Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati.
La guía es principalmente para principiantes, y trataré de definir y enfatizar los temas tanto como pueda. Dado que el apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute... es un tema muy grande, dividiría todo el tutorial en pocas partes. Asegúrese de leer las otras partes si encuentra útil esta.
Contenuto
1. introduzione
- Cos'è l'apprendimento profondo??
- ¿Por qué Deep Learning?
- ¿Qué cantidad de datos es grande?
- Campos donde se utiliza el aprendizaje profundo
- Diferencia entre Deep Learning y Machine Learning
2) Importa le librerie richieste
3) Riepilogo
4) Regressione logistica
- Grafo computacional
- Inicializando parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto....
- Spread a termine
- Optimización con Gradient Descent
5) Regresión logística con Sklearn
6) Note finali
introduzione
Cos'è l'apprendimento profondo??
- Es un subcampo del aprendizaje automático, inspirado en las neuronas biológicas del cerebro y traduciéndolo a redes neuronales artificiales con aprendizaje de representación.
¿Por qué el aprendizaje profundo?
- Cuando aumenta el volumen de datos, las técnicas de aprendizaje automático, sin importar cuán optimizadas sean, comienzan a volverse ineficientes en términos de rendimiento y precisión, mientras que el aprendizaje profundo funciona mucho mejor en tales casos.
¿Qué cantidad de datos es grande?
- Bene, no se puede cuantificar un umbral para que los datos se consideren grandes, ma, intuitivamente, digamos que una muestra de un millón podría ser suficiente para decir “Es grande” (aquí es donde Michael Scott habría pronunciado sus famosas palabras “Eso es lo que ella dijo”).
Campos donde se usa DL
- Classificazione delle immagini, riconoscimento vocale, PNL (elaborazione del linguaggio naturale), sistemi di raccomandazione, eccetera.
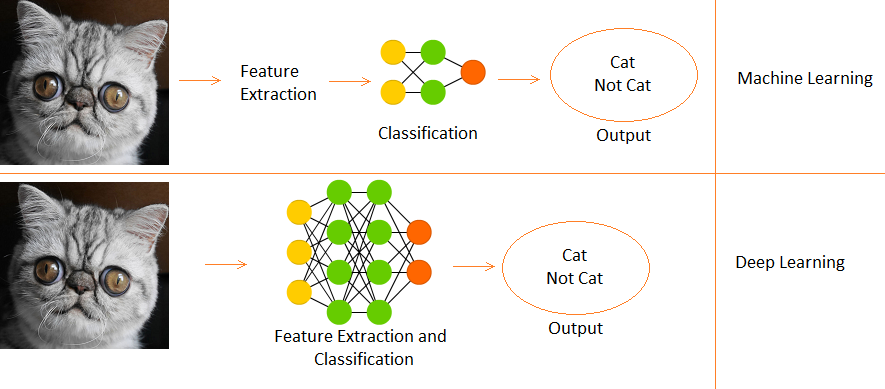
Diferencia entre aprendizaje profundo y aprendizaje automático
- El aprendizaje profundo es un subconjunto del aprendizaje automático.
- En Machine Learning, las funciones se proporcionan manualmente.
- Mientras que Deep Learning aprende funciones directamente de los datos.
Useremo il Conjunto de datos de dígitos en lenguaje de señas que está disponible en Kaggle qui. Ora cominciamo.
Importación de bibliotecas necesarias
importa numpy come np # linear algebra import pandas as pd # elaborazione dati, CSV file I/O (ad esempio. pd.read_csv) importa matplotlib.pyplot come plt # Input data files are available in the "../input/" directory. # import warnings import warnings # filter warnings warnings.filterwarnings('ignorare') from subprocess import check_output print(check_output(["ls", "../ingresso"]).decodificare("utf8")) # Any results you write to the current directory are saved as output.

Resumen de los datos
- Ci sono 2062 imágenes de dígitos en lenguaje de señas en este conjunto de datos.
- Dado que hay 10 dígitos del 0 al 9, ci sono 10 imágenes de señales únicas.
- All'inizio, solo usaremos 0 e 1 (para que sea simple para los estudiantes)
- En los datos, el signo de la mano para 0 está entre los índices 204 e 408. Ci sono 205 muestras para 0.
