Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
introduzione
Ciao lettori!
Il deep learning è utilizzato in molte applicazioni, come il rilevamento di oggetti, riconoscimento facciale, compiti di elaborazione del linguaggio naturale e molti altri. In questo blog costruirò un modello che verrà utilizzato per risolvere il Sudoku irrisolto da un'immagine utilizzando il deep learning, andiamo a librerie come OpenCV e TensorFlow. Se vuoi saperne di più su OpenCV, controllare questo Collegamento. Allora cominciamo.
- Se vuoi conoscere le librerie Python per l'elaborazione delle immagini, allora dai un'occhiata a questo Collegamento.
- Per altri articoli, Clicca qui.

Immagine Fonte
Il blog è diviso in tre parti:
Parte 1: Modello di classificazione delle cifre
Per prima cosa costruiremo e addestreremo una rete neurale sul set di dati dell'immagine Char74k per le cifre. Questo modello aiuterà a classificare le cifre delle immagini.
Parte 2: Leggere e rilevare il sudoku da un'immagine
Questa sezione contiene, identificare il puzzle da un'immagine con l'aiuto di OpenCV, ordina le cifre nel puzzle Sudoku rilevato usando Part 1, infine ottenere i valori delle celle Sudoku e memorizzarli in una matrice.
Parte 3: Risolvere il puzzle
Archivieremo l'array che abbiamo ottenuto in Pat-2 in forma di matrice e infine eseguiremo un ciclo di ricorsione per risolvere il puzzle..
IMPORTAZIONE DI LIBRERIE
Importeremo tutte le librerie richieste utilizzando i seguenti comandi:
import numpy as np import pandas as pd import seaborn as sns import matplotlib.pyplot as plt import os, random import cv2 from glob import glob import sklearn from sklearn.model_selection import train_test_split import tensorflow as tf from tensorflow import keras from tensorflow.keras.preprocessing.image import ImageDataGenerator from keras.preprocessing.image import ImageDataGenerator, load_img from keras.utils.np_utils import to_categorical from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Activation, Ritirarsi, Denso, Appiattire, Normalizzazione batch, Conv2D, MaxPooling2D from tensorflow.keras.optimizers import RMSprop from tensorflow.keras import backend as K from tensorflow.keras.preprocessing import image from sklearn.metrics import accuracy_score, classification_report from pathlib import Path from PIL import Image
Parte 1: Modello di classificazione delle cifre
In questa sezione, usaremos un modelo de clasificación de dígitos.
CARGANDO DATOS
Usaremos un conjunto de datos de imágenes para clasificar los números en una imagen. Los datos se especifican como características como imágenes y etiquetas como etiquetas.
#Loading the data data = os.listdir("cifre/cifre" ) data_X = [] data_y = [] data_classes = len(dati) per io nel raggio d'azione (0,data_classes): data_list = os.listdir("cifre/cifre" +"/"+str(io)) per j in data_list: pic = cv2.imread("cifre/cifre" +"/"+str(io)+"/"+J) pic = cv2.resize(Pic,(32,32)) data_X.append(Pic) data_y.append(io) se len(data_X) == len(data_y) : Stampa("Totale Dataponits = ",len(data_X)) # Labels and images data_X = np.array(data_X) data_y = np.array(data_y)

CONJUNTO DE DATOS DIVIDIDO
Estamos dividiendo el conjunto de datos en conjuntos de tren, prueba y validación como lo hacemos en cualquier problema de aprendizaje automático.
#Spliting the train validation and test sets
train_X, test_X, train_y, test_y = train_test_split(data_X,data_y,test_size=0.05)
treno_X, valid_X, train_y, valid_y = train_test_split(treno_X,train_y,test_size=0.2)
Stampa("Forma del set di allenamento = ",train_X.shape)
Stampa("Forma del set di convalida = ",valid_X.shape)
Stampa("Forma del set di prova = ",test_X.shape)

Procesamiento previo de las imágenes para la neuronale rossoLe reti neurali sono modelli computazionali ispirati al funzionamento del cervello umano. Usano strutture note come neuroni artificiali per elaborare e apprendere dai dati. Queste reti sono fondamentali nel campo dell'intelligenza artificiale, consentendo progressi significativi in attività come il riconoscimento delle immagini, Elaborazione del linguaggio naturale e previsione delle serie temporali, tra gli altri. La loro capacità di apprendere schemi complessi li rende strumenti potenti..
