R lucido … R lucido – Satya Nadella
introduzione:
R lucido, R lucido, R lucido.
Convenzionalmente, R lucido. R lucido.
Quindi, R lucido? sì, R lucido.

fonte: R lucido
Le applicazioni di dati facilitano gli esperti in materia, i responsabili delle decisioni aziendali o i consumatori interagiscono con i dati, grandi e piccoli.
Si differenziano dai report di BI statici in quanto offrono un'interazione ad hoc attraverso un'interfaccia intuitiva su misura per il caso d'uso specifico. También se diferencian de la analiticoL'analisi si riferisce al processo di raccolta, Misura e analizza i dati per ottenere informazioni preziose che facilitano il processo decisionale. In vari campi, come business, Salute e sport, L'analisi può identificare modelli e tendenze, Ottimizza i processi e migliora i risultati. L'utilizzo di strumenti avanzati e tecniche statistiche è fondamentale per trasformare i dati in conoscenze applicabili e strategiche.... automatizada impulsada por el aprendizaje automático, dal momento che sono progettati per “umano in ciclo” al contrario del processo decisionale automatizzato.
Questo li rende perfetti per analisi che richiedono una combinazione di dati e intuizione.. Queste app semplificano la ricerca e l'esplorazione dei dati. L'indagine sui dati avviene in reazione a un evento o un'anomalia specifici.
L'utente combina i dati degli eventi con altre origini dati e dati storici per identificare la causa principale e agire. Questo porta a centinaia o migliaia di piccole intuizioni che insieme fanno una grande differenza..
Ci sono diverse biblioteche sia in R (Brillante) come in pitone (Plotly Dash, Streamlit, Onda, eccetera.) per creare applicazioni dati.
In questo articolo, esploreremo come Shiny R può essere utilizzato per creare un'applicazione che consenta all'utente di suddividere il set di dati in training / Tentativo, costruire più modelli, generare metriche del modello, visualizzare il risultato e prendere la decisione al volo.
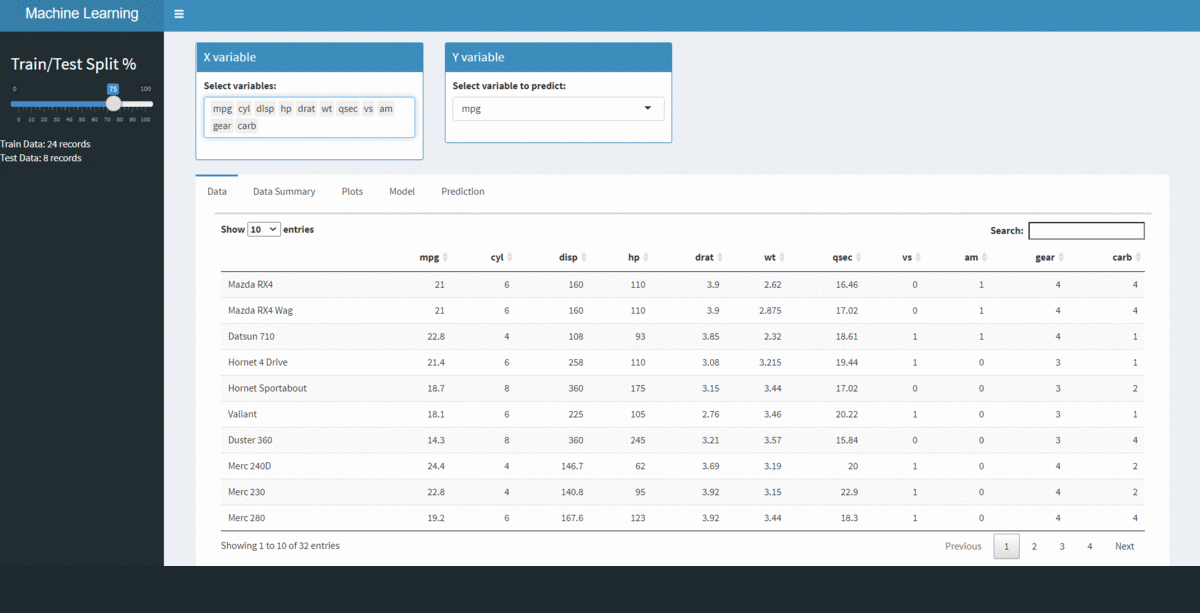
Alla fine di questo articolo, creeremo la seguente applicazione. Nota le varie schede sulla home page.
