Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
introduzione:
Tecnologia. Questo set di dati è composto da cifre scritte a mano dal 0 al 9 e fornisce una pavimentazione per testare i sistemi di elaborazione delle immagini. Questo è considerato il "programma Hello World in Machine Learning"’ que involucra Deep Learning.
I passaggi coinvolti sono:
- Importa set di dati
- Dividir el conjunto de datos en prueba y addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina....
- Costruzione del modello
- Allena il modello
- Prevedi precisione
1) Importazione di set di dati:
Per continuare con il codice, abbiamo bisogno del set di dati. Quindi, pensiamo a varie fonti come set di dati, FIA, Kaggle, eccetera. Ma dal momento che stiamo usando Python con i suoi vasti moduli integrati, ha i dati MNIST nel modulo keras.datasets. Perciò, non abbiamo bisogno di scaricare e memorizzare i dati esternamente.
da keras.datsets import mnist data = mnist.load_data()
Perciò, dal modulo keras.datasets importiamo la funzione mnist che contiene il data set.
Dopo, il set di dati è memorizzato nei dati variabili utilizzando la funzione mnist.load_data () che carica il set di dati in dati variabili.
Prossimo, vediamo il tipo di dati che troviamo qualcosa di insolito dato che è del tipo tupla. Sappiamo che il set di dati mnist contiene immagini di cifre scritte a mano, immagazzinato sotto forma di tuple.
dati genere(dati)
2) Dividi il set di dati in training e test:
Dividiamo direttamente il set di dati in train and test. Quindi, Per quello, inizializziamo quattro variabili X_train, y_train, X_test, y_test per danneggiare il treno e testare i dati rispettivamente per i valori dipendenti e indipendenti.
(X_treno, y_train), (X_test, y_test) = dati X_treno[0].forma X_train.shape

Stampando la forma di ogni immagine possiamo scoprire che ha una dimensione di 28 × 28. Il che significa che l'immagine ha 28 pixel x 28 pixel.
Ora, dobbiamo rimodellare in modo tale da poter accedere a ogni pixel dell'immagine. La razón para acceder a cada píxel es que solo entonces podemos aplicar ideas de apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute... y podemos asignar un código de color a cada píxel. Quindi memorizziamo l'array rimodellato in X_train, X_test rispettivamente.
X_train = X_train.reshape((X_train.shape[0], 28*28)).come tipo('float32')
X_test = X_test.reshape((X_test.shape[0], 28*28)).come tipo('float32')
Conosciamo il codice colore RGB in cui valori diversi producono vari colori. È anche difficile ricordare tutte le combinazioni di colori. Quindi, fare riferimento a questo Collegamento per avere una breve idea sui codici colore RGB.
Sappiamo già che ogni pixel ha il suo codice colore univoco e sappiamo anche che ha un valore massimo di 255. Per realizzare Machine Learning, è importante convertire tutti i valori di 0 un 255 per ogni pixel a un intervallo di valori di 0 un 1. Il modo più semplice è dividere il valore di ogni pixel per 255 per ottenere i valori nell'intervallo di 0 un 1.
X_treno = X_treno / 255 X_test = X_test / 255
Ora abbiamo finito di dividere i dati in test e training, oltre a preparare i dati per un uso successivo. Perciò, ora possiamo passare al pass 3: Costruzione di modelli.
3) Allena il modello:
Per eseguire la costruzione del modello, dobbiamo importare le funzioni richieste, vale a dire, sequenziale e denso per eseguire deep learning, che è disponibile nella libreria Keras.
Ma questo non è direttamente disponibile, por lo que debemos comprender este simple grafico a lineeIl grafico a linee è uno strumento visivo utilizzato per rappresentare i dati nel tempo. È costituito da una serie di punti collegati da linee, che permette di osservare le tendenze, Fluttuazioni e modelli nei dati. Questo tipo di grafico è particolarmente utile in aree come l'economia, Meteorologia e ricerca scientifica, semplificando il confronto di diversi set di dati e l'identificazione dei comportamenti su tutta la linea..:
1) Duro -> Modelli -> Sequenziale
2) Duro -> Copertine -> Denso
Vediamo come possiamo importare le funzioni con la stessa logica di un codice Python.
da keras.models import Sequential da keras.layers import Dense modello = Sequenziale() modello.aggiungi(Denso(32, input_dim = 28 * 28, attivazione = 'rileggere')) modello.aggiungi(Denso(64, attivazione = 'rileggere')) modello.aggiungi(Denso(10, attivazione = 'softmax'))
Luego almacenamos la función en el modelo de variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi...., in quanto semplifica l'accesso alla funzione ogni volta invece di digitare la funzione ogni volta, possiamo usare la variabile e chiamare la funzione.
