introduzione
Il riepilogo del testo è una di quelle applicazioni dell'elaborazione del linguaggio naturale (PNL) che avrà sicuramente un grande impatto sulle nostre vite. Con i media digitali in crescita e le pubblicazioni in costante crescita, Chi ha tempo per rivedere gli articoli / documenti / libri completi per decidere se sono utili o meno? fortunatamente, questa tecnologia è qui.
Ti sei imbattuto nell'app mobile?? in pantaloncini? È un'applicazione di notizie innovativa che converte gli articoli di notizie in un riepilogo di 60 parole. Ed è proprio quello che impareremo in questo articolo.: Riepilogo testo automatico.
Il riepilogo automatico del testo è uno dei problemi più impegnativi e interessanti nel campo dell'elaborazione del linguaggio naturale. (PNL). È un processo di generazione di un riepilogo di testo conciso e significativo da più risorse di testo, come i libri, articoli di notizie, i post del blog, articoli di ricerca, e-mail e tweet.
La domanda di sistemi di sintesi del testo automatizzati è in aumento in questi giorni grazie alla disponibilità di grandi quantità di dati testuali.
Attraverso questo articolo, esploreremo i domini del testo sommario. Capiremo come funziona l'algoritmo TextRank e lo implementeremo anche in Python. Allaccia la tua cintura di sicurezza, Sarà un viaggio divertente!
Sommario
- Approcci di sintesi del testo
- Comprendere l'algoritmo TextRank
- Comprendere l'affermazione del problema
- Implementazione dell'algoritmo TextRank
- Qual è il prossimo?
Approcci di sintesi del testo
Il riepilogo automatico del testo ha attirato l'attenzione già nel decennio del 1950. UN lavoro di ricerca, pubblicato da Hans Peter Luhn alla fine degli anni '90. 1950, intitolato “Creazione automatica di abstract di letteratura”, ha utilizzato caratteristiche come la frequenza delle parole e la frequenza delle frasi per estrarre frasi importanti dal testo a fini di sintesi.
Altro importante indagare, interpretato da Harold P. Edmundson alla fine 1960, metodi usati come la presenza di parole chiave, le parole usate nel titolo che compaiono nel testo e la disposizione delle frasi, estrarre frasi significative per il riepilogo del testo. Da allora, sono stati pubblicati molti studi importanti ed entusiasmanti per affrontare la sfida del riepilogo automatico del testo.
TIl riepilogo dell'estensione può essere suddiviso in due categorie: Riepilogo estrattivo e Astratto astratto.
- Riepilogo estrattivo: Questi metodi si basano sull'estrazione di più parti, come frasi e frasi, un pezzo di testo e impilali per creare un riassunto. Perciò, Identificare le frasi corrette da riassumere è della massima importanza in un metodo estrattivo.
- Astratto astratto: Questi metodi utilizzano tecniche avanzate di PNL per generare un riassunto completamente nuovo.. Alcune parti di questo sommario potrebbero non apparire nemmeno nel testo originale.
In questo articolo, ci concentreremo sul riassunto estrattivo tecnica.
Comprendere l'algoritmo TextRank
Prima di iniziare con l'algoritmo TextRank, c'è un altro algoritmo con cui dovremmo familiarizzare: l'algoritmo PageRank. Infatti, Questo TextRank davvero ispirato! PageRank viene utilizzato principalmente per classificare le pagine Web nei risultati di ricerca online. Capiamo rapidamente le basi di questo algoritmo con l'aiuto di un esempio.
