introduzione
Si hay un área en la ciencia de datos que ha llevado al crecimiento del aprendizaje automático y la inteligencia artificial en los últimos años, es el aprendizaje profundo. Desde laboratorios de investigación en universidades con poco éxito en la industria hasta la alimentación de todos los dispositivos inteligentes del planeta, el aprendizaje profundo y las redes neuronales han iniciado una revolución.
Nota: Se sei più interessato ad apprendere concetti in un formato audiovisivo, abbiamo questo articolo completo spiegato nel video qui sotto. Se non è così, puoi continuare a leggere.
In questo articolo, le presentaremos los componentes de las redes neuronales.
Bloques de construcción de una red neuronal: capas y neuronas
Hay dos bloques de construcción de una neuronale rossoLe reti neurali sono modelli computazionali ispirati al funzionamento del cervello umano. Usano strutture note come neuroni artificiali per elaborare e apprendere dai dati. Queste reti sono fondamentali nel campo dell'intelligenza artificiale, consentendo progressi significativi in attività come il riconoscimento delle immagini, Elaborazione del linguaggio naturale e previsione delle serie temporali, tra gli altri. La loro capacità di apprendere schemi complessi li rende strumenti potenti.., veamos cada uno de ellos en detalle:
1. ¿Qué son las capas en una red neuronal?
Una red neuronal está formada por componentes apilados verticalmente llamados copertine. Cada línea de puntos de la imagen representa una capa. Hay tres tipos de capas en un NN-
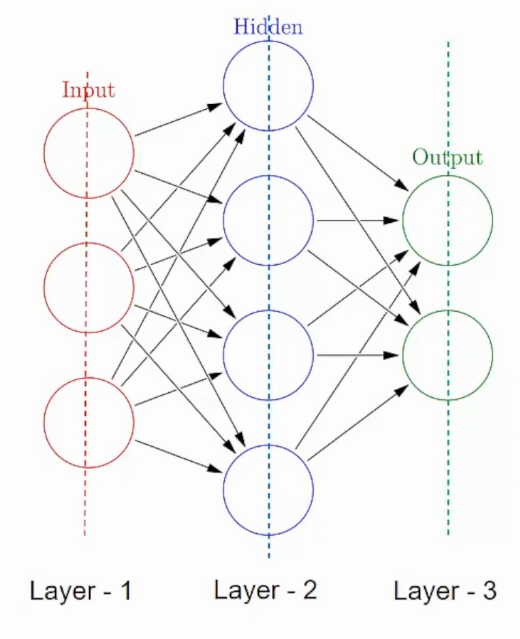
Livello di inputIl "livello di input" si riferisce al livello iniziale in un processo di analisi dei dati o nelle architetture di reti neurali. La sua funzione principale è quella di ricevere ed elaborare le informazioni grezze prima che vengano trasformate dagli strati successivi. Nel contesto dell'apprendimento automatico, La corretta configurazione del livello di input è fondamentale per garantire l'efficacia del modello e ottimizzarne le prestazioni in attività specifiche....– Primero está la capa de entrada. Esta capa aceptará los datos y los pasará al resto de la red.
Mantello nascosto– El segundo tipo de capa se llama capa oculta. Las capas ocultas son una o más para una red neuronal. Nel caso sopra, il numero è 1. Las capas ocultas son las que realmente son responsables del excelente rendimiento y la complejidad de las redes neuronales. Realizan múltiples funciones al mismo tiempo, como transformación de datos, creación automática de funciones, eccetera.
Livello di outputIl "Livello di output" è un concetto utilizzato nel campo della tecnologia dell'informazione e della progettazione di sistemi. Si riferisce all'ultimo livello di un modello o di un'architettura software che è responsabile della presentazione dei risultati all'utente finale. Questo livello è fondamentale per l'esperienza dell'utente, poiché consente l'interazione diretta con il sistema e la visualizzazione dei dati elaborati....– El último tipo de capa es la capa de salida. La capa de salida contiene el resultado o la salida del problema. Las imágenes sin procesar se pasan a la capa de entrada y recibimos la salida en la capa de salida. Ad esempio-

In questo caso, estamos proporcionando una imagen de un vehículo y esta capa de salida proporcionará una salida, ya sea un vehículo de emergencia o que no sea de emergencia, después de pasar por las capas de entrada y ocultas, Certo.
