Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
Un sistema di raccomandazione è una delle principali applicazioni della scienza dei dati. Ogni azienda Internet consumer richiede un sistema di raccomandazione come Netflix, Youtube, un servizio di notizie, eccetera. Quello che vuoi mostrare da una vasta gamma di articoli è un sistema di raccomandazione.

Sommario
- Introduzione a un sistema di raccomandazione
- Tipi di sistema di raccomandazione
- Sistema di raccomandazione del libro
- Filtraggio basato sul contenuto
- Filtraggio collaborativo
- Filtraggio ibrido
- Sistema di raccomandazioni pratiche
- Descrizione del set di dati
- Pre-elaborazione dei dati
- Esegui EDA
- Raggruppamento
- Predizioni
- Note finali
Che cos'è veramente il sistema di raccomandazione?
Un motore di raccomandazione è una classe di apprendimento automatico che offre suggerimenti pertinenti al cliente. Prima del sistema di raccomandazione, la più grande tendenza all'acquisto era accettare un suggerimento dagli amici. Ma ora Google sa quali notizie leggerà, Youtube sa che tipo di video vedrai in base alla cronologia delle tue ricerche, cronologia visualizzazioni o cronologia acquisti.
Un sistema di raccomandazione aiuta un'organizzazione a fidelizzare i clienti ea creare fiducia nei prodotti e servizi desiderati per coloro che sono venuti sul tuo sito.. L'attuale sistema di raccomandazione è così potente da poter gestire anche il nuovo cliente che ha visitato il sito per la prima volta.. Raccomandano prodotti di tendenza o molto apprezzati e possono anche consigliare prodotti che apportano il massimo beneficio all'azienda.
Tipi di sistema di raccomandazione
Un sistema di raccomandazione è generalmente costruito utilizzando 3 tecniche di filtraggio basato sul contenuto, filtraggio collaborativo e una combinazione di entrambi.
1) Filtraggio basato sul contenuto
L'algoritmo consiglia un prodotto simile a quelli usati come sguardi. In parole semplici, in questo algoritmo, proviamo a trovare un elemento che assomigli a. Ad esempio, a una persona piace vedere gli scatti di Sachin Tendulkar, quindi potresti anche vedere le riprese di Ricky Ponting perché i due video hanno tag e categorie simili.
Solo che sembra simile tra i contenuti e non si concentra più sulla persona che lo sta visualizzando. Consiglia solo il prodotto che ha il punteggio più alto in base alle preferenze passate.
2) Filtraggio basato sulla collaborazione
I sistemi di raccomandazione di filtraggio basati sulla collaborazione si basano su interazioni passate di utenti ed elementi di destinazione. In parole semplici, Cerchiamo di trovare clienti simili e di offrire prodotti in base a ciò che hanno scelto il loro aspetto. Capiamo con un esempio. X e Y sono due utenti simili e l'utente X ha visto film A, Per C. E l'utente Y ha guardato i film B, C e D, quindi raccomanderemo un film all'utente Y e un film D all'utente X.
YouTube ha cambiato il suo sistema di consigli da una tecnica di filtraggio basata sui contenuti a una basata sulla collaborazione.. Se hai mai sperimentato, ci sono anche video che non hanno niente a che fare con la tua storia, ma lo consiglia anche perché l'altra persona simile a te l'ha visto.
3) Metodo di filtraggio ibrido
È fondamentalmente una combinazione dei due metodi precedenti. È un modello troppo complesso che consiglia un prodotto in base alla sua storia e a utenti simili come te.
Ci sono alcune organizzazioni che utilizzano questo metodo come Facebook che mostra notizie importanti per te e altri anche nella tua rete e lo stesso viene utilizzato anche da Linkedin..
Sistema di raccomandazione del libro
Un sistema di raccomandazione di libri è un tipo di sistema di raccomandazione in cui dobbiamo consigliare libri simili al lettore in base al loro interesse. Il sistema di raccomandazione dei libri viene utilizzato dai siti Web online che forniscono e-book come Google Play Books, biblioteca aperta, buone letture, eccetera.