- Cosa c'è di più, el signo de la mano para 1 está entre los índices 822 e 1027. Ci sono 206 campioni.
- Perciò, noi useremo 205 muestras de cada clase (Nota: in realtà, 205 muestras son mucho menos para un modelo de Deep Learning adecuado, pero como se trata de un tutorial, podemos ignorarlo),
Ahora prepararemos nuestras matrices X e Y, donde X es nuestra matriz de imágenes (caratteristiche) e Y es nuestra matriz de etiquetas (0 e 1).
# load data set x_l = np.load('../input/Sign-language-digits-dataset/X.npy') Y_l = np.load('../input/Sign-language-digits-dataset/Y.npy') img_size = 64 plt.sottotrama(1, 2, 1) plt.imshow(x_l[260].rimodellare(img_size, img_size)) asse.plt('spento') plt.sottotrama(1, 2, 2) plt.imshow(x_l[900].rimodellare(img_size, img_size)) asse.plt('spento')
# Join a sequence of arrays along an row axis. # a partire dal 0 a 204 is zero sign and from 205 a 410 is one sign X = np.concatenate((x_l[204:409], x_l[822:1027] ), asse=0) z = np.zeros(205) o = np.ones(205) Y = np.concatenate((Insieme a, oh), asse=0).rimodellare(X.forma[0],1) Stampa("X shape: " , X.forma) Stampa("Y shape: " , Y.shape)

Para crear nuestra matriz X, primero dividimos y concatenamos nuestros segmentos de imágenes de signos de mano de 0 e 1 del conjunto de datos a la matriz X. Prossimo, hacemos algo similar con Y, pero usamos las etiquetas en su lugar.
1) Entonces vemos que la forma de nuestra matriz X es (410, 64, 64)
- Il 410 significa 205 immagini di 0, 205 immagini di 1.
- il 64 significa que el tamaño de nuestras imágenes es de 64 X 64 pixel.
2) La forma de Y es (410,1), così, 410 unos y ceros.
3) Ahora dividimos X e Y en trenes y conjuntos de prueba.
- tren = 75%, tren = 15%
- random_state = Utiliza una semilla en particular mientras se aleatoriza, così, si la celda se ejecuta varias veces, el número aleatorio generado no cambia cada vez. La misma distribución de prueba y tren se crea cada vez.
# Then lets create x_train, y_train, x_test, y_test arrays from sklearn.model_selection import train_test_split X_train, X_test, Y_train, Y_test = train_test_split(X, E, test_size=0.15, random_state=42) number_of_train = X_train.shape[0] number_of_test = X_test.shape[0]
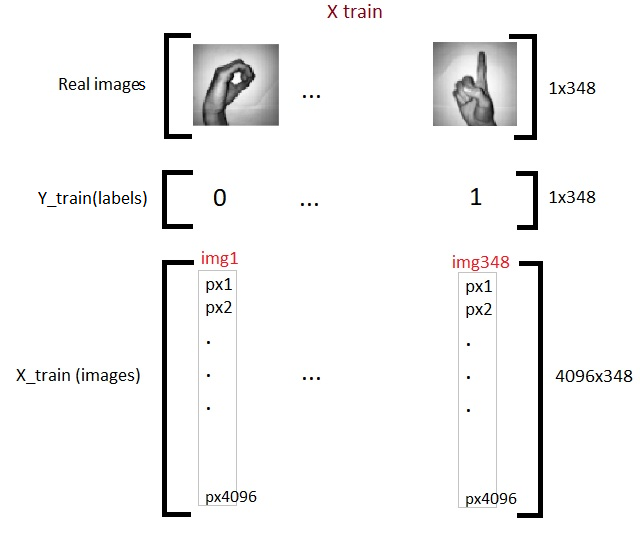
Tenemos una matriz de entrada tridimensional, por lo que tenemos que aplanarla a 2D para alimentar nuestro primer modelo de aprendizaje profundo. Como y ya es 2D, lo dejamos tal como está.
