Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati.
introduzione
Discuterò questo argomento in dettaglio di seguito.
Fasi della regressione lineare
Come suggerisce il nome, L'idea alla base dell'esecuzione della regressione lineare è che dovremmo arrivare a un'equazione lineare che descriva la relazione tra variabili dipendenti e indipendenti.
passo 1
Supponiamo di avere un set di dati dove x è il variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... L'indipendente e Y è una funzione di x (E= f (X)). Perciò, Usando la regressione lineare possiamo formare la seguente equazione (Equazione per la linea più adatta):
Y = mx + C
Questa è un'equazione di una retta dove m è la pendenza della retta e c è l'intersezione.
passo 2
Ora, per ricavare la linea più adatta, per prima cosa assegniamo valori casuali a myc e calcoliamo il valore corrispondente di Y per un dato x. Questo valore Y è il valore di output.
passo 3
In che modo la regressione logistica è un algoritmo di machine learning supervisionato, conosciamo già il reale valore Y (variabile dipendente). Ora, Come viene calcolato il valore di output (Rappresentiamolo come ?), Possiamo verificare se la nostra previsione è accurata o meno.
Nel caso della regressione lineare, Calcoliamo questo errore (residuo) utilizzando il metodo MSE (errore quadratico medio) e noi lo chiamiamo Funzione di perditaLa funzione di perdita è uno strumento fondamentale nell'apprendimento automatico che quantifica la discrepanza tra le previsioni del modello e i valori effettivi. Il suo obiettivo è quello di guidare il processo di formazione minimizzando questa differenza, consentendo così al modello di apprendere in modo più efficace. Esistono diversi tipi di funzioni di perdita, come l'errore quadratico medio e l'entropia incrociata, ognuno adatto a compiti diversi e...:
La funzione di perdita può essere scritta come:
L = 1 / n ∑ ((e – ?)2)
Dove n è il numero di osservazioni.
passo 4
Per ottenere la linea migliore, Dobbiamo minimizzare il valore della funzione di perdita.
Per ridurre al minimo la funzione di perdita, Usiamo una tecnica chiamata discesa di gradienteGradiente è un termine usato in vari campi, come la matematica e l'informatica, per descrivere una variazione continua di valori. In matematica, si riferisce al tasso di variazione di una funzione, mentre in progettazione grafica, Si applica alla transizione del colore. Questo concetto è essenziale per comprendere fenomeni come l'ottimizzazione negli algoritmi e la rappresentazione visiva dei dati, consentendo una migliore interpretazione e analisi in....
Diamo un'occhiata a come funziona la discesa del gradiente (anche se non entrerò nei dettagli, poiché questo non è l'obiettivo di questo articolo).
Discesa gradiente
Se guardiamo la formula per la funzione di perdita, L'"errore quadratico medio"’ significa che l'errore è rappresentato in termini di secondo ordine.
Se tracciamo la funzione di perdita per il peso (Nella nostra equazione i pesi sono MYC), Sarà una curva parabolica. Ora che la nostra bici sta riducendo al minimo la funzione di stallo, Dobbiamo arrivare alla fine della curva.
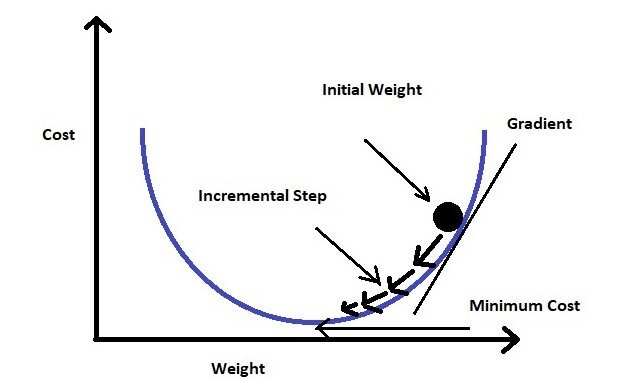
Per realizzare questo, Dobbiamo prendere la derivata del primo ordine della funzione di perdita per i pesi (Myc). Sottrarremo quindi il risultato della derivata dal peso iniziale moltiplicandolo per un tasso di apprendimento (un). Continueremo a ripetere questo passaggio fino a raggiungere il valore minimo (Noi li chiamiamo minimi globali). Impostiamo una soglia di un valore molto piccolo (esempio: 0.0001) come minimi globali. Se non impostiamo il valore di soglia, Può volerci un'eternità per raggiungere l'esatto valore zero.
