Per ogni reclutamento, le aziende pubblicano annunci online, riferimenti e controllarli manualmente.
Le aziende di solito inviano migliaia di curriculum per ogni pubblicazione.
Quando le aziende raccolgono curriculum tramite annunci online, classificali in base alle tue esigenze.
Dopo aver raccolto i curriculum, le aziende chiudono annunci e portali di applicazioni online.
Dopo, inviare i curricula raccolti al team di reclutamento.
Diventa molto difficile per i team di assunzione leggere il curriculum e selezionare il curriculum in base al requisito, nessun problema se ci sono uno o due curriculum, ma è molto difficile rivedere i curriculum di 1000 e scegli il meglio.
Risolvere questo problema, Oggi in questo articolo leggeremo e rivedremo il curriculum utilizzando l'apprendimento automatico con Python in modo da poter completare le giornate di lavoro in pochi minuti.
2. Cos'è la valutazione del curriculum vitae?
Scegliere le persone giuste per il lavoro è la più grande responsabilità di tutte le aziende, poiché la scelta del giusto gruppo di persone può accelerare la crescita del business in modo esponenziale.
Analizzeremo qui un esempio di azienda di questo tipo, quello che conosciamo come dipartimento IT. Sappiamo che il reparto IT non tiene il passo con i mercati in crescita.
A causa di molti grandi progetti con grandi aziende, il tuo team non ha tempo per leggere i curriculum e scegliere il miglior curriculum in base alle tue esigenze.
Per risolvere questo tipo di problemi, l'azienda sceglie sempre una terza parte il cui compito è fare il curriculum secondo il requisito. Queste aziende sono conosciute come l'organizzazione del servizio di assunzione. Questa è la schermata di riepilogo delle informazioni.
Il lavoro di selezionare i migliori talenti, Compiti, concorsi di codifica online, tra tanti altri, noto anche come schermata di ripresa.
Mancanza di tempo, le grandi aziende non hanno abbastanza tempo per aprire i curriculum, quindi devono ricorrere all'aiuto di qualsiasi altra compagnia. Quindi devono pagare soldi. Che è un problema molto serio.
Risolvere questo problema, l'azienda vuole avviare da sola la schermata di ripresa utilizzando un algoritmo di apprendimento automatico.
3. Riprendi lo screening utilizzando l'apprendimento automatico
In questa sezione, vedremo l'implementazione passo passo di Riprendi screening usando python.
3.1 Dati utilizzati
Abbiamo dati pubblicamente disponibili da Kaggle. È possibile scaricare i dati utilizzando il seguente link.
https://www.kaggle.com/gauravduttakiit/resume-dataset
3.2 Analisi esplorativa dei dati
Diamo una rapida occhiata ai dati che abbiamo.
resumeDataSet.head()

Ci sono solo due colonne che abbiamo nei dati. Di seguito è riportata la definizione di ciascuna colonna.
Categoria: Tipo di lavoro per il quale è adattato il curriculum vitae.
Riprendere: CV del candidato
resumeDataSet.shape
Produzione:
(962, 2)
Ci sono 962 osservazioni che abbiamo nei dati. Ogni osservazione rappresenta i dettagli completi di ogni candidato, per quello che abbiamo 962 riprende per la selezione.
Vediamo quali diverse categorie abbiamo nei dati.