Dopo, trasforma l'immagine in un denso gruppo di livelli e impila ogni livello uno sopra l'altro e usa 'relu’ como nuestra funzione svegliaLa funzione di attivazione è un componente chiave nelle reti neurali, poiché determina l'output di un neurone in base al suo input. Il suo scopo principale è quello di introdurre non linearità nel modello, Consentendo di apprendere modelli complessi nei dati. Ci sono varie funzioni di attivazione, come il sigma, ReLU e tanh, Ognuno con caratteristiche particolari che influiscono sulle prestazioni del modello in diverse applicazioni..... La spiegazione di "relu"’ va oltre lo scopo di questo blog. Per avere maggiori informazioni a riguardo, puoi consultare Quello.
D'altra parte, impiliamo qualche altro strato con "softmax"’ come nostra funzione di attivazione. Per maggiori informazioni sulla funzione 'softmax', puoi fare riferimento a questo articolo, in quanto è di nuovo oltre lo scopo di questo blog, poiché il mio obiettivo principale è ottenere il più accurato possibile con il set di dati MNIST.
Dopo, infine compiliamo il modello completo e usiamo entropia incrociata como nuestra Funzione di perditaLa funzione di perdita è uno strumento fondamentale nell'apprendimento automatico che quantifica la discrepanza tra le previsioni del modello e i valori effettivi. Il suo obiettivo è quello di guidare il processo di formazione minimizzando questa differenza, consentendo così al modello di apprendere in modo più efficace. Esistono diversi tipi di funzioni di perdita, come l'errore quadratico medio e l'entropia incrociata, ognuno adatto a compiti diversi e..., per ottimizzare l'uso del nostro modello Adamo come nostro ottimizzatore e usiamo la precisione come metrica per valutare il nostro modello.
Per una panoramica del nostro modello, usamos ‘model.summary ()', che fornisce brevi dettagli sul nostro modello.
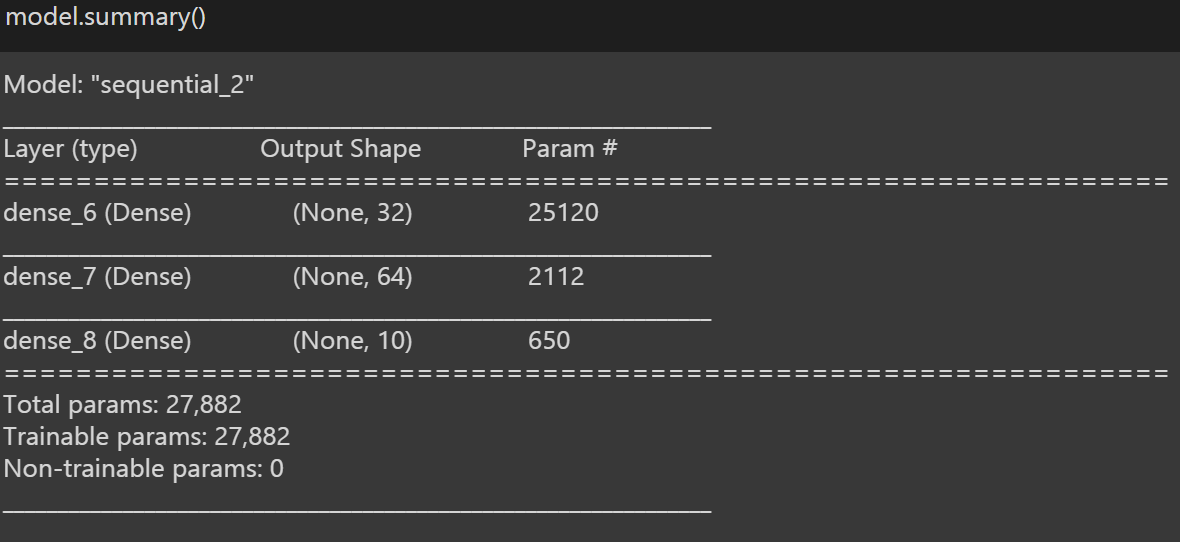
Ora possiamo passare al Pass 4: Allena il modello.
4) Allena il modello:
Questo è il penultimo passaggio in cui addestreremo il modello con una singola riga di codice. Quindi, Per quello, stiamo usando la funzione .fit () che prende come input l'insieme dei treni della variabile dipendente e della variabile indipendente e dipendente, e imposta le epoche = 10, e imposta batch_size come 100.
