Questo articolo ha subito una serie di modifiche!!
Inizialmente stavo scrivendo su un argomento diverso (relacionado con la analiticoL'analisi si riferisce al processo di raccolta, Misura e analizza i dati per ottenere informazioni preziose che facilitano il processo decisionale. In vari campi, come business, Salute e sport, L'analisi può identificare modelli e tendenze, Ottimizza i processi e migliora i risultati. L'utilizzo di strumenti avanzati e tecniche statistiche è fondamentale per trasformare i dati in conoscenze applicabili e strategiche....). Avevo quasi finito di scriverlo. avevo investito circa 2 ore e scritto un articolo medio. Se l'avessi fatto dal vivo, avrei fatto bene! Ma qualcosa in me mi ha impedito di farlo vivere. Non ero soddisfatto del risultato. L'articolo non trasmette come mi sento a riguardo 2015 e quanto potrebbe essere utile DataPeaker per l'apprendimento dell'analisi quest'anno.
Quindi, Ho messo quell'articolo nel Cestino e ho iniziato a ripensare a quale argomento avrebbe reso giustizia. Questo è quello che ho finito con: lasciami scrivere fantastici articoli e guide su quello che è stato il mio più grande apprendimento 2014: Libreria Scikit-learn o sklearn in Python. Questo è stato il mio più grande apprendimento perché ora è lo strumento che uso per qualsiasi progetto di machine learning su cui lavoro.
La creazione di questi articoli non sarebbe solo immensamente utile per i lettori del blog, mi sfiderebbe anche a scrivere di qualcosa a cui sono ancora relativamente nuovo. Mi piacerebbe anche sentire da te lo stesso: Qual è stato il tuo più grande apprendimento in 2014 e vorresti condividerlo con i lettori di questo blog?
Che cos'è scikit-learn o sklearn?
Scikit-learn è probabilmente la libreria più utile per l'apprendimento automatico in Python. La libreria sklearn contiene molti strumenti efficienti per l'apprendimento automatico e la modellazione statistica, che includono la classificazione, regressione, raggruppamento e riduzione dimensionale.
Nota che sklearn viene utilizzato per creare modelli di apprendimento automatico. Non dovrebbe essere usato per leggere i dati, manipolarli e riassumerli. Ci sono librerie migliori per questo (ad esempio, NumPy, panda, eccetera.)
![]()
Componenti di scikit-learn:
Scikit-learn viene caricato con molte funzionalità. Ecco alcuni di loro per aiutarti a capire la diffusione:
- Algoritmos de apprendimento supervisionatoL'apprendimento supervisionato è un approccio di apprendimento automatico in cui un modello viene addestrato utilizzando un set di dati etichettati. Ogni input nel set di dati è associato a un output noto, consentendo al modello di imparare a prevedere i risultati per nuovi input. Questo metodo è ampiamente utilizzato in applicazioni come la classificazione delle immagini, Riconoscimento vocale e previsione delle tendenze, sottolineandone l'importanza in...: Pensa a qualsiasi algoritmo di apprendimento automatico supervisionato di cui hai sentito parlare e ci sono buone probabilità che faccia parte di scikit-learn. Da modelli lineari generalizzati (ad esempio, regressione lineare), supporta macchine vettoriali (SVM), alberi decisionali e metodi bayesiani, fanno tutti parte della cassetta degli attrezzi di scikit-learn. La diffusione degli algoritmi di machine learning è uno dei motivi principali dell'elevato utilizzo di scikit-learn. Ho iniziato a usare scikit per risolvere problemi di apprendimento supervisionato e lo consiglierei anche a persone che non conoscono scikit / apprendimento automatico.
- Convalida incrociata: Esistono diversi metodi per verificare l'accuratezza dei modelli monitorati su dati non visti utilizzando sklearn.
- Algoritmi di apprendimento non supervisionato: Ancora, è disponibile un'ampia varietà di algoritmi di apprendimento automatico, dalla piscina, analisi fattoriale, analisi delle componenti principali alle reti neurali non supervisionate.
- Più set di dati sui giocattoli: Questo è stato utile durante l'apprendimento di scikit-learn. Avevo imparato SAS utilizzando vari set di dati accademici (ad esempio, il set di dati IRIS, il set di dati sui prezzi delle case di Boston). Averli a portata di mano durante l'apprendimento di una nuova biblioteca ha aiutato molto..
