introduzione
La manipulación de datos es una fase inevitable del modelado predictivo. Un modelo predictivo robusto no se puede construir simplemente utilizando algoritmos de aprendizaje automático. Ma, con un enfoque para comprender el problema empresarial, los datos subyacentes, realizar las manipulaciones de datos necesarias y luego extraer información empresarial.
Entre estas varias fases de la construcción de modelos, la mayor parte del tiempo se suele dedicar a comprender los datos subyacentes y realizar las manipulaciones necesarias. Este también sería el tema central de este artículo: paquetes para realizar una manipulación de datos más rápida en R.

¿Qué es la manipulación de datos?
Si todavía está confundido con este ‘término’, déjeme explicárselo. La manipulación de datos es un término que se utiliza de forma poco estricta con “Esplorazione dei dati”. Implica ‘manipular’ datos utilizando un conjunto de variables disponibles. Esto se hace para mejorar la exactitud y precisión asociadas con los datos.
In realtà, el proceso de recopilación de datos puede tener muchas lagunas. Hay varios factores incontrolables que conducen a la inexactitud en los datos, como la situación mental de los encuestados, sesgos personales, differenze / errores en las lecturas de las máquinas, eccetera. Para mitigar estas inexactitudes, se manipulan los datos para aumentar la precisión (massimo) posible en los datos.
Qualche volta, esta etapa también se conoce como disputa de datos o limpieza de datos.
Diferentes formas de manipular / tratar datos:
No existe una forma correcta o incorrecta de manipular los datos, siempre que los comprenda y haya tomado las acciones necesarias al final del ejercicio. tuttavia, aquí hay algunas formas generales en las que las personas intentan abordar la manipulación de datos. Aquí están:
- Generalmente, los principiantes en R se sienten cómodos manipular datos utilizando funciones de base R incorporadas. Este es un buen primer paso, pero a menudo es repetitivo y requiere mucho tiempo. Perciò, es una forma menos eficiente de resolver el problema.
- Uso de paquetes para manipulación de datos. CRAN tiene más de 7000 paquetes disponibles en la actualidad. In parole semplici, estos paquetes no son más que una colección de códigos preescritos de uso común. Le ayudan a realizar las tareas repetitivas en ayunas, reducen los errores en la codificación y reciben la ayuda del código escrito por expertos (en todo el ecosistema de código abierto para R) para hacer que su código sea más eficiente. Esta suele ser la forma más común de realizar la manipulación de datos.
- Uso de algoritmos ML para manipulación de datos. Puede utilizar algoritmos de refuerzo basados en árboles para ocuparse de los datos faltantes y los valores atípicos. Si bien estos definitivamente requieren menos tiempo, estos enfoques generalmente lo dejan con ganas de una mejor comprensión de los datos al final.
Perciò, la mayoría de las veces, el uso de paquetes es el método de facto para realizar la manipulación de datos. In questo articolo, he explicado varios paquetes que facilitan la vida de ‘R’ durante la etapa de manipulación de datos.
Nota: Este artículo es más adecuado para principiantes en R Language. Puede instalar un paquete usando:
install.packages('package name')
Lista de paquetes
Per una migliore comprensione, también he demostrado su uso al realizar operaciones de uso común. A continuación se muestra la lista de paquetes discutidos en este artículo:
- dplyr
- tabella dati
- ggplot2
- remodelar2
- lettore
- tidyr
- lubridate
Nota: Entiendo que ggplot2 es un paquete gráfico. Ma, generalmente, ayuda a visualizar datos (distribuzioni, correlaciones) y realizar manipulaciones en consecuencia. Perciò, lo agregué a esta lista. En todos los paquetes, he cubierto solo los comandos más utilizados en la manipulación de datos.
paquete dplyr
Estos paquetes son creados y mantenidos por Hadley Wickham. Este paquete tiene todo (quasi) para acelerar sus esfuerzos de manipulación de datos. Es mejor conocido por la exploración y transformación de datos. Su sintaxis de encadenamiento lo hace altamente adaptable de usar. Incluye 5 comandos principales de manipulación de datos:
- filtro: filtra los datos en función de una condición
- selezionare: se utiliza para seleccionar columnas de interés de un conjunto de datos
- Organizzare: se utiliza para organizar los valores del conjunto de datos en orden ascendente o descendente.
