Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
Introduzione
NOI, gli umani, leggiamo testi quasi ogni minuto della nostra vita. Non sarebbe fantastico se anche le nostre macchine o i nostri sistemi potessero leggere il testo come facciamo noi?? Ma la domanda più importante è “Come facciamo leggere le nostre macchine”? È qui che entra in gioco il riconoscimento ottico dei caratteri. (OCR).
Riconoscimento ottico dei caratteri (OCR)
riconoscimento ottico dei caratteri (OCR) è una tecnica di lettura o acquisizione di testo da fotografie stampate o scansionate, immagini scritte a mano e convertirle in un formato digitale che può essere modificato e ricercato.
Applicazioni
L'OCR ha molte applicazioni nel mondo degli affari oggi.. Alcuni di loro sono elencati di seguito:
- Riconoscimento dei passaporti negli aeroporti
- Automazione dell'immissione dei dati
- riconoscimento targa
- Estrarre le informazioni sui biglietti da visita da un elenco di contatti
- Conversione di documenti manoscritti in immagini elettroniche
- Creazione di PDF ricercabili
- Creare file udibili (dal testo all'audio)
Alcuni degli strumenti OCR open source sono Tesseract, OCRopus.
In questo articolo, ci concentreremo su Tesseract OCR. E per leggere le immagini abbiamo bisogno di OpenCV.
Installazione di Tesseract OCR:
Scarica il programma di installazione più recente per Windows 10 a partire dal “https://github.com/UB-Mannheim/tesseract/wiki“. Esegui il file .exe una volta scaricato.
Nota: Non dimenticare di copiare il percorso di installazione del file software. Ne avremo bisogno in seguito in quanto dobbiamo aggiungere il percorso dell'eseguibile tesseract nel codice se la directory di installazione è diversa da quella predefinita.
Il percorso di installazione tipico nei sistemi Windows è C: Programmi.
Quindi, nel mio caso, è “C: Archivos de programa Tesseract-OCRtesseract.exe“.
Prossimo, per installare il contenitore Python per Tesseract, Aprire il prompt dei comandi ed eseguire il comando “pip installare pytesseract“.
OpenCV
OpenCV (Visione artificiale open source) è una libreria open source per applicazioni di elaborazione delle immagini, apprendimento automatico e visione artificiale.
OpenCV-Python è l'API Python per OpenCV.
Per installarlo, Aprire il prompt dei comandi ed eseguire il comando “pip instalar opencv-python“.
Creare uno script OCR di esempio
1. Leggi un'immagine di esempio
importa cv2
Leggere l'immagine utilizzando il metodo cv2.imread () y guárdela en una variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... "img".
img = cv2.imread("immagine.jpg")
Se richiesto, Ridimensionare l'immagine utilizzando il metodo Cv2.resize ()
img = cv2.resize(img, (400, 400))
Visualizzare l'immagine utilizzando il metodo cv2.imshow ()
cv2.imshow("Immagine", img)
Visualizza la finestra all'infinito (Per evitare che il kernel si arresti in modo anomalo)
cv2.waitKey(0)
Chiudi tutte le finestre aperte
cv2.destroyAllWindows()
2. Conversione di immagini a catena
importazione pytesseract
Impostare il percorso tesseract nel codice
pytesseract.pytesseract.tesseract_cmd=r'C:ProgrammiTesseract-OCRtesseract.exe'
Il seguente errore si verifica se non si imposta il percorso.