In una fase di pre-elaborazione, preprocessiamo le caratteristiche (immagini) scala di grigi, normalizzandoli e migliorandoli con l'equalizzazione dell'istogramma. Successivamente, convertirli in array NumPp e quindi modificarli e aumentare i dati.
def Prep(img): img = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) #making image grayscale img = cv2.equalizeHist(img) #Histogram equalization to enhance contrast img = img/255 #normalizing return img train_X = np.array(elenco(carta geografica(Compito a casa, treno_X))) test_X = np.array(elenco(carta geografica(Compito a casa, test_X))) valid_X= np.array(elenco(carta geografica(Compito a casa, valid_X))) #Reshaping the images train_X = train_X.reshape(train_X.shape[0], train_X.shape[1], train_X.shape[2],1) test_X = test_X.reshape(test_X.shape[0], test_X.shape[1], test_X.shape[2],1) valid_X = valid_X.reshape(valid_X.shape[0], valid_X.shape[1], valid_X.shape[2],1) #Augmentation datagen = ImageDataGenerator(width_shift_range=0,1, height_shift_range=0,1, zoom_range=0,2, shear_range=0,1, rotation_range=10) datagen.fit(treno_X)
Una codifica a caldo
In questa sezione, Useremo la codifica one-hot per taggare le classi.
train_y = to_categorical(train_y, data_classes) test_y = to_categorical(test_y, data_classes) valid_y = to_categorical(valid_y, data_classes)
COSTRUZIONE DEL MODELLO
Estamos utilizando una convolucional neuronale rossoReti neurali convoluzionali (CNN) sono un tipo di architettura di rete neurale progettata appositamente per l'elaborazione dei dati con una struttura a griglia, come immagini. Usano i livelli di convoluzione per estrarre le caratteristiche gerarchiche, il che li rende particolarmente efficaci nelle attività di riconoscimento e classificazione dei modelli. Grazie alla sua capacità di apprendere da grandi volumi di dati, Le CNN hanno rivoluzionato campi come la visione artificiale.. para la construcción de modelos. Consiste dei seguenti passaggi:
#Creating a Neural Network
model = Sequential()
modello.aggiungi((Conv2D(60,(5,5),input_shape=(32, 32, 1) ,imbottitura = 'Uguale' ,attivazione = 'rileggere')))
modello.aggiungi((Conv2D(60, (5,5),imbottitura="stesso",attivazione = 'rileggere')))
modello.aggiungi(MaxPooling2D(pool_size=(2,2)))
#modello.aggiungi(Ritirarsi(0.25))