- mutar: se utiliza para crear nuevas variables a partir de variables existentes
- astratto (con group_by): se utiliza para realizar análisis mediante operaciones de uso común, como mínimo, massimo, recuento medio, eccetera.
Concéntrese en estos comandos y haga un gran trabajo en la exploración de datos. Entendamos estos comandos uno por uno. He utilizado 2 conjuntos de datos R preinstalados, vale a dire, mtcars e iris.
> biblioteca(dplyr)
> dati("mtcars")
> dati('iris')
> mydata <- mtcars
#read data > testa(mydata)

#creating a local dataframe. Local data frame are easier to read > mynewdata <- tbl_df(mydata) > myirisdata <- tbl_df(iris)
#now data will be in tabular structure > mynewdata> myirisdata
 >
> 
#use filter to filter data with required condition > filtro(mynewdata, Cil > 4 & gear > 4 )> filtro(mynewdata, Cil > 4)
> filtro (myirisdata, Species% in% c ('setosa', 'vergine'))
 > filtro(
> filtro( > filtro (
> filtro (
#utilizzo SelezionareIl comando "SELEZIONARE" è fondamentale in SQL, Utilizzato per interrogare e recuperare dati da un database. Consente di specificare colonne e tabelle, filtrare i risultati utilizzando clausole quali "DOVE" e ordinando con "ORDINA PER". La sua versatilità lo rende uno strumento essenziale per la manipolazione e l'analisi dei dati, facilitare l'ottenimento di informazioni specifiche in modo efficiente.... to pick columns by name > Selezionare(mynewdata, Cil,mpg,hp)#here you can use (-) to hide columns > Selezionare(mynewdata, -Cil, -mpg )
# ocultar un rango de columnas> selezionare (mynewdata, -C (Cil, mpg))
 #
# #
# 
#chaining or pipelining - a way to perform multiple operations #in one line > mynewdata %>% Selezionare(Cil, wt, gear)%>% filtro(wt > 2)
#arrange can be used to reorder rows > mynewdata%>% Selezionare(Cil, wt, gear)%>% arrange(wt)
#o
> mynewdata%>% Selezionare(Cil, wt, gear)%>% arrange(desc(wt))
#mutare - create new variables > mynewdata %>% Selezionare(mpg, Cil)%>% mutare(newvariable = mpg*cyl)
#o
> newvariable <- mynewdata %>% mutare(newvariable = mpg*cyl)
#riassumere - this is used to find insights from data > myirisdata%>% group_by(Specie)%>% riassumere(Average = mean(Sepal.Length, na.rm = TRUE))
#or use summarise each
 #
#> myirisdata%>% group_by(Specie)%>% summarise_each(funs(Significare, n()), Sepal.Length, Sepal.Larghezza)#You can create complex chain commands using these 5 verbs.
 #
##you can rename the variables using rename command > mynewdata %>% rinominare(miles = mpg)
paquete data.table
Este paquete le permite realizar una manipulación más rápida en un conjunto de datos. Deje sus formas tradicionales de subconfigurar filas y columnas y use este paquete. Con una codificación mínima, puede hacer mucho más. El uso de data.table ayuda a reducir el tiempo de cálculo en comparación con data.frame. Quedará asombrado por la simplicidad de este paquete.
Una tabla de datos tiene 3 parti, vale a dire, DT[io,J,di]. Puede entender esto como, podemos decirle a R que haga un subconjunto de las filas usando ‘i’, para calcular ‘j’ que está agrupado por ‘por’. La maggior parte delle volte, “di” se relaciona con una variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... Categorico. Nel seguente codice, ho usato 2 set di dati (calidad del aire e iris).