Ahora que conocemos las capas y su función, hablemos en detalle de de qué se compone cada una de estas capas.
2. ¿Qué son las neuronas en una red neuronal?
Una capa consta de pequeñas unidades individuales llamadas neuronas. UN neurona en una red neuronal puede entenderse mejor con la ayuda de neuronas biológicas. Una neurona artificial es similar a una neurona biológica. Recibe información de las otras neuronas, realiza algún procesamiento y produce una salida.
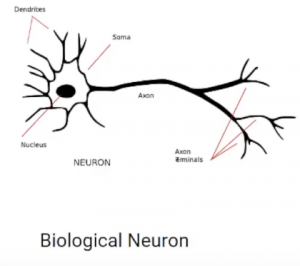
Ahora veamos una neurona artificial
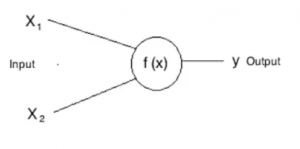
Qui, X1 e X2 son entradas a las neuronas artificiales, F (X) representa el procesamiento realizado en las entradas y e representa la salida de la neurona.
¿Qué es un disparo de una neurona?
En la vida real, todos hemos escuchado la frase: “Enciende esas neuronas” In un modo o nell'altro. Lo mismo se aplica también a las neuronas artificiales. Todas las neuronas tienen tendencia a dispararse, pero solo en determinadas condiciones. Ad esempio-
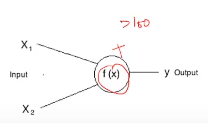
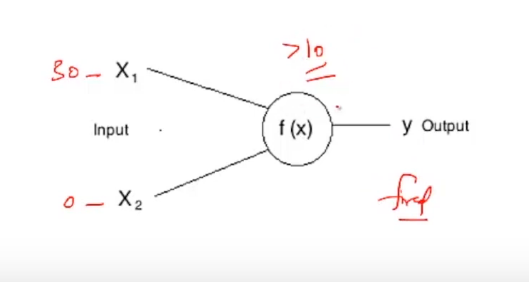
Si representamos esta f (X) por suma, entonces esta neurona puede dispararse cuando la suma es mayor que, Diciamo 100. Si bien puede haber un caso en el que la otra neurona puede dispararse cuando la suma es mayor que 10-
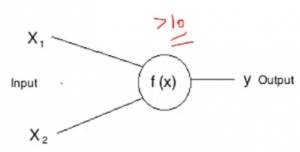
Estas determinadas condiciones que difieren de una neurona a otra se denominan Umbral. Ad esempio, si la entrada X1 en la primera neurona es 30 y X2 es 0:
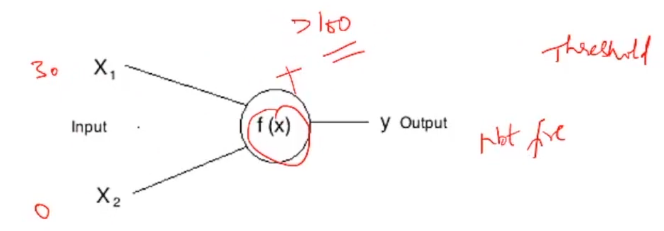
Esta neurona no se disparará, ya que la suma 30 + 0 = 30 no es mayor que el umbral, vale a dire, 100. Mientras que si la entrada hubiera permanecido igual para la otra neurona, esta neurona se habría disparado ya que la suma de 30 es mayor que la umbral de 10.
