Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
Le macchine che capiscono il linguaggio mi affascinano, e rifletto spesso a quali algoritmi si sarebbe abituato Aristotele per costruire una macchina di analisi retorica se avesse avuto la possibilità. Se sei nuovo nella scienza dei dati, entrare nella PNL può sembrare complicato, soprattutto perché ci sono molti recenti progressi nel campo. è difficile capire da dove cominciare.
Sommario
1. Cosa possono capire le macchine??
2.Progetto 1: nuvola di parole
3.Progetto 2: Rilevamento spam
4.Progetto 3: Analisi del sentimento
5. conclusione
Cosa possono capire le macchine??
Mentre un computer può essere abbastanza bravo a trovare schemi e riassumere documenti, deve trasformare le parole in numeri prima di dar loro un senso. Questa trasformazione è molto necessaria perché la matematica non funziona molto bene con le parole e le macchine. “loro imparano” grazie alla matematica. Prima della trasformazione delle parole in numeri, è richiesta la pulizia dei dati. La pulizia dei dati include la rimozione della punteggiatura e dei caratteri speciali e la loro modifica in modo da renderli più coerenti e interpretabili.
Progetto 1: nuvola di parole
1.Dipendenze e importazione dati
Inizia importando le dipendenze e i dati. I dati vengono archiviati come file di valori separati da virgole (CSV), quindi userò i panda ‘ read_csv () funzione per aprirlo in un DataFrame.
import pandas as pd import sqlite3 import regex as re import matplotlib.pyplot as plt from wordcloud import WordCloud #create dataframe from csv df = pd.read_csv('emails.csv') df.head() df.head()


2.Analisi esplorativa
Para eliminar filas duplicadas y establecer algunos recuentos de línea de base, es mejor hacer un análisis rápido de los datos. Aquí usamos pandas drop_duplicates para eliminar las filas duplicadas.
Stampa("spam count: " +str(len(df.loc[df.spam==1])))
Stampa("not spam count: " +str(len(df.loc[df.spam==0])))
Stampa(forma df)
df['spam'] = df['spam'].come tipo(int)
df = df.drop_duplicates()
df = df.reset_index(inplace = False)[['testo','spam']]
Stampa(forma df)
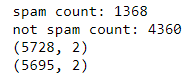
Conta e modella prima / dopo la deduplica
Cos'è una nuvola di parole??
Le nuvole di parole facilitano la comprensione delle frequenze delle parole, quindi è un modo utile per visualizzare i dati di testo. Le parole che appaiono più grandi nel cloud sono quelle che compaiono più frequentemente nel testo dell'email. Le nuvole di parole facilitano l'identificazione “parole chiave”.
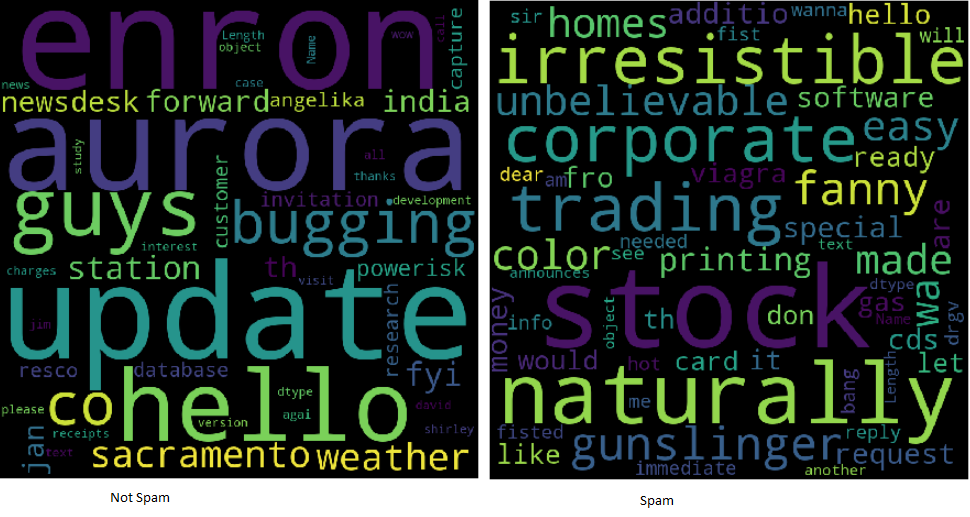
Esempi di nuvole di parole
Todo el texto está en minúsculas en la imagen de nube de palabras. No contiene signos de puntuación ni caracteres especiales. El texto ahora se llama limpio y listo para su análisis. Con la ayuda de expresiones regulares, es fácil limpiar el texto usando un bucle:
clean_desc = [] for w in range(len(df.text)): desc = df['testo'][w].inferiore() #remove punctuation desc = re.sub('[^ a-zA-Z]', ' ', desc) #remove tags desc=re.sub("</?.*?>"," <> ",desc) #remove digits and special chars desc=re.sub("(D|W)+"," ",desc) clean_desc.append(desc) #assign the cleaned descriptions to the data frame df['testo'] = clean_desc df.head(3)