X_train_flatten = X_train.reshape(number_of_train,X_train.shape[1]*X_train.shape[2]) X_test_flatten = X_test .reshape(number_of_test,X_test.shape[1]*X_test.shape[2]) Stampa("X train flatten",X_train_flatten.shape) Stampa("X test flatten",X_test_flatten.shape)

Ahora tenemos un total de 348 immagini, cada una con 4096 píxeles en la matriz de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... X. E 62 imágenes de la misma densidad de píxeles 4096 en la matriz de prueba. Ahora transponemos las matrices. Esta es solo una elección personal y verá en los próximos códigos por qué lo digo.
x_train = X_train_flatten.T x_test = X_test_flatten.T y_train = Y_train.T y_test = Y_test.T print("x_treno: ",x_train.shape) Stampa("x_test: ",x_test.shape) Stampa("y_train: ",y_train.shape) Stampa("y_test: ",y_test.shape)

Así que ahora hemos terminado con la preparación de nuestros datos requeridos. Así es como se ve:
Ahora nos familiarizaremos con uno de los modelos básicos de Dl, llamado Regresión logística.
Regressione logistica
Cuando se habla de clasificación binaria, el primer modelo que me viene a la mente es la regresión logística. Pero uno podría preguntarse ¿cuál es el uso de la regresión logística en el aprendizaje profundo? La risposta è semplice, ya que la regresión logística es una neuronale rossoLe reti neurali sono modelli computazionali ispirati al funzionamento del cervello umano. Usano strutture note come neuroni artificiali per elaborare e apprendere dai dati. Queste reti sono fondamentali nel campo dell'intelligenza artificiale, consentendo progressi significativi in attività come il riconoscimento delle immagini, Elaborazione del linguaggio naturale e previsione delle serie temporali, tra gli altri. La loro capacità di apprendere schemi complessi li rende strumenti potenti.. semplice. Los términos red neuronal y aprendizaje profundo van de la mano. Para comprender la regresión logística, primero tenemos que aprender acerca de las gráficas computacionales.
Gráfico de cálculo
Los gráficos computacionales pueden considerarse una forma pictórica de representar expresiones matemáticas. Entendamos eso con un ejemplo. Supongamos que tenemos una expresión matemática simple como:
c = ( un2 + B2 ) 1/2
Su gráfico computacional será:
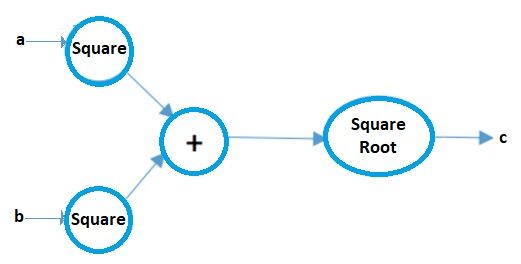
Fonte immagine: Autore
Ahora veamos un gráfico computacional de regresión logística:
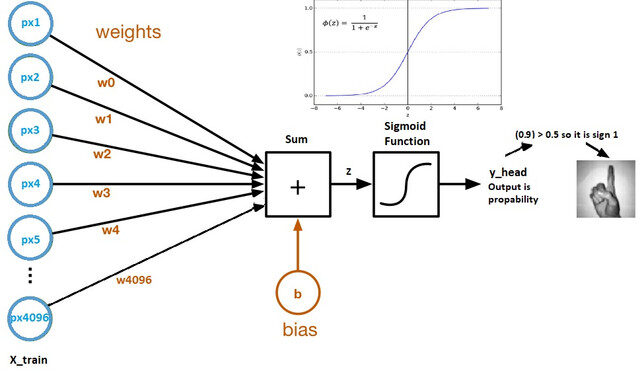
Fonte immagine: Set di dati Kaggle
- Los pesos y el sesgo se denominan parámetros del modelo.
- Los pesos representan los coeficientes de cada píxel.
- El sesgo es la intersección de la curva formada al trazar parámetros frente a etiquetas.
- Z = (px1 * wx1) + (px2 * wx2) +…. + (px4096 * wx4096)
- y_head = sigmoid_funtion (INSIEME A)
- Lo que hace la función sigmoidea es esencialmente escalar el valor de Z entre 0 e 1, por lo que se convierte en una probabilidad.
¿Por qué utilizar la función sigmoidea?
- Nos da un resultado probabilístico.