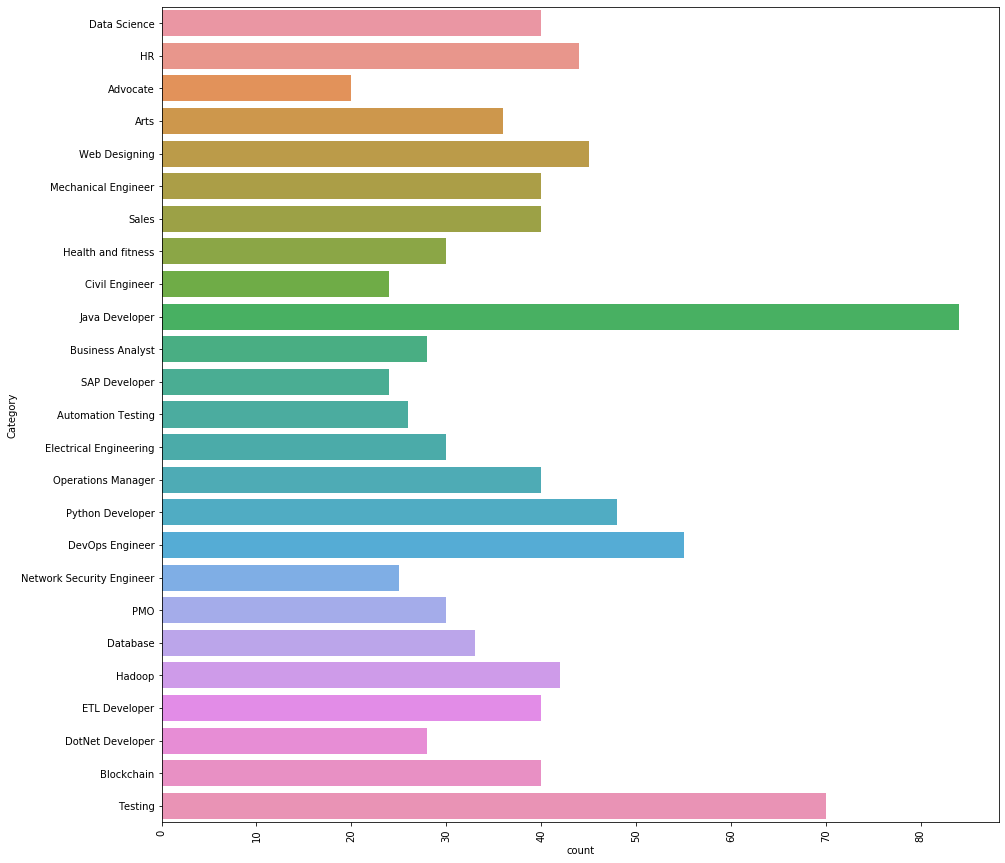
Ci sono 25 diverse categorie che abbiamo nei dati. Il 3 Le principali categorie di lavoro che abbiamo nei dati sono le seguenti.
Sviluppatore Java, Test e DevOps Engineer.
Invece di contare o frequenza, Possiamo anche visualizzare la distribuzione delle categorie di lavoro in percentuale come mostrato di seguito:
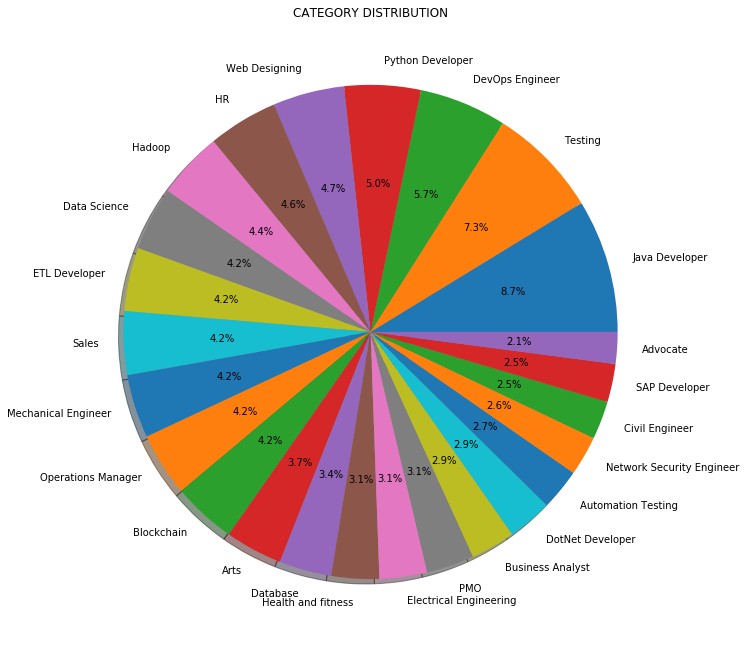
3.3 Pretrattamento dei dati
passo 1: Cancella colonna "Riprendi"’
In questo passaggio, rimuoviamo tutte le informazioni non necessarie dai curriculum come URL, hashtag e caratteri speciali.
def cleanResume(riprendereTesto):
resumeText = re.sub('httpS+s*', ' ', riprendereTesto) # rimuovi URL
resumeText = re.sub('RT|cc', ' ', riprendereTesto) # rimuovere RT e cc
resumeText = re.sub('#S+', '', riprendereTesto) # rimuovere gli hashtag
resumeText = re.sub('@S+', ' ', riprendereTesto) # rimuovere le menzioni
resumeText = re.sub('[%S]' % ri.scappare("""!"#$%&'()*+,-./:;<=>[e-mail protetta][]^_`{|}~"""), ' ', riprendereTesto) # rimuovi le punteggiature
resumeText = re.sub(R'[^x00-x7f]',R' ', riprendereTesto)
resumeText = re.sub('s+', ' ', riprendereTesto) # rimuovi gli spazi bianchi extra
ritorna il testo del curriculum
riprendereDataSet['ripristino_ripulito'] = resumeDataSet.Resume.apply(lambda x: pulitoRiprendi(X))
passo 2: 'Codifica categoria’
Ora, codificheremo la colonna "Categoria"’ usando LabelEncoding. Sebbene la colonna "Categoria"’ sono dati "nominali", stiamo usando LabelEncong perché la colonna "Category"’ è la nostra colonna 'target'. Al realizar LabelEncoding, ogni categoria diventerà una classe e creeremo un modello di classificazione multiclasse.
