Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
introduzione
In questo articolo, aprenderemos cómo una de las técnicas de apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute... utilizadas para encontrar la precisión de Set di dati sul cancro al seno, ma so che la maggior parte dei tecnici non sa di cosa stiamo parlando, inizieremo dalle basi per poi passare al nostro argomento. Primo, faremo una breve introduzione al deep learning e poi, ¿qué es la neuronale rossoLe reti neurali sono modelli computazionali ispirati al funzionamento del cervello umano. Usano strutture note come neuroni artificiali per elaborare e apprendere dai dati. Queste reti sono fondamentali nel campo dell'intelligenza artificiale, consentendo progressi significativi in attività come il riconoscimento delle immagini, Elaborazione del linguaggio naturale e previsione delle serie temporali, tra gli altri. La loro capacità di apprendere schemi complessi li rende strumenti potenti.. artificial?
Cos'è l'apprendimento profondo??
Se parliamo di deep learning, capisci solo che è un sottoinsieme o una sottoparte dell'apprendimento automatico. Possiamo dire che il deep learning è una funzione dell'intelligenza artificiale che imita il cervello umano ed elabora quei dati e crea modelli da utilizzare nel processo decisionale.
L'apprendimento profondo è il tipo di apprendimento automatico che è un po' come il cervello umano. Utilizza una struttura multistrato di algoritmi chiamati reti neurali. I loro algoritmi cercano di copiare i dati che gli umani analizzerebbero con una certa struttura logica. Conosciuto anche come rete neurale profonda o apprendimento neurale profondo.
Nell'apprendimento profondo esiste un concetto chiamato Rete neurale artificiale che discuteremo brevemente di seguito.:
Artificiale neuronale rosso
Come suggerisce il nome, rete neurale artificiale, è la rete dei neuroni artificiali. Si riferisce a un modello ispirato biologicamente nel cervello. Possiamo dire che di solito è una rete computazionale basata su reti neurali biologiche che costruiscono la struttura del cervello umano.
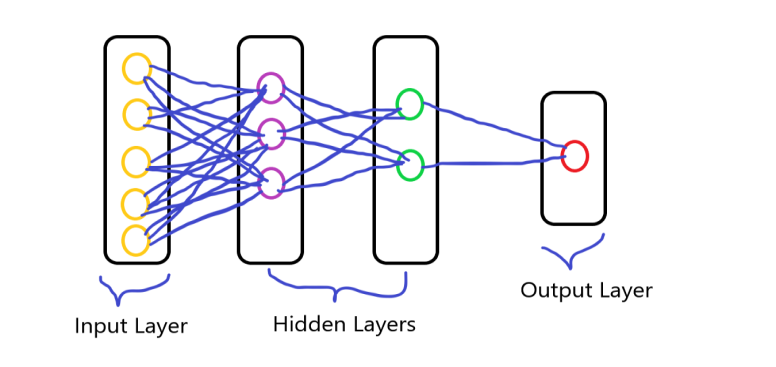
Sapete tutti che i neuroni sono interconnessi tra loro nel nostro cervello e nel processo di trasmissione dei dati. È simile ai neuroni del cervello umano che sono interconnessi tra loro, la rete neurale è costituita da un gran numero di neuroni artificiali, chiamate unità disposte in una sequenza di strati. avere i vari strati di neuroni e formare una rete completa. questi neuroni sono chiamati nodi.
Si compone di tre strati che è:
- Livello di inputIl "livello di input" si riferisce al livello iniziale in un processo di analisi dei dati o nelle architetture di reti neurali. La sua funzione principale è quella di ricevere ed elaborare le informazioni grezze prima che vengano trasformate dagli strati successivi. Nel contesto dell'apprendimento automatico, La corretta configurazione del livello di input è fondamentale per garantire l'efficacia del modello e ottimizzarne le prestazioni in attività specifiche....