passo 5
Una volta che la funzione di perdita è ridotta al minimo, otteniamo l'equazione finale per la retta più adatta e possiamo prevedere il valore di Y per ogni dato X.
Questo è il punto in cui finisce la regressione lineare e siamo solo a un passo dall'arrivare alla regressione logistica.
Regressione logistica
Come ho detto prima, fondamentalmente, La regressione logistica viene utilizzata per classificare gli elementi di un insieme in due gruppi (Classificazione binaria) calcolando la probabilità di ogni elemento dell'insieme.
Fasi della regressione logistica
Nella regressione logistica, Decidiamo una soglia di probabilità. Se la probabilità di un particolare elemento è maggiore della soglia di probabilità, Classifichiamo quell'elemento in un gruppo o viceversa.
passo 1
Per calcolare la separazione binaria, primo, determiniamo la linea più adatta seguendo i passaggi della Regressione Lineare.
passo 2
La linea di regressione che otteniamo dalla regressione lineare è molto suscettibile ai valori anomali. Perciò, Non farà un buon lavoro nel classificare due classi.
Perciò, Il valore stimato viene convertito in probabilità dandolo in pasto alla funzione sigmoide.
L'equazione sigmoidea:

Come possiamo vedere in Fig. 3, Possiamo dare in pasto qualsiasi numero reale alla funzione sigmoide e restituirà un valore compreso tra 0 e 1.
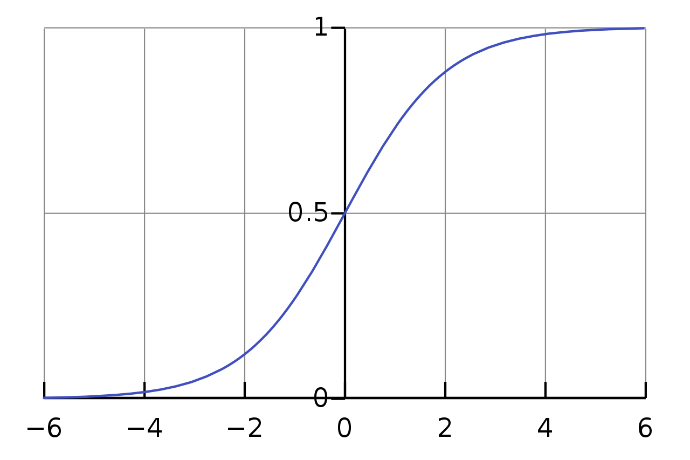
Fig 2: Curva sigmoidea (immagine tratta da Wikipedia)
Perciò, Se alimentiamo l'output ? valore alla funzione sigmoide risintonizza un valore di probabilità compreso tra 0 e 1.
passo 3
Finalmente, Il valore di output della funzione sigmoide diventa 0 oh 1 (Valori discreti) in base al valore soglia. Generalmente, Impostare il valore di soglia su 0,5. così, Otteniamo la classificazione binaria.
Ora che abbiamo l'idea di base di come la regressione lineare e la regressione logistica siano correlate, Esaminiamo il processo con un esempio.
Esempio
Consideriamo un problema in cui ci viene fornito un set di dati contenente l'altezza e il peso di un gruppo di persone. Il nostro compito è quello di prevedere il peso per le nuove voci nella colonna Altezza.
Quindi possiamo scoprire che questo è un problema di regressione in cui costruiremo un modello di regressione lineare. Addestreremo il modello con i valori di altezza e peso forniti. Una volta addestrato il modello, Possiamo prevedere il peso per un dato valore di altezza sconosciuto.