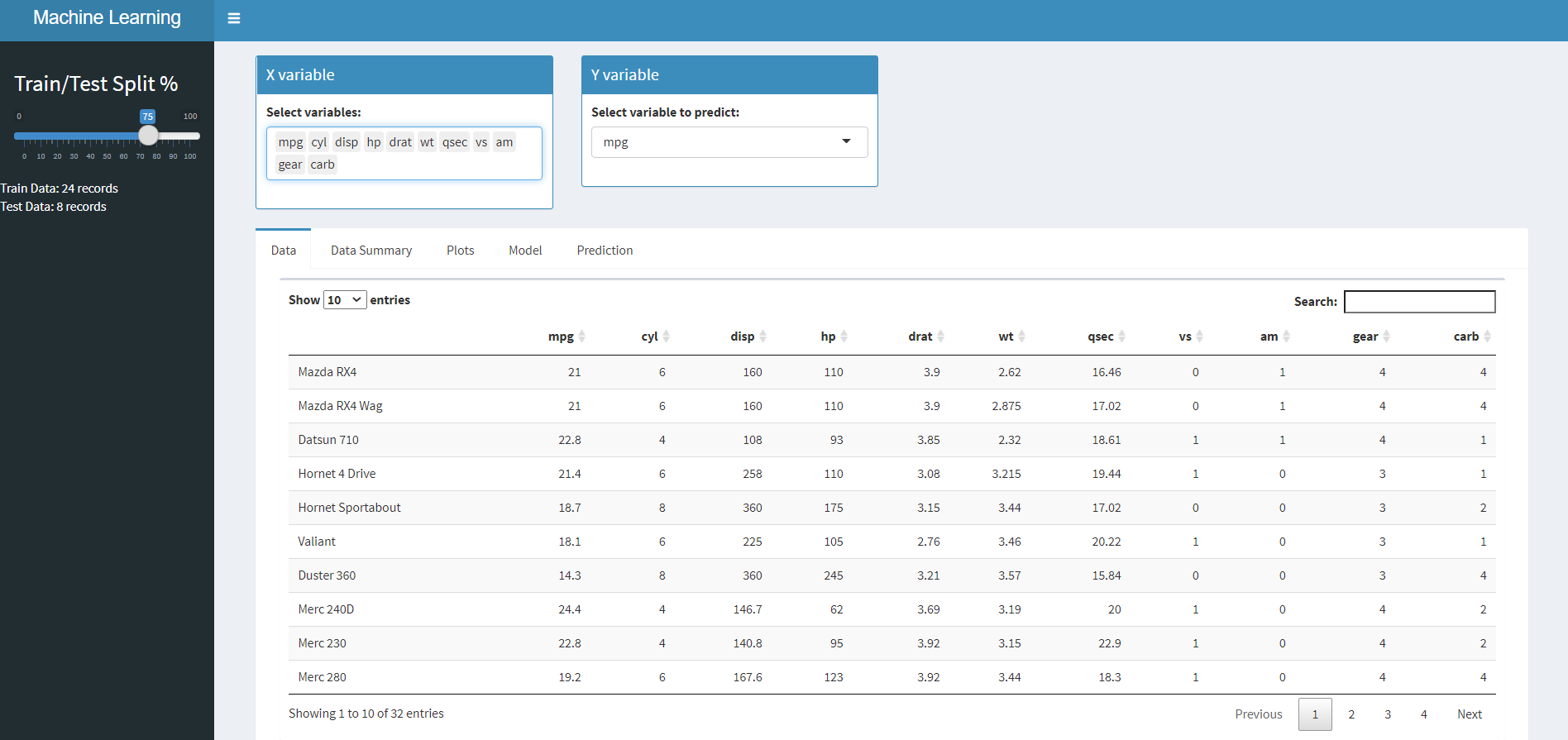
Di partenza:
Noi useremo mtcars set di dati per questa applicazione. Dopo aver testato e assicurato che l'interfaccia utente e le funzionalità del server funzionino come previsto, possiamo modificare il set di dati e l'app dovrebbe funzionare altrettanto bene con un'elaborazione minima dei dati, se necessario.