Per convertire un'immagine in una stringa, utilizzare pytesseract.image_to_string (img) e salvarlo in una variabile “testo”
testo = pytesseract.image_to_string(img)
Stampare il risultato
Stampa(testo)
Codice completo:
import cv2 import pytesseract pytesseract.pytesseract.tesseract_cmd=r'C:Program FilesTesseract-OCRtesseract.exe' img = cv2.imread("immagine.jpg") img = cv2.resize(img, (400, 450)) cv2.imshow("Immagine", img) testo = pytesseract.image_to_string(img) Stampa(testo) cv2.waitKey(0) cv2.destroyAllWindows()
L'output del codice precedente:
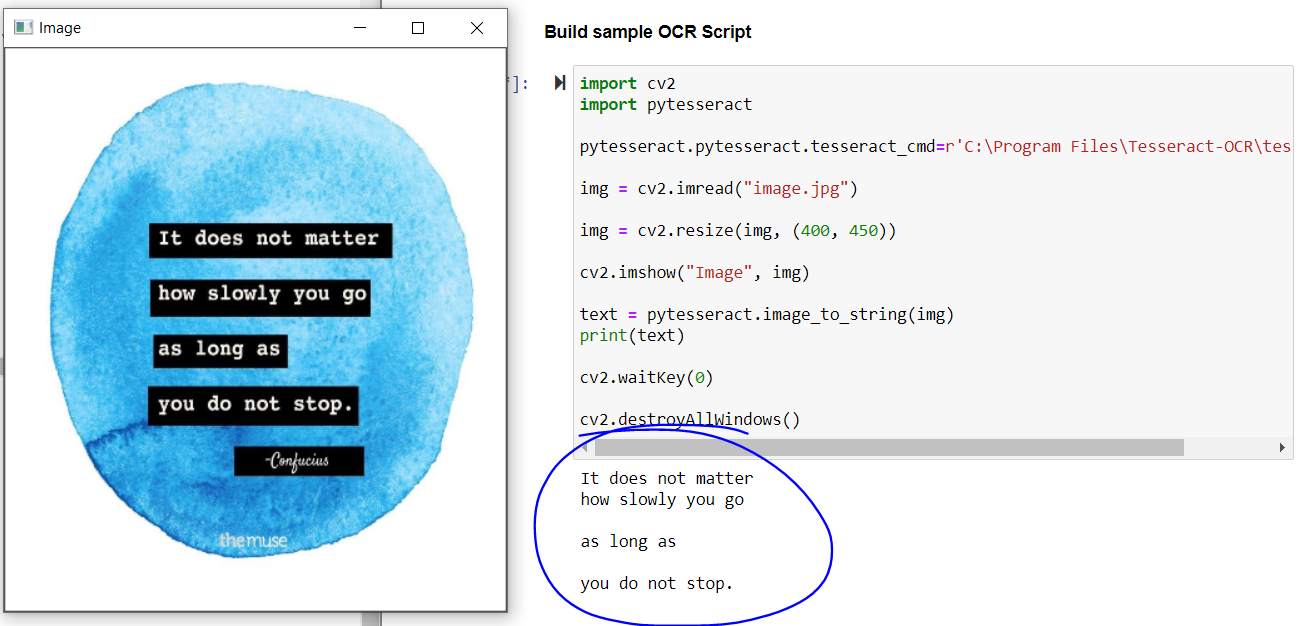
L'output del codice precedente
Se guardiamo il risultato, l'appuntamento principale viene estratto perfettamente, ma non si ottiene il nome del filosofo e il testo in fondo all'immagine.
Per estrarre il testo in modo accurato ed evitare cadute di precisione, dobbiamo eseguire una precedente elaborazione dell'immagine. Ho trovato questo articolo (https://versodatascience.com/pre-processing-in-ocr-fc231c6035a7) abbastanza utile. Dai un'occhiata per comprendere meglio le tecniche di pre-elaborazione.
Perfetto! Ora che abbiamo le basi richieste, diamo un'occhiata ad alcune semplici applicazioni OCR.
1. Creazione di nuvole di parole nelle immagini delle recensioni
La nuvola di parole è una rappresentazione visiva della frequenza delle parole. Più grande è la parola che appare in una nuvola di parole, parola più comunemente usata nel testo.
