Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
La creazione del riconoscimento facciale è considerata un compito molto semplice nel campo della visione artificiale., ma è estremamente difficile avere una pipeline in grado di prevedere volti con sfondi complessi quando si hanno più volti, diverse condizioni di illuminazione e diverse scale dell'immagine. Questo blog descriverà come creiamo un modello che in alcuni casi può superare gli umani. Il nostro set di dati è composto da 3 Lezioni (Non posso condividere i dati a causa di problemi di riservatezza, ma ti mostrerò com'è). Classe 1 it Jesse Eisenberg (attore), classe 2 è Mila Kunis (pop star) e la classe 0, Chiunque. Ecco com'era il nostro treno (80 immagini) e dati di prova (più di 1800 immagini).
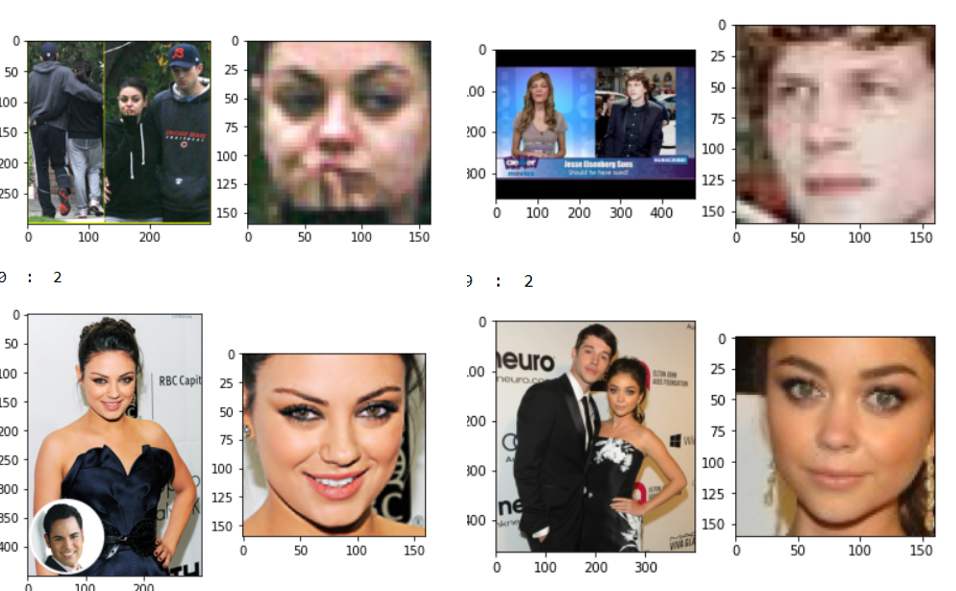
Questi sono i nostri dati di prova e i volti estratti da quelle immagini, questi dati sono estremamente complessi a causa di più facce, sfondi complessi e molte immagini pixelate. In secondo luogo, i nostri dati del treno sono estremamente puliti come mostrato nell'immagine qui sotto. Abbiamo molte differenze nella distribuzione dei dati di prova e di addestramento. Abbiamo bisogno di una tecnica che possa generalizzare bene indipendentemente dal numero di campioni necessari e da quanto diversi siano i dati del treno e dei test.

La tecnica che useremo per questo compito è, primo, generar la incrustación facial a partir de un modelo de apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute... y luego aplicar un clasificador simple.
Utilizzo di FACENET
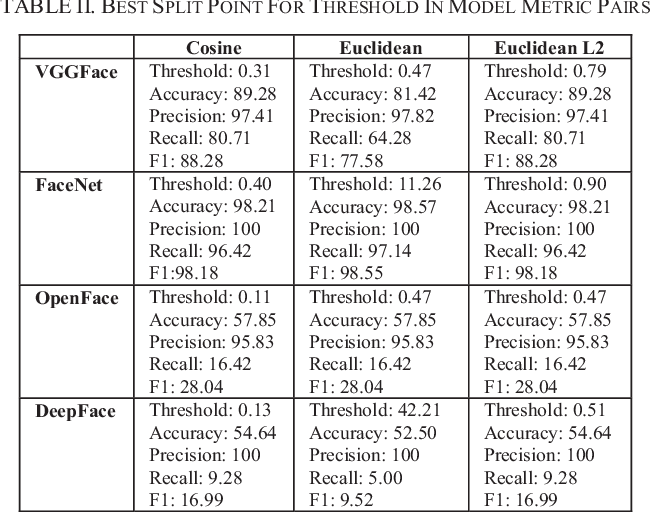
Per spingere davvero i limiti del rilevamento dei volti, vedremo alcuni metodi all'avanguardia. Le moderne tecniche di estrazione del viso hanno fatto uso di Deep Convolution Networks. Come sappiamo tutti, le funzionalità create dai moderni framework di deep learning sono in realtà migliori della maggior parte delle funzionalità costruite a mano. controlliamo 4 modelli di apprendimento profondo, vale a dire, FaceNet (Google), DeepFace (Facebook), VGGFface (Oxford) e OpenFace (CMU). Di questi 4 Modelli FaceNet ci stava dando il miglior risultato. Generalmente, FaceNet offre risultati migliori degli altri 3 Modelli.