Primo, installiamo il lucido e carichiamolo. L'app Shiny ha principalmente due file, un'interfaccia utente e un server:
install.packages("brillante")
biblioteca("brillante")
Interfaccia utente (interfaccia utente):
Qui è dove definisci il tuo design: MarcatoriIl "Marcatori" sono strumenti linguistici utilizzati per guidare la struttura e il flusso di un testo. La sua funzione principale è quella di evidenziare le relazioni tra le idee, come aggiunta, contrasto o causa ed effetto. Esempi comuni includono "Cosa c'è di più", "tuttavia" e "così". Questi elementi non solo migliorano la coesione della scrittura, ma anche facilitare la comprensione del lettore, rendere i contenuti più accessibili e chiari.... de posición que se completarán en el tiempo de ejecución a partir de los datos / grafica resa dal server.
server:
Qui è dove scrivi la maggior parte della logica, discussione sui dati, lo schema, eccetera. La maggior parte del lavoro pesante viene svolto qui.
Aggiungiamo i due campi a tendina, uno per le variabili indipendenti e l'altro per selezionare l'obiettivo.
cruscottoCorpo(
fluidPage(
scatola(
selezionare Input(
"Seleziona X",
etichetta = "Seleziona le variabili:",
scelte = nomi(mtcars),
multiplo = VERO,
selezionato = nomi(mtcars)
),
solidHeader = VERO,
larghezza = "3",
stato = "primario",
titolo = "variabile X"
),
scatola(
selezionare Input("Seleziona Y", etichetta = "Seleziona la variabile da prevedere:", scelte = nomi(mtcars)),
solidHeader = VERO,
larghezza = "3",
stato = "primario",
titolo = "e variabile"
)
Prossimo, agregaremos un control deslizante en el pannelloUn panel è un gruppo di esperti che si riunisce per discutere e analizzare un argomento specifico. Questi forum sono comuni alle conferenze, seminari e dibattiti pubblici, dove i partecipanti condividono le loro conoscenze e prospettive. I pannelli possono riguardare una varietà di aree, Dalla scienza alla politica, e il suo obiettivo è quello di favorire lo scambio di idee e la riflessione critica tra i partecipanti.... lateral para dividir el conjunto de datos para entrenar y probar según la selección del usuario.
dashboard Barra laterale(
sliderInput(
"Dispositivo di scorrimento1",
etichetta = h3("Divisione treno/prova %"),
min = 0,
massimo = 100,
valore = 75
),
textOutput("cntTrain"),
textOutput("cntTest"),
Ora, creeremo diverse schede, ognuno dei quali ha una funzionalità specifica come dettagliato di seguito:
Dati – Per visualizzare i dati grezzi in forma tabellare,
Riepilogo dati – Vedi le statistiche di base del nostro set di dati.
rate – In questo caso, creeremo un solo grafico di correlazione, ma se necessario è possibile aggiungere elementi grafici più pertinenti.
Modello – Costruisci un modello di regressione lineare basato sulla selezione dell'utente di variabili X, Y y divisiones de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... / prova
Predizione – Pronostica sul set di prova.
fluidPage(
tabBox(
id = "scheda 1",
altezza = "1000px",
larghezza = 12,
tabPannello("Dati",
scatola(con Spinner(Uscita DT(
"Dati"
)), larghezza = 12)),
tabPannello(
"Riepilogo dati",
scatola(con Spinner(verbatimTextOutput("Somm")), larghezza = 6),
scatola(con Spinner(verbatimTextOutput("Summ_old")), larghezza = 6)
),
tabPannello("Trame",
scatola(con Spinner(plotOutput(
"Corr"
)), larghezza = 12)),
#scatola(con Spinner(verbatimTextOutput("Corr Matrix")), larghezza = 12),
tabPannello(
"Modello",
scatola(
con Spinner(verbatimTextOutput("Modello")),
larghezza = 6,
titolo = "Riepilogo del modello"
),
scatola(
con Spinner(verbatimTextOutput("ImpVar")),
larghezza = 5,
titolo = "Importanza variabile"
)
),
#textOutput("correlazione_accuratezza"),
tabPannello(
"Predizione",
scatola(con Spinner(plotOutput("Predizione")), larghezza = 6, titolo = "Linea Best Fit"),
scatola(con Spinner(plotOutput("trame residue")), larghezza = 6, titolo = "Grafici diagnostici")
)
)
Ora che abbiamo creato la nostra interfaccia utente, si procederà all'implementazione della logica del server per popolare l'interfaccia utente in base alla selezione dell'utente: interattività.
Compilazione della scheda dati: Usiamo il dataframe mtcars e lo memorizziamo in un oggetto per nome InputDataset e quindi riempire l'interfaccia utente utilizzando renderDT () funzione.