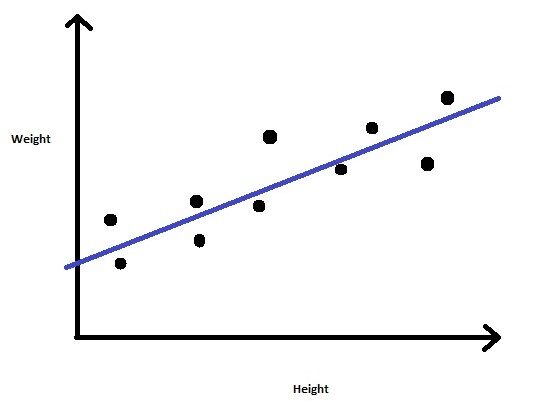
Fig 3: Regressione lineare
Supponiamo ora di avere un campo aggiuntivo Obesità E dobbiamo classificare se una persona è obesa o meno in base alla sua altezza e al suo peso proporzionati. Questo è chiaramente un problema di classificazione in cui dobbiamo separare il set di dati in due classi (obesi e non obesi).
Quindi, per il nuovo problema, possiamo seguire nuovamente i passaggi della Regressione Lineare e costruire una linea di regressione. Questa volta, La linea si baserà su due parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... Height e Weight e la linea di regressione si adatteranno tra due set di valori discreti. Poiché questa linea di regressione è molto suscettibile ai valori anomali, Non verrà utilizzato per classificare due classi.
Per ottenere un posizionamento migliore, Forniremo i valori di output della linea di regressione alla funzione sigmoide. La funzione sigmoide restituisce la probabilità di ogni valore di output della retta di regressione. Ora, sulla base di un valore di soglia predefinito, Possiamo facilmente classificare l'output in due classi: obesi o non obesi.
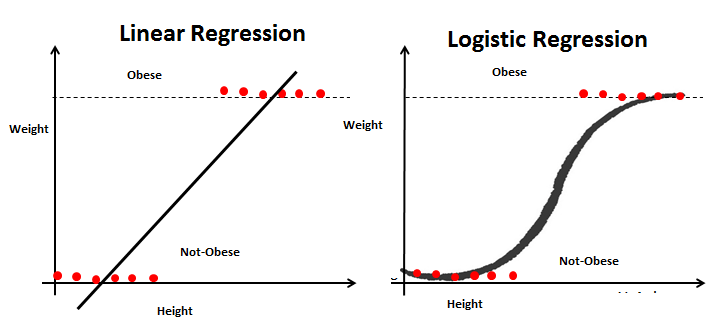
Finalmente, Possiamo riassumere le somiglianze e le differenze tra questi due modelli.
Le somiglianze tra regressione lineare e regressione logistica
- Sia la regressione lineare che la regressione logistica sono algoritmi di apprendimento automatico supervisionato.
- Regressione lineare e regressione logistica, Entrambi i modelli sono modelli di regressione parametrica, vale a dire, Entrambi i modelli utilizzano equazioni lineari per le previsioni.
Queste sono tutte le somiglianze che abbiamo tra questi due modelli.
tuttavia, In termini di funzionalità, Questi due sono completamente diversi. Di seguito sono riportate le differenze.
Le differenze tra regressione lineare e regressione logistica
- La regressione lineare viene utilizzata per gestire i problemi di regressione, mentre la regressione logistica viene utilizzata per gestire i problemi di classificazione.
- La regressione lineare fornisce un output continuo, Tuttavia, la regressione logistica fornisce un output discreto.
- Lo scopo della regressione lineare è trovare la linea più adatta, mentre la regressione logistica è un passo avanti e adatta i valori della linea alla curva sigmoidea.
- Il metodo per calcolare la funzione di perdita nella regressione lineare è l'errore quadratico medio, mentre la regressione logistica è la stima di massima verosimiglianza.
Nota: Al momento della stesura di questo articolo, Ho dato per scontato che il lettore abbia già familiarità con il concetto di base di regressione lineare e regressione logistica. Spero che questo articolo spieghi la relazione tra questi due concetti.





