elaborazione non grafica, sono chiamati GPGPU: unità di elaborazione grafica per uso generale
Breve storia delle GPU: Come siamo arrivati qui?
Ora, potresti chiederti perché le GPU sono così calde in questo momento. Viaggiamo attraverso una breve storia dello sviluppo della GPU.
Semplicemente, Un GPGPU è una configurazione di programmazione parallela che coinvolge GPU e CPU in grado di elaborare e analizzare i dati in modo equivalente a un'immagine o altro modo grafico. I GPGPU sono stati costruiti per un'elaborazione grafica migliore e più generale, ma in seguito si scoprì che erano ben adattati al calcolo scientifico. Questo perché la maggior parte dell'elaborazione grafica comporta l'applicazione di operazioni su array di grandi dimensioni.
L'uso di GPGPU per il calcolo scientifico è iniziato in 2001 con l'implementazione della moltiplicazione matriciale. Uno dei primi algoritmi comuni ad essere implementato più velocemente sulle GPU è stato il factoring LU 2005. Ma, A quest'ora, i ricercatori hanno dovuto codificare tutti gli algoritmi su una GPU e hanno dovuto comprendere l'elaborazione grafica di basso livello.
Sopra 2006, Nvidia ha introdotto un linguaggio CUDA di alto livello, che ti aiuta a scrivere programmi da processori grafici in un linguaggio di alto livello. Questo è stato probabilmente uno dei cambiamenti più significativi nel modo in cui i ricercatori interagiscono con le GPU..
Quale GPU usare oggi?
Qui ti fornirò rapidamente alcune conoscenze tecniche prima di acquistare una GPU per il deep learning.
Palcoscenico 1:
La prima cosa da determinare è quale tipo di risorsa richiedono le tue attività. Se le tue attività saranno piccole o possono inserirsi in complesse elaborazioni sequenziali, non hai bisogno di un grande sistema per funzionare. Potresti anche saltare completamente l'utilizzo della GPU. Perché, se hai intenzione di lavorare principalmente in "altre" aree / Algoritmi ML, non hai necessariamente bisogno di una GPU.
Palcoscenico 2:
Se i tuoi compiti sono un po' intensi e disponi di dati gestibili, una GPU ragionevole sarebbe un'opzione migliore per te. In genere uso il mio laptop per lavorare su problemi con i giocattoli., che ha una GPU leggermente obsoleta (una Nvidia GT 740M . da 2 GB). Avere un laptop GPU mi aiuta a eseguire le cose ovunque io vada. Ci sono alcuni laptop di fascia alta (e dovrebbero essere pesanti) con Nvidia GTX 1080 (una VRAM di 8 GB) che puoi interrogare alla fine.
Palcoscenico 3:
Se lavori regolarmente su problemi complessi o sei un'azienda che sfrutta il deep learning, probablemente sería mejor que creara un sistema de aprendizaje profundo o utilizara un Servizio cloudIl "Servizio cloud" si riferisce alla fornitura di risorse informatiche su Internet, Consentire agli utenti di accedere allo storage, elaborazione e applicazioni senza la necessità di un'infrastruttura fisica locale. Questo modello offre flessibilità, Scalabilità e risparmio sui costi, poiché le aziende pagano solo per ciò che usano. Cosa c'è di più, Facilita la collaborazione e l'accesso ai dati da qualsiasi luogo, migliorare l'efficienza operativa in vari settori.. como AWS o FloydHub. In DataPeaker creiamo un sistema di deep learning per noi stessi, per cui condividiamo le nostre specifiche. Ecco il post.
Palcoscenico 4:
Se sei google, probabilmente avrai bisogno di un altro data center da mantenere. Scherzi a parte, se i tuoi compiti sono su una scala più ampia del solito e hai abbastanza soldi in tasca per coprire i costi; Puoi scegliere per un grappoloUn cluster è un insieme di aziende e organizzazioni interconnesse che operano nello stesso settore o area geografica, e che collaborano per migliorare la loro competitività. Questi raggruppamenti consentono la condivisione delle risorse, Conoscenze e tecnologie, promuovere l'innovazione e la crescita economica. I cluster possono coprire una varietà di settori, Dalla tecnologia all'agricoltura, e sono fondamentali per lo sviluppo regionale e la creazione di posti di lavoro.... de GPU y hacer computación con múltiples GPU. Ci sono anche alcune opzioni che potrebbero essere disponibili nel prossimo futuro., come TPU e FPGA più veloci, questo renderebbe la vita più facile.
Il futuro sembra eccitante
Come menzionato in precedenza, c'è molta ricerca e lavoro attivo per pensare ad alternative per accelerare l'elaborazione. Google dovrebbe introdurre le unità di elaborazione Tensorflow (TPU) alla fine di quest'anno, che promette accelerazione rispetto alle attuali GPU.
Equivalentemente, Intel sta lavorando per creare FPGA più veloci, che può garantire una maggiore flessibilità nei prossimi giorni. Allo stesso tempo, offerte da fornitori di servizi cloud (come esempio, AWS) stanno anche aumentando. Vedremo ognuno di loro emergere nei prossimi mesi..
Note finali
In questo post, abbiamo spiegato le motivazioni dell'utilizzo di una GPU per applicazioni di deep learning e visto come sceglierle per il tuo compito. Spero che questo post ti sia stato utile. Se hai domande specifiche sull'argomento, sentiti libero di commentare qui sotto o di chiedere in portale di discussione.