Ora, el umbral negativo se llama Pregiudizio de una neurona. Representemos esto un poco matemáticamente. Entonces podemos representar la condición de disparo y no disparo de una neurona usando este par de ecuaciones:
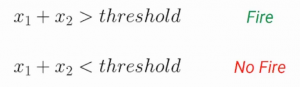
Si la suma de las entradas es mayor que el umbral, la neurona se activará. Altrimenti, la neurona no se disparará. Simplifiquemos un poco esta ecuación y llevemos el umbral al lado izquierdo de las ecuaciones. Ora, este umbral negativo se llama Pregiudizio-
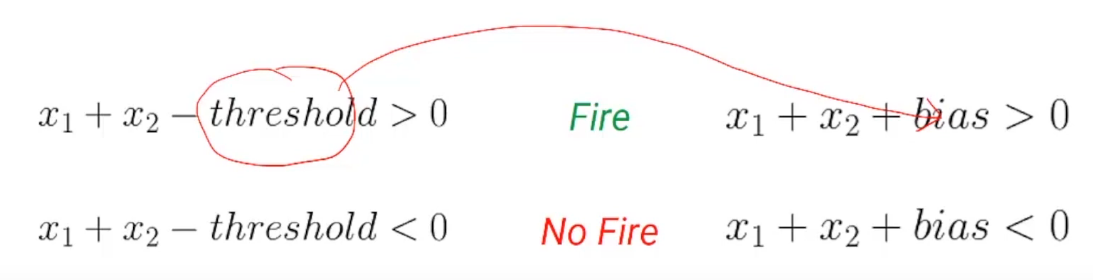
Una cosa a tener en cuenta es que en una red neuronal artificial, todas las neuronas de una capa tienen el mismo sesgo. Ahora que tenemos una buena comprensión del sesgo y cómo representa la condición para que una neurona se dispare, pasemos a otro aspecto de una neurona artificial llamado Pesos.
Fino ad ora, incluso en nuestro cálculo, hemos asignado la misma importancia a todas las entradas. Ad esempio-
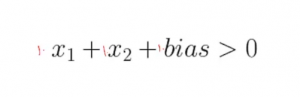
Aquí X1 tiene un peso de 1 y X2 tiene un peso de 1 y el sesgo tiene un peso de 1, pero ¿qué pasa si queremos tener diferentes pesos adjuntos a diferentes entradas?
Echemos un vistazo a un ejemplo para entender esto mejor. Suponga que hoy es una fiesta universitaria y tiene que decidir si debe ir a la fiesta o no en función de algunas condiciones de entrada, como ¿Hace buen tiempo? ¿Está el lugar cerca? ¿Viene tu enamoramiento?
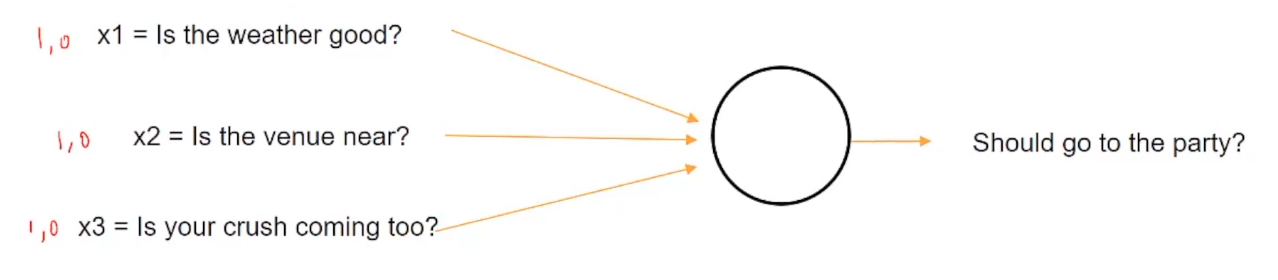
Quindi, si el clima es bueno, se presentará con un valor de 1, altrimenti, 0. Allo stesso modo, si el lugar está cerca, se representará con 1, altrimenti, 0. E allo stesso modo, si la persona que te gusta va a venir a la fiesta o no.
Ahora suponga que siendo un adolescente universitario, adora absolutamente a la persona que le gusta y puede hacer todo lo posible para verlo. Así que definitivamente irás a la fiesta sin importar cómo esté el clima o qué tan lejos esté el lugar, entonces querrás asignar más peso a X3 que representa el enamoramiento en comparación con las otras dos entradas.