Per questo, Ho scattato alcune istantanee delle recensioni di Amazon per il prodotto Apple iPad di 8a generazione.
immagine di esempio
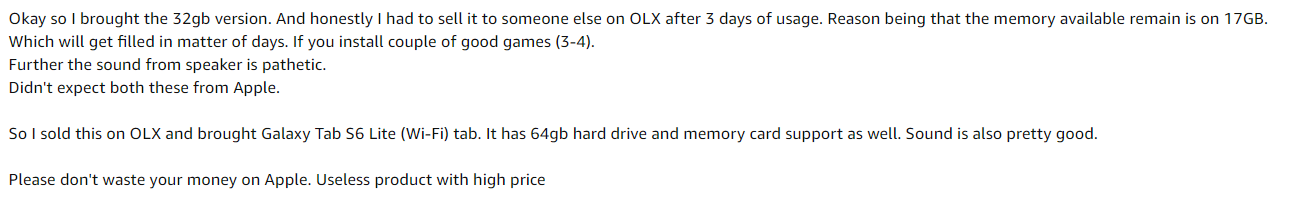
Passi:
- Creare un elenco di tutte le immagini di recensione disponibili
- Se richiesto, Visualizzare le immagini utilizzando il metodo Cv2.imshow ()
- Leggere il testo dalle immagini usando pytesseract
- Creare un framework di dati
- Pre-elaborare il testo: Eliminare caratteri speciali, ferma le parole
- Crea nuvole di parole positive e negative
passo 1: crea un elenco di tutte le immagini di recensione disponibili
importare il sistema operativo percorsocartella = "Recensioni" myRevList = os.listdir(percorsocartella)
passo 2: Se richiesto, Visualizzare le immagini utilizzando il metodo Cv2.imshow ()
per l'immagine in myRevList:
img = cv2.imread(F'{percorsocartella}/{Immagine}')
cv2.imshow("Immagine", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
passo 3: legge il testo dalle immagini usando pytesseract
import cv2 import pytesseract pytesseract.pytesseract.tesseract_cmd=r'C:Program FilesTesseract-OCRtesseract.exe' corpus = [] per le immagini in myRevList: img = cv2.imread(F'{percorsocartella}/{immagini}') se img è Nessuno: corpus.append("Impossibile leggere l'immagine.") altro: rev = pytesseract.image_to_string(img) corpus.append(rev) elenco(corpus) corpus
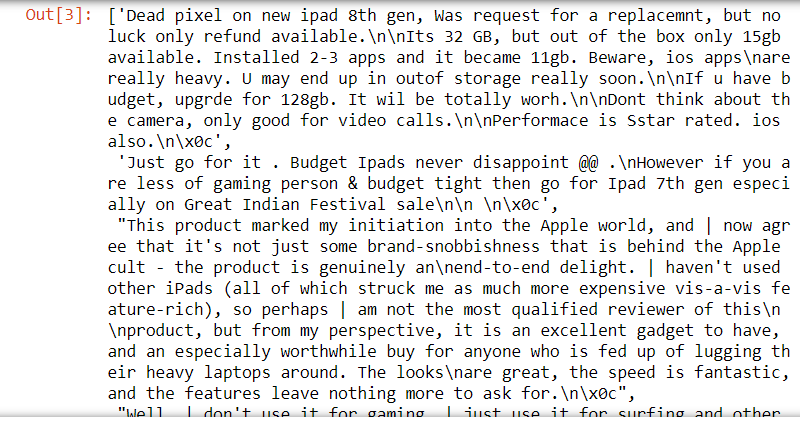
passo 4: crea un framework di dati
import pandas as pd
data = pd.DataFrame(elenco(corpus), colonne=['Recensione'])
dati

passo 5: pre-elaborazione del testo: Eliminare caratteri speciali, parole vuote
#removing special characters
import re
def clean(testo):
restituisci re.sub('[^A-Za-z0-9" "]+', ' ', testo)
dati['Recensione pulita'] = dati['Recensione'].applicare(pulire)
dati

Rimozione di parole vuote dalla "Revisione pulita"’ e l'aggiunta di tutte le parole rimanenti a una variabile di elenco “final_list”.
-
# removing stopwords import nltk from nltk.corpus import stopwords nltk.download("Punkt") from nltk import word_tokenize stop_words = stopwords.words('inglese') final_list = [] per la colonna nei dati[['Recensione pulita']]: columnSeriesObj = dati[colonna] all_rev = columnSeriesObj.values for i in range(len(all_rev)): token = word_tokenize(all_rev[io]) per Word in token: se word.lower() non in stop_words: final_list.append(parola)
passo 6: Crea nuvole di parole positive e negative
Installare la libreria cloud di Word con il comando “pip installare wordcloud“.