- Mantello nascosto
- Livello di outputIl "Livello di output" è un concetto utilizzato nel campo della tecnologia dell'informazione e della progettazione di sistemi. Si riferisce all'ultimo livello di un modello o di un'architettura software che è responsabile della presentazione dei risultati all'utente finale. Questo livello è fondamentale per l'esperienza dell'utente, poiché consente l'interazione diretta con il sistema e la visualizzazione dei dati elaborati....
Creare ANN utilizzando un set di dati sul cancro al seno
Ora passiamo al nostro argomento, qui prenderemo il set di dati e quindi creeremo la rete neurale artificiale e classificheremo la diagnosi, primo, prendiamo un set di dati sul cancro al seno e poi andiamo avanti.
Set di dati: Set di dati sul cancro al seno
Dopo aver scaricato il set di dati, importeremo le librerie importanti che sono necessarie per ulteriori elaborazioni.
Importa librerie
#importare panda importa panda come pd #import numpy importa numpy come np importa matplotlib.pyplot come plt import seaborn come sb
Qui importiamo i panda, NumPy e alcune librerie di visualizzazione.
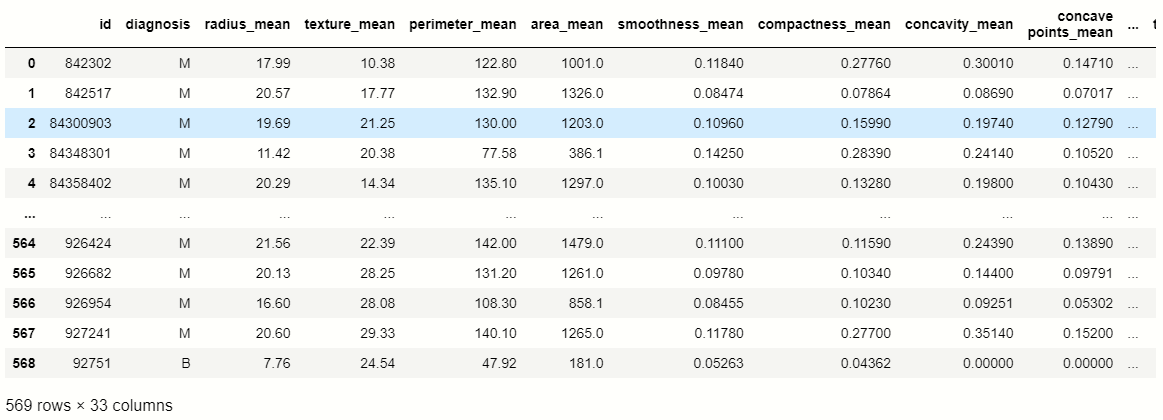
Ora carichiamo il nostro set di dati usando i panda:
df = pd.read_csv('Cancro_seno.csv')
df
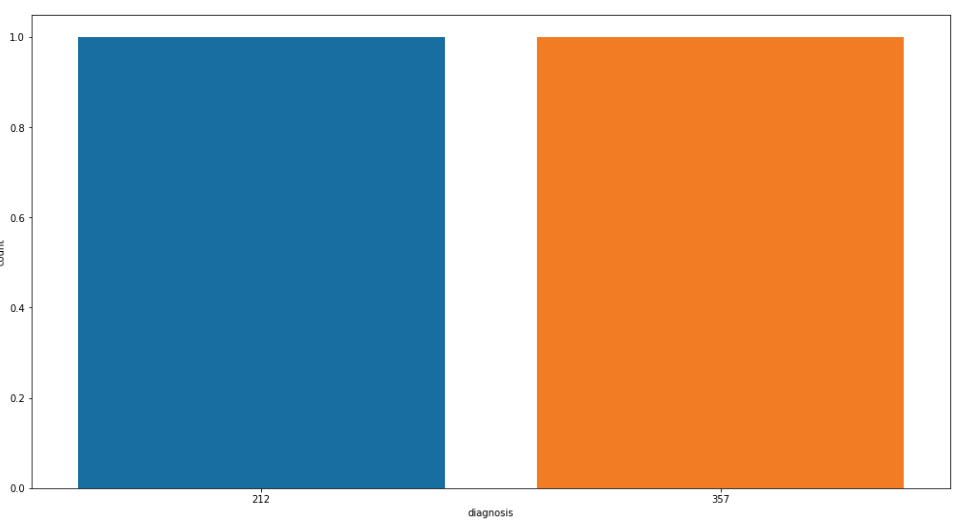
In questo set di dati, puntiamo al 'diagnosi’ colonna caratteristiche, quindi controlliamo il conteggio dei valori di quella colonna usando i panda:
# conteggio dei valori delle variabili in 'diagnosi' df['diagnosi'].value_counts()

Ora visualizziamo i conteggi dei valori delle “colonne diagnostiche”: per una migliore comprensione
Visualizza conti a valore
plt.figure(figsize=[17,9]) sb.countplot(df['diagnosi'].value_counts()) plt.mostra()
Valori nulli
Nel set di dati, dobbiamo controllare i valori nulli che sono presenti all'interno delle variabili per le quali usiamo i panda:
df.isnull().somma()
Dopo aver eseguito il programma, concludiamo che il nome della funzione 'Unnamed': 32’ contiene tutti i valori null, quindi eliminiamo o scartiamo quella colonna.
#caratteristica di caduta df.drop(["Senza nome": 32','ID'],asse = 1, posto = vero)
Variabili indipendenti e dipendenti
Ora è il momento di dividere il set di dati in variabili indipendenti e dipendenti, per questo creiamo due variabili, uno rappresenta indipendente e l'altro rappresenta dipendente.
# variabili indipendenti
x = df.drop('diagnosi',asse=1)
#variabili dipendenti
y = df.diagnosi
Gestione del valore categoriale