var_mod = ['Categoria']
le = LabelEncoder()
per io in var_mod:
riprendereDataSet[io] = le.fit_transform(riprendereDataSet[io])
passo 3: pre-elaborazione della colonna 'clean_resume'’
Qui preprocesseremo e convertiremo la colonna "clean_resume"’ nei vettori. Ci sono molti modi per farlo, come "Sacco di parole", 'Tf-Idf', "Parola2Vec"’ e una combinazione di questi metodi.
Useremo il "metodo Tf-Idf"’ per ottenere i vettori in questo approccio.
RichiestoText = resumeDataSet['ripristino_ripulito'].valori
richiestoTarget = resumeDataSet['Categoria'].valori
word_vectorizer = TfidfVectorizer(
sublinear_tf=Vero,
stop_words="inglese",
max_features=1500)
word_vectorizer.fit(testorichiesto)
WordFeatures = word_vectorizer.transform(testorichiesto)
Abbiamo "WordFeatures"’ come vettori e' richiestoTarget’ e target dopo questo passaggio.
3.4 Costruzione di modelli
Useremo il "metodo Uno vs Resto"’ con ‘KNeighborsClassifier’ per costruire questo modello di classificazione multiclasse.
noi useremo 80% de datos para addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... e 20% dati per la convalida. Dividiamo ora i dati in training e test set.
X_treno,X_test,y_train,y_test = train_test_split(Caratteristiche della parola,Target obbligatorio,stato_casuale=0, test_size=0.2) Stampa(X_train.shape) Stampa(X_test.shape)
Produzione:
(769, 1500) (193, 1500)
Poiché ora disponiamo di dati di test e allenamento, costruiamo il modello.
clf = OneVsRestClassifier(KNeighborsClassifier()) clf.fit(X_treno, y_train) predizione = clf.predict(X_test)
3.5 Risultati
Vediamo i risultati che abbiamo.
Stampa("Precisione del classificatore KNeighbors sul set di allenamento": {:.2F}'.formato(clf.score(X_treno, y_train)))
Stampa("Precisione del classificatore KNeighbors sul set di prova": {:.2F}'.formato(clf.score(X_test, y_test)))
Produzione:
Precisione del classificatore KNeighbors sul set di allenamento: 0.99 Precisione del classificatore KNeighbors sul set di prova: 0.99
Possiamo vedere che i risultati sono sorprendenti. Possiamo classificare ogni categoria di un dato curriculum con a 99% precisione.
Possiamo anche controllare il rapporto di classificazione dettagliato per ogni classe o categoria.
Stampa(metrics.classification_report(y_test, predizione))
Produzione:
supporto del punteggio f1 di richiamo di precisione
0 1.00 1.00 1.00 3
1 1.00 1.00 1.00 3
2 1.00 0.80 0.89 5
3 1.00 1.00 1.00 9
4 1.00 1.00 1.00 6
5 0.83 1.00 0.91 5
6 1.00 1.00 1.00 9
7 1.00 1.00 1.00 7
8 1.00 0.91 0.95 11
9 1.00 1.00 1.00 9
10 1.00 1.00 1.00 8
11 0.90 1.00 0.95 9
12 1.00 1.00 1.00 5
13 1.00 1.00 1.00 9
14 1.00 1.00 1.00 7
15 1.00 1.00 1.00 19
16 1.00 1.00 1.00 3
17 1.00 1.00 1.00 4
18 1.00 1.00 1.00 5
19 1.00 1.00 1.00 6
20 1.00 1.00 1.00 11
21 1.00 1.00 1.00 4
22 1.00 1.00 1.00 13
23 1.00 1.00 1.00 15
24 1.00 1.00 1.00 8
precisione 0.99 193
macro media 0.99 0.99 0.99 193
media ponderata 0.99 0.99 0.99 193
In cui si, 0, 1, 2…. sono le categorie di lavoro. Otteniamo i tag effettivi dal codificatore di tag che utilizziamo.
le classi_
Produzione:
['Avvocato', "Arti", "Test di automazione", "Blocca catena",'Analista di affari', 'Ingegnere civile', "Scienza dei dati", 'Banca dati',"Ingegnere DevOps", "Sviluppatore DotNet", "Sviluppatore ETL",'Ingegnere elettrico', "Risorse umane", 'Hadoop', 'Salute e fitness',"Sviluppatore Java", 'Ingegnere meccanico',"Ingegnere della sicurezza di rete", "Responsabile delle operazioni", 'PMO',"Sviluppatore Python", "Sviluppatore SAP", 'Saldi', 'Test',"Progettazione web"]
Qui 'Avvocato’ È la classe 0, 'Arte’ È la classe 1, e così via …
4. Codice
Qui puoi vedere l'implementazione completa ....