In lingua inglese, abbiamo un insieme predefinito di parole positive e negative chiamato Opinion Lexicons. Questi file possono essere scaricati da Collegamento o direttamente da me Archivio GitHub.
Una volta scaricati i file, Leggere i file nel codice e creare un elenco di parole positive e negative.
con aperto(R"opinione-lessico-inglese-parole-positive.txt","R") come pos:
poswords = pos.read().diviso("n")
con aperto(R"opinione-lessico-inglesenegative-parole.txt","R") come neg:
negwords = neg.read().diviso("n")
Importazione di librerie per generare e visualizzare nuvole di parole.
import matplotlib.pyplot as plt
from wordcloud import WordCloud
Nuvola di parole positive
# Choosing the only words which are present in poswords
pos_in_pos = " ".aderire([w per W in final_list se W in poswords])
wordcloud_pos = WordCloud(
background_color="Nero",
larghezza=1800,
altezza=1400
).creare(pos_in_pos)
plt.imshow(wordcloud_pos)

La parola "buono" è la parola più usata che cattura la nostra attenzione. Se guardiamo indietro alle recensioni, le persone hanno scritto recensioni dicendo che l'iPad ha un buon schermo, buon suono, buon software e hardware.
Nuvola di parole negative
# Choosing the only words which are present in negwords
neg_in_neg = " ".aderire([w per W in final_list se W in negwords])
wordcloud_neg = WordCloud(
background_color="Nero",
larghezza=1800,
altezza=1400
).creare(neg_in_neg)
plt.imshow(wordcloud_neg)

Parole costose, bloccato, picchiato, La delusione si è distinta nella nuvola di parole negative. Se guardiamo al contesto della parola bloccato, dado “Anche se ha solo 3 GB di RAM, non si blocca mai”, che è una cosa positiva del dispositivo.
Perciò, è bene creare nuvole di parole bigrama / trigramma per non perdere il contesto.
2. Creare file udibili (dal testo all'audio)
gTTS è una libreria Python con l'API text-to-speech di Google Translate.
Per installare, Eseguire il comando “pip install gtts"Al prompt dei comandi.
Importa le librerie richieste
import cv2
import pytesseract
from gtts import gTTS
import os
Impostare il percorso tesseract
pytesseract.pytesseract.tesseract_cmd=r'C:ProgrammiTesseract-OCRtesseract.exe'