modello.aggiungi((Conv2D(30, (3,3),imbottitura="stesso", attivazione = 'rileggere')))
modello.aggiungi((Conv2D(30, (3,3), imbottitura="stesso", attivazione = 'rileggere')))
modello.aggiungi(MaxPooling2D(pool_size=(2,2), passi=(2,2)))
modello.aggiungi(Ritirarsi(0.5))
modello.aggiungi(Appiattire())
modello.aggiungi(Denso(500,attivazione = 'rileggere'))
modello.aggiungi(Ritirarsi(0.5))
modello.aggiungi(Denso(10, attivazione='softmax'))
modello.riepilogo()
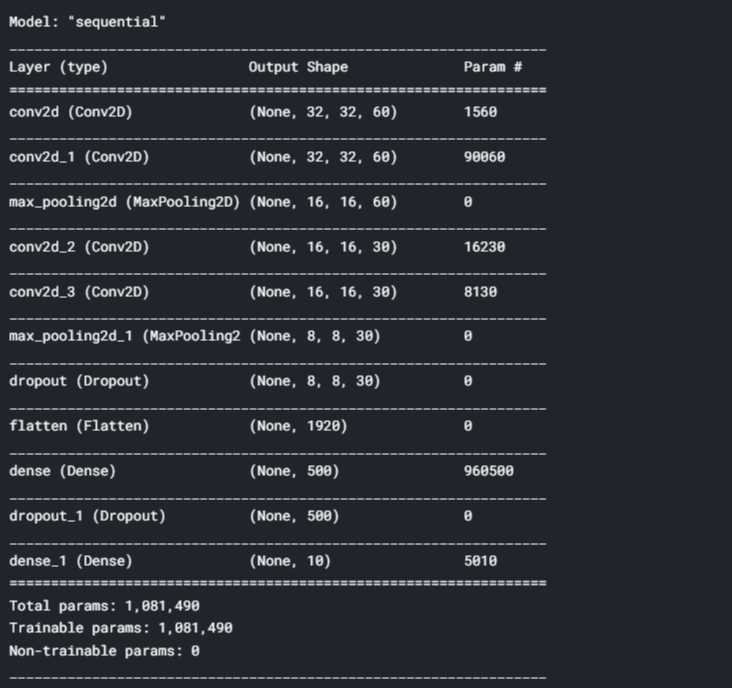
In questo passaggio, Compileremo il modello e testeremo il modello nel set di test come mostrato di seguito:
#Compiling the model optimizer = RMSprop(lr=0,001, rho=0,9, epsilon = 1e-08, decadimento=0,0) modello.compila(ottimizzatore=ottimizzatore,perdita="categorical_crossentropy",metriche=['precisione']) #Fit the model history = model.fit(datagen.flow(treno_X, train_y, batch_size=32), epoche = 30, validation_data = (valid_X, valid_y), verboso = 2, steps_per_epoch= 200) # Testing the model on the test set score = model.evaluate(test_X, test_y, verboso=0) Stampa('Punteggio del test=",punto[0]) Stampa("Accuratezza del test =', punto[1])

Parte 2: Leggere e rilevare il sudoku da un'immagine
LEGGI IL PUZZLE SUDOKU
Leggere un Sudoku usando OpenCv usando il seguente codice:
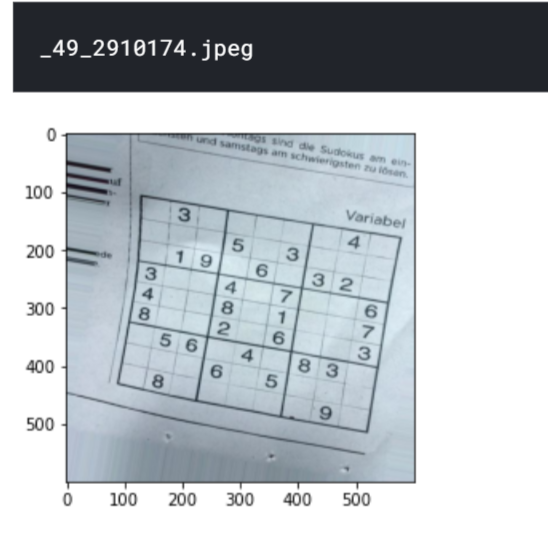
# Randomly select an image from the dataset
folder="sudoku-box-detection/aug"
a=random.choice(os.listdir(cartella))
Stampa(un)
sudoku_a = cv2.imread(cartella+'/'+a)
plt.figure()
plt.imshow(sudoku_a)
plt.mostra()
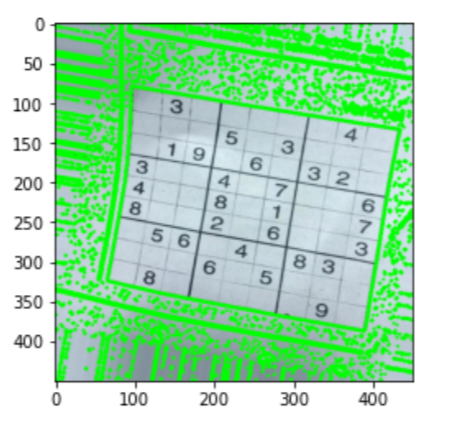
Preprocese la imagen para un análisis más detallado utilizando el siguiente código;
#Preprocessing image to be read sudoku_a = cv2.resize(sudoku_a, (450,450)) # funzione in scala di grigi, blur and change the receptive threshold of image def preprocess(Immagine): grigio = cv2.cvtColor(Immagine, cv2.COLOR_BGR2GRAY) sfocatura = cv2. GaussianBlur(grigio, (3,3),6) #sfocatura = cv2.bilateralFilter(grigio,9,75,75) threshold_img = cv2.adaptiveThreshold(sfocatura,255,1,1,11,2) return threshold_img threshold = preprocess(sudoku_a) #let's look at what we have got plt.figure() plt.imshow(soglia) plt.mostra()
DETECTANDO CONTORNO
In questa sezione, vamos a detectar el contorno. Seguimos detectando el contorno más grande de la imagen.
