El código abierto se refiere a algo que las personas pueden modificar y compartir porque son accesibles para todos. Puede utilizar el trabajo de nuevas formas, integrarlo en un proyecto más grande o encontrar un nuevo trabajo basado en el original. El código abierto promueve el libre intercambio de ideas dentro de una comunidad para generar innovaciones o ideas creativas y tecnológicas. Perciò, los programadores deberían considerar la posibilidad de contribuir a proyectos de código abierto por las siguientes razones:
1. Le ayuda a escribir código más limpio.
2. Obtiene una mejor comprensión de la tecnología.
3. Contribuir a proyectos de código abierto le ayuda a ganar atención, popularidad y puede aprovechar su carrera.
4. Agregar un proyecto de código abierto a su currículum aumenta su peso.
5. Mejora las habilidades de codificación
6. Mejorar el software a nivel de usuario y empresarial.
 Fonte: Google Immagini
Fonte: Google Immagini
Para comenzar a contribuir a proyectos de código abierto, existen algunos requisitos previos:
1. Aprenda un lenguaje de programación: dado que en la contribución de código abierto necesita escribir código para involucrarse en el desarrollo, necesita aprender un lenguaje de programación. Eso puede ser de cualquier elección. Es fácil aprender otro idioma en una etapa posterior dependiendo de las necesidades del proyecto.
2. Familiarícese con los sistemas de control de versiones: estas son las herramientas de software que ayudan a mantener todos los cambios en un solo lugar que se están realizando para recuperarlos en una etapa posterior si es necesario. Fondamentalmente, realizan un seguimiento de cada modificación realizada por usted a lo largo del tiempo en el código fuente. Algunos sistemas de control de versiones populares son Git, Mercuriale, CVS, eccetera. De todos estos, Git es el más popular y ampliamente utilizado en la industria.
Ahora veremos algunos de los increíbles proyectos de código abierto en los que puede contribuir.
Allora cominciamo!
1. Caliban

Fonte: Google Immagini
Este es un proyecto de aprendizaje automático del gigante tecnológico Google. Se utiliza para desarrollar portátiles y flujos de trabajo de investigación de aprendizaje automático en un entorno informático aislado y reproducible. Resuelve un gran problema. Cuando los desarrolladores están creando proyectos de ciencia de datos, muchas veces es difícil crear un entorno de prueba que pueda mostrar su proyecto en una situación de la vida real. No es posible predecir todos los casos extremos. Quindi, Caliban es una posible solución para este problema. Caliban facilita el desarrollo de cualquier modelo de aprendizaje automático localmente, ejecuta código en su máquina y luego prueba exactamente el mismo código en un entorno de nube para ejecutarlo en máquinas grandes. Perciò, los flujos de trabajo de investigación de Dockerized se simplifican, tanto a nivel local como en la nube.
Enlace de Github: https://github.com/google/caliban
2. Kornia

Fonte: Google Immagini
Kornia es una biblioteca de visión por computadora para PyTorch. Se utiliza para resolver algunos problemas genéricos de visión por computadora. Kornia se basa en PyTorch y depende de su eficiencia y potencia de la CPU para poder calcular funciones complejas. Kornia es un paquete de bibliotecas que se utiliza para entrenar modelos de redes neuronales y realizar transformación de imágenes, filtrado de imágenes, detección de bordes, geometría epipolar, estimación de profundidad, eccetera.
Enlace de Github: https://github.com/kornia/kornia
3. Zoológico de análisis
![]()
![]()
Fonte: Google Immagini
Analytics Zoo es una plataforma unificada de análisis de datos e inteligencia artificial que une los programas TensorFlow, Duro, PyTorch, Scintilla, Flink y Ray en una canalización integrada. Esto puede escalar de manera eficiente desde una computadora portátil a un gran grappoloUn cluster è un insieme di aziende e organizzazioni interconnesse che operano nello stesso settore o area geografica, e che collaborano per migliorare la loro competitività. Questi raggruppamenti consentono la condivisione delle risorse, Conoscenze e tecnologie, promuovere l'innovazione e la crescita economica. I cluster possono coprire una varietà di settori, Dalla tecnologia all'agricoltura, e sono fondamentali per lo sviluppo regionale e la creazione di posti di lavoro.... para procesar la producción de big data. Este proyecto es mantenido por Intel-analítica.