Cuando imprimimos la variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... dipendente e quindi vediamo che contengono dati categorici e dobbiamo convertire i dati categorici in formato binario per un'ulteriore elaborazione. Perciò, usiamo Scikit learn Label Encoder per codificare i dati categorici.
da sklearn.preprocessing import LabelEncoder #creare l'oggetto lb = LabelEncoder() y = lb.fit_transform(e)
Divisione dati
Ahora es el momento de dividir los datos en partes de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... e test:
da sklearn.model_selection import train_test_split xtrain,xtest,ytrain,ytest = train_test_split(X,e,test_size=0.3,random_state=40)
Scala i dati
Quando abbiamo creato la rete neurale artificiale, dobbiamo ridimensionare i dati a numeri più piccoli perché l'algoritmo di deep learning moltiplica i pesi e i dati di input dei nodi e richiede molto tempo, quindi per ridurre quel tempo ridimensioniamo i dati.
scalare, usiamo scikit impara Scalatore standard modulo, scaliamo il set di dati di training e test:
#importazione di StandardScaler da sklearn.preprocessing import StandardScaler #creare un oggetto sc = Scala standard() xtrain = sc.fit_transform(xtrain) xtest = sc.transform(xtest)
Da qui iniziamo a creare la rete neurale artificiale, per questo importiamo le librerie importanti che vengono utilizzate per creare ANN:
#importare keras importare keras #importazione di moduli sequenziali da keras.models import Sequential # importare il modulo denso per i livelli nascosti da keras.layers import Dense #importare le funzioni di attivazione da keras.layers import LeakyReLU,PRELU,ELU da keras.layers import Dropout
Creazione di livelli
Dopo aver importato quelle librerie, creiamo i tre tipi di strati:
- Livello di input
- Mantello nascosto
- Livello di output
Primo, creiamo il modello:
#creazione del modello classificatore = Sequenziale()
UN sequenziale El modelo es apropiado para una pila simple de capas donde cada capa tiene exactamente un tensoreI tensori sono strutture matematiche che generalizzano concetti come scalari e vettori. Sono utilizzati in varie discipline, compresa la fisica, Ingegneria e Machine Learning, per rappresentare dati multidimensionali. Un tensore può essere visualizzato come una matrice multidimensionale, che consente di modellare relazioni complesse tra variabili diverse. La loro versatilità e capacità di gestire grandi volumi di informazioni li rendono strumenti fondamentali nell'analisi e nell'elaborazione dei dati.... de entrada y un tensor de salida.