#load data > dati("airquality") > mydata <- airquality > testa(airquality,6)
> dati(iris)
> myiris <- iris
#load package > biblioteca(data.table)
> mydata <- data.table(mydata) > mydata
> myiris <- data.table(myiris) > myiris
#subset rows - select 2nd to 4th row > mydata[2:4,]
#select columns with particular values > myiris[Species == 'setosa']
 #
#
#select columns with multiple values. This will give you columns with Setosa #and virginica species > myiris[Species %in% c('setosa', 'vergine')] #select columns. Returns a vector > mydata[,Temp]

> mydata[,.(Temp,Mese)]
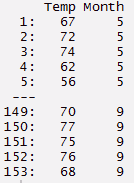
#returns sum of selected column > mydata[,somma(Ozone, na.rm = TRUE)] [1]4887
#returns sum and standard deviation > mydata[,.(somma(Ozone, na.rm = TRUE), sd(Ozone, na.rm = TRUE))]
#print and plot > myiris[,{Stampa(Sepal.Length) > complotto(Sepal.Larghezza) NULLO}]

#grouping by a variable > myiris[,.(sepalsum = sum(Sepal.Length)), by=Species]

#select a column for computation, hence need to set the key on column > setkey(myiris, Specie) #selects all the rows associated with this data point > myiris['setosa'] > myiris[C('setosa', 'vergine')]
Paquete ggplot2
ggplot ofrece un mundo completamente nuevo de colores y patrones. Si eres un alma creativa, te encantará este paquete hasta el fondo. Ma, si desea aprender lo que es necesario para comenzar, siga los códigos a continuación. Debe aprender las formas de trazar al menos estos 3 grafica: Diagramma di dispersioneIl grafico a dispersione è uno strumento grafico utilizzato in statistica per visualizzare la relazione tra due variabili. Consiste in un insieme di punti in un piano cartesiano, dove ogni punto rappresenta una coppia di valori corrispondenti alle variabili analizzate. Questo tipo di grafico consente di identificare i modelli, Tendenze e possibili correlazioni, facilitare l'interpretazione dei dati e il processo decisionale sulla base delle informazioni visive presentate...., Diagrama de barras, Istogramma.