Leggi l'immagine usando cv2.imread () e prendere il testo dell'immagine usando pytesseract e salvarlo in una variabile.
rev = cv2.imread("Recensioni15.PNG")
# Visualizzare l'immagine utilizzando Cv2.imshow() metodo
# cv2.imshow("Immagine", rev)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# grab the text from image using pytesseract
txt = pytesseract.image_to_string(rev)
Stampa(Il Predictive Power Score è un'alternativa alla matrice di correlazione)
Imposta la lingua e crea una conversione da testo a audio usando gTTS senza passare attraverso il testo, la lingua
lingua="Su" outObj = gTTS(text=txt, lang=lingua, slow=Falso)
Salva il file audio come “rev.mp3”
outObj.save("rev.mp3")
riprodurre il file audio
sistema operativo('rev.mp3')
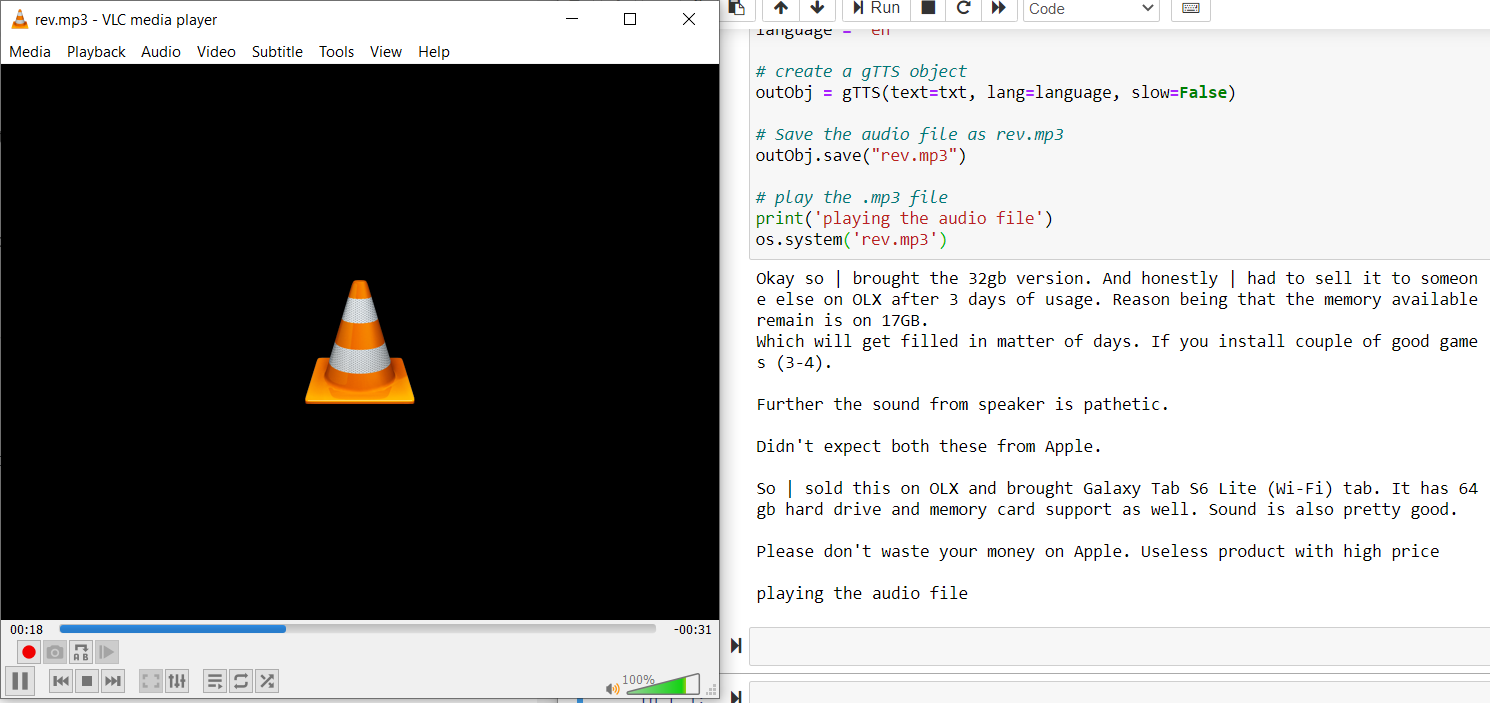
Codice completo:
-
import cv2 import pytesseract from gtts import gTTS import os rev = cv2.imread("Recensioni15.PNG") # cv2.imshow("Immagine", rev) # cv2.waitKey(0) # cv2.destroyAllWindows() txt = pytesseract.image_to_string(rev) Stampa(Il Predictive Power Score è un'alternativa alla matrice di correlazione) lingua="Su" outObj = gTTS(text=txt, lang=lingua, slow=Falso) outObj.save("rev.mp3") Stampa('riproduzione del file audio') sistema operativo('rev.mp3')
Note finali
Alla fine di questo articolo, abbiamo compreso il concetto di riconoscimento ottico dei caratteri (OCR) e abbiamo familiarità con la lettura di immagini con OpenCV e l'acquisizione di testo da immagini con pytesseract. e abbiamo familiarità con la lettura di immagini con OpenCV e l'acquisizione di testo da immagini con pytesseract: e abbiamo familiarità con la lettura di immagini con OpenCV e l'acquisizione di testo da immagini con pytesseract, e abbiamo familiarità con la lettura di immagini con OpenCV e l'acquisizione di testo da immagini con pytesseract.
Riferimenti:
e abbiamo familiarità con la lettura di immagini con OpenCV e l'acquisizione di testo da immagini con pytesseract, Per favore, e abbiamo familiarità con la lettura di immagini con OpenCV e l'acquisizione di testo da immagini con pytesseract. e abbiamo familiarità con la lettura di immagini con OpenCV e l'acquisizione di testo da immagini con pytesseract
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