Ora creiamo gli strati della rete neurale:
#primo livello nascosto classificatore.add(Denso(unità=9,kernel_initializer="lui_uniforme",attivazione = 'rileggere',input_dim=30)) #secondo livello nascosto classificatore.add(Denso(unità=9,kernel_initializer="lui_uniforme",attivazione = 'rileggere')) # ultimo livello o livello di output classificatore.add(Denso(unità=1,kernel_initializer="glorot_uniform",attivazione='sigmoide'))
Nel seguente codice, il metodo Dense viene utilizzato per creare i livelli, en el que usamos parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... fundamentales. Il primo parametro è Nodi di uscita, il Il secondo è l'inizializzatore per la matrice dei pesi del kernel, el tercero es la funzione svegliaLa funzione di attivazione è un componente chiave nelle reti neurali, poiché determina l'output di un neurone in base al suo input. Il suo scopo principale è quello di introdurre non linearità nel modello, Consentendo di apprendere modelli complessi nei dati. Ci sono varie funzioni di attivazione, come il sigma, ReLU e tanh, Ognuno con caratteristiche particolari che influiscono sulle prestazioni del modello in diverse applicazioni.... y el último parámetro son los nodos de entrada o el número de características independientes.
Dopo aver eseguito questo codice, ne prendiamo il riepilogo utilizzando:
#prendendo il riassunto dei livelli
classificatore.riepilogo()

Compilando ANN
Ora compiliamo il nostro modello con l'ottimizzatore:
#compilazione dell'ANN classificatore.compila(ottimizzatore="Adamo",perdita="binary_crossentropy",metriche=['precisione'])
Adeguamento della ANN ai dati di training
Dopo aver compilato il modello, dobbiamo adattare la ANN ai dati di addestramento per la previsione:
#fitting the ANN to the training set
model = classifier.fit(xtrain,ytrain,batch_size=100,epoche=100)

il adattarsi() Il metodo adatta la ANN ai dati di addestramento, nei parametri impostiamo i valori specifici di ogni variabile come dimensione del lotto, epoche, eccetera. Finalmente, abbiamo trovato un eccellente punteggio di precisione, quindi il nostro modello si adatta perfettamente ai dati di allenamento.
Dopo aver addestrato i dati, dobbiamo anche testare il punteggio di accuratezza dei dati del test, vediamo dopo:
#ora test per i dati di prova y_pred = classificatore.predict(test)
Quando si esegue questo codice, abbiamo scoperto che y_pred conteneva i diversi valori, quindi convertiamo i valori di previsione in valori di soglia come True, Impostore.
#convertire i valori y_pred = (y_pred>0.5) Stampa(y_pred)

Matrice di punteggiatura e confusione
Ora controlliamo la matrice di confusione e il punteggio dei valori previsti.