Analytics Zoo ayuda a una solución de IA de las siguientes formas:
- Le ayuda a crear prototipos de modelos de IA fácilmente.
- El escalado se gestiona de forma eficiente.
- Ayuda a agregar procesos de automatización a su canal de ML como ingeniería de características, selección de modelos, eccetera.
Enlace de Github: https://github.com/intel-analytics/analytics-zoo
4. Aprendizaje automático automatizado MLJAR para humanos

Fonte: Google Immagini
Mljar es una plataforma para crear modelos de prototipos y servicios de implementación. Para encontrar el mejor modelo, Mljar busca diferentes algoritmos y realiza ajustes de hiperparámetros. Proporciona resultados rápidos interesantes al ejecutar todos los cálculos en la nube y finalmente crear modelos de conjunto. Dopo, crea un informe para usted a partir del addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... de AutoML. ¿No es esto genial?
Mljar entrena eficientemente modelos para clasificación binaria, classificazione multiclasse, regressione.
Proporciona dos tipos de interfaces:
- Puede ejecutar modelos de aprendizaje automático en su navegador web
- Proporciona un contenedor de Python sobre la API de Mljar.
El informe recibido de Mljar contiene la tabla con información sobre la puntuación de cada modelo y el tiempo necesario para entrenar cada modelo. El rendimiento se muestra como diagramas de dispersión y de caja, por lo que es fácil comprobar visualmente qué algoritmos funcionan mejor entre todos. guarda questo:
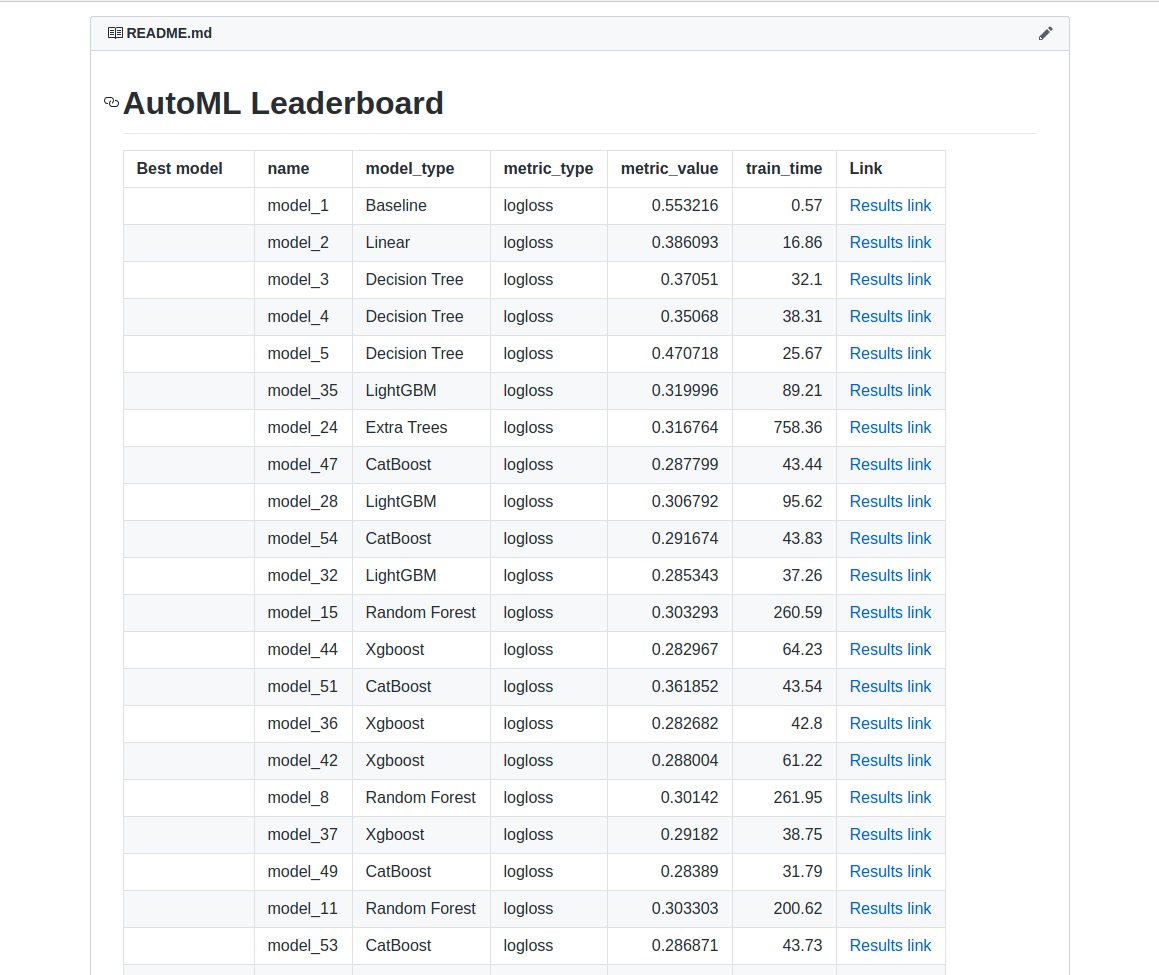
Fonte: Google Immagini
Documentazione: https://supervised.mljar.com/
Código fuente: https://github.com/mljar/mljar-supervised
5.DeepDetect
Fonte: Google Immagini
DeepDetect es una API de aprendizaje automático y un servidor escrito en C ++. Si desea trabajar con algoritmos de aprendizaje automático de última generación y desea integrarlos en aplicaciones existentes, DeepDetect es para usted. DeepDetect admite una amplia variedad de tareas como clasificación, segmentazioneLa segmentazione è una tecnica di marketing chiave che comporta la divisione di un ampio mercato in gruppi più piccoli e omogenei. Questa pratica consente alle aziende di adattare