In questo articolo, utilizzeremo il metodo di filtraggio basato sulla collaborazione per creare un sistema di raccomandazione dei libri. Puoi scaricare il set di dati da qui
Attuazione pratica del sistema di raccomandazione
Sporciamoci le mani mentre proviamo a implementare un sistema di raccomandazione di libri utilizzando il filtro collaborativo.
Descrizione del set di dati
avere 3 file nel nostro set di dati che sono tratti da alcuni libri che vendono siti web.
- libri: prima si tratta di libri che contengono tutte le informazioni relative ai libri, come l'autore, titolo, l'anno di pubblicazione, eccetera.
- Utenti: il secondo file contiene le informazioni dell'utente registrato, come ID utente, Posizione.
- giudizi: i voti contengono informazioni come quale utente ha assegnato il voto a quale libro.
Quindi, in base a questi tre file, possiamo costruire un potente modello di filtraggio collaborativo. Cominciamo.
Caricare dati
iniziamo importando librerie e caricando set di dati. durante il caricamento del file abbiamo alcuni problemi come.
- I valori nel file CSV sono separati da punto e virgola, non per coma.
- Ci sono alcune righe che non funzionano come se non potessimo importarle con i panda e genera un errore perché Python è un linguaggio interpretato.
- La codifica di un file è in latino
Quindi, durante il caricamento dei dati, dobbiamo gestire queste eccezioni e dopo aver eseguito il seguente codice, Riceverai un avviso e mostrerà quali righe hanno un errore che abbiamo saltato durante il caricamento.
import numpy as np
import pandas as pd
books = pd.read_csv("BX-Libri.csv", settembre=';', codifica="latino-1", error_bad_lines=Falso)
utenti = pd.read_csv("Utenti BX.csv", settembre=';', codifica="latino-1", error_bad_lines=Falso)
valutazioni = pd.read_csv("BX-Book-Ratings.csv", settembre=';', codifica="latino-1", error_bad_lines=Falso)
Pre-trattamento dei dati
Ora, nell'archivio libri, Abbiamo alcune colonne aggiuntive che non sono necessarie per il nostro compito, ad esempio URL di immagini. E rinomineremo le colonne di ogni file poiché il nome della colonna contiene spazio e lettere maiuscole per correggerlo per renderlo facile da usare.
libri = libri[["ISBN", 'Titolo del libro', 'Libro-Autore', "Anno di pubblicazione", 'Editore']]
libri.rinominare(colonne = {'Titolo del libro':'titolo', 'Libro-Autore':'autore', "Anno di pubblicazione":'anno', 'Editore':'editore'}, inplace=Vero)
utenti.rinominare(colonne = {'ID utente':'ID utente', 'Posizione':'Posizione', 'Età':'età'}, inplace=Vero)
rating.rename(colonne = {'ID utente':'ID utente', 'Valutazione del libro':'valutazione'}, inplace=Vero)
Ora, se vedi l'intestazione di ogni frame di dati, puoi vedere qualcosa del genere.
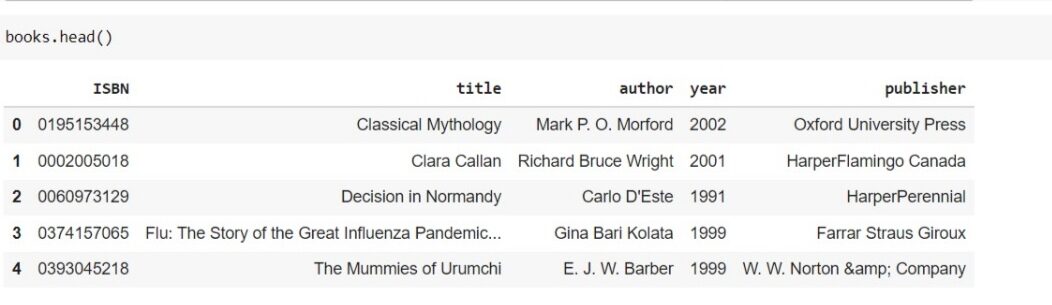
Il set di dati è affidabile e può essere considerato come un grande set di dati. Ho 271360 libri di dati e il numero totale di utenti registrati sul sito è di circa 278000 e hanno dato un punteggio vicino a 11 lakh. così, possiamo dire che il set di dati che abbiamo è buono e affidabile.