#Caricamento librerie
avvisi di importazione
warnings.filterwarnings('ignorare')
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib.gridspec import GridSpec
import re
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from scipy.sparse import hstack
from sklearn.multiclass import OneVsRestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
#Caricamento dati
resumeDataSet = pd.read_csv('../input/ResumeScreeningDataSet.csv' ,codifica='utf-8')
#EDA
plt.figure(figsize=(15,15))
plt.xticks(rotazione=90)
sns.countplot(y ="Categoria", data=resumeDataSet)
plt.savefig('../output/jobcategory_details.png')
#Grafico a torta
targetCounts = resumeDataSet['Categoria'].value_counts().reset_index()['Categoria']
targetLabels = resumeDataSet['Categoria'].value_counts().reset_index()['indice']
# Crea figure quadrate e assi
plt.figure(1, figsize=(25,25))
the_grid = GridSpec(2, 2)
plt.sottotrama(la griglia[0, 1], aspetto=1, titolo="DISTRIBUZIONE PER CATEGORIE")
source_pie = plt.pie(targetCounts, etichette=targetLabels, autopct="%1.1F%%", ombra=Vero, )
plt.savefig('../output/category_dist.png')
#Pre-elaborazione dei dati
def cleanResume(riprendereTesto):
resumeText = re.sub('httpS+s*', ' ', riprendereTesto) # rimuovi URL
resumeText = re.sub('RT|cc', ' ', riprendereTesto) # rimuovere RT e cc
resumeText = re.sub('#S+', '', riprendereTesto) # rimuovere gli hashtag
resumeText = re.sub('@S+', ' ', riprendereTesto) # rimuovere le menzioni
resumeText = re.sub('[%S]' % ri.scappare("""!"#$%&'()*+,-./:;<=>[e-mail protetta][]^_`{|}~"""), ' ', riprendereTesto) # rimuovi le punteggiature
resumeText = re.sub(R'[^x00-x7f]',R' ', riprendereTesto)
resumeText = re.sub('s+', ' ', riprendereTesto) # rimuovi gli spazi bianchi extra
ritorna il testo del curriculum
riprendereDataSet['ripristino_ripulito'] = resumeDataSet.Resume.apply(lambda x: pulitoRiprendi(X))
var_mod = ['Categoria']
le = LabelEncoder()
per io in var_mod:
riprendereDataSet[io] = le.fit_transform(riprendereDataSet[io])
RichiestoText = resumeDataSet['ripristino_ripulito'].valori
richiestoTarget = resumeDataSet['Categoria'].valori
word_vectorizer = TfidfVectorizer(
sublinear_tf=Vero,
stop_words="inglese",
max_features=1500)
word_vectorizer.fit(testorichiesto)
WordFeatures = word_vectorizer.transform(testorichiesto)
#Costruzione di modelli X_treno,X_test,y_train,y_test = train_test_split(Caratteristiche della parola,Target obbligatorio,stato_casuale=0, test_size=0.2) Stampa(X_train.shape) Stampa(X_test.shape) clf = OneVsRestClassifier(KNeighborsClassifier()) clf.fit(X_treno, y_train) predizione = clf.predict(X_test)
#Risultati
Stampa("Precisione del classificatore KNeighbors sul set di allenamento": {:.2F}'.formato(clf.score(X_treno, y_train)))
Stampa("Precisione del classificatore KNeighbors sul set di prova": {:.2F}'.formato(clf.score(X_test, y_test)))
Stampa("n Rapporto di classificazione per il classificatore %s:n%sn" % (clf, metrics.classification_report(y_test, predizione)))
5. conclusione
In questo articolo, Abbiamo imparato come l'apprendimento automatico e l'elaborazione del linguaggio naturale possono essere applicati per migliorare la nostra vita quotidiana attraverso l'esempio del rilevamento CV. Abbiamo appena risolto quasi 1000 riprende tra pochi minuti nelle rispettive categorie con a 99% precisione.
Contatta nella sezione commenti se hai domande.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