Algoritmo PageRank
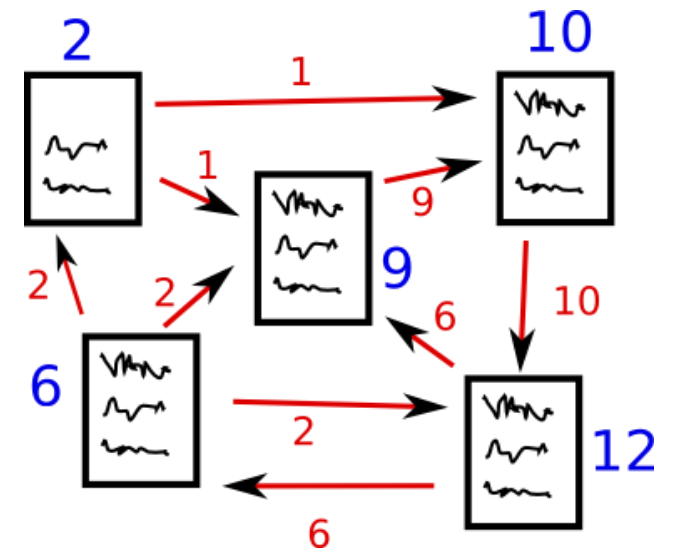
Fonte: http://www.scottbot.net/HIAL/
Supponiamo di avere 4 siti web: w1, w2, w3 e w4. Queste pagine contengono collegamenti che puntano a vicenda. Alcune pagine potrebbero non avere alcun collegamento; si chiamano pagine sospese.

- La pagina web w1 ha collegamenti a w2 e w4
- w2 ha collegamenti per w3 e w1
- w4 ha collegamenti solo per la pagina web w1
- w3 non ha collegamenti e, così, si chiamerà pagina sospesa
Per classificare queste pagine, dovremmo calcolare un punteggio chiamato Punteggio PageRank. Questo punteggio è la probabilità che un utente visiti quella pagina.
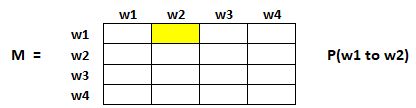
Per catturare le probabilità che gli utenti navighino da una pagina all'altra, creeremo un quadrato matrice M, che ha n righe e n colonne, dove Nord è il numero di pagine web.
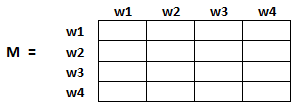
Ogni elemento di questa matrice denota la probabilità che un utente passi da una pagina web all'altra. Ad esempio, la cella evidenziata sotto contiene la probabilità di transizione da w1 a w2.
L'inizializzazione delle quote è spiegata nei seguenti passaggi:
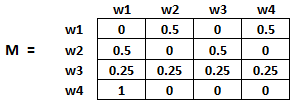
- Probabilità di passare dalla pagina i alla j, vale a dire, m[ io ][ J ], è inizializzato con 1 / (numero di link univoci sul sito web wi)
- Se non c'è alcun collegamento tra la pagina i e j, allora la probabilità sarà inizializzata con 0
- Se un utente è atterrato su una pagina sospesa, si presume che abbia la stessa probabilità di passare a qualsiasi pagina. Perciò, m[ io ][ J ] sarà inizializzato con 1 / (numero di pagine web)
Perciò, nel nostro caso, l'array M verrà inizializzato come segue:
Finalmente, i valori in questo array verranno aggiornati in modo iterativo per raggiungere le classifiche della pagina web.
Algoritmo dell'intervallo di testo
Comprendiamo l'algoritmo TextRank, ora che conosciamo il PageRank. Ho elencato le somiglianze tra questi due algoritmi di seguito:
- Invece di pagine web, usiamo frasi.
- La somiglianza tra due frasi qualsiasi è usata come equivalente alla probabilità di transizione della pagina web.