# Finding the outline of the sudoku puzzle in the image contour_1 = sudoku_a.copy() contour_2 = sudoku_a.copy() contorno, gerarchia = cv2.findContours(soglia,cv2. RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE) cv2.drawContours(contour_1, contorno,-1,(0,255,0),3) #let's see what we got plt.figure() plt.imshow(contour_1) plt.mostra()
El siguiente código se usa para obtener el Sudoku recortado y bien alineado al remodelarlo.
def main_outline(contorno):
più grande = np.array([])
max_area = 0
per i in contorno:
area = cv2.contourArea(io)
se area >50:
peri = cv2.arcLunghezza(io, Vero)
circa = cv2.approxPolyDP(io , 0.02* peri, Vero)
se area > max_area e len(Circa.) ==4:
biggest = approx
max_area = area
return biggest ,max_area
def reframe(scambio ferroviario):
points = points.reshape((4, 2))
points_new = np.zeros((4,1,2),dtype = np.int32)
add = points.sum(1)
points_new[0] = punti[np.argmin(Inserisci)]
points_new[3] = punti[np.argmax(Inserisci)]
diff = np.diff(scambio ferroviario, asse =1)
points_new[1] = punti[np.argmin(differenza)]
points_new[2] = punti[np.argmax(differenza)]
return points_new
def splitcells(img):
righe = np.vsplit(img,9)
scatole = []
per r in righe:
cols = np.hsplit(R,9)
per scatola in cols:
boxes.append(scatola)
return boxes
black_img = np.zeros((450,450,3), ad esempio uint8)
maggiore, maxArea = main_outline(contorno)
se biggest.size != 0:
più grande = reframe(maggiore)
cv2.drawContours(contour_2, più grande,-1, (0,255,0),10)
pts1 = np.float32(maggiore)
pts2 = np.float32([[0,0],[450,0],[0,450],[450,450]])
matrice = cv2.getPerspectiveTransform(pts1,pts2)