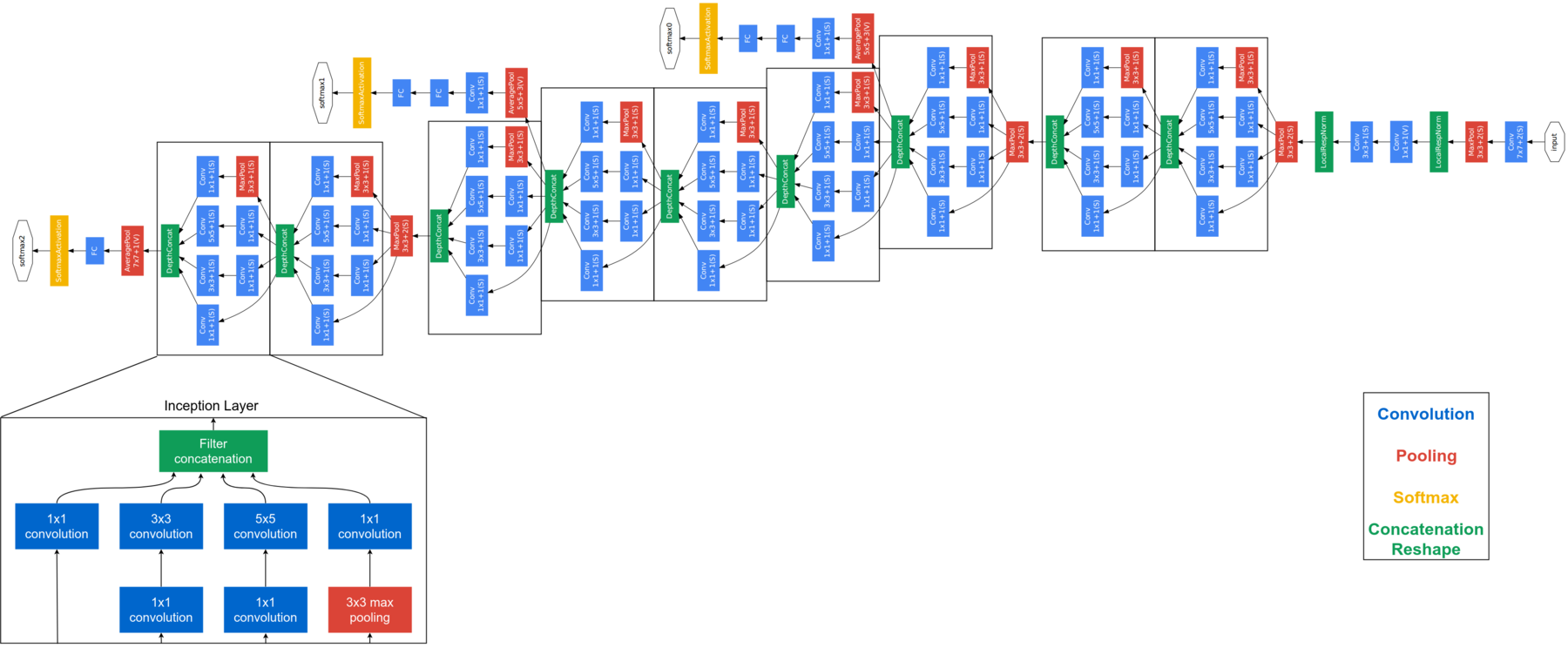
FaceNet è considerato un modello di nuova generazione sviluppato da Google. Si basa sul livello iniziale, spiegare l'architettura completa di FaceNet va oltre lo scopo di questo blog. Di seguito è riportata l'architettura FaceNet. FaceNet usa módulos de inicio en bloques para reducir la cantidad de parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... entrenables. Questo modello acquisisce immagini RGB di 160 × 160 e genera un incorporamento di dimensioni 128 per una foto. Per questa implementazione, avremo bisogno di un paio di funzioni aggiuntive. Pero antes de enviar la imagen de la cara a FaceNet, necesitamos extraer las caras de las imágenes.