Approccio a porre un problema
Non vogliamo trovare somiglianze tra utenti o libri. vogliamo farlo Se c'è un utente A che ha letto e apprezzato i libri x e y, e anche all'utente B sono piaciuti questi due libri e ora l'utente A ha letto e gli è piaciuto un libro z che non è stato letto da B, quindi dobbiamo consigliare z book all'utente B. Questo è il filtro collaborativo.
Quindi, questo si ottiene usando la fattorizzazione matriciale, creeremo una matrice dove le colonne saranno gli utenti e gli indici saranno i libri e il valore sarà il voto. Come se dovessimo creare una tabella pivot.
Un grosso difetto con una dichiarazione del problema nel set di dati.
Se prendiamo tutti i libri e tutti gli utenti per modellare, Non pensi che creerà un problema?? Quindi quello che dobbiamo fare è ridurre il numero di utenti e libri perché non possiamo considerare un utente che si è registrato solo sul sito o che ha letto solo uno o due libri. In tale utente, non possiamo fare affidamento sul consigliare libri ad altri perché dobbiamo estrarre conoscenza dai dati. Quindi, limiteremo questo numero e prenderemo un utente che ha valutato almeno 200 libri e limiteremo anche i libri e prenderemo solo quei libri che hanno ricevuto almeno 50 valutazioni degli utenti.
Analisi esplorativa dei dati
Quindi iniziamo con l'analisi e prepariamo il set di dati come abbiamo discusso per la modellazione. Vediamo quanti utenti hanno dato valutazioni ed estraiamo quegli utenti che hanno dato più di 200 giudizi.
giudizi['ID utente'].value_counts()
passo 1) Estrai utenti e valutazioni da più di 200
quando esegui il codice sopra, possiamo vedere che solo 105283 le persone hanno dato una valutazione tra 278000. Ora estrarremo gli identificatori utente che hanno concesso più di 200 valutazioni e quando abbiamo gli identificatori utente estrarremo le valutazioni solo di questo identificatore utente dal quadro dei dati di valutazione.
x = valutazioni['ID utente'].value_counts() > 200
y = x[X].index #user_ids
print(y.forma)
rating = valutazioni[giudizi['ID utente'].raggio(e)]
passo-2) Unire le classificazioni ai libri
Poi c'è 900 utenti che hanno dato una valutazione di 5.2 lakh e questo è ciò che vogliamo. Ora uniremo le valutazioni con i libri in base all'ISBN in modo da ottenere la valutazione di ciascun utente su ogni ID libro e l'utente che non ha valutato quell'ID libro, il valore sarà zero.
rating_with_books = ratings.merge(libri, su='ISBN') rating_with_books.head()

passo-3) Dai un'occhiata ai libri che hanno ricevuto più di 50 giudizi.
Ora la dimensione del frame di dati è diminuita e abbiamo 4.8 lakh perché quando uniamo il frame di dati, non avevamo tutti i dati identificativi del libro. Ora conteremo la valutazione di ogni libro, quindi raggrupperemo i dati in base al titolo e i dati aggregati in base al rating.
number_rating = rating_with_books.groupby('titolo')['valutazione'].contare().reset_index()
number_rating.rename(colonne= {'valutazione':'number_of_ratings'}, inplace=Vero)
final_rating = rating_with_books.merge(number_rating, on='titolo')
final_rating.shape
final_rating = final_rating[final_rating['number_of_ratings'] >= 50]
final_rating.drop_duplicates(['ID utente','titolo'], inplace=Vero)
Dobbiamo eliminare i valori duplicati perché se lo stesso utente ha valutato la stessa cartella di lavoro più volte, Verrà creato un problema. Finalmente, abbiamo un set di dati con quell'utente che ha valutato più di 200 libri e libri che hanno ricevuto più di 50 giudizi. la forma del frame di dati finale è 59850 righe e 8 colonne.
