Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati.
introduzione
come riabilitare le persone attraverso l'uso di dati e informazioni pertinenti.
In questo progetto, prevediamo i sentimenti dei tweet COVID-19. I dati raccolti dal Tweeter e useremo l'ambiente Python per implementare questo progetto.
Dichiarazione problema
La sfida data è quella di costruire un modello di classificazione per prevedere il sentimento dei tweet Covid-19.. I tweet sono stati estratti da Twitter ed è stata eseguita la codifica manuale. Riceviamo informazioni come Posizione, Tuitear en, Tweet originale e Sentimiento.
Approccio per analizzare vari sentimenti
prima di continuare, è utile sapere cosa si intende per sentiment analysis. L'analisi del sentiment è il processo di identificazione e classificazione computazionale delle opinioni espresse in un testo, soprattutto per determinare se l'atteggiamento dello scrittore verso un particolare argomento è positivo, Negativo o Neutro. (dizionario di Oxford)
Di seguito è riportata la procedura operativa standard per l'approccio al tipo di progetto di analisi del sentimento. Seguiremo questa procedura per prevedere ciò che dovremmo prevedere!!
-
Analisi esplorativa dei dati.
-
Pretrattamento dei dati.
-
Vettorializzazione.
-
Modelli di classificazione.
-
Valutazione.
-
conclusione.
Indovina qualche tweet
Leggerò il tweet e puoi dirmi il sentimento di quel tweet se è positivo?, negativo o neutro? Quindi il primo tweet è “Mi stupisce ancora quanti dipendenti del supermercato di #Toronto lavorino senza una sorta di mascherina. Sappiamo tutti ormai che i dipendenti possono essere asintomatici durante la trasmissione del #coronavirus”. Qual è la tua ipotesi?? sì, hai ragione. Questo è un tweet negativo perché contiene parole negative come “Sorpreso”.
Se non riesci a indovinare il tweet qui sopra, Non preoccuparti, Ho un altro tweet per te. Indovina questo tweet-"A causa della situazione Covid-19, abbiamo aumentato la domanda di tutti i prodotti alimentari. Il tempo di consegna potrebbe essere più lungo per tutti gli ordini online, in particolare i pacchetti di condivisione del congelatore e della carne. Vi ringraziamo per la vostra pazienza in questo periodo".. Questa volta hai assolutamente ragione nel prevedere questo tweet come “Positivo”. Parole come “Grazie”, “Maggiore richiesta” sono ottimisti in natura, quindi queste parole hanno classificato il tweet come positivo.
Riepilogo dati
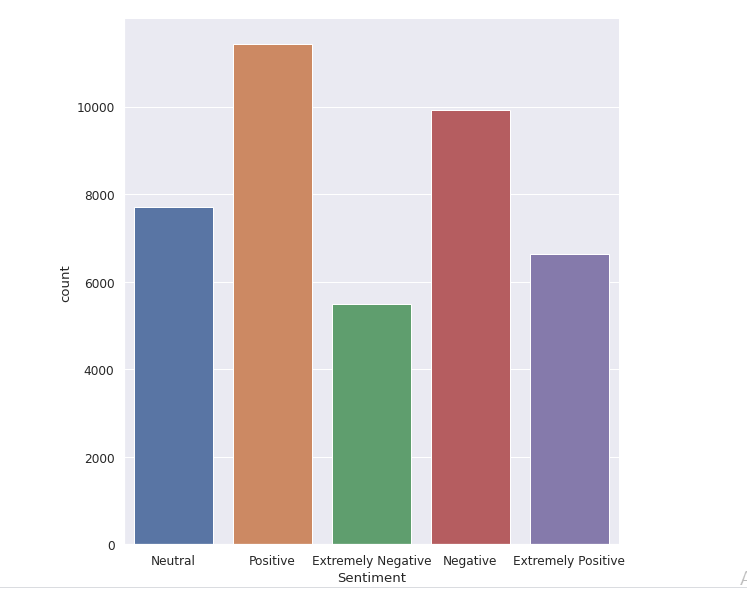
Il set di dati originale ha 6 colonne e 41157 righe. Per analizzare vari sentimenti, abbiamo solo bisogno di due colonne chiamate Original Tweet e Sentiment. Ci sono cinque tipi di sentimenti: Estremamente negativo, negativo, neutro, positivo ed estremamente positivo come puoi vedere nell'immagine seguente.