Trenino => X_treno; y_train
Epoche => Una época significa entrenar la neuronale rossoLe reti neurali sono modelli computazionali ispirati al funzionamento del cervello umano. Usano strutture note come neuroni artificiali per elaborare e apprendere dai dati. Queste reti sono fondamentali nel campo dell'intelligenza artificiale, consentendo progressi significativi in attività come il riconoscimento delle immagini, Elaborazione del linguaggio naturale e previsione delle serie temporali, tra gli altri. La loro capacità di apprendere schemi complessi li rende strumenti potenti.. con todos los datos de entrenamiento para un ciclo. Un'epoca è composta da uno o più lotti, dove usiamo una parte del set di dati per addestrare la rete neurale. Il che significa che mandiamo il modello in addestramento 10 tempi per ottenere un'elevata precisione. Puoi anche modificare il numero di epoche in base alle prestazioni del modello.
Dimensione del lotto => La dimensione batch è un termine utilizzato nell'apprendimento automatico e si riferisce al numero di esempi di addestramento utilizzati in un'iterazione. Quindi, fondamentalmente, noi inviamo 100 immagini da addestrare come batch per iterazione.
Vediamo la parte di codifica.
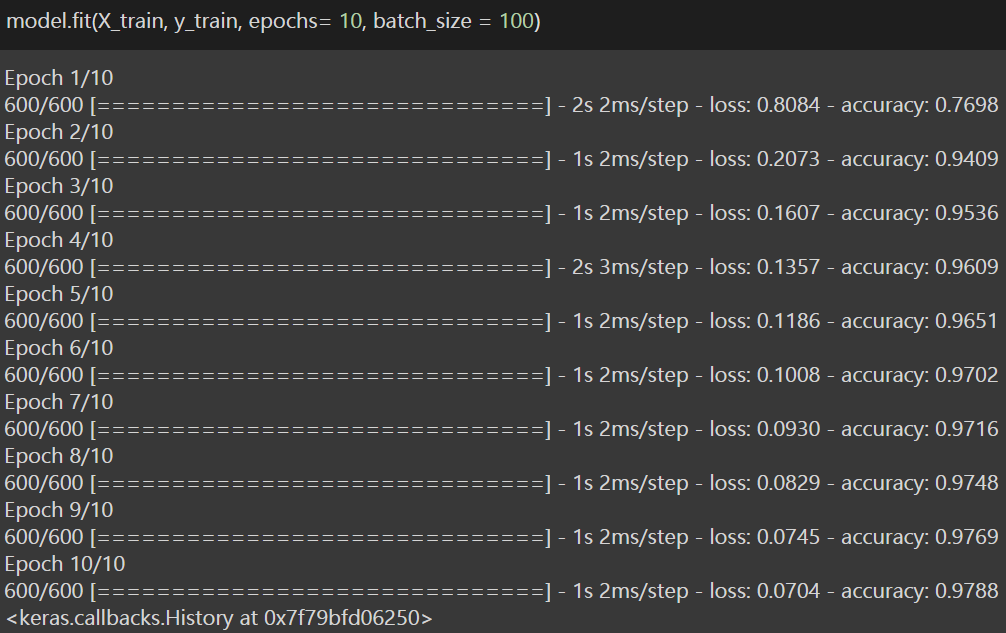
Perciò, dopo aver addestrato il modello, abbiamo raggiunto una precisione di 97,88% per il set di dati di allenamento. Ora è il momento di vedere come funziona il modello nel set di prova e vedere se abbiamo raggiunto la precisione richiesta. Perciò, ora andiamo all'ultimo passaggio o passaggio 5: Prevedi precisione.
5) Precisione della previsione:
Quindi, per scoprire come funziona il modello sul set di dati di test, Uso la variabile punteggi per memorizzare il valore e uso la funzione .valuta () che prende il test set delle variabili dipendenti e indipendenti come input. Questo calcola la perdita e la precisione del modello nel set di prova. Come ci concentriamo sulla precisione, stampiamo solo la precisione.

Finalmente, abbiamo raggiunto il risultato e garantiamo una precisione di oltre 96% nel set di prova che è molto apprezzabile, e il motivo del blog è raggiunto. Ho scritto il link a il computer portatile per tua referenza (lettori).
Per favore, sentiti libero di connetterti con me attraverso Linkedin così come. E grazie per aver letto il blog.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





