Questo post è stato pubblicato come parte del Blogathon sulla scienza dei dati.
introduzione

In questo post, cercheremo di mitigarlo attraverso l'uso del Apprendimento per rinforzoL'apprendimento per rinforzo è una tecnica di intelligenza artificiale che consente a un agente di imparare a prendere decisioni interagendo con un ambiente. Attraverso il feedback sotto forma di premi o punizioni, L'agente ottimizza il proprio comportamento per massimizzare le ricompense accumulate. Questo approccio viene utilizzato in una varietà di applicazioni, Dai videogiochi alla robotica e ai sistemi di raccomandazione, distinguendosi per la sua capacità di apprendere strategie complesse.....
Técnicas que podemos usar para predecir los precios de las acciones
Al tratarse de una predicción de valores continuos, se puede usar cualquier tipo de técnica de regresión:
- La regresión lineal le ayudará a predecir valores continuos
- Los modelos de series de tiempo son modelos que se pueden usar para datos relacionados con el tiempo.
- ARIMA es uno de esos modelos que se utiliza para predecir predicciones futuristas asociadas con el tiempo.
- LSTM es además una de esas técnicas que se ha utilizado para las predicciones del precio de las acciones. LSTM se refiere a la memoria a largo plazo y hace uso de redes neuronales para predecir valores continuos. Los LSTM son muy poderosos y son conocidos por retener la memoria a largo plazo.
Nonostante questo, hay otra técnica que se puede usar para las predicciones del precio de las acciones y es el aprendizaje por refuerzo.
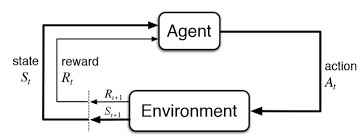
Che cos'è l'apprendimento per rinforzo??
El aprendizaje por refuerzo es otro tipo de aprendizaje automático al mismo tiempo del apprendimento supervisionatoL'apprendimento supervisionato è un approccio di apprendimento automatico in cui un modello viene addestrato utilizzando un set di dati etichettati. Ogni input nel set di dati è associato a un output noto, consentendo al modello di imparare a prevedere i risultati per nuovi input. Questo metodo è ampiamente utilizzato in applicazioni come la classificazione delle immagini, Riconoscimento vocale e previsione delle tendenze, sottolineandone l'importanza in... e senza supervisione. Se trata de un sistema de aprendizaje basado en agentes en el que el agente realiza acciones en un entorno en el que el objetivo es maximizar el registro. El aprendizaje por refuerzo no necesita el uso de datos etiquetados como el aprendizaje supervisado.
El aprendizaje por refuerzo funciona muy bien con menos datos históricos. Hace uso de la función de valor y la calcula en base a la política que se decida para esa acción.
El aprendizaje por refuerzo se modela como un procedimiento de decisión de Markov (MDP):
-
Un entorno E y estados de agente S
-
Un conjunto de acciones A tomadas por el agente.
-
P (S, s ‘) => P (ns + 1 = s’ | st = s, at = a) es la probabilidad de transición de un estado sa s ‘
-
R (S, s ‘): recompensa inmediata por cualquier acción
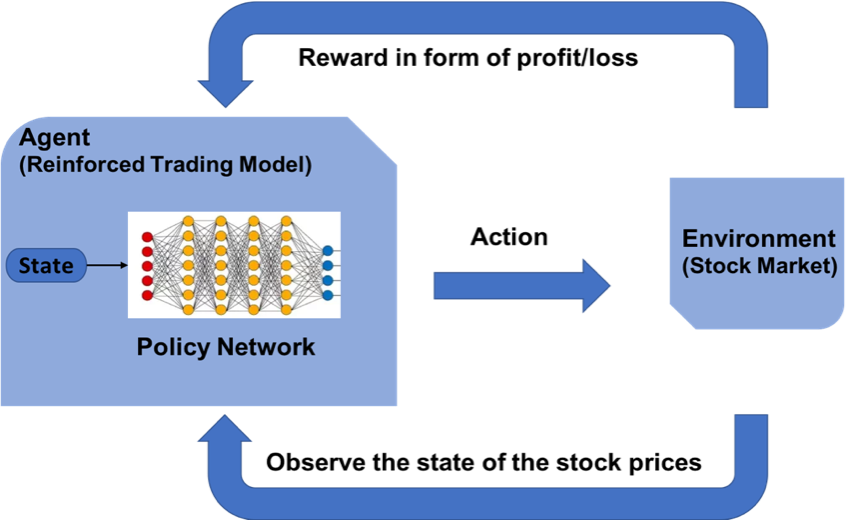
¿Cómo podemos predecir los precios del mercado de valores usando el aprendizaje por refuerzo?
El concepto de aprendizaje reforzado se puede aplicar a el pronóstico del precio de las acciones para una acción específica, puesto que utiliza los mismos principios fundamentales de requerir datos históricos menores, trabajando en un sistema basado en agentes para predecir rendimientos más altos en función del entorno actual. Veremos un ejemplo de predicción del precio de una acción para una determinada acción siguiendo el modelo de aprendizaje por refuerzo. Hace uso del concepto de aprendizaje Q explicado con más detalle.