Queste 3 patrones de gráficos cubren casi todos los tipos de representación de datos, excepto mapas. ggplot está enriquecido con funciones personalizadas para hacer que su visualización sea cada vez mejor. Se vuelve aún más poderoso cuando se agrupa con otros paquetes como cowplot, gridExtra. Infatti, hay muchas funciones. Perciò, debe concentrarse en algunos comandos y desarrollar su experiencia en ellos. También he mostrado el método para comparar gráficos en una ventana. Requiere el paquete ‘gridExtra’. Perciò, debe instalarlo. He usado conjuntos de datos R preinstalados.
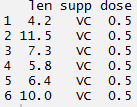
> biblioteca(ggplot2) > biblioteca(gridExtra) > df <- ToothGrowth
> df$dose <- come.fattore(df$dose) > testa(df)
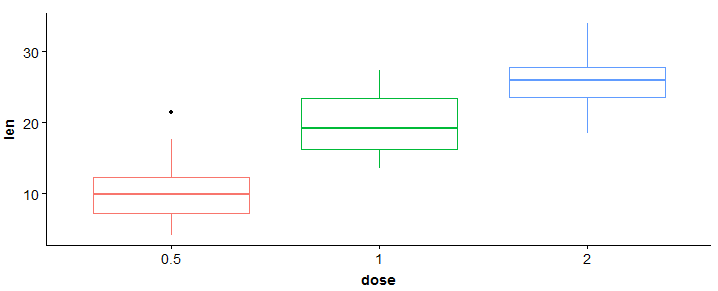
#trama a scatole > bp <- ggplot(df, aes(x = dose, y = len, color = dose)) + geom_boxplot() + Tema(legend.position = 'none') > bp
#add gridlines > bp + background_grid(major = "xy", minor="nessuno")
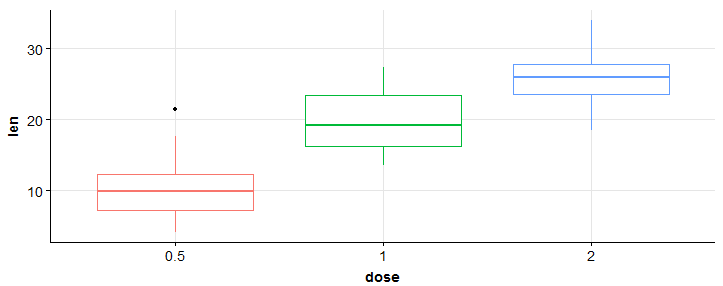
#scatterplot > sp <- ggplot(mpg, aes(x = cty, y = hwy, color = factor(Cil)))+geom_point(dimensione = 2.5) > sp
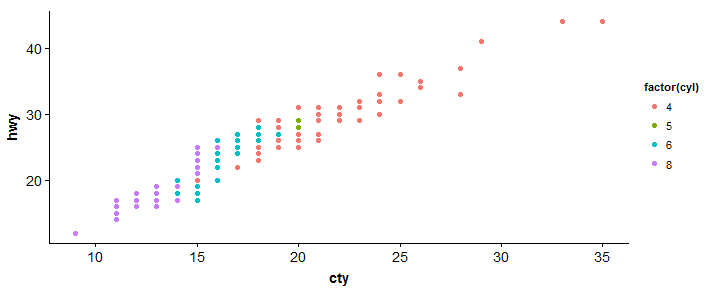
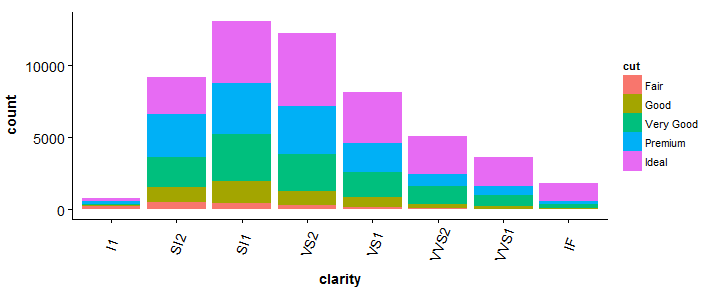
#barplot > bp <- ggplot(diamonds, aes(clarity, fill = cut)) + geom_bar() +Tema(axis.text.x = element_text(angle = 70, vjust = 0.5)) > bp
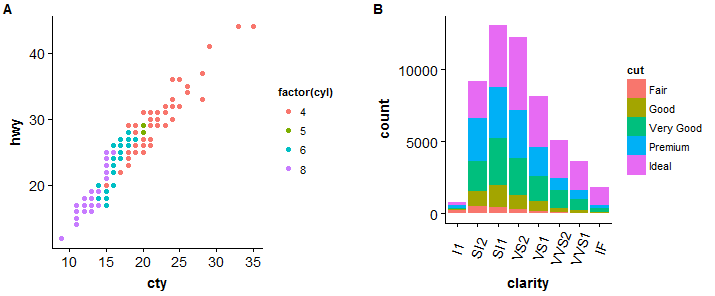
#compare two plots > plot_grid(sp, bp, labels = c("UN","B"), ncol = 2, nrow = 1)#istogramma > ggplot(diamonds, aes(x = carat)) + geom_histogram(binwidth = 0.25, riempimento="steelblue")+scale_x_continuous(breaks=seq(0,3, by=0.5))
 #istogramma
> ggplot(
#istogramma
> ggplot(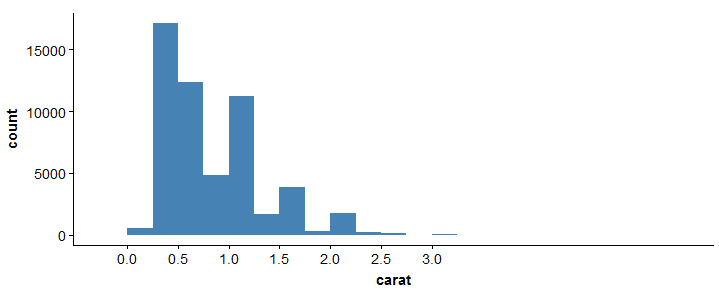
Para obtener más información sobre este paquete, consulte la hoja de referencia aquí: hoja de referencia de ggplot2
paquete reshape2
Come suggerisce il nome, este paquete es útil para remodelar los datos. Todos sabemos que los datos vienen en muchas formas. Perciò, estamos obligados a domesticarlo según nuestras necesidades. Generalmente, el proceso de remodelación de datos en R es tedioso y preocupante. Las funciones base de R consisten en la opción ‘Agregación’ mediante la cual los datos se pueden reducir y reorganizar en formas más pequeñas, pero con una reducción en la cantidad de información. La agregación incluye funciones de base de tapply, by y agregadas. El paquete de remodelación soluciona estos problemas. Aquí intentamos combinar características que tienen valores únicos. Ho 2 funciones a saber derretir e emitir.