le proprie strategie e i propri messaggi alle caratteristiche specifiche di ciascun segmento, migliorando così l'efficacia delle tue campagne. Il targeting può essere basato su criteri demografici, psicografico, geografico o comportamentale, facilitando una comunicazione più pertinente e personalizzata con il pubblico di destinazione...., regressione, rilevamento di oggetti, Encoder automatici. Admite el apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute... supervisado y no supervisado de imágenes, series de tiempo, texto y algunos tipos más de datos. Pero DeepDetect depende de bibliotecas externas de aprendizaje automático como:
- Bibliotecas de aprendizaje profundo: Tensorflow, Caffè2, Torch.
- Biblioteca de aumento de gradienteGradiente è un termine usato in vari campi, come la matematica e l'informatica, per descrivere una variazione continua di valori. In matematica, si riferisce al tasso di variazione di una funzione, mentre in progettazione grafica, Si applica alla transizione del colore. Questo concetto è essenziale per comprendere fenomeni come l'ottimizzazione negli algoritmi e la rappresentazione visiva dei dati, consentendo una migliore interpretazione e analisi in...: XGBoost.
- Agrupación con T-SNE.
Enlace de Github: https://github.com/jolibrain/deepdetect
6. Dopamina

Fonte: Google Immagini
La dopamina es un proyecto de código abierto del gigante tecnológico Google. Está escrito en Python. Es un marco de investigación para la creación rápida de prototipos de algoritmos de Apprendimento per rinforzoL'apprendimento per rinforzo è una tecnica di intelligenza artificiale che consente a un agente di imparare a prendere decisioni interagendo con un ambiente. Attraverso il feedback sotto forma di premi o punizioni, L'agente ottimizza il proprio comportamento per massimizzare le ricompense accumulate. Questo approccio viene utilizzato in una varietà di applicazioni, Dai videogiochi alla robotica e ai sistemi di raccomandazione, distinguendosi per la sua capacità di apprendere strategie complesse.....
Los principios de diseño de la dopamina son:
- Experimento sencillo: la dopamina facilita a los nuevos usuarios la realización de experimentos.