Los pasos para diseñar un modelo de aprendizaje por refuerzo son:
- Importazione di librerie
- Crea el agente que tomará todas las decisiones.
- Establecer funciones básicas para formatear los valores, función sigmoidea, leer el archivo de datos, eccetera.
- Formare l'agente
- Examinar el desempeño del agente
Establecer el entorno de aprendizaje reforzado
MDP para el pronóstico del precio de las acciones:
- Agente: un agente A que trabaja en el entorno E
- Azione – Comprar / Comercializar / Mantener
- Estados: valores de datos
- Recompensas: ganancias / rischi
El papel de Q – Learning
Q-learning es un algoritmo de aprendizaje por refuerzo sin modelo para conocer la calidad de las acciones y decirle a un agente qué acción tomar en qué circunstancias. Q-learning encuentra una política óptima en el sentido de maximizar el valor esperado de la recompensa total en cualquier paso sucesivo, comenzando desde el estado actual.
Consecución de datos
-
Ir a Yahoo Finance
-
Escriba el nombre de la compañía, come esempio. Banco HDFC
-
Seleccione el período de tiempo para, come esempio, 5 anni
-
Haga clic en Descargar para descargar el archivo CSV
Implementemos nuestro modelo en Python
Importazione di librerie
Para construir el modelo de aprendizaje por refuerzo, importe las bibliotecas de Python indispensables para modelar las capas de la neuronale rossoLe reti neurali sono modelli computazionali ispirati al funzionamento del cervello umano. Usano strutture note come neuroni artificiali per elaborare e apprendere dai dati. Queste reti sono fondamentali nel campo dell'intelligenza artificiale, consentendo progressi significativi in attività come il riconoscimento delle immagini, Elaborazione del linguaggio naturale e previsione delle serie temporali, tra gli altri. La loro capacità di apprendere schemi complessi li rende strumenti potenti.. y la biblioteca NumPy para algunas operaciones básicas.
import keras
from keras.models import Sequential
from keras.models import load_model
from keras.layers import Dense
from keras.optimizers import Adam
import math
import numpy as np
import random
from collections import deque
Creando el Agente
El código del agente comienza con algunas inicializaciones básicas para los distintos parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto..... Se definen algunas variables estáticas como gamma, epsilon, epsilon_min y epsilon_decay. Estos son valores de umbral constante que se usan para impulsar todo el procedimiento de compra y venta de acciones y mantener los parámetros con calma. Estos valores mínimos y de caída sirven como valores de umbral en la distribución normal.
El agente diseña el modelo de red neuronal en capas para realizar acciones de compra, venta o retención. Este tipo de acción se lleva a cabo al observar su predicción anterior y además el estado del entorno actual. El método act se utiliza para predecir la próxima acción que se tomará. Si la memoria se llena, existe otro método llamado expReplay diseñado para restablecer la memoria.
Agente de clase:
def __init__(se stesso, state_size, is_eval=False, nome_modello=""): self.state_size = state_size # normalized previous days self.action_size = 3 # sit, comprare, sell self.memory = deque(maxlen=1000) self.inventory = [] self.model_name = model_name self.is_eval = is_eval self.gamma = 0.95 self.epsilon = 1.0 self.epsilon_min = 0.01 self.epsilon_decay = 0.995 self.model = load_model(nome del modello) if is_eval else self._model() def _model(se stesso): modello = Sequenziale() modello.aggiungi(Denso(units=64, input_dim=self.state_size, attivazione="riprendere")) modello.aggiungi(Denso(units=32, attivazione="riprendere")) modello.aggiungi(Denso(units=8, attivazione="riprendere")) modello.aggiungi(Denso(self.action_size, attivazione="lineare")) modello.compila(perdita="mse", ottimizzatore=Adam(lr=0,001)) return model def act(se stesso, stato): if not self.is_eval and random.random()<= self.epsilon: restituire random.randrange(self.action_size) options = self.model.predict(stato) restituire np.argmax(options[0]) def expReplay(se stesso, dimensione del lotto): mini_batch = [] l = len(self.memory) per io nel raggio d'azione(io - dimensione del lotto + 1, io): mini_batch.append(self.memory[io]) for state, azione, ricompensa, next_state, done in mini_batch: target = reward if not done: target = reward + self.gamma * np.amax(self.model.predict(next_state)[0]) target_f = self.model.predict(stato) target_f[0][azione] = target self.model.fit(stato, target_f, epochs=1, verboso=0) se self.epsilon > self.epsilon_min: self.epsilon *= self.epsilon_decay
Establecer funciones básicas
El formatprice () se escribe para estructurar el formato de la moneda. GetStockDataVec () traerá los datos de stock a Python. Defina la función sigmoidea como un cálculo matemático. GetState () está codificado de tal manera que proporciona el estado actual de los datos.