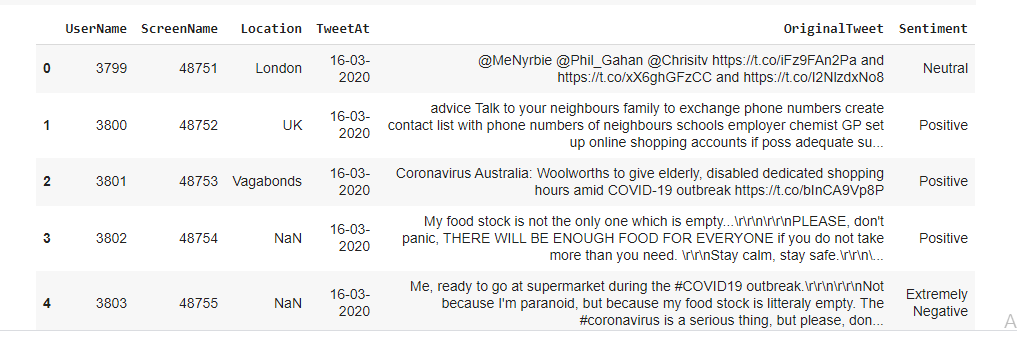
Riepilogo set di dati
Analisi di base dei dati esplorativi
Colonne come “Nome utente” e “Nome della schermata"Non forniscono informazioni significative per la nostra analisi. Perciò, non usiamo queste funzioni per la costruzione del modello. Tutti i dati dei tweet raccolti per i mesi di marzo e aprile 2020. Il seguente grafico a barre ci mostra il numero di valori univoci in ogni colonna.
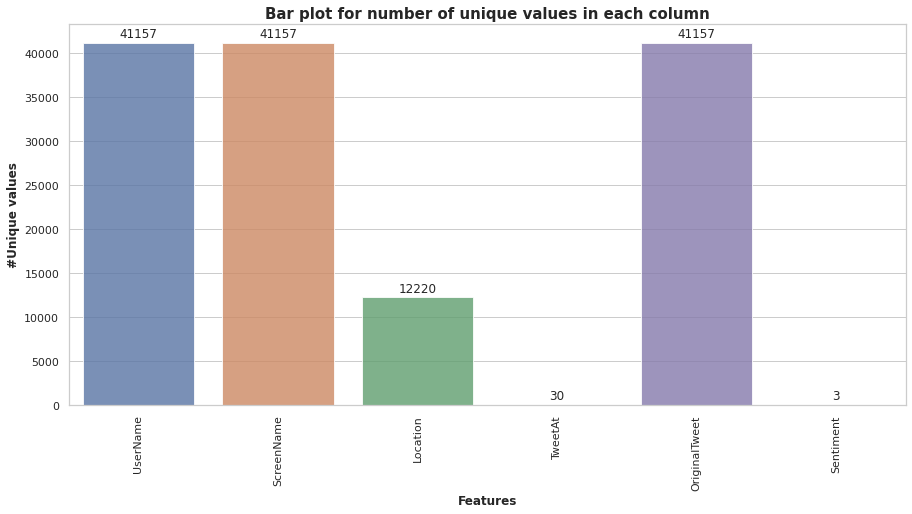
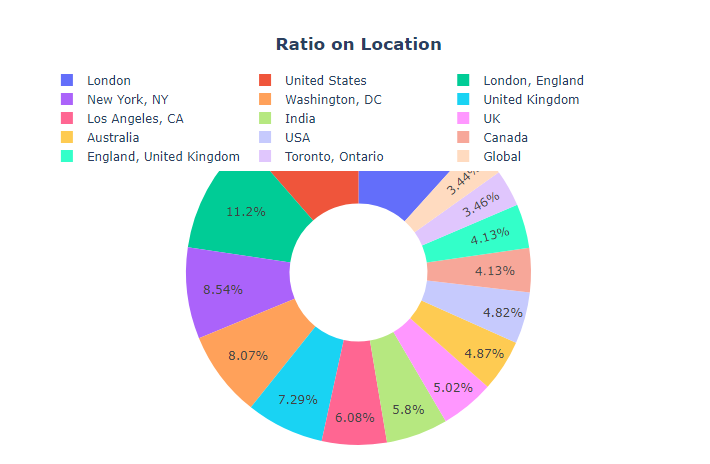
Ci sono alcuni valori nulli nella colonna della posizione, ma non abbiamo bisogno di prenderci cura di loro, poiché useremo solo due colonne, vale a dire, “Sentimento” e “Tweet originale". La maggior parte dei tweet è arrivata dalla sede di Londra (11,7%), como se desprende de la siguiente figura"Figura" è un termine che viene utilizzato in vari contesti, Dall'arte all'anatomia. In campo artistico, si riferisce alla rappresentazione di forme umane o animali in sculture e dipinti. In anatomia, designa la forma e la struttura del corpo. Cosa c'è di più, in matematica, "figura" è legato alle forme geometriche. La sua versatilità lo rende un concetto fondamentale in molteplici discipline.....