- I punteggi di somiglianza sono memorizzati in una matrice quadrata, simile alla matrice M usata per PageRank
TextRank è una tecnica di sintesi del testo estrattiva e non supervisionata. Diamo un'occhiata al flusso dell'algoritmo TextRank che seguiremo:
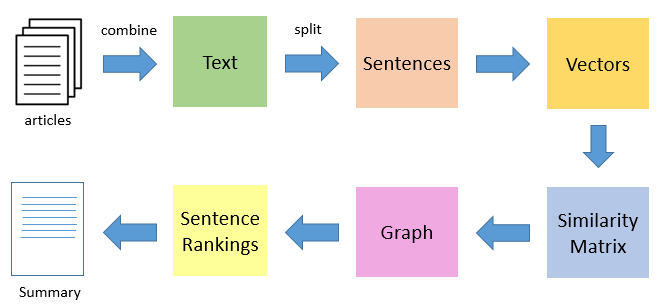
- Il primo passo sarebbe concatenare tutto il testo contenuto negli articoli.
- Quindi dividere il testo in singole frasi
- Nel prossimo passo, troveremo la rappresentazione vettoriale (intarsi di parole) per ogni frase.
- Le somiglianze tra i vettori di frase vengono calcolate e memorizzate in una matrice.
- Dopo, la matrice di somiglianza viene convertita in un grafico, con frasi come vertici e punteggi di somiglianza come bordi, per calcolare l'intervallo di frasi.
- Finalmente, un certo numero di frasi meglio classificate formano il riassunto finale.
Quindi, senza più preamboli, Accendi i nostri taccuini Jupyter e iniziamo a programmare!!
Nota: Se vuoi saperne di più sulla teoria dei grafi, Ti consiglio di controllare questo Articolo.
Comprendere l'affermazione del problema
Essere un grande appassionato di tennis, Cerco sempre di tenermi aggiornato su ciò che sta accadendo in questo sport controllando religiosamente il maggior numero possibile di aggiornamenti sul tennis online. tuttavia, Questo si è rivelato un lavoro piuttosto difficile!! Ci sono troppe risorse e il tempo è un limite.
Perciò, Ho deciso di progettare un sistema che potesse prepararmi un riepilogo puntato scansionando più articoli. Come fare questo? Questo è quello che ti mostrerò in questo tutorial. Applicheremo l'algoritmo TextRank su un set di dati di articoli raschiati per creare un riassunto carino e conciso.
Nota che questo è essenzialmente un singolo dominio, attività di riepilogo multi-documento, vale a dire, prenderemo più articoli come input e genereremo un singolo riepilogo puntato. Il riepilogo del testo multidominio non è trattato in questo articolo, ma sentiti libero di provarlo alla fine.
Puoi scaricare il set di dati che utilizzeremo da qui.
Implementazione dell'algoritmo TextRank
Quindi, senza più preamboli, accendi i tuoi notebook Jupyter e implementiamo ciò che abbiamo imparato finora.
Importa le librerie richieste
Primo, importare le librerie che sfrutteremo per questa sfida.
importa numpy come np
importa panda come pd
import nltk
nltk.download('Punto') # esecuzione una tantum
importare re
Leggi i dati
Ora leggiamo il nostro set di dati. Ho fornito il link per scaricare i dati nella sezione sopra (nel caso te lo fossi perso).
df = pd.read_csv("tennis_articles_v4.csv")
Ispeziona i dati
Diamo una rapida occhiata ai dati.
df.head()

Ho 3 colonne nel nostro set di dati: 'id_articolo', "testo_articolo"’ y "fonte". Siamo più interessati alla colonna "testo_articolo"’ in quanto contiene il testo degli articoli. Imprimamos algunos de los valores de la variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... solo para ver cómo se ven.
df['testo_articolo'][0]
Produzione:
"Maria Sharapova non ha praticamente amici come tenniste nel WTA Tour. Il giocatore russo non ha problemi a parlarne apertamente e in una recente intervista ha detto: 'Io non davvero nascondi troppo i sentimenti. Penso che tutti sappiano che questo è il mio lavoro qui. Quando sono in campo o quando sono in campo a giocare, Sono un concorrente e voglio battere ogni singola persona se sono negli spogliatoi o dall'altra parte della rete...