- Dado que es un derivado, podemos usarlo en el algoritmo de descenso de gradienteGradiente è un termine usato in vari campi, come la matematica e l'informatica, per descrivere una variazione continua di valori. In matematica, si riferisce al tasso di variazione di una funzione, mentre in progettazione grafica, Si applica alla transizione del colore. Questo concetto è essenziale per comprendere fenomeni come l'ottimizzazione negli algoritmi e la rappresentazione visiva dei dati, consentendo una migliore interpretazione e analisi in....
Ahora examinaremos en detalle cada uno de los componentes del gráfico computacional anterior.
Parámetros de inicialización
Fonte immagine: Documentos de Microsoft
Cada píxel tiene su propio peso. Pero la pregunta es ¿cuáles serán sus pesos iniciales? Hay varias técnicas para hacer eso que cubriré en la parte 2 de este artículo, Ma per ora, podemos inicializarlas usando cualquier valor aleatorio, Diciamo 0.01.
La forma de la matriz de pesos será (4096, 1), ya que hay un total de 4096 píxeles por imagen, y deje que el sesgo inicial sea 0.
# lets initialize parameters # So what we need is dimension 4096 that is number of pixels as a parameter for our initialize method(def) def initialize_weights_and_bias(dimensione): w = np.full((dimensione,1),0.01) b = 0.0 return w, B
w,b = initialize_weights_and_bias(4096)
Spread a termine
Todos los pasos desde los píxeles hasta la función de coste se denominan propagación hacia adelante.
Para calcular Z usamos la fórmula: Z = (wT) X + B. donde x es la matriz de píxeles, w pesos y b es el sesgo. Después de calcular Z, lo introducimos en la función sigmoidea que devuelve y_head (probabilità). Successivamente, calculamos la Funzione di perditaLa funzione di perdita è uno strumento fondamentale nell'apprendimento automatico che quantifica la discrepanza tra le previsioni del modello e i valori effettivi. Il suo obiettivo è quello di guidare il processo di formazione minimizzando questa differenza, consentendo così al modello di apprendere in modo più efficace. Esistono diversi tipi di funzioni di perdita, come l'errore quadratico medio e l'entropia incrociata, ognuno adatto a compiti diversi e... (errore).
La función de costo es la suma de todas las pérdidas y penaliza al modelo por las predicciones incorrectas. Así es como nuestro modelo aprende los parámetros.
# calculation of z #z = np.dot(w.T,x_treno)+b def sigmoid(Insieme a): y_head = 1/(1+np.exp(-Insieme a)) return y_head
y_head = sigmoid(0) y_head > 0.5
La expresión matemática de la función de pérdida (tronco d'albero) è:
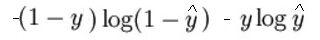
Come ho detto prima, lo que esencialmente hace la función de pérdida es penalizar las predicciones incorrectas. aquí está el código para la propagación hacia adelante:
# Forward propagation steps: # find z = w.T*x+b # y_head = sigmoid(Insieme a) # perdita(errore) = loss(e,y_head) # cost = sum(perdita) def forward_propagation(w,B,x_treno,y_train): z = np.dot(w.T,x_treno) + b y_head = sigmoid(Insieme a) # probabilistic 0-1 loss = -y_train*np.log(y_head)-(1-y_train)*np.log(1-y_head) cost = (np.sum(perdita))/x_train.shape[1] # x_train.shape[1] is for scaling return cost
Optimización con Gradient Descent
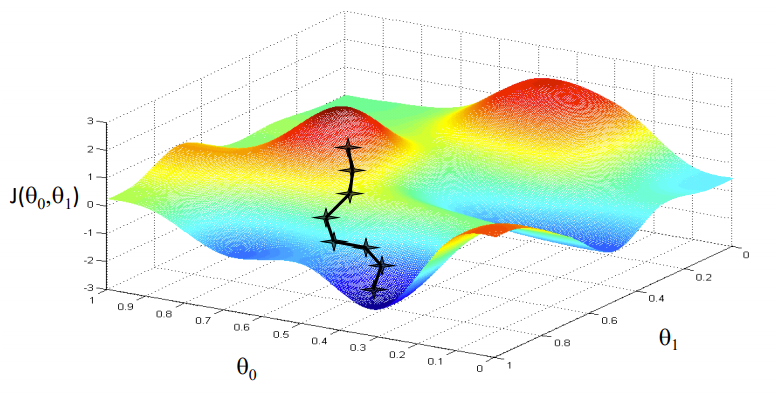
Fonte immagine: Coursera
Nuestro objetivo es encontrar los valores de nuestros parámetros para los cuales, la función de pérdida es el mínimo. La ecuación para el descenso de gradientes es:
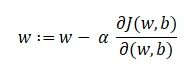
Donde w es el peso o el parámetro. La letra griega alfa es algo llamado tamaño escalonado. Lo que significa es el tamaño de las iteraciones que tomaremos mientras bajamos la pendiente para encontrar los mínimos locales. Y el resto es la derivada de la función de pérdida, también conocida como gradiente. El algoritmo para el descenso de gradientes es simple:
- Primo, tomamos un punto de datos aleatorio en nuestro gráfico y encontramos su pendiente.