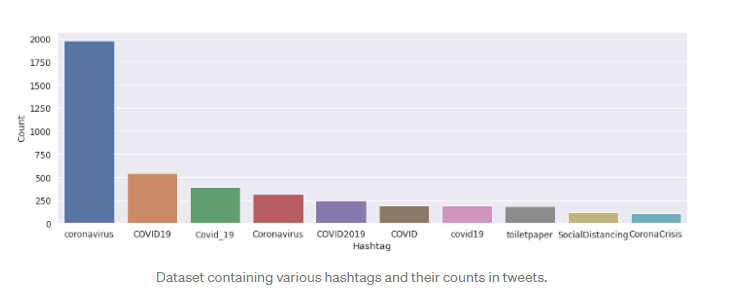
Ci sono alcune parole come "coronavirus", 'negozio di alimentari', che hanno la frequenza massima nel nostro set di dati. Possiamo vederlo nella seguente nuvola di parole. Ci sono diversi #hashtag nella colonna dei tweet. Ma sono quasi uguali in tutti i sentimenti, quindi non ci forniscono informazioni complete e significative.
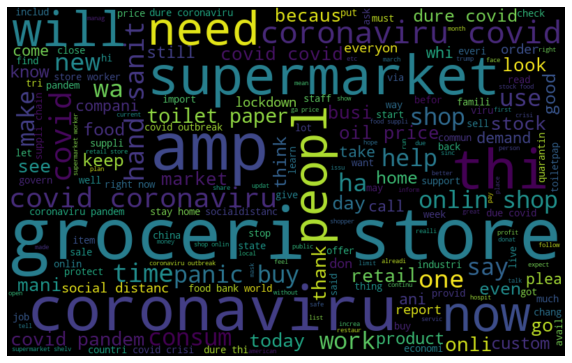
World Cloud che mostra le parole che hanno una frequenza massima nella nostra colonna Tweet
Quando proviamo ad esplorare la colonna "Feeling", abbiamo scoperto che la maggior parte delle persone ha sentimenti positivi su vari argomenti, cosa ci mostra il tuo ottimismo in tempi di pandemia. Pochissime persone hanno pensieri estremamente negativi sul Covid-19.
Pretrattamento dei dati
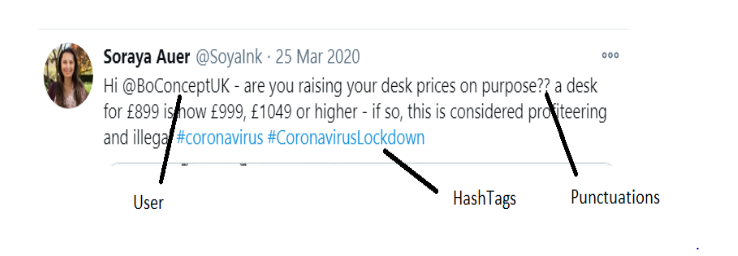
La pre-elaborazione dei dati di testo è un passaggio essenziale, in quanto rende il testo in chiaro pronto per l'estrazione. L'obiettivo di questo passaggio è ripulire i rumori meno rilevanti per trovare il sentimento di tweet come punteggiatura(.,?, "Eccetera.), personaggi speciali(@,%, &, $, eccetera.), numeri(1,2,3, eccetera.), mango il tweeter, link(HTTPS: / HTTP:) e termini che non hanno molto peso nel contesto del testo.