da sklearn.metrics import confusione_matrix
da sklearn.metrics import precision_score
cm = confusione_matrice(ytest,y_pred)
punteggio = precision_score(ytest,y_pred)
Stampa(cm)
Stampa('il punteggio è:',punto)
Produzione:-
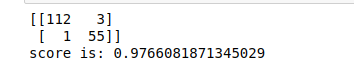
Visualizza matrice di confusione
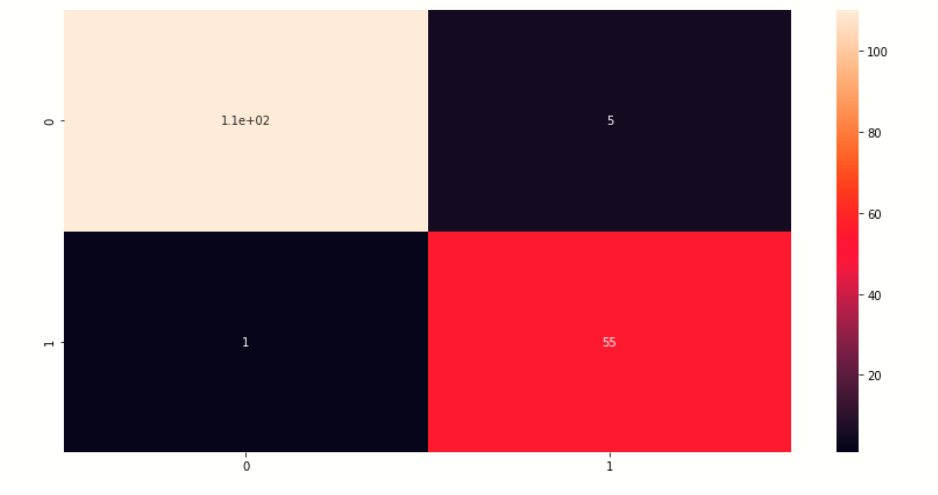
Qui visualizziamo la matrice di confusione dei valori di previsione.
# creazione di una mappa termica della matrice di compressione plt.figure(figsize=[14,7]) sb.heatmap(cm,annot=Vero) plt.mostra()
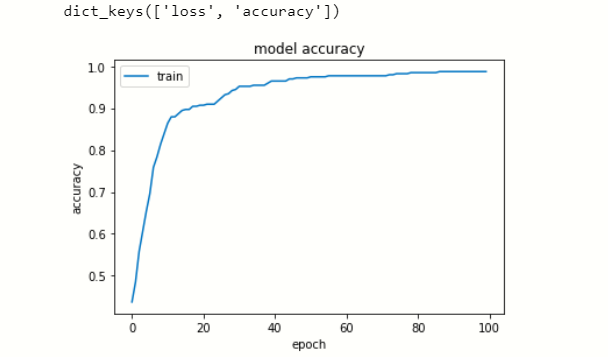
Visualizza la cronologia dei dati
Ora visualizziamo la perdita e la precisione in ogni epoca.
# elenca tutti i dati nella cronologia
Stampa(chiavi.storia.modello())
# riassumere la storia per la precisione
plt.trama(modello.storia['precisione'])
plt.titolo("precisione del modello")
plt.ylabel('precisione')
plt.xlabel('epoca')
plt.legend(['treno', 'test'], loc ="superiore sinistro")
plt.mostra()
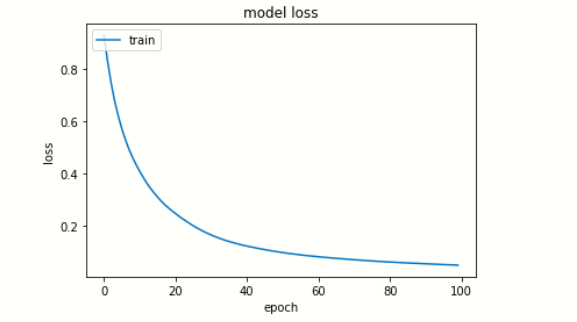
# riassumere la storia per la perdita
plt.trama(modello.storia['perdita'])
plt.titolo("perdita di modello")
plt.ylabel('perdita')
plt.xlabel('epoca')
plt.legend(['treno', 'test'], loc ="superiore sinistro")
plt.mostra()
Modello di risparmio
Finalmente, salviamo il nostro modello.
#salvare il modello
classificatore.salva('Nome_file.h5')
Nota finale
Questa è la mia prima ANN creata in deep learning, Sono un principiante nell'apprendimento profondo. Faccio del mio meglio per spiegare questo articolo, spero ti piaccia. Grazie per aver letto questo articolo.
Connettiti con me su LinkedIn: Profilo
Grazie.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