Nota che qui creiamo una lista vuota clean_desc, allora usiamo a di continuo per controllare il testo riga per riga, impostandolo in minuscolo, rimuovere punteggiatura e caratteri speciali e aggiungerlo all'elenco. Quindi sostituiamo la colonna di testo con i dati nell'elenco clean_desc.
Per le parole
Le stopword sono le parole più comuni come “il” e “a partire dal”. La loro rimozione dal testo dell'e-mail consente di quadrare le parole frequenti più rilevanti. Eliminare le stopword può essere una tecnica comune!! Alcune librerie Python come NLTK sono precaricate con un elenco di parole non significative, ma è facile crearne uno da zero.
stop_words = ['è','tu','tuo','e', 'il', 'a', 'a partire dal', 'o', 'IO', 'per', 'fare', 'ottenere', 'non', 'qui', 'in', 'io sono', 'avere', 'Su', 'Rif', 'nuovo', 'soggetto']
Si prega di notare che includo alcune parole relative alla posta elettronica, Che cosa “Rif” e “affare”. Spetta all'analista vedere quali parole dovrebbero essere incluse o escluse. A volte è utile incorporare tutte le parole!
Costruisci la parola potrebbe
Convenientemente, hay una biblioteca de Python para crear nubes de palabras. Se instalará usando pip.
pip installa wordcloud
Al construir la nube de palabras, es posible alinear varios parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... como alto y ancho, palabras vacías y palabras máximas. incluso es posible darle forma en lugar de mostrar el rectángulo predeterminado.
wordcloud = WordCloud(larghezza = 800, altezza = 800, background_color="Nero", stopwords = stop_words, max_words = 1000 , min_font_size = 20).creare(str(DF1['testo'])) #plot the word cloud fig = plt.figure(dimensione del fico = (8,8), facecolor = None) plt.imshow(nuvola di parole) asse.plt('spento') plt.mostra()
Para guardar y mostrar la nube de palabras. Se utilizan matplotlib y show (). Indipendentemente dal fatto che sia spam, è il risultato di tutti i record.

Spingi ulteriormente l'esercizio suddividendo il frame delle informazioni e creando nuvole di due parole per aiutare ad analizzare la differenza tra le parole chiave utilizzate nello spam e non nello spam..
Progetto 2: Rilevamento spam
Pensalo come un problema di classificazione binaria, poiché un'e-mail può essere spam indicata da “1” o nello spam indicato da “0”. Vorrei creare un modello di apprendimento automatico in grado di identificare se un'e-mail può essere spam o meno. Sto visitando la libreria Python Scikit-Learn per esplorare gli algoritmi di tokenizzazione, vettorizzazione e classificazione statistica.