def formatPrice(n): Restituzione("-Rs." se n<0 altro "Rs.")+"{0:.2F}".formato(addominali(n)) def getStockDataVec(chiave): vec = [] lines = open(key+".csv","R").leggere().splitlines() per linea in righe[1:]: #Stampa(linea) #Stampa(galleggiante(line.split(",")[4])) vec.append(galleggiante(line.split(",")[4])) #Stampa(vec) return vec def sigmoid(X): Restituzione 1/(1+math.exp(-X)) def getState(dati, T, n): d = t - n + 1 block = data[D:T + 1] se d >= 0 else -d * [dati[0]] + dati[0:T + 1] # pad with t0 res = [] per io nel raggio d'azione(n - 1): res.append(sigmoide(blocco[io + 1] - blocco[io])) restituire np.array([res])
Entrenando al Agente
Dependiendo de la acción que predice el modelo, la llamada de compra / venta suma o resta dinero. Se entrena por medio de múltiples episodios que son los mismos que épocas en el apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute.... Prossimo, el modelo se guarda posteriormente.
import sys stock_name = input("Enter stock_name, window_size, Episode_count") window_size = input() episode_count = input() stock_name = str(stock_name) window_size = int(window_size) episode_count = int(episode_count) agente = Agente(window_size) data = getStockDataVec(stock_name) l = len(dati) - 1 batch_size = 32 for e in range(episode_count + 1): Stampa("Episode " + str(e) + "/" + str(episode_count)) state = getState(dati, 0, window_size + 1) total_profit = 0 agent.inventory = [] per t nell'intervallo(io): action = agent.act(stato) # sit next_state = getState(dati, T + 1, window_size + 1) reward = 0 se azione == 1: # buy agent.inventory.append(dati[T]) Stampa("Buy: " + formatPrice(dati[T])) elif action == 2 e len(agent.inventory) > 0: # sell bought_price = window_size_price = agent.inventory.pop(0) reward = max(dati[T] - bought_price, 0) total_profit += data[T] - bought_price print("Sell: " + formatPrice(dati[T]) + " | Profit: " + formatPrice(dati[T] - bought_price)) done = True if t == l - 1 else False agent.memory.append((stato, azione, ricompensa, next_state, done)) state = next_state if done: Stampa("--------------------------------") Stampa("Profitto totale: " + formatPrice(total_profit)) Stampa("--------------------------------") se len(agent.memory) > dimensione del lotto: agent.expReplay(dimensione del lotto) if e % 10 == 0: agent.model.save(str(e))
Salida de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... al final del primer episodio:
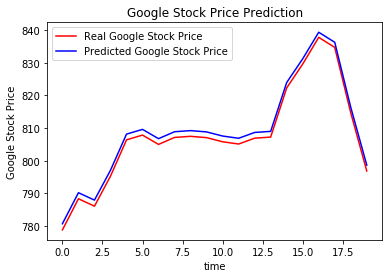
Profitto totale: Rs.340.03
Evaluación del modelo
Una vez que se haya entrenado el modelo en función de los nuevos datos, podrá probar el modelo para establecer las ganancias / pérdidas que ofrece. Di conseguenza, puede examinar la credibilidad del modelo.
stock_name = input("Enter Stock_name, Model_name") model_name = input() modello = load_model(nome del modello) window_size = model.layers[0].input.shape.as_list()[1] agente = Agente(window_size, Vero, nome del modello) data = getStockDataVec(stock_name) Stampa(dati) l = len(dati) - 1 batch_size = 32 state = getState(dati, 0, window_size + 1) Stampa(stato) total_profit = 0 agent.inventory = [] Stampa(io) per t nell'intervallo(io): action = agent.act(stato) Stampa(azione) # sit next_state = getState(dati, T + 1, window_size + 1) reward = 0 se azione == 1: # buy agent.inventory.append(dati[T]) Stampa("Buy: " + formatPrice(dati[T])) elif action == 2 e len(agent.inventory) > 0: # sell bought_price = agent.inventory.pop(0) reward = max(dati[T] - bought_price, 0) total_profit += data[T] - bought_price print("Sell: " + formatPrice(dati[T]) + " | Profit: " + formatPrice(dati[T] - bought_price)) done = True if t == l - 1 else False agent.memory.append((stato, azione, ricompensa, next_state, done)) state = next_state if done: Stampa("--------------------------------") Stampa(stock_name + " Profitto totale: " + formatPrice(total_profit)) Stampa("--------------------------------") Stampa ("Total profit is:",formatPrice(total_profit))
Note finali
El aprendizaje por refuerzo da resultados positivos para las predicciones de valores. A través de el uso de Q learning, se pueden realizar diferentes experimentos. Más investigación sobre el aprendizaje por refuerzo permitirá la aplicación del aprendizaje por refuerzo en una etapa más segura.
Puedes comunicarte con