df['testo_articolo'][1]
BASILEA, Svizzera (AP), Roger Federer è arrivato alla 14a finale di Swiss Indoors della sua carriera battendo Daniil Medvedev, settimo seme 6-1, 6-4 di sabato. Alla ricerca del nono titolo all'evento della sua città natale, e un 99° globale, Federer will play 93th-ranked Marius Copil on Sunday. Federer dominated the 20th-ranked Medvedev and had his first match-point chance to break serve again at 5-1...
df['testo_articolo'][2]
Roger Federer ha rivelato che gli organizzatori della rilanciata e condensata Coppa Davis gli hanno concesso tre giorni per decidere se si sarebbe impegnato nella controversa competizione. Parlando al torneo Swiss Indoors dove lo farà gioca la finale di domenica contro il qualificato rumeno Marius Copil, il numero tre del mondo ha detto che dato il lasso di tempo incredibilmente breve per prendere una decisione, ha rinunciato a qualsiasi impegno...
Ora abbiamo 2 opzioni: possiamo riassumere ogni articolo singolarmente o possiamo generare un unico riassunto per tutti gli articoli. Per il nostro scopo, andremo avanti con quest'ultimo.
Dividi il testo in frasi
Ora il prossimo passo è dividere il testo in singole frasi. Useremo il send_tokenize () funzione di nltk libreria per farlo.
da nltk.tokenize import sent_tokenize frasi = [] per s in df['testo_articolo']: frasi.append(send_tokenize(S)) frasi = [y per x nelle frasi per y in x] # appiattire la lista
Stampiamo alcuni elementi dalla lista. frasi.
frasi[:5]
Produzione:
['Maria Sharapova non ha praticamente amici come tenniste nel WTA Tour.', "Il giocatore russo non ha problemi a parlarne apertamente e in un recente intervista ha detto: 'In realtà non nascondo troppo i sentimenti.", "Penso che tutti sappiano che questo è il mio lavoro qui.", "Quando sono in campo o quando sono in campo a giocare, Sono un concorrente e voglio battere ogni singola persona che sia nel spogliatoio o attraverso la rete. Quindi non sono io quello di cui iniziare una conversazione il tempo e sappi che nei prossimi minuti devo andare a cercare di vincere una partita di tennis.", "Sono una ragazza abbastanza competitiva."]
Descarga GloVe Word Embeddings
Guanto Gli intarsi di parole sono rappresentazioni vettoriali di parole. Questi intarsi di parole verranno utilizzati per creare vettori per le nostre frasi. Avremmo anche potuto usare gli approcci Bag-of-Words o TF-IDF per creare caratteristiche per le nostre frasi, ma questi metodi ignorano l'ordine delle parole (e il numero di funzioni è solitamente abbastanza grande).
Useremo il pre-addestrato Wikipedia 2014 + Gigaword 5 Vettori di guanti disponibili qui. Avviso: la dimensione di questi incorporamenti di parole è 822 MB.
!wget http://nlp.stanford.edu/data/glove.6B.zip !decomprimi il guanto*.zip
Estraiamo le parole o i vettori di parole incorporati.
# Estrai vettori di parole
word_embeddings = {}
f = aperto('guanto.6B.100d.txt', codifica='utf-8')
per linea in f:
valori = riga.split()
parola = valori[0]
coefs = es asarray(valori[1:], dtype="float32")
word_embeddings[parola] = coefs
f.chiudi()
len(word_embeddings)
400000
Ora abbiamo vettori di parole per 400.000 diversi termini memorizzati nel dizionario: 'parole_incorporamenti'.
Pre-elaborazione del testo
È sempre una buona pratica rendere i tuoi dati testuali il più possibile privi di rumore. Quindi, facciamo un po' di pulizia di base del testo.