Cosa c'è di più, dobbiamo rimuovere le parole vuote dai tweet. Le stopword sono quelle parole del linguaggio naturale che hanno pochissimo significato., Che cosa “è”, “un”, “il”, eccetera. Per rimuovere le stopword da una frase, puoi suddividere il testo in parole e quindi eliminare la parola se esiste nell'elenco di parole non significative fornito da NLTK.
Dopo, dobbiamo normalizzare i tweet usando Stemming o Lemmatization. “Stemming ”è un processo basato su regole per rimuovere i suffissi (" ns "," mento "," è ",“ed”," S ", eccetera.) di una parola. Ad esempio, “giocare a”, “giocatore”, “giocato”, “giocare a” e “giocare a” sono le diverse varianti della parola – “giocare a”.

La derivazione non convertirà le parole originali in parole significative. Come potete vedere, “considerato” è derivato in “condizione”, che non ha significato ed è anche un errore di ortografia. Il modo migliore è usare lo stemming invece del processo di derivazione.
La derivazione è un'operazione più potente e prende in considerazione l'analisi morfologica delle parole. Restituisce il motto, che è la forma base di tutte le sue forme flessive.

Qui, nel processo di lemmatizzazione, stiamo girando la parola “alzare” alla sua forma base “alzare”. También necesitamos convertir todos los tweets a minúsculas antes de realizar el proceso de standardizzazioneLa standardizzazione è un processo fondamentale in diverse discipline, che mira a stabilire norme e criteri uniformi per migliorare la qualità e l'efficienza. In contesti come l'ingegneria, Istruzione e amministrazione, La standardizzazione facilita il confronto, Interoperabilità e comprensione reciproca. Nell'attuazione degli standard, si promuove la coesione e si ottimizzano le risorse, che contribuisce allo sviluppo sostenibile e al miglioramento continuo dei processi.....
Possiamo includere il processo di tokenizzazione. Nella tokenizzazione, convertiamo un gruppo di frasi in token. También se denomina segmentazioneLa segmentazione è una tecnica di marketing chiave che comporta la divisione di un ampio mercato in gruppi più piccoli e omogenei. Questa pratica consente alle aziende di adattare le proprie strategie e i propri messaggi alle caratteristiche specifiche di ciascun segmento, migliorando così l'efficacia delle tue campagne. Il targeting può essere basato su criteri demografici, psicografico, geografico o comportamentale, facilitando una comunicazione più pertinente e personalizzata con il pubblico di destinazione.... de texto o análisis léxico. Fondamentalmente, si tratta di dividere i dati in un piccolo numero di parole. La tokenizzazione in Python può essere eseguita da Python NLTK word_tokenize funzione () dalla biblioteca.
Vettorializzazione
Possiamo usare un vettore di conteggio o un vettore TF-IDF. Count Vectorizer creerà un array sparso di tutte le parole e il numero di volte in cui sono presenti in un documento.
TFIDF, Corto per termine inverso frequenza-frequenza del documento, è una statistica numerica che cerca di riflettere l'importanza di una parola per un documento in una raccolta o corpus. Il valore TF - IDF aumenta proporzionalmente al numero di volte che una parola compare nel documento ed è compensato dal numero di documenti nel corpus che contengono la parola, che aiuta ad adattarsi al fatto che alcune parole appaiono più frequentemente in generale. (wiki)
Modelli di classificazione degli edifici
Il problema dato è la classificazione ordinale multiclasse. Ci sono cinque tipi di sentimenti, quindi dobbiamo addestrare i nostri modelli in modo che possano darci l'etichetta corretta per il set di dati di test. Costruirò diversi modelli come Bayes ingenuo, Regressione logistica, foresta casuale, XGBoost, supporta macchine vettoriali, CatBoost y descenso de gradienteGradiente è un termine usato in vari campi, come la matematica e l'informatica, per descrivere una variazione continua di valori. In matematica, si riferisce al tasso di variazione di una funzione, mentre in progettazione grafica, Si applica alla transizione del colore. Questo concetto è essenziale per comprendere fenomeni come l'ottimizzazione negli algoritmi e la rappresentazione visiva dei dati, consentendo una migliore interpretazione e analisi in... Stocastico.