Importa le dipendenze
Importa le funzionalità di Scikit-Learn che vorremmo modificare e modellare le informazioni. Userò CountVectorizer, train_test_split, modelli di insieme e un paio di metriche.
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn import ensemble
from sklearn.metrics import classification_report, precision_score
Transformar texto en números
En el proyecto 1, se limpió el texto. una vez que eche un vistazo a una nube de palabras, observe que se trata principalmente de palabras sueltas. Cuanto más grande sea la palabra, mayor será su frecuencia. Para evitar que la nube de palabras genere oraciones, il testo passa attraverso un processo chiamato tokenizzazione. è il metodo per dividere una frase in singole parole. Le singole parole sono chiamate token.
Con CountVectorizer () de SciKit-Learn, facile rielaborare il testo del corpo in una matrice sparsa di numeri che possono essere passati agli algoritmi di apprendimento automatico dal computer. Per semplificare il concetto di vettorizzazione del conteggio, immagina di avere due frasi:
Il cane è bianco
Il gatto è nero
Convertir las oraciones a un modelo de espacio vectorial las transformaría de tal manera que mira las palabras en todas las oraciones y luego representa las palabras en la oración con un número.
El perro gato es blanco negro
The dog is white = [1,1,0,1,1,0] The cat is black = [1,0,1,1,0,1] We can show this using code as well. I’ll add a third sentence to show that it counts the tokens. #list of sentences text = ["the dog is white", "the cat is black", "the cat and the dog are friends"] #instantiate the class cv = CountVectorizer() #tokenize and build vocab cv.fit(testo) Stampa(cv.vocabulary_) #transform the text vector = cv.transform(testo) Stampa(vector.toarray())
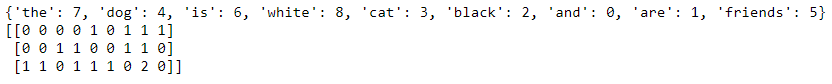
La escasa matriz de recuentos de palabras.
Observe que dentro del último vector, podrá ver un 2 ya que la palabra “il” aparece dos veces. CountVectorizer cuenta los tokens y me permite construir la matriz dispersa que contiene las palabras transformadas en números.
Método de la bolsa de palabras
Debido a que el modelo no tiene en cuenta la ubicación de las palabras y, Invece, li mescola come le patatine in uno scrabble, questo è spesso chiamato il metodo della borsa delle parole. Sto visitando per creare la matrice sparsa, quindi dividi le informazioni usando SK-learn train_test_split ().
text_vec = ContaVectorizer().fit_transform(df['testo'])
X_treno, X_test, y_train, y_test = train_test_split(text_vec, df['spam'], test_size = 0.45, stato_casuale = 42, casuale = vero)
Nota che ho impostato l'array sparse text_vec su X e il df['spam'] colonna a Y. Mescolo e prendo una dimensione di prova del 45%.
Il classificatore
Es muy recomendable experimentar con varios clasificadores y determinar cuál funciona mejor para este escenario. durante este ejemplo, estoy usando el modelo GradientBoostingClassifier () de la colección Scikit-Learn Ensemble.
classifier = ensemble.GradientBoostingClassifier( n_estimatori = 100, #how many decision trees to build learning_rate = 0.5, #learning rate max_depth = 6 )
Cada algoritmo tendrá su propio conjunto de parámetros que podrá modificar. eso se llama ajuste de hiperparámetros. sottoporsi alla documentazione per saperne di più su ciascuno dei parametri utilizzati nei modelli.
Genera previsioni
Finalmente, aggiustiamo le informazioni, chiamiamo prevedere e generare il rapporto di classificazione. Quando si utilizza classificazione_report (), facile creare un rapporto di testo che mostri la maggior parte delle metriche di classifica.
classificatore.fit(X_treno, y_train) previsioni = classificatore.predizione(X_test) Stampa(classificazione_report(y_test, predizioni))
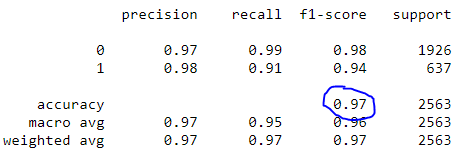
Rapporto di classificazione
Si noti che il nostro modello ha raggiunto una precisione del 97%.
Progetto 3: Analisi del sentimento
L'analisi del sentimento è, Cosa c'è di più, una sorta di problema di classificazione. Il testo è sostanzialmente in visita per riflettere un sentimento positivo, neutro o negativo. ciò si nota a causa della polarità del testo. È anche possibile determinare e rendere conto della soggettività del testo! Ci sono molte grandi risorse che coprono la speculazione dietro l'analisi del sentimento..
Invece di costruire un altro modello, questo progetto utilizza uno strumento semplice e pronto all'uso per indagare sul sentimento chiamato TextBlob. Usaré TextBlob para presentar columnas de opinión en el DataFrame para que se analicen a menudo.

¿Qué es TextBlob?
Construida sobre NLTK y patrón, la biblioteca TextBlob para Python 2 y tres intenta simplificar varias tareas de procesamiento de texto. Proporciona herramientas para clasificación, etichettatura di parte del discorso, estrazione della frase, análisis de sentimientos y más. Instálelo usando pip.
pip install -U textblob
python -m textblob.download_corpora
Sentimiento de TextBlob
Usando la propiedad de sentimiento, TextBlob devuelve una tupla con nombre de la forma Sentiment (polarità, soggettività). La polaridad puede flotar dentro del rango [-1.0, 1.0] dove -1 es el más negativo y 1 es el más positivo. La subjetividad podría flotar dentro del rango [0.0, 1.0] dove 0.0 es extremadamente objetivo y 1.0 es extremadamente subjetivo.
blob = TextBlob("This is a good example of a TextBlob")
Stampa(blob)blob.sentiment
#Sentiment(polarity=0.7, subjectivity=0.6000000000000001)
Aplicar TextBlob
Al usar listas de comprensión, es fácil cargar la columna de texto como TextBlob, así que cree dos nuevas columnas para almacenar la polaridad y la subjetividad.
#load the descriptions into textblob email_blob = [TestoBlob(testo) for text in df['testo']] #add the sentiment metrics to the dataframe df['tb_Pol'] = [b.sentiment.polarity for b in email_blob] df['tb_Subj'] = [b.sentiment.subjectivity for b in email_blob] #show dataframe df.head(3)

TextBlob hace que sea muy simple llegar a una puntuación de sentimiento de referencia para la polaridad y subjetividad. Para impulsar a este usuario aún más, vedi se puoi aggiungere queste nuove funzionalità al modello di rilevamento dello spam per aumentare la precisione.
conclusione:
Sebbene l'elaborazione della comunicazione linguistica possa sembrare un argomento intimidatorio, i pezzi fondamentali non sembrano così difficili da capire. Molte librerie facilitano l'inizio dell'esplorazione della scienza dei dati e della PNL. Completando questi tre progetti:
nuvola di parole
Rilevamento spam
Analisi del sentimento
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