rivelatore = dlib.cnn_face_detection_model_v1("../input/pretrained-models-faces/mmod_human_face_detector.dat")
def rect_to_bb(Rect):
# Prendere un limite previsto da DLIB e convertirlo
# al formato (X, e, w, h) come faremmo normalmente
# with OpenCV
x = rect.rect.left()
y = rect.rect.top()
w = rect.rect.right() - x
h = rect.rect.bottom() - e
# restituire una tupla di (X, e, w, h)
Restituzione (X, e, w, h)
def dlib_corrected(dati, data_type="treno"):
#We set the size of the image
dim = (160, 160)
data_images=[]
#If we are processing training data we need to keep track of the labels
if data_type=='train':
data_labels=[]
#Loop over all images
for cnt in range(0,len(dati)):
immagine = dati[img][cnt]
#The large images are resized
if image.shape[0] > 1000 e image.shape[1] > 1000:
immagine = cv2.resize(Immagine, (1000,1000), interpolazione = cv2.INTER_AREA)
#The image is converted to grey-scales
gray = cv2.cvtColor(Immagine, cv2.COLOR_BGR2GRAY)
#Detect the faces
rects = detector(grigio, 1)
sub_images_data = []
#Loop over all faces in the image
for (io, Rect) in enumerare(rects):
#Convertire il rettangolo di selezione in spigoli
(X, e, w, h) = rect_to_bb(Rect)
#Here we copy and crop the face out of the image
clone = image.copy()
Se(X>=0 e y>=0 e w>=0 e h>=0):
crop_img = clone[e:y+h, X:x+w]
altro:
crop_img = clone.copy()
#We resize the face to the correct size
rgbImg = cv2.resize(crop_img, Oscuro, interpolazione = cv2.INTER_AREA)
#In the test set we keep track of all faces in an image
if data_type == 'train':
sub_images_data = rgbImg.copy()
altro:
sub_images_data.append(rgbImg)
#If no face is detected in the image we will add a NaN
if(len(rects)==0):
if data_type == 'train':
sub_images_data = np.empty(Oscuro + (3,))
sub_images_data[:] = np.nan
if data_type=='test':
nan_images_data = np.empty(Oscuro + (3,))
nan_images_data[:] = np.nan
sub_images_data.append(nan_images_data)
#Qui aggiungiamo l'immagine(S) to the list we will return
data_images.append(sub_images_data)
#And add the label to the list
if data_type=='train':
data_labels.append(dati['class'][cnt])
#Lastly we need to return the correct number of arrays
if data_type=='train':
restituire np.array(data_images), np.array(data_labels)
altro:
restituire np.array(data_images)
USANDO DLIB
DLIB es un modelo ampliamente utilizado para detectar rostros. En nuestros experimentos, abbiamo scoperto che dlib produce risultati migliori di HAAR, anche se notiamo che alcuni miglioramenti possono ancora essere apportati:
- Se i bordi della faccia del rettangolo vengono spostati fuori dall'immagine, prendiamo l'intera immagine invece del ritaglio del viso. È implementato come segue:
- e (X> = 0 e e> = 0 y w> = 0 eh> = 0):
- crop_img = clon[e:y+h, X:x+w]
- il riposo:
- e (X> = 0 e e> = 0 y w> = 0 eh> = 0):
- Per le immagini di prova, invece di salvare un volto per immagine, salviamo tutti i volti per la previsione.
- Invece di un rilevatore basato su HOG, possiamo usare un rilevatore basato sulla CNN. Come questi miglioramenti sono progettati per ottimizzare il tuo utilizzo con FaceNet, definiremo un nuovo rilevamento del volto corretto.