He usado el problema dado de Clasificación multiclase que es una variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... dependiente que tiene los valores -Positivo, Estremamente positivo, Neutro, Negativo, Estremamente negativo. Converti anche questo problema in una classificazione binaria, vale a dire, Ho classificato tutti i tweet solo in due tipi Positivo e Negativo. Puoi anche optare per la classificazione a tre classi, vale a dire, Positivo, Negativo e Neutro per una maggiore precisione. In fase di valutazione, confronteremo i risultati di questi algoritmi.
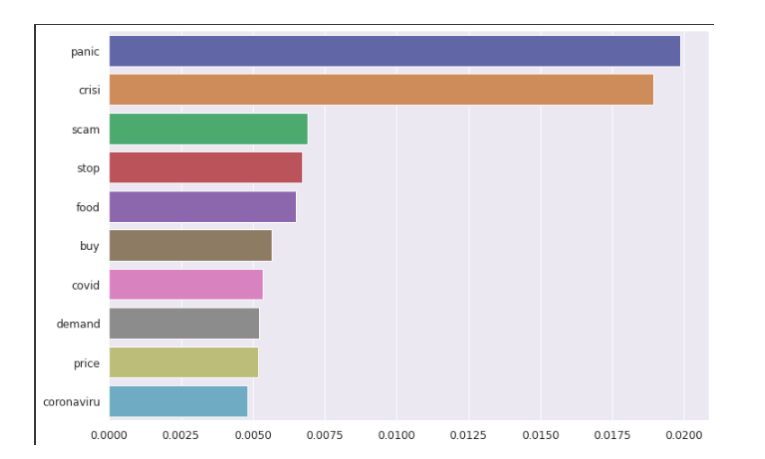
Importanza della funzione
il importanza delle caratteristiche (importanza variabile) descrivere quale caratteristiche è rilevante. Può aiutare a capire meglio il problema risolto e, A volte, portare a miglioramenti del modello impiegando caratteristica selezione. Le prime tre parole evidenziate sono panico, crisi e truffa, come possiamo vedere nel grafico seguente.
conclusione
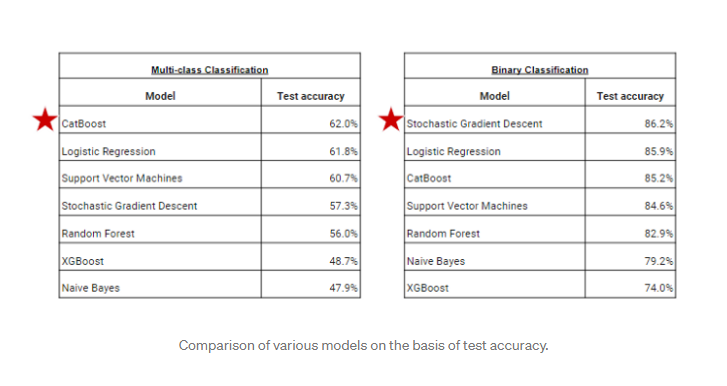
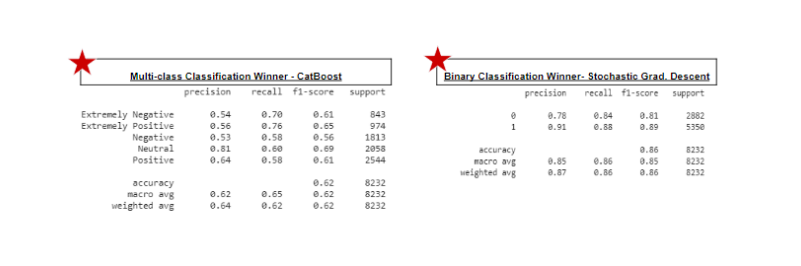
In questo modo, possiamo esplorare ulteriormente da vari tweet e dati testuali. I nostri modelli cercheranno di prevedere correttamente i diversi sentimenti. Ho usato vari modelli per addestrare il nostro set di dati, ma alcuni modelli mostrano una maggiore precisione mentre altri no. Per la classificazione multiclasse, il miglior modello per questo set di dati sarebbe CatBoost. Per la classificazione binaria, il modello migliore per questo set di dati sarebbe Stochastic Gradient Descent.
(Puoi accedere al codice Python di questo progetto da questo link-https://github.com/rajeshmore1/Capstone-Project-2 )
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