imagewrap = cv2.warpPerspective(sudoku_a,matrice,(450,450))
imagewrap = cv2.cvtColor(imagewrap, cv2.COLOR_BGR2GRAY)
plt.figure()
plt.imshow(imagewrap)
plt.mostra()
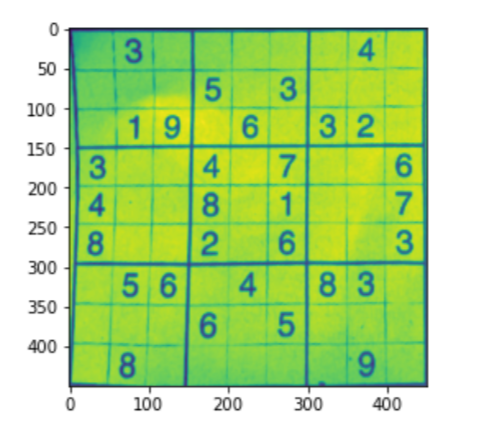
# Importing puzzle to be solved puzzle = cv2.imread("su-puzzle/su.jpg") #let's see what we got plt.figure() plt.imshow(rompicapo) plt.mostra()
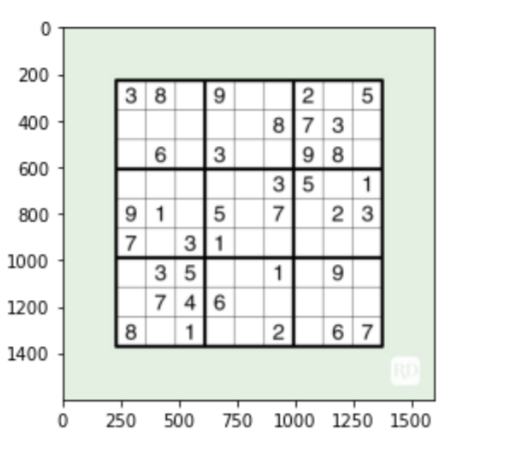
# Finding the outline of the sudoku puzzle in the image
su_contour_1= su_puzzle.copy()
su_contour_2= sudoku_a.copy()
su_contour, gerarchia = cv2.findContours(su_puzzle,cv2. RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)
cv2.drawContours(su_contour_1, su_contour,-1,(0,255,0),3)
black_img = np.zeros((450,450,3), ad esempio uint8)
su_biggest, su_maxArea = main_outline(su_contour)
se su_biggest.size != 0:
su_biggest = reframe(su_biggest)
cv2.drawContours(su_contour_2.su_biggest,-1, (0,255,0),10)
su_pts1 = np.float32(su_biggest)
su_pts2 = np.float32([[0,0],[450,0],[0,450],[450,450]])
su_matrix = cv2.getPerspectiveTransform(su_pts1, su_pts2)
su_imagewrap = cv2.warpPerspective(rompicapo,su_matrice,(450,450))
su_imagewrap =cv2.cvtColor(su_imagewrap, cv2.COLOR_BGR2GRAY)
plt.figure()
plt.imshow(su_imagewrap)
plt.mostra()
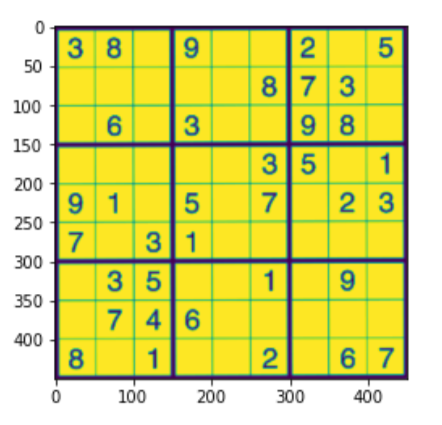
DIVIDI LE CELLE E CLASSIFICA LE CIFRE
In questa sezione, dividiamo le celle e classifichiamo le cifre.
- Prima dividi il sudoku in 81 celle con cifre o spazi vuoti
- Ritagliare le cellule
- Usa il modello per classificare le cifre nelle celle in modo che le celle vuote siano ordinate come zero
- Finalmente, rilevare l'output in un array di 81 cifre.