- Es compacto y confiable.
- También facilita la reproducibilidad de los resultados.
- Es flexible, così, facilita que los nuevos usuarios prueben nuevas ideas de investigación.
Nota: Mira estos Cuadernos Colaboratorios para aprender a usar la dopamina.
Enlace de Github: https://github.com/google/dopamine
7. TensorFlow

Fonte: Google Immagini
Tensorflow es el más famoso, popular y uno de los mejores proyectos de código abierto de aprendizaje automático en GitHub. Es una biblioteca de software de código abierto para el cálculo numérico utilizando gráficos de flujo de datos. Tiene una interfaz Python muy fácil de usar y no tiene interfaces no deseadas en otros lenguajes para construir y ejecutar gráficos computacionales. TensorFlow proporciona API estables de Python y C ++. Tensorflow tiene algunos casos de uso sorprendentes como:
- En reconocimiento de voz / suono
- Aplicaciones de bases de texto
- Riconoscimento delle immagini
- Detección de video
…¡y muchos más!
Collegamento GitHub: https://github.com/tensorflow/tensorflow
8. PredicciónIO

Fonte: Google Immagini
Está construido sobre una pila de código abierto de última generación. Este servidor de aprendizaje automático está diseñado para que los científicos de datos creen motores predictivos para cualquier tarea de aprendizaje automático. Algunas de sus características sorprendentes son:
- Ayuda a construir e implementar rápidamente un motor como un servicio web en plantillas de producción que son personalizables.
- Una vez implementado como servicio web, responda a consultas dinámicas en tiempo real.
- Admite bibliotecas de procesamiento de datos y aprendizaje automático como OpenNLP, Spark MLLib.
- También simplifica la gestión de la infraestructura de datos
Collegamento GitHub: https://github.com/apache/predictionio
9.Scikit-impara
Fonte: Google Immagini
Es una biblioteca de herramientas de aprendizaje automático de software libre basada en Python. Proporciona varios algoritmos para clasificación, regressione, algoritmos de agrupación en clústeres, incluidos bosques aleatorios, aumento del gradiente, DBSCAN. Esto se basa en SciPy que debe estar preinstalado para que pueda usar sci-kit learn. También proporciona modelos para:
- Métodos de conjunto
- Estrazione delle caratteristiche
- Ajuste de parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto....
- Aprendizaje múltiple
- Selezione delle funzioni
- Riduzione della dimensionalità
Nota: Para aprender scikit-learn, siga la documentación: https://scikit-learn.org/stable/
Collegamento GitHub: https://github.com/scikit-learn
10. Pylearn2
Pylearn2 es la biblioteca de aprendizaje automático más común entre todos los desarrolladores de Python. Está basado en Theano. Puede usar expresiones matemáticas para escribir su complemento mientras Theano toma o optimización y estabilización. Tiene algunas características asombrosas como:
- un “algoritmo de entrenamiento predeterminado” para entrenar el modelo en sí
-
- Criterios de estimación del modelo
-
- Puntuación coincidente
- Entropia incrociata
- Probabilidad logarítmica
- Preprocesamiento del conjunto de datos
- NormalizzazioneLa standardizzazione è un processo fondamentale in diverse discipline, che mira a stabilire norme e criteri uniformi per migliorare la qualità e l'efficienza. In contesti come l'ingegneria, Istruzione e amministrazione, La standardizzazione facilita il confronto, Interoperabilità e comprensione reciproca. Nell'attuazione degli standard, si promuove la coesione e si ottimizzano le risorse, che contribuisce allo sviluppo sostenibile e al miglioramento continuo dei processi.... de contraste
- Blanqueamiento ZCA
- Extracción de parches (para implementar algoritmos de tipo convolución)
Collegamento GitHub: https://github.com/lisa-lab/pylearn2
Note finali:
Contribuir al código abierto conlleva demasiados pros. Quindi, estos son algunos buenos proyectos de código abierto para contribuir.
Grazie per aver letto se sei arrivato qui 🙂
Connettiamoci LinkedIn.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