Nota l'uso di parentesi graffe alla fine dell'oggetto InputDataset (). Questo viene fatto perché è un oggetto reattivo, il che significa che qualsiasi modifica a questo oggetto avrà un impatto altrove in cui è referenziato nell'applicazione.
InputDataset <- reattivo({
mtcars
})
output$Dati <- renderDT(InputDataset())
su linee simili, Puoi usare astratto() e correlazione funzione per completare il riepilogo e la correlazione dei dati trama tab. È possibile accedere al codice lato server da GitHub
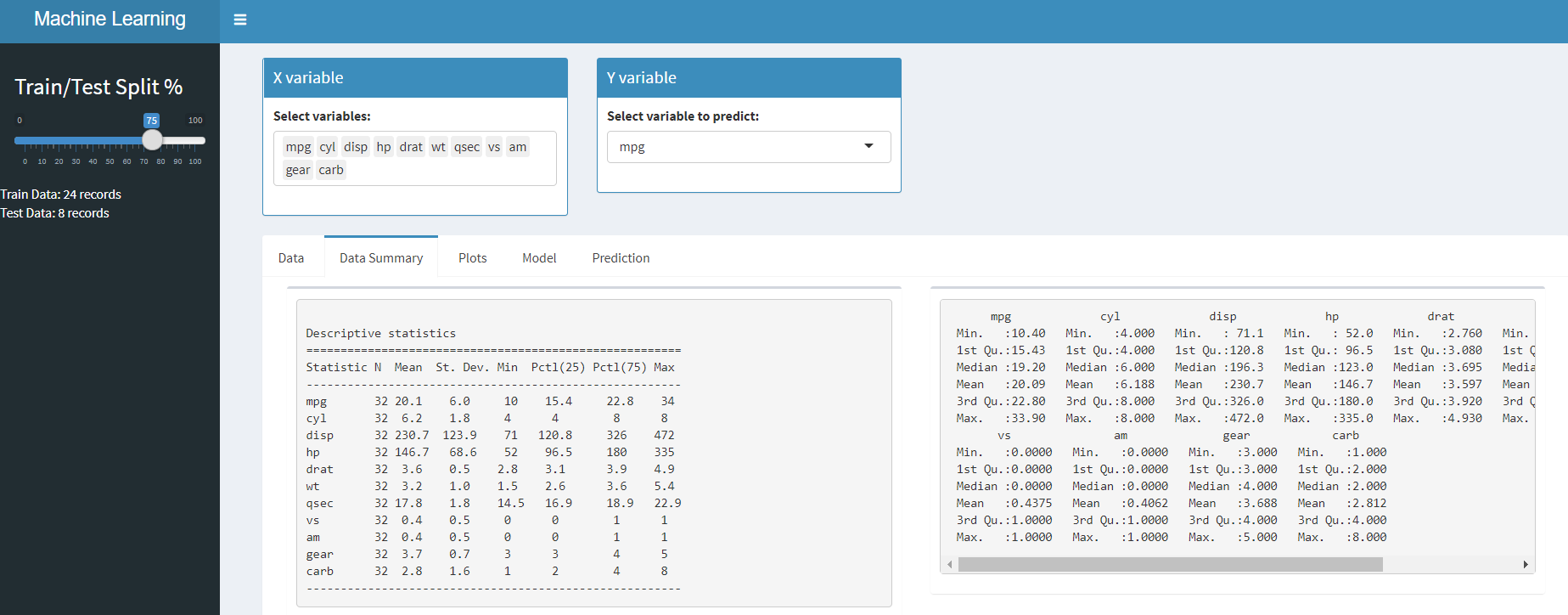
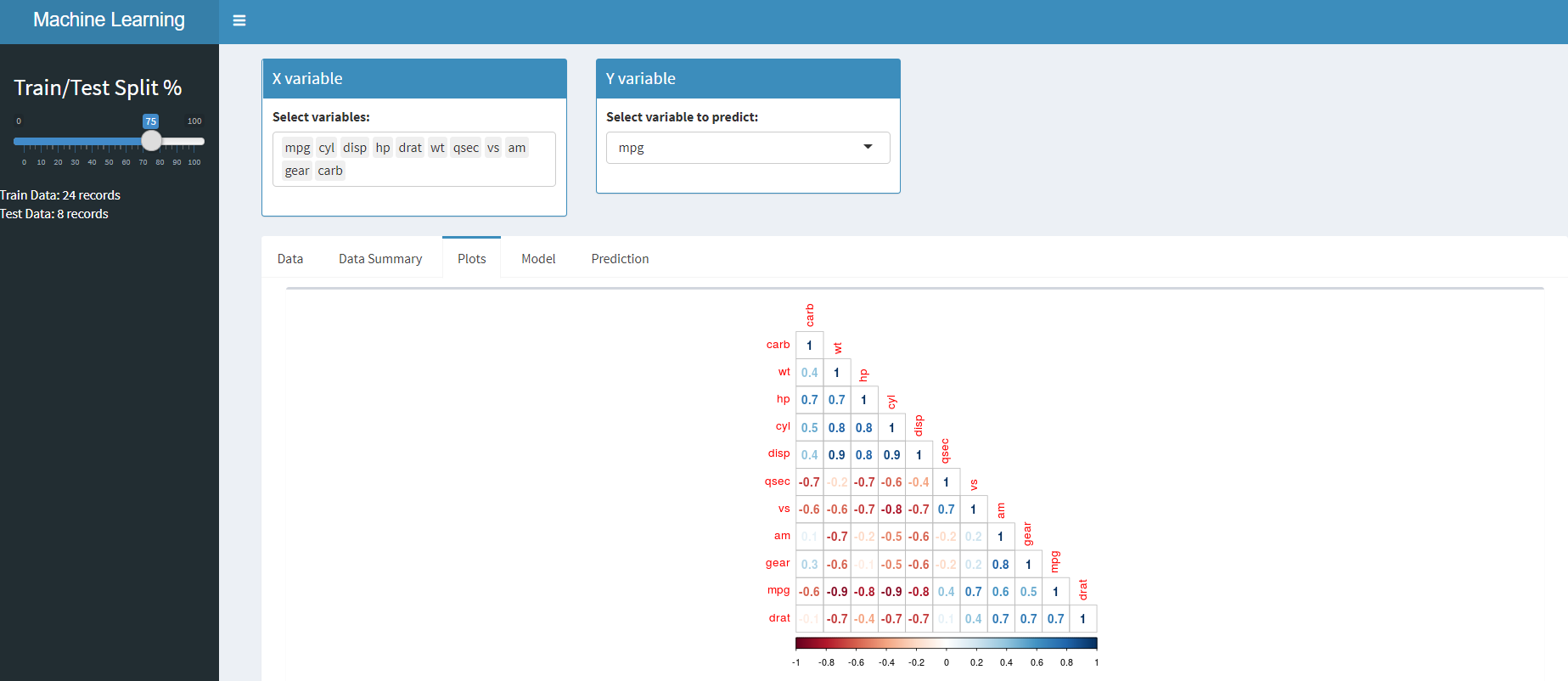
Ora che abbiamo visto come completare i dati, costruiamo un modello di regressione lineare e vediamo anche l'importanza delle variabili.
F <- reattivo({
come.formula(impasto(inserisci$SelezionaY, "~."))
})
Modello_Lineare <- reattivo({
lm(F(), dati = trainingData())
})
output$Modello <- renderPrint(riepilogo(Modello_Lineare()))
output$Model_new <-
renderPrint(
Osservatore di stelle(
Modello_Lineare(),
tipo = "testo",
titolo = "Risultati del modello",
cifre = 1,
fuori = "tabella1.txt"
)
)
tmpImp <- reattivo({
#varImp(Modello_Lineare())
imp <- as.data.frame(varImp(Modello_Lineare()))
imp <- data.frame(complessivo = imp$Complessivo,
nomi = nomi di riga(imp))
imp[ordine(imp$ nel complesso, decrescente = T),]
})
output$Var <- renderPrint(tmpImp())
Implementiamo la logica per il predizione scheda in cui utilizzeremo il nostro modello della sezione precedente per prevedere il set di dati del test e anche generare grafici residui.