Tal situación se puede representar si asignamos pesos a una entrada como esta:
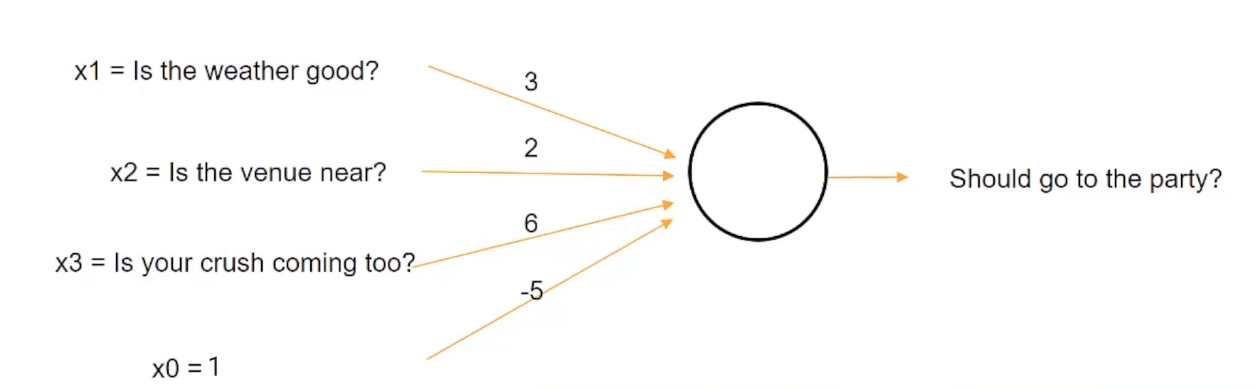
Podemos asignar un peso de 3 al clima, un peso de 2 al lugar y un peso de 6 al enamoramiento. però, si la suma de estos tres factores, que es el clima, el lugar y el enamoramiento es mayor que un umbral de 5, entonces puedes decidir ir a la fiesta de lo contrario.
Nota: X0 es el valor de sesgo
Quindi, ad esempio, hemos tomado inicialmente la condición en la que el enamoramiento es más importante que el clima o el lugar en sí.

Así que digamos, ad esempio, como representamos aquí, el clima (X1) está mal representado por 0 y el lugar (X2) está lejos representado por 0, pero tu crush (X3) viene a la fiesta que está representada por 1, así que cuando calculas la suma después de multiplicar los valores de Xs con sus respectivos pesos, obtenemos una suma de 0 para Weather (X1), 0 para Venue (X2) e 6 para Crush (X3). dato che 6 es mayor que el umbral de 5, decidirá ir a la fiesta. Perciò, la salida (e) è 1.
Imaginemos ahora un escenario diferente. Imagina que estás enfermo hoy y no importa qué no vayas a la fiesta, entonces esta situación se puede representar asignando el mismo peso al clima, el lugar y el enamoramiento con el umbral de 4.
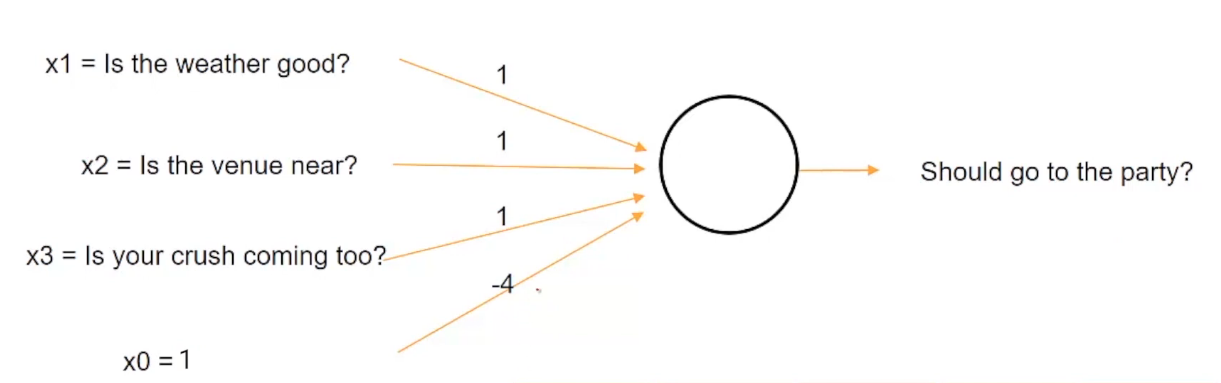
Ora, in questo caso, estamos cambiando el valor del umbral y estableciéndolo en un valor de 4, por lo que incluso si el clima es bueno, el lugar está cerca y la persona que te gusta está llegando, no irás a la fiesta desde el suma, vale a dire, 1 + 1 + 1 uguale a 3, es menor que el valor umbral de 4.