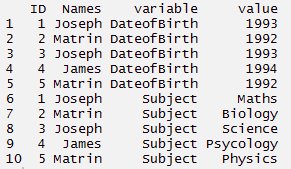
derretir : Esta función convierte datos de formato ancho a formato largo. Es una forma de reestructuración en la que múltiples columnas categóricas se ‘fusionan’ en filas únicas. Entendamos usando el código a continuación.
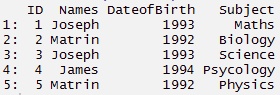
#create a data > ID <- C(1,2,3,4,5) > Names <- C('Joseph','Matrin','Joseph','James','Matrin') > DateofBirth <- C(1993,1992,1993,1994,1992) > Oggetto<- C('Matematica','Biology','Science','Psycology','Fisica')
> thisdata <- data.frame(ID, Names, DateofBirth, Oggetto) > data.table(thisdata)
#load package > install.packages('reshape2') > biblioteca(rimodellare2)
#Fondere > mt <- Fondere(thisdata, id=(C('ID','Names'))) > mt
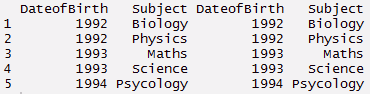
emitir : Esta función convierte los datos de formato largo a formato ancho. Comienza con datos fundidos y cambia a formato largo. Es solo el reverso de derretir funzione. Tiene dos funciones a saber, dcast e un molde. dcast devuelve un marco de datos como salida. acast devuelve un vector / Sede centrale / matriz como salida. Entendamos usando el código a continuación.
#lancio > mcast <- dcast(mt, DateofBirth + Subject ~ variable) > mcast
Nota: Mientras investigaba, encontré esta imagen que describe acertadamente el paquete de remodelación.
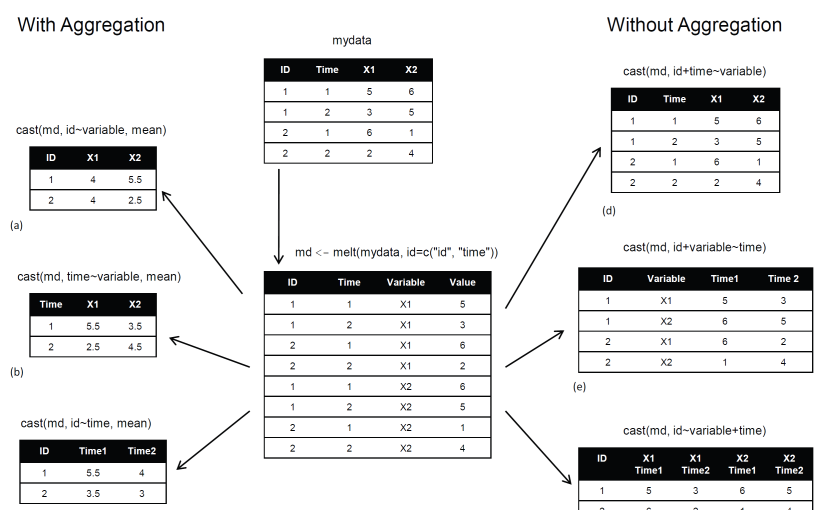 fonte: r-estadisticas
fonte: r-estadisticas
paquete readr
Come suggerisce il nome, ‘readr’ ayuda a leer varias formas de datos en R. Con una velocidad 10 veces más rápida. Qui, los caracteres nunca se convierten en factores (por lo que no más stringAsFactors = FALSE). Este paquete puede reemplazar las funciones tradicionales de R base read.csv () y read.table (). Ayuda a leer los siguientes datos:
- Archivos delimitados con
read_delim(),read_csv(),read_tsv(), eread_csv2(). - Archivos de ancho fijo con
read_fwf(), eread_table(). - Archivos de registro web con
read_log()
Si el tiempo de carga de datos es superior a 5 secondi, esta función también le mostrará una barra de progreso. Puede suprimir la barra de progreso marcándola como FALSO. Veamos el siguiente código:
> install.packages('readr') > biblioteca(readr)
> read_csv('prova.csv',col_names = TRUE)
También puede especificar el tipo de datos de cada columna cargada en los datos usando el siguiente código:
> read_csv("iris.csv", col_types = list(