current_preds <-
reattivo({
data.frame(cbind(corrente = tmp(), previsto = prezzo_predetto()))
})
In forma <-
reattivo({
(
complotto(
current_preds()$attuale,
current_preds()$previsto,
pch = 16,
cex = 1.3,
col = "blu",
principale = "Linea Best Fit",
xlab = "Effettivo",
ylab = "Previsto"
)
)
})
output$Previsione <- renderPlot(In forma())
output$residualPlots <- renderPlot({
attraverso(mfrow = c(2, 2)) # Modificare il layout del pannello in 2 X 2
complotto(Modello_Lineare())
attraverso(mfrow = c(1, 1)) # Torna a 1 X 1
})
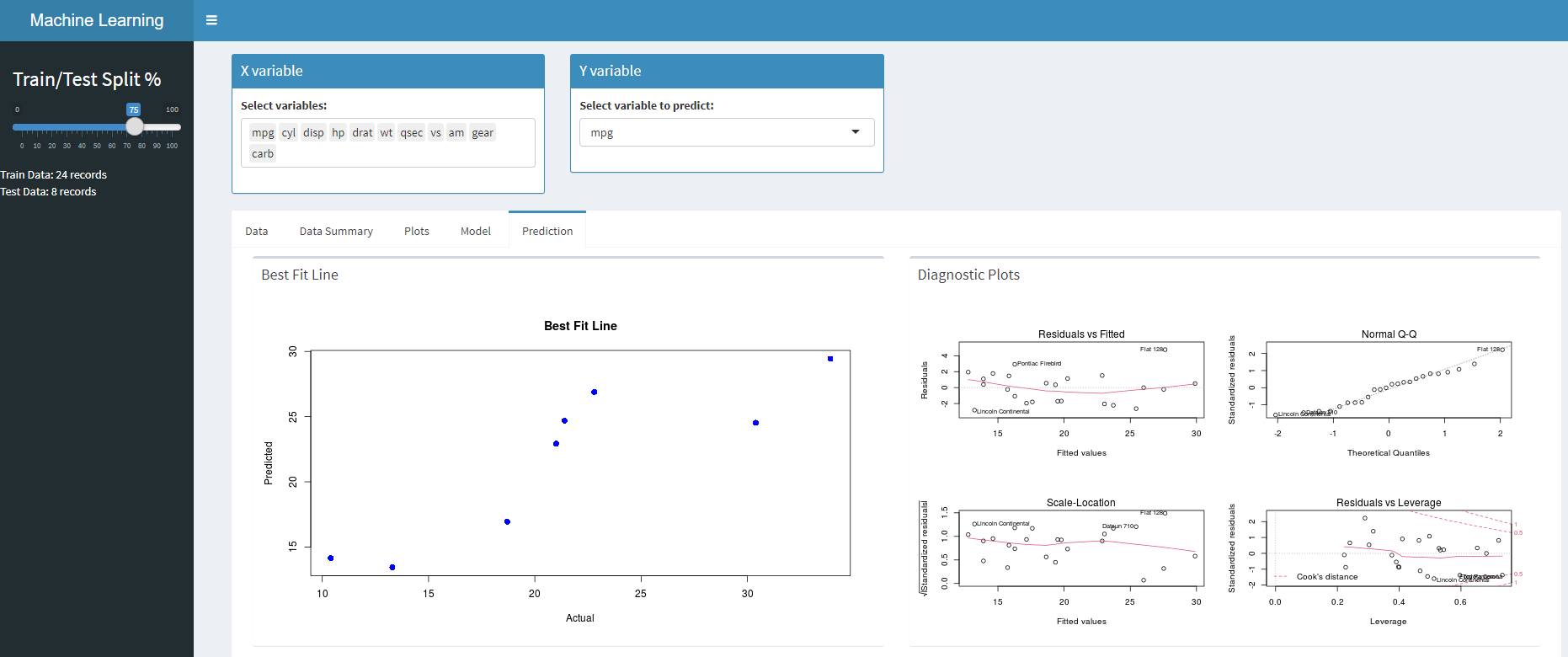
Puoi accedere al codice completo da GitHub. Dopo aver eseguito l'app, vedrai la home page caricata. Puoi navigare in varie sezioni, apportare modifiche alle variabili, creare modelli e prevedere anche in fase di test al volo seguendo i passaggi seguenti.

passo 1:
Seleziona la divisione dei dati del treno / test preferito nel pannello di sinistra.
passo 2:
Seleziona le variabili X e Y dai menu a discesa.
passo 3:
Passa alle rispettive schede per vedere il risultato:
conclusione:
L'obiettivo del blog era creare un'applicazione dati utilizzando R Shiny. Questa è stata un'implementazione molto semplice con tutti i controlli integrati.
Giusto per renderlo un po' più interessante, Ho scelto di portare un aspetto di creazione di modelli nell'app per mostrare come è possibile creare app basate su modelli in un breve lasso di tempo.
Insieme agli oggetti Shiny, puoi utilizzare gli elementi HTML per definire lo stile dei tuoi contenuti nella tua app.
Buon apprendimento !!!!
Puoi connetterti con me – Linkedin
Puoi trovare il codice di riferimento: Github
Riferimenti
https://shiny.rstudio.com/tutorial/
https://unsplash.com/
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