- Estrazione delle caratteristiche: Scikit-impara a estrarre funzionalità da immagini e testo (ad esempio, sacco di parole)
Comunità / organizzazioni che utilizzano scikit-learn:
Uno dei motivi principali dietro l'uso di strumenti open source è la grande comunità che ha. Lo stesso vale anche per sklearn. Ci sono in giro 35 collaboratori di scikit-learn fino ad oggi, il più notevole è Andreas Mueller (PS Andy cheat sheet sull'apprendimento automatico è una delle migliori visualizzazioni per comprendere lo spettro degli algoritmi di apprendimento automatico).
Ci sono diverse organizzazioni come Evernote, Inria e AWeber mostrati in scikit impara la home page come utenti. Ma penso davvero che l'uso effettivo sia molto di più.
Oltre a queste comunità, ci sono diversi incontri in giro per il mondo. C'era anche un Concorso di conoscenza Kaggle, che si è conclusa di recente, ma potrebbe comunque essere uno dei posti migliori per iniziare a giocare con la biblioteca.
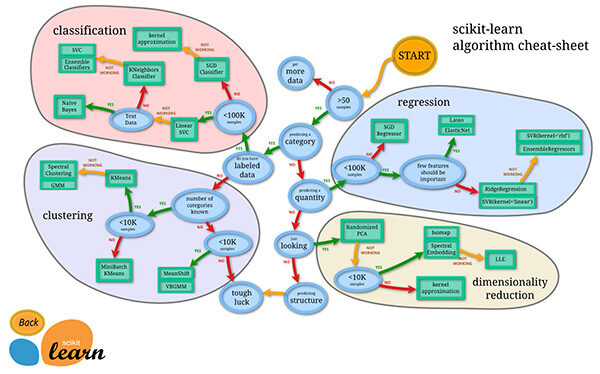
Foglio informativo sull'apprendimento automatico: consulte la imagen original para obtener una mejor risoluzioneIl "risoluzione" si riferisce alla capacità di prendere decisioni ferme e raggiungere gli obiettivi prefissati. In contesti personali e professionali, Implica la definizione di obiettivi chiari e lo sviluppo di un piano d'azione per raggiungerli. La risoluzione è fondamentale per la crescita personale e il successo in vari ambiti della vita, In quanto ti permette di superare gli ostacoli e mantenere la concentrazione su ciò che conta davvero....
Esempio veloce:
Ora che capisci l'ecosistema ad alto livello, lasciatemi illustrare l'uso di sklearn con un esempio. L'idea è semplicemente quella di illustrare la semplicità d'uso di sklearn. Vedremo vari algoritmi e i modi migliori per usarli in uno degli articoli che seguono..
Costruiremo una regressione logistica sul dataset IRIS:
passo 1: importare le librerie pertinenti e leggere il set di dati
importa numpy come np
importa matplotlib come plt
da set di dati di importazione sklearn
delle metriche di importazione di sklearn
de sklearn.linear_model import LogisticRegression
Abbiamo importato tutte le librerie. Prossimo, leggiamo il dataset:
dataset = set di datos.load_iris ()
passo 2: Comprendere il set di dati esaminando distribuzioni e diagrammi
Sto saltando questi passaggi per ora. puoi leggere questo articolo se vuoi imparare l'analisi esplorativa.
passo 3: Creare un modello di regressione logistica sul set di dati ed effettuare stime
model.fit (set di datiun "set di dati" o dataset è una raccolta strutturata di informazioni, che può essere utilizzato per l'analisi statistica, Apprendimento automatico o ricerca. I set di dati possono includere variabili numeriche, categorico o testuale, e la loro qualità è fondamentale per ottenere risultati affidabili. Il suo utilizzo si estende a varie discipline, come la medicina, Economia e scienze sociali, facilitare il processo decisionale informato e lo sviluppo di modelli predittivi.....dati, dataset.target)
previsto = dataset.target
predicted = model.predict (dataset.data)
passo 4: Stampare la matrice di confusione
Stampa (metrics.classification_report (previsto, Previsto))
Stampa (metrics.confusion_matrix (previsto, Previsto))
Note finali:
Questa era una panoramica di una delle librerie di apprendimento automatico più potenti e versatili di Python. È stato anche il più grande apprendimento che ho fatto 2014. Qual è stato il tuo più grande apprendimento in 2014? Condividilo con il gruppo attraverso i commenti qui sotto.
Sei entusiasta di imparare e usare Scikit-learn?? Se è così, restate sintonizzati per gli altri articoli di questa serie.
Un rapido promemoria: se non hai controllato Discussione di Vidhya analitico tuttavia, dovresti farlo ora. Gli utenti si stanno unendo velocemente, quindi prendi il nome utente che vuoi prima che lo prenda qualcun altro.