Il blocco di codice sopra estrae i volti dall'immagine, per molte immagini abbiamo diverse facce, quindi dobbiamo mettere tutte quelle facce in una lista. Per estrarre le facce che stiamo usando dlib.cnn_face_detection_model_v1, nota che non dovresti inserire immagini di dimensioni molto grandi in questo, altrimenti otterrai un errore di memoria dlib. Se un'immagine non ha un volto, immagazzina NaN in quei posti. Let's FaceNet queste immagini di dati ora. La pre-elaborazione di cui sopra è necessaria solo per i dati di test, i dati del treno sono già puliti, cosa si può vedere nelle immagini sopra. Una volta che abbiamo finito di ottenere gli intarsi facciali dai dati del treno, ottenere intarsi facciali per i dati di test, pero primero debe usar el preprocesamiento proporcionado en el bloque de código anterior para extraer caras de los datos de prueba.
def get_embedding(modello, face_pixels):
# scale pixel values
face_pixels = face_pixels.astype('float32')
# standardizzare i valori dei pixel su più canali (globale)
Significare, std = face_pixels.mean(), face_pixels.std()
face_pixels = (face_pixels - Significare) / standard
# transform face into one sample
samples = expand_dims(face_pixels, asse=0)
# make prediction to get embedding
yhat = model.predict(campioni)
ritorno yhat[0]
modello = load_model('.. /input/pretraininged-models-faces/facenet_keras.h5')
svmtrainX = []
per indice, face_pixels in enumerare(nuovoTrenoX):
embedding = get_embedding(modello, face_pixels)
svmtrainX.append(incorporamento)
Después de generar las incrustaciones para el addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... y la prueba, useremo SVM per la classificazione. Perché SVM, Puoi chiedere? Con molta esperienza, Sono venuto a sapere che le funzioni basate su SVM + DL può superare qualsiasi altro metodo, anche ai metodi di deep learning, quando la quantità di dati è piccola.
from sklearn.svm import SVC from sklearn.pipeline import make_pipeline from sklearn.naive_bayes import GaussianNB from sklearn.neural_network import MLPClassifier from sklearn.preprocessing import StandardScaler, MinMaxScaler, Normalizer linear_model = make_pipeline(StandardScaler(), SVC(kernel="rbf", C=1,0, gamma=0,01, probabilità = Vero)) linear_model.fit(svmtrainX, svmtrainY)
Una vez que el SVM está entrenado, es hora de hacer algunas pruebas, pero nuestros datos de prueba tienen varias caras en una lista. Quindi, siempre que tengamos a Jesse o Mila en una imagen, ignoraremos la clase 0 y cuando tanto Jesse como Mila estén presentes en una imagen, entonces elegiremos la que nos brinde la mayor precisión.
predicitons=[]
per me in corrected_test_X:
flag=0
if(len(io)==1):
embedding = get_embedding(modello, io[0])
tmp_output = linear_model.predict([incorporamento])
predicitons.append(tmp_output[0])
altro:
tmp_sub_pred = []
tmp_sub_prob = []
per j in i:
j= j.astype(int)
embedding = get_embedding(modello, J)
tmp_output = linear_model.predict([incorporamento])
tmp_sub_pred.append(tmp_output[0])
tmp_output_prob = linear_model.predict_log_proba([incorporamento])
tmp_sub_prob.append(np.max(tmp_output_prob[0]))
Se 1 in tmp_sub_pred e 2 a tmp_sub_pred:
index_1 = np.where(np.array(tmp_sub_pred)==1)[0][0]
index_2 = np.where(np.array(tmp_sub_pred)==2)[0][0]
Se(tmp_sub_prob[indice_1] > tmp_sub_prob[indice_2] ):
predicitons.append(1)
altro:
predicitons.append(2)
elifa 1 non in tmp_sub_pred e 2 non in tmp_sub_pred:
predicitons.append(0)
elifa 1 in tmp_sub_pred e 2 non in tmp_sub_pred:
predicitons.append(1)
elifa 1 non in tmp_sub_pred e 2 a tmp_sub_pred:
predicitons.append(2)
DISCUSSIONE
Osservazioni finali, questo è un set di dati molto piccolo, quindi i risultati possono cambiare enormemente anche quando si aggiungono o si rimuovono alcune immagini. Nel nostro test abbiamo scoperto che ci ha tradito molte volte, c'era in giro 20 immagini nel test che sono state erroneamente previste da noi ma correttamente dal nostro modello. Confermiamo il risultato atteso cercando quelle immagini su Google.
Le reti neurali profonde possono estrarre funzionalità più significative rispetto ai modelli di apprendimento automatico. tuttavia, il crollo di queste grandi reti è la necessità di una grande quantità di dati. Siamo riusciti ad affrontare questo problema utilizzando un modello precedentemente addestrato, un modello che è stato addestrato su un set di dati molto più ampio per conservare la conoscenza di come codificare le immagini facciali, che poi usiamo per i nostri scopi in questa sfida. Cosa c'è di più, La messa a punto di SVM ci ha davvero aiutato ad andare oltre la precisione del 95%.