Sepal.Length = col_double(),
Sepal.Width = col_double(),
Petal.Length = col_double(),
Petal.Width = col_double(),
Species = col_factor(C("setosa", "Versicolor", "virginica"))
))
tuttavia, si elige omitir columnas sin importancia, se ocupará de ello automáticamente. Quindi, el código anterior también se puede reescribir como:
> read_csv("iris.csv", col_types = list(
Species = col_factor(C("setosa", "Versicolor", "virginica"))
)
PS – readr tiene muchas funciones auxiliares. Quindi, cuando escriba un archivo csv, use write_csv en su lugar. Es mucho más rápido que write.csv.
paquete tidyr
Este paquete puede hacer que sus datos se vean “organizzato”. Ho 4 funciones principales para realizar esta tarea. No hace falta decir que si se encuentra atascado en la fase de exploración de datos, puede usarlos en cualquier momento (junto con dplyr). Este dúo forma un equipo formidable. Son fáciles de aprender, codificar e implementar. Sono 4 funciones son:
- raccogliere () – ‘reúne’ múltiples columnas. Dopo, los convierte en pares clave: valore. Esta función se transformará de forma amplia de datos a forma larga. Puede usarlo como una alternativa a ‘derretir’ en el paquete de remodelación.
- spread (): se invierte de recopilar. Toma un par clave: valor y lo convierte en columnas separadas.
- spezzare (): divide una columna en varias columnas.
- unite (): se invierte o se separa. Une varias columnas en una sola columna
Entendamos de cerca usando el siguiente código:
#load package > biblioteca(tidyr)
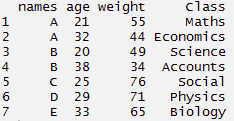
#create a dummy data set > nomi <- C('UN','B','C','D',"E",'UN','B') > weight <- C(55,49,76,71,65,44,34) > età <- C(21,20,25,29,33,32,38) > Classe <- C('Matematica','Science','Social','Fisica','Biology','Economics','Accounts')
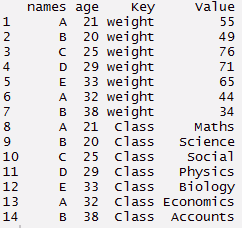
#create data frame > tdata <- data.frame(nomi, età, weight, Classe) > tdata#using gather function > long_t <- tdata %>% gather(Chiave, Valore, weight:Classe) > long_t

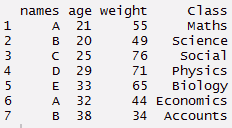 #
#
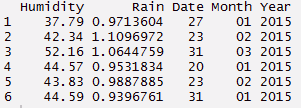
La función separada se usa mejor cuando se nos proporciona una variable de fecha y hora en el conjunto de datos. Dado que la columna contiene información múltiple, tiene sentido dividirla y usar esos valores individualmente. Usando el código a continuación, he separado una columna en fecha, mese e anno.