- Luego encontramos la dirección en la que disminuye la función de pérdida de valor.
- Actualice los pesos usando la fórmula anterior. (Este método también se llama retropropagación)
- Seleccione el siguiente punto tomando un tamaño de α.
- Ripetere.
# In backward propagation we will use y_head that found in forward progation # Therefore instead of writing backward propagation method, lets combine forward propagation and backward propagation def forward_backward_propagation(w,B,x_treno,y_train): # forward propagation z = np.dot(w.T,x_treno) + b y_head = sigmoid(Insieme a) loss = -y_train*np.log(y_head)-(1-y_train)*np.log(1-y_head) cost = (np.sum(perdita))/x_train.shape[1] # x_train.shape[1] is for scaling # backward propagation derivative_weight = (np.dot(x_treno,((y_head-y_train).T)))/x_train.shape[1] # x_train.shape[1] is for scaling derivative_bias = np.sum(y_head-y_train)/x_train.shape[1] # x_train.shape[1] is for scaling gradients = {"derivative_weight": derivative_weight,"derivative_bias": derivative_bias} return cost,gradienti
Ahora actualizamos los parámetros de aprendizaje:
# Updating(learning) parameters def update(w, B, x_treno, y_train, tasso_di_apprendimento,number_of_iterarion): cost_list = [] cost_list2 = [] indice = [] # aggiornamento(learning) parameters is number_of_iterarion times for i in range(number_of_iterarion): # make forward and backward propagation and find cost and gradients cost,gradients = forward_backward_propagation(w,B,x_treno,y_train) cost_list.append(costo) # lets update w = w - tasso_di_apprendimento * gradienti["derivative_weight"] b = b - tasso_di_apprendimento * gradienti["derivative_bias"] se io % 10 == 0: cost_list2.append(costo) index.append(io) Stampa ("Cost after iteration %i: %F" %(io, costo)) # we update(imparare) parameters weights and bias parameters = {"weight": w,"Pregiudizio": B} plt.trama(indice,cost_list2) plt.xticks(indice,rotation='vertical') plt.xlabel("Number of Iterarion") plt.ylabel("Costo") plt.mostra() return parameters, gradienti, cost_list
parametri, gradienti, cost_list = update(w, B, x_treno, y_train, learning_rate = 0.009,number_of_iterarion = 200)
Finora, aprendimos nuestros parámetros. Significa que estamos ajustando los datos. En el paso de predicción, tenemos x_test como entrada y usándolo, hacemos predicciones hacia adelante.