# rimuovi le punteggiature, numeri e caratteri speciali
clean_sentences = pd.Serie(frasi).str.replace("[^ a-zA-Z]", " ")
# fare alfabeti minuscoli
frasi_pulite = [Più lentamente() per s in clean_sentences]
Elimina le parole vuote (parole di uso comune di una lingua: è, sono, il, di, in, eccetera.) presente nelle preghiere. Se non l'hai scaricato nltk-stopwords, quindi esegui la seguente riga di codice:
nltk.download('stopword')
Ora possiamo importare le parole vuote.
da nltk.corpus importa parole non significative
stop_words = stopwords.parole('inglese')
Definiamo una funzione per rimuovere queste stopword dal nostro set di dati.
# funzione per rimuovere le stopword
def remove_stopwords(suo):
sen_new = " ".aderire([io per io in sen se non in stop_words])
return sen_new
# rimuovi le stopword dalle frasi frasi_pulite = [remove_stopwords(r.split()) per r in clean_sentences]
noi useremo frasi_pulite per creare vettori per le frasi nei nostri dati con l'aiuto dei vettori di parole GloVe.
Rappresentazione vettoriale di frasi
# Estrai vettori di parole
word_embeddings = {}
f = aperto('guanto.6B.100d.txt', codifica='utf-8')
per linea in f:
valori = riga.split()
parola = valori[0]
coefs = es asarray(valori[1:], dtype="float32")
word_embeddings[parola] = coefs
f.chiudi()
Ora, creiamo vettori per le nostre preghiere. Cercheremo prima i vettori (ciascuno degli articoli di dimensioni 100) per le parole costituenti in una frase e poi prenderemo la media / media di quei vettori per arrivare a un vettore consolidato per la frase.
vettori_frase = []
per i in clean_sentences:
se len(io) != 0:
v = somma([word_embeddings.get(w, np.zero((100,))) per w in i.split()])/(len(io.diviso())+0.001)
altro:
v = np.zero((100,))
frase_vettori.append(v)
Nota: Per ulteriori best practice per la pre-elaborazione del testo, puoi consultare il nostro video corso, Elaborazione del linguaggio naturale (PNL) usando Python.
Preparazione della matrice di similarità
Il prossimo passo è trovare somiglianze tra le frasi, e useremo l'approccio della somiglianza del coseno per questa sfida. Creiamo una matrice di somiglianza vuota per questo compito e completiamo con le somiglianze coseno dalle frasi.
Definiamo prima un array a dimensione zero (n * n). Inizializzeremo questa matrice con i punteggi di similarità del coseno delle frasi. Qui, Nord è il numero di frasi.
# matrice di somiglianza sim_mat = np.zero([len(frasi), len(frasi)])
Useremo la somiglianza del coseno per calcolare la somiglianza tra una coppia di frasi.
da sklearn.metrics.pairwise import cosene_similarity
E inizializza la matrice con i punteggi di similarità del coseno.
per io nel raggio d'azione(len(frasi)):
per j nell'intervallo(len(frasi)):
se io != j:
sim_mat[io][J] = coseno_somiglianza(vettori_frase[io].rimodellare(1,100), vettori_frase[J].rimodellare(1,100))[0,0]
Applicazione dell'algoritmo PageRank
prima di continuare, convertire la matrice di somiglianza sim_mat su un grafico. I nodi di questo grafico rappresenteranno le frasi e i bordi rappresenteranno i punteggi di somiglianza tra le frasi. In questo grafico, applicheremo l'algoritmo PageRank per arrivare alla classificazione delle frasi.
importa networkx come nx nx_graph = nx.from_numpy_array(sim_mat) punteggi = nx.pagerank(nx_graph)
Estrazione riassuntiva
Finalmente, è ora di estrarre le prime N frasi in base alle loro classifiche per la generazione del riepilogo.