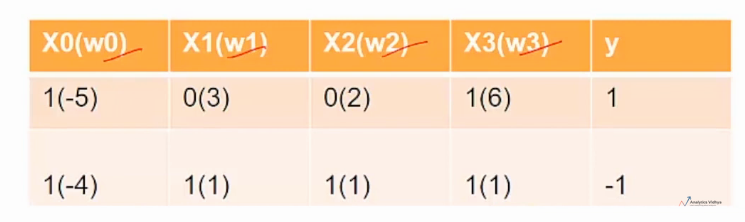
Estos w0, w1, w2 y w3 se denominan pesos de neuronas y son diferentes para diferentes neuronas. Estos pesos son los que tiene que aprender una red neuronal para tomar buenas decisiones.
Funciones de activación en una red neuronal
Ahora que sabemos cómo una red neuronal combina diferentes entradas usando pesos, pasemos al último aspecto de una neurona llamado Funzioni trigger. Fino ad ora, lo que hemos estado haciendo es simplemente agregar algunas entradas ponderadas y calcular alguna salida, y esta salida puede leerse desde menos infinito hasta infinito.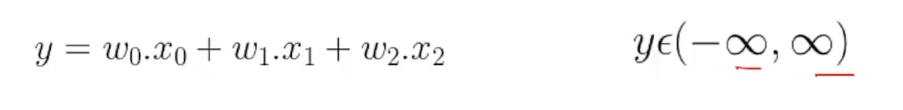
Pero esto puede cuestionarse en muchas circunstancias. Supongamos que primero queremos estimar la edad de una persona a partir de su altura, peso y nivel de colesterol y luego clasificar a la persona como anciana o no, en función de si la edad es mayor de 60 anni.
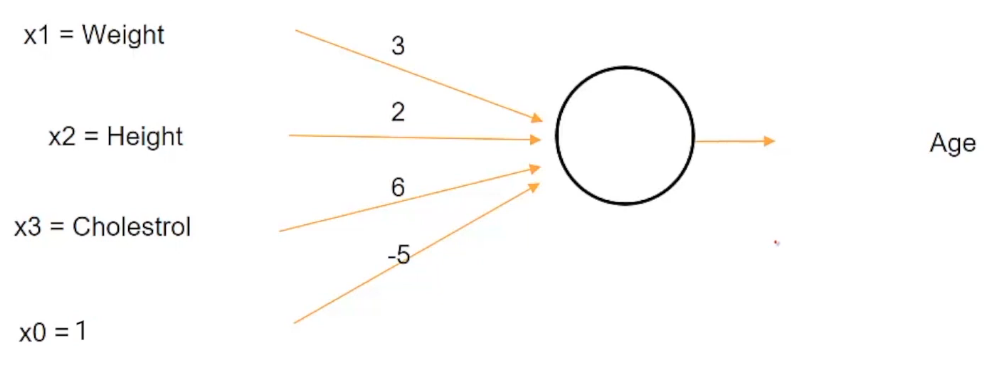
però, si usamos esta neurona dada, entonces la edad de -20 es incluso posible. Sabes que el rango de edad según la estructura actual de esta neurona variará de -∞ a ∞. Quindi, incluso la edad de alguien como -20 è possibile, dado este rango absurdo para la edad, todavía podemos usar nuestra condición para decidir si una persona es mayor o no. Ad esempio, si hemos dicho un cierto criterio como que una persona es mayor solo si la edad es mayor de 60 anni. Quindi, incluso si la edad resulta ser -20, podemos usar este criterio para clasificar a la persona como no mayor.
Pero hubiera sido mucho mejor si la edad hubiera tenido mucho más sentido, como si la salida de esta neurona que representa la edad hubiera estado en el rango de, Diciamo, 0 un 120. Quindi, ¿cómo podemos resolver este problema cuando la salida de una neurona no está en un rango particular?
Un método es recortar la edad en el lado negativo sería usar una función como máx. (0, X).
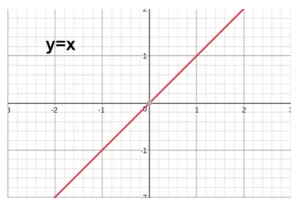
Ahora observemos primero la condición original, antes de usar cualquier función. Para la X positiva, tuvimos una Y positiva, y para la X negativa tuvimos una Y negativa. Aquí el eje x representa los valores reales e y representa los valores transformados.