# prediction def predict(w,B,x_test): # x_test is a input for forward propagation z = sigmoid(np.dot(w.T,x_test)+B) Y_prediction = np.zeros((1,x_test.shape[1])) # if z is bigger than 0.5, our prediction is sign one (y_head=1), # if z is smaller than 0.5, our prediction is sign zero (y_head=0), per io nel raggio d'azione(z.shape[1]): if z[0,io]<= 0.5: Y_prediction[0,io] = 0 altro: Y_prediction[0,io] = 1 return Y_prediction
prevedere(parametri["weight"],parametri["Pregiudizio"],x_test)
Ahora hacemos nuestras predicciones. Pongámoslo todo junto:
def logistic_regression(x_treno, y_train, x_test, y_test, tasso_di_apprendimento , num_iterations): # initialize dimension = x_train.shape[0] # questo è 4096 w,b = initialize_weights_and_bias(dimensione) # do not change learning rate parameters, gradienti, cost_list = update(w, B, x_treno, y_train, tasso_di_apprendimento,num_iterations) y_prediction_test = predict(parametri["weight"],parametri["Pregiudizio"],x_test) y_prediction_train = predict(parametri["weight"],parametri["Pregiudizio"],x_treno) # Print train/test Errors print("train accuracy: {} %".formato(100 - np.significa(np.abs(y_prediction_train - y_train)) * 100)) Stampa("test accuracy: {} %".formato(100 - np.significa(np.abs(y_prediction_test - y_test)) * 100)) logistic_regression(x_treno, y_train, x_test, y_test,tasso_di_apprendimento = 0.01, num_iterations = 150)
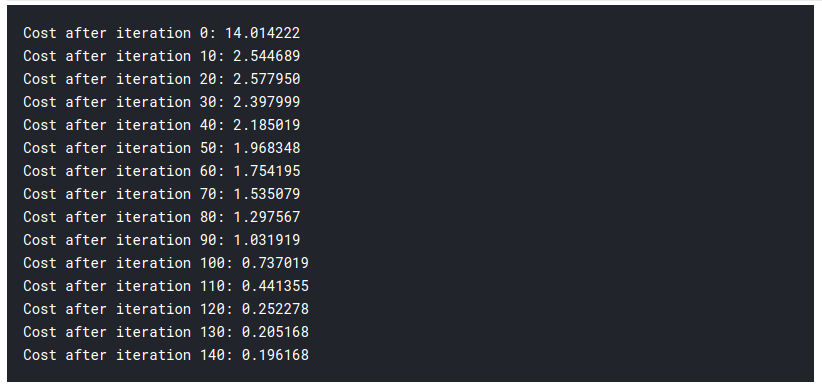
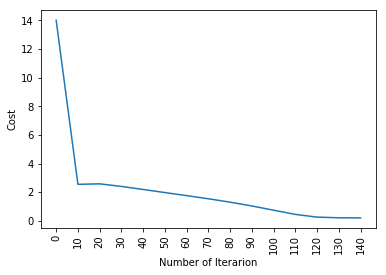

Quindi, come potete vedere, incluso el modelo más fundamental de aprendizaje profundo es bastante difícil. No es fácil para ti aprender, y los principiantes a veces pueden sentirse abrumados al estudiar todo esto de una vez. Pero la cuestión es que aún no hemos tocado el aprendizaje profundo, esto es como la superficie. Hay mucho más que agregaré en la parte 2 de este artículo.
Dado que hemos aprendido la lógica detrás de la regresión logística, podemos usar una biblioteca llamada SKlearn que ya tiene muchos de los modelos y algoritmos incorporados, por lo que no tiene que comenzar todo desde cero.
Regresión logística con Sklearn

No voy a explicar mucho en esta sección ya que conoces casi toda la lógica y la intuición detrás de la regresión logística. Si está interesado en leer sobre la biblioteca de Sklearn, puede leer la documentación oficial qui. Ecco il codice, y estoy seguro de que se quedará atónito al ver el poco esfuerzo que requiere:
from sklearn import linear_model logreg = linear_model.LogisticRegression(random_state = 42,max_iter= 150) Stampa("test accuracy: {} ".formato(logreg.fit(x_train.T, y_train.T).punto(x_test.T, y_test.T))) Stampa("train accuracy: {} ".formato(logreg.fit(x_train.T, y_train.T).punto(x_train.T, y_train.T)))

sì! esto es todo lo que se necesitó, ¡solo 1 línea de código!
Note finali
Hemos aprendido mucho hoy. Pero esto es solo el principio. Asegúrese de consultar la parte 2 de este artículo. Puede encontrarlo en el siguiente enlace. Si le gusta lo que lee, puede leer algunos de los otros artículos interesantes que he escrito.
Sion | Autor en DataPeaker
Espero que hayas pasado un buen rato leyendo mi artículo. Salute!!
I media mostrati in questo articolo sulle migliori librerie di machine learning in Julia non sono di proprietà di DataPeaker e vengono utilizzati a discrezione dell'autore.