frasi_classificate = ordinate(((punteggi[io],S) per me,s in enumerare(frasi)), inverso=Vero)
# Estrai in alto 10 frasi come il riassunto per io nel raggio d'azione(10): Stampa(frasi_classificate[io][1])
Quando sono in campo o quando sono in campo a giocare, Sono un concorrente e voglio battere ogni singola persona che siano negli spogliatoi o dall'altra parte della rete. Quindi non sono io quello che inizia una conversazione sul meteo e sappi che nei prossimi minuti devo andare a provare a vincere una partita di tennis. I principali giocatori ritengono che un grande evento a fine novembre combinato con uno a gennaio prima dell'Australian Open lo farà significa troppo tennis e troppo poco riposo. Parlando al torneo Swiss Indoors dove giocherà la finale di domenica contro il qualificato rumeno Marius Copil, il numero tre del mondo ha detto che dato il lasso di tempo incredibilmente breve per prendere una decisione, ha rinunciato qualsiasi impegno. "Mi sentivo come se le migliori settimane in cui dovevo conoscere i giocatori mentre giocavo fossero le settimane della Fed Cup o il settimane olimpiche, non necessariamente durante i tornei. Attualmente al nono posto, Nishikori con una vittoria potrebbe passare all'interno 125 punti del taglio per l'evento a otto a Londra il mese prossimo. Ha usato il suo primo break point per chiudere il primo set prima di salire 3-0 nel secondo e concludendo il vincere al suo primo match point. Lo spagnolo ha rotto Anderson due volte nel secondo, ma non ha avuto un'altra possibilità sul servizio del sudafricano nel set finale. "Abbiamo anche avuto l'impressione che in questa fase potrebbe essere meglio giocare delle partite che allenarsi. Il concorso è impostato per caratterizzare 18 paesi nel novembre 18-24 finali a Madrid l'anno prossimo, e sostituirà le classiche sfide casa-trasferta giocate quattro volte all'anno per decenni. Federer ha detto all'inizio di questo mese a Shanghai che le sue possibilità di giocare la Coppa Davis erano quasi inesistenti.
Ed eccoci! Un riassunto straordinario, ordinato, conciso e utile per i nostri articoli.
Qual è il prossimo?
Il riepilogo automatico del testo è un tema caldo di ricerca e, in questo articolo, abbiamo coperto solo la punta dell'iceberg. Nel futuro, exploraremos la técnica de resumen de texto abstracto donde el apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute... juega un papel importante. Cosa c'è di più, possiamo anche esaminare le seguenti attività di riepilogo:
Specifico per il problema
- Riepilogo testo multidominio
- Riepilogo documento singolo
- Riepilogo del testo in più lingue (fonte in una lingua e sommario in un'altra lingua)
Specifico dell'algoritmo
- Riepilogo del testo utilizzando RNN e LSTM
- Resumen de texto mediante Apprendimento per rinforzoL'apprendimento per rinforzo è una tecnica di intelligenza artificiale che consente a un agente di imparare a prendere decisioni interagendo con un ambiente. Attraverso il feedback sotto forma di premi o punizioni, L'agente ottimizza il proprio comportamento per massimizzare le ricompense accumulate. Questo approccio viene utilizzato in una varietà di applicazioni, Dai videogiochi alla robotica e ai sistemi di raccomandazione, distinguendosi per la sua capacità di apprendere strategie complesse....
- Riassunto del testo per mezzo di reti generative conflittuali (GAN)
Note finali
Spero che questo post ti abbia aiutato a capire il concetto di riepilogo automatico del testo. Ha una varietà di casi d'uso e ha generato applicazioni di grande successo. O per sfruttare la tua attività o semplicemente per la tua conoscenza, il riassunto del testo è un approccio con cui tutti gli appassionati di PNL dovrebbero avere familiarità.
Cercherò di trattare la tecnica di sintesi del testo astratto utilizzando tecniche avanzate in un prossimo articolo.. Intanto, sentiti libero di usare la sezione commenti qui sotto per farmi sapere i tuoi pensieri o porre qualsiasi domanda tu possa avere su questo articolo..