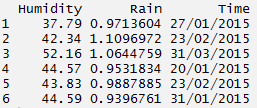
#create a data set > Humidity <- C(37.79, 42.34, 52.16, 44.57, 43.83, 44.59) > Rain <- C(0.971360441, 1.10969716, 1.064475853, 0.953183435, 0.98878849, 0.939676146) > Ore <- C("27/01/2015 15:44","23/02/2015 23:24", "31/03/2015 19:15", "20/01/2015 20:52", "23/02/2015 07:46", "31/01/2015 01:55") #build a data frame > d_set <- data.frame(Humidity, Rain, Ore) #using separate function we can separate date, mese, anno > separate_d <- d_set %>% separate(Ore, C('Data', 'Mese','Anno')) > separate_d#using unite function - reverse of separate > unite_d <- separate_d%>% unite(Ore, C(Data, Mese, Anno), SEP = "/") > unite_d
#utilizando la función de propagación - inversa de la recopilación> wide_t % spread (chiave, valore)> wide_t
 #
# #
#
Paquete Lubridate
El paquete Lubridate reduce la molestia de trabajar con la variable de tiempo de datos en R. La función incorporada de este paquete ofrece una buena manera de facilitar el análisis de fechas y horas. Este paquete se utiliza con frecuencia con datos que comprenden datos puntuales. Aquí he cubierto tres tareas básicas realizadas con Lubridate.
Esto incluye función de actualización, función de duración y extracción de fecha. Come principiante, conocer estas 3 funciones le brindará la experiencia suficiente para lidiar con las variables de tiempo. Sebbene, R tiene funciones incorporadas para manejar fechas, pero esto es mucho más rápido. Entendamos usando el siguiente código:
> install.packages('lubridate') > biblioteca(lubridate)
#current date and time > now() [1] "2015-12-11 13:23:48 IST"
#assigning current date and time to variable n_time > n_time <- now()
#using update function > n_update <- aggiornare(n_time, year = 2013, month = 10) > n_update [1] "2013-10-11 13:24:28 IST"
#add days, mesi, anno, Secondi > d_time <- now() > d_time + ddays(1) [1] "2015-12-12 13:24:54 IST" > d_time + dweeks(2) [1] "2015-12-12 13:24:54 IST" > d_time + dyears(3) [1] "2018-12-10 13:24:54 IST" > d_time + dhours(2) [1] "2015-12-11 15:24:54 IST" > d_time + dminutes(50) [1] "2015-12-11 14:14:54 IST" > d_time + dseconds(60) [1] "2015-12-11 13:25:54 IST"
#extract date,tempo
> n_time$hour <- hour(now()) > n_time$minute <- minute(now()) > n_time$second <- secondo(now()) > n_time$month <- mese(now()) > n_time$year <- anno(now())
#check the extracted dates in separate columns > new_data <- data.frame(n_time$hour, n_time$minute, n_time$second, n_time$month, n_time$year) > new_data
Nota: El mejor uso de estos paquetes no es de forma aislada sino en conjunto. Puede usar fácilmente este paquete con dplyr, donde puede seleccionar fácilmente una variable de datos y extraer los datos útiles de ella usando el comando en cadena.
Note finali
Estos paquetes no solo mejorarían su experiencia de manipulación de datos, sino que también le darían razones para explorar R en profundidad. Ahora que hemos visto, estos paquetes facilitan la codificación en R. Ya no es necesario escribir códigos largos. Anziché, escriba códigos cortos y haga más.
Cada paquete tiene capacidades multitarea. Perciò, le sugiero que obtenga una función importante que se puede usar con frecuencia. E, una vez que se familiarice con ellos, podrá profundizar más. Inicialmente cometí este error. Intenté explorar todas las funciones de ggplot2 y terminé en una confusión. Le sugiero que practique estos códigos mientras lee. Esto le ayudaría a generar confianza en el uso de estos paquetes.
In questo articolo, he explicado el uso de paquetes de 7 R que pueden hacer que la exploración de datos sea más fácil y rápida. R conocido por sus increíbles funciones estadísticas, con paquetes recientemente actualizados, también lo convierte en una herramienta favorita de los científicos de datos.