Pero ahora, si quiere deshacerse de los valores negativos, lo que podemos hacer es usar una función como max (0, X). Al usar esta función, cualquier cosa que esté en el lado negativo del eje x se recorta a 0.
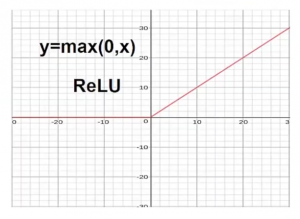
Este tipo de función se llama Función riprendereLa funzione di attivazione ReLU (Unità lineare rettificata) È ampiamente utilizzato nelle reti neurali grazie alla sua semplicità ed efficacia. Definito come ( F(X) = massimo(0, X) ), ReLU consente ai neuroni di attivarsi solo quando l'input è positivo, che aiuta a mitigare il problema dello sbiadimento del gradiente. È stato dimostrato che il suo utilizzo migliora le prestazioni in varie attività di deep learning, rendendo ReLU un'opzione.. y estas clases de funciones, que transforman la entrada combinada, sono denominati Funzioni trigger. Quindi, ReLU es una funzione svegliaLa funzione di attivazione è un componente chiave nelle reti neurali, poiché determina l'output di un neurone in base al suo input. Il suo scopo principale è quello di introdurre non linearità nel modello, Consentendo di apprendere modelli complessi nei dati. Ci sono varie funzioni di attivazione, come il sigma, ReLU e tanh, Ognuno con caratteristiche particolari che influiscono sulle prestazioni del modello in diverse applicazioni.....
Dependiendo del tipo de transformación necesaria, puede haber diferentes tipos de funciones de activación. Echemos un vistazo a algunas de las funciones de activación más populares:
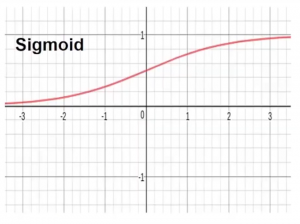
- Funzione di attivazione sigmoide– Esta función transforma el rango de entradas combinadas a un rango entre 0 e 1. Ad esempio, si la salida es de menos infinito a infinito que está representado por el eje x, la función sigmoide restringirá este rango infinito a un valor entre 0 e 1.

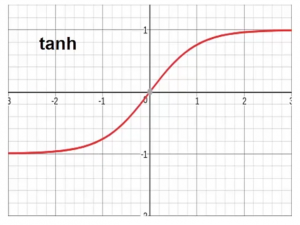
- Función de activación de Tanh Esta función transforma el rango de entradas combinadas a un rango entre -1 e 1. Tanh se ve muy similar a la forma del sigmoide pero restringe el rango entre -1 e 1.
 Las diferentes funciones de activación funcionan de manera diferente en diferentes distribuciones de datos. Quindi, a veces debe probar y verificar diferentes funciones de activación y descubrir cuál funciona mejor para un problema en particular.
Las diferentes funciones de activación funcionan de manera diferente en diferentes distribuciones de datos. Quindi, a veces debe probar y verificar diferentes funciones de activación y descubrir cuál funciona mejor para un problema en particular.
Note finali
Fino ad ora, hemos discutido que la red neuronal está compuesta por diferentes tipos de capas apiladas juntas y cada una de estas capas está compuesta por unidades individuales llamadas neuronas. Cada neurona tiene tres propiedades: la primera está sesgada, la segunda es el peso y la tercera es la función de activación.
Cosa c'è di più, el sesgo es el umbral negativo después del cual desea que se active la neurona. El peso es cómo se define qué entrada es más importante para las demás. La función de activación ayuda a transformar la entrada ponderada combinada para organizarla de acuerdo con la necesidad en cuestión.
Te recomiendo encarecidamente que consultes nuestro Cintura nera certificata AI e ML Più Programma para comenzar su viaje hacia el fascinante mundo de la ciencia de datos y aprender estos y muchos más temas.
Espero que este artículo funcione como un punto de partida para su aprendizaje hacia las redes neuronales y el apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute....
Comuníquese con nosotros en los comentarios a continuación en caso de que tenga alguna duda.