passo 4) Crea tabella pivot
Come abbiamo discusso in precedenza, creeremo una tabella pivot in cui le colonne saranno gli identificatori dell'utente, l'indice sarà il titolo del libro e il valore i voti. E l'ID utente che non ha valutato alcun libro avrà valore come NAN, quindi imputalo con zero.
book_pivot = final_rating.pivot_table(colonne="ID utente", indice='titolo', valori="valutazione") book_pivot.fillna(0, inplace=Vero)
Possiamo vedere che più di 11 Gli utenti sono stati rimossi perché i loro voti erano in quei libri che non ricevono più di 50 giudizi, quindi vengono rimossi dall'immagine.
modellazione
Abbiamo preparato il nostro set di dati da modellare. Useremo l'algoritmo dei vicini più prossimi, che è uguale al K . più vicino, che viene utilizzato per il raggruppamento in base alla distanza euclidea.
Ma qui, nella tabella pivot, abbiamo molti valori zero e nel raggruppamento, Questa potenza di calcolo aumenterà per calcolare la distanza dai valori zero, quindi convertiremo la tabella pivot nella matrice sparsa e quindi la alimenteremo al modello.
from scipy.sparse import csr_matrix
book_sparse = csr_matrix(book_pivot)
Ora addestreremo l'algoritmo dei vicini più vicini. qui dobbiamo specificare un algoritmo che è un mezzo grossolano per trovare la distanza da ogni punto a tutti gli altri punti.
from sklearn.neighbors import NearestNeighbors
model = NearestNeighbors(algoritmo='bruto')
model.fit(book_sparse)
Facciamo una previsione e vediamo se suggerisce libri o no. troveremo i vicini più vicini all'id del libro di entrata e dopo quello, stamperemo il 5 libri principali che sono più vicini a quei libri. Ci fornirà la distanza e l'identificazione del libro a quella distanza. passiamo ad harry potter, che cosa c'è che non va 237 indici.
distanze, suggerimenti = modello.kneighbors(book_pivot.iloc[237, :].valori.rimodellare(1, -1))
stampiamo tutti i libri suggeriti.
per io nel raggio d'azione(len(suggerimenti)): Stampa(book_pivot.index[suggerimenti[io]])
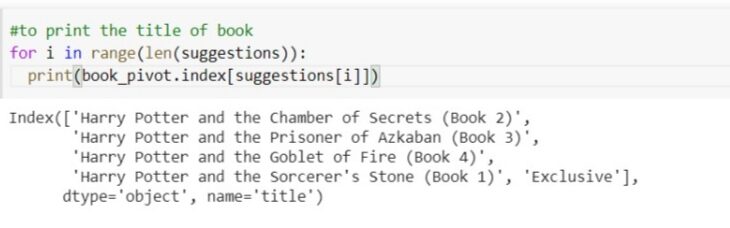
così, abbiamo creato con successo un sistema di raccomandazione dei libri.
Note finali
Viva! Dobbiamo costruire un affidabile sistema di raccomandazione dei libri e puoi modificarlo e trasformarlo in un progetto finale. Questo è un meraviglioso progetto di apprendimento non supervisionato in cui abbiamo svolto molte pre-elaborazione e puoi esplorare ulteriormente il set di dati e, se trovi qualcosa di più interessante, condividilo nel box dei commenti.
Spero che sia stato facile recuperare il ritardo su ogni metodo e seguire l'articolo. Se hai qualche domanda, postalo nella sezione commenti qui sotto. Sarò felice di aiutarti con qualsiasi domanda.
Circa l'autore
Raghav Agrawal
Sto conseguendo la mia laurea in informatica. Mi piacciono molto la scienza dei dati e i big data. Amo lavorare con i dati e apprendere nuove tecnologie. Per favore, sentiti libero di connetterti con me su Linkedin.
Se ti piace il mio articolo, Per favore, leggilo anche agli altri. Collegamento
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