sudoku_cell = splitcells(su_imagewrap)
#Let's have alook at the last cell
plt.figure()
plt.imshow(sudoku_cell[58])
plt.mostra()
def CropCell(cellule):
Cells_croped = []
per l'immagine nelle celle:
img = np.array(Immagine)
img = img[4:46, 6:46]
img = Image.fromarray(img)
Cells_croped.append(img)
return Cells_croped
sudoku_cell_croped= CropCell(sudoku_cell)
#Let's have alook at the last cell
plt.figure()
plt.imshow(sudoku_cell_croped[58])
plt.mostra()
Parte 3: RESOLVER EL SODOKU
En esta sección vamos a realizar dos operaciones:
- Remodelando la matriz en una matriz de 9 X 9
- Resolver la matriz usando recursividad
# Reshaping the grid to a 9x9 matrix
grid = np.reshape(griglia,(9,9))
griglia
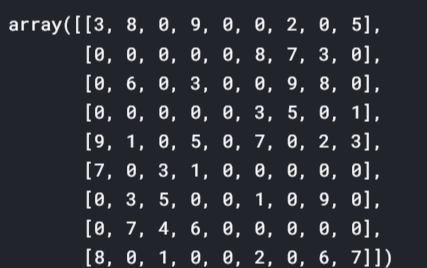
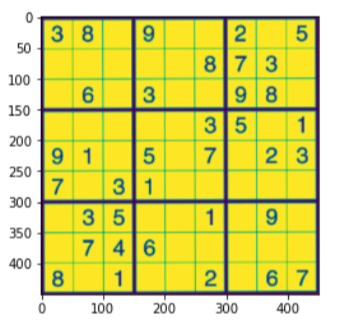
#For compairing
plt.figure()
plt.imshow(su_imagewrap)
plt.mostra()
Verifique el siguiente código para resolver aún más el sudoku:
def next_box(quiz):
per riga nell'intervallo(9):
per col in gamma(9):
se quiz[riga][col] == 0:
Restituzione (riga, col)
return False
#Function to fill in the possible values by evaluating rows collumns and smaller cells
def possible (quiz,riga, col, n):
#global quiz
for i in range (0,9):
se quiz[riga][io] == n e riga != io:
return False
for i in range (0,9):
se quiz[io][col] == n e col != io:
return False
row0 = (riga)//3
col0 = (col)//3
per io nel raggio d'azione(riga0*3, riga0*3 + 3):
per j nell'intervallo(col0*3, col0*3 + 3):
se quiz[io][J]==n e (io,J) != (riga, col):
return False
return True
#Recursion function to loop over untill a valid answer is found.
def risolvere(quiz):
val = next_box(quiz)
se val è False:
ritorna Vero
altro:
riga, col = val
for n in range(1,10): #n is the possible solution
if possible(quiz,riga, col, n):
quiz[riga][col]=n
if solve(quiz):
return True
else:
quiz[riga][col]=0
return
def Solved(quiz):
per riga nell'intervallo(9):
se riga % 3 == 0 e riga != 0:
Stampa("....................")
per col in gamma(9):
se col % 3 == 0 e col != 0:
Stampa("|", fine=" ")
se col == 8:
Stampa(quiz[riga][col])
altro:
Stampa(str(quiz[riga][col]) + " ", fine="")
risolvere(griglia)

Verifique el siguiente código para obtener el resultado final:
se risolvi(griglia):
Risolto(griglia)
altro:
Stampa("La soluzione non esiste. Cifre errate del modello.")
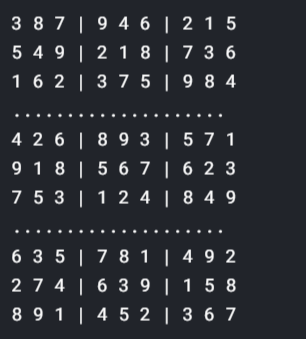
Viva!! Hemos terminado con la risoluzioneIl "risoluzione" si riferisce alla capacità di prendere decisioni ferme e raggiungere gli obiettivi prefissati. In contesti personali e professionali, Implica la definizione di obiettivi chiari e lo sviluppo di un piano d'azione per raggiungerli. La risoluzione è fondamentale per la crescita personale e il successo in vari ambiti della vita, In quanto ti permette di superare gli ostacoli e mantenere la concentrazione su ciò che conta davvero.... de sudoku mediante el apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute.... Se vuoi maggiori informazioni, vedi i link sotto:
https://www.youtube.com/watch?v=G_UYXzGuqvM
https://www.kaggle.com/yashchoudhary/deep-sudoku-solver-multiple-approaches
https://www.youtube.com/watch?v = QR66rMS_ZfA
Note finali
Quindi, in questo articolo, abbiamo avuto una discussione dettagliata su Risolvi il sudoku usando il deep learning. Spero che tu impari qualcosa da questo blog e ti aiuti in futuro. Grazie per la lettura e la pazienza. Buona fortuna!
Puoi controllare i miei articoli qui: Articoli
Identificazione e-mail: [e-mail protetta]
Connettiti con me su LinkedIn: LinkedIn.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